 電子發燒友App
電子發燒友App


AI大模型已超出人類想象的速度,將我們帶入智能世界。算力、算法、數據構成了AI的三要素。算力、算法是AI大模型時代的工具,數據的規模和質量才真正決定了AI智能的高度。數據存儲將信息變為語料庫、知識庫,正在和計算一起成為最重要的AI大模型基礎設施。
本文來自“《邁向智能世界白皮書2023版(合集)》”。高可靠、高性能、共享的數據存儲,成為以Oracle為代表的數據庫的最佳數據基礎設施。面向未來,對企業數據存儲進行了如下展望:
AI大模型將AI帶入新的發展階段。AI大模型需要更高效的海量原始數據收集和預處理,更高性能的訓練數據加載和模型數據保存,以及更加及時和精準的行業推理知識庫。以近存計算、向量存儲為代表的AI數據新范式正在蓬勃發展。
大數據應用經歷了歷史信息統計、未來趨勢預測階段,正在進入輔助實時精準決策、智能決策階段。以近存計算為代表的數據新范式,將大幅提升湖倉一體大數據平臺的分析效率。
以開源為基礎的分布式數據庫,正在承擔越來越關鍵的企業應用,新的分布式數據庫+共享存儲的高性能、高可靠架構正在形成。
多云成為企業數據中心新常態,企業自建數據中心和公有云形成有效互補。云計算的建設模式從封閉全棧走向開放解耦,從而實現應用多云部署、數據/資源集中共享。
AI大模型應用聚集海量企業私域數據,數據安全風險劇增。構建包括存儲內生安全在內的完整數據安全體系,迫在眉睫。
AI大模型推動數據中心的計算、存儲架構從以CPU為中心走向以數據為中心,新的系統架構、生態正在重新構建。
AI技術正在越來越多地融入在數據存儲產品及其管理,從而大幅改善數據基礎設施的SLA水平。
1、AI大模型
AI的發展遠超過預期,2022年末,當OpenAI發布ChatGPT時,沒有人能想到,AI大模型接下來將為人類社會帶來歷史性變革。
簡單來說,AI大模型時代的到來,存儲作為數據的關鍵載體,需要在三個方面演進,即海量非結構化數據的治理、10倍的性能提升、存儲內生安全。在滿足EB級海量擴展性的基礎之上,需要滿足百GBps級的帶寬和千萬級IOPS,實現10倍以上的性能提升。
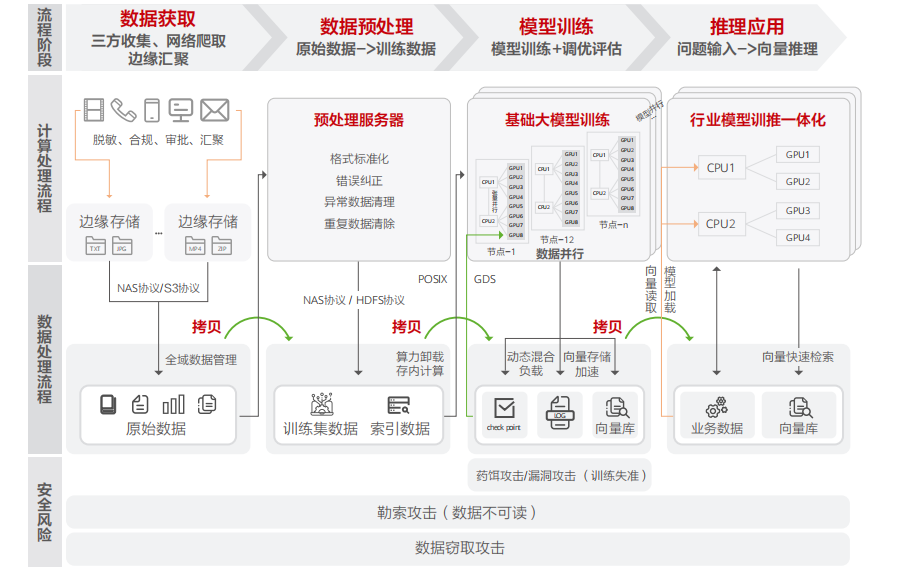
企業在使用AI大模型、HPC、大數據時均需要豐富的原始數據,它們的來源是相同的,均是企業所積累的生產交易數據、科研實驗數據和用戶行為數據。因此,大模型采用和HPC、大數據同源的建設模式是最經濟高效的,實現一份數據在不同環境中協同工作。

全閃存存儲將帶來性能大幅提升,加快AI大模型開發落地的速度;以數據為中心的架構可以帶來硬件資源的解耦與互聯,加速數據的按需流動;數據編織、向量存儲與近存計算等新興數據處理技術,將最大程度降低企業整合數據、使用數據的門檻,滿足資源的高效利用,降低行業接入AI大模型的難度;存儲內生安全體系將保護企業核心私密數據資產,讓企業更加放心地使用AI大模型。
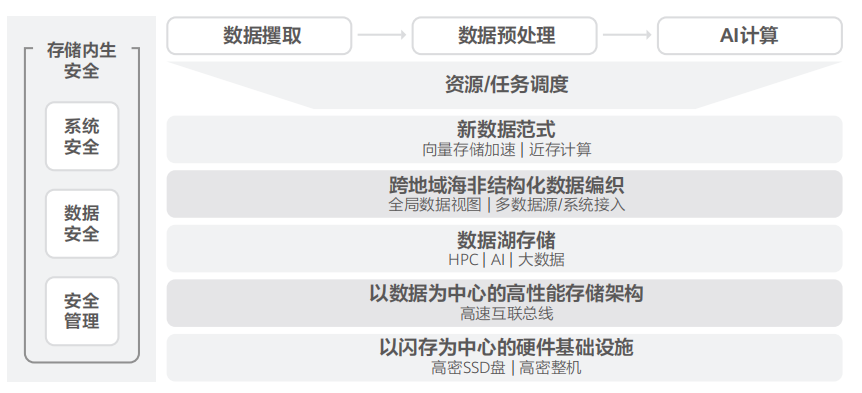
2、大數據
大數據應用的發展可以描述為傳統數據應用、預測分析和主動決策三個階段。
傳統數據倉庫時代:企業通過數據倉庫構建面向主題的、可隨時間變化的數據集合,從而實現對歷史數據進行準確的描述和統計,為分析決策服務,但僅能處理TB級結構化數據。
傳統數據湖時代:企業使用Hadoop技術構建數據湖,處理結構化、半結構化數據,實現基于歷史數據預測未來的發展趨勢。這個階段形成了數據湖和數據倉庫并存的“煙囪”架構,數據需要在數據湖和數據倉庫之間流轉,因而無法實現實時決策、主動決策。
湖倉一體時代:企業開始嘗試從IT堆棧優化上尋找實時決策、主動決策解決方案,將大數據平臺快速推向湖倉一體的新架構。其核心舉措是與存儲廠商聯合創新,將大數據IT堆棧存算解耦,以數據湖存儲實現數據湖和數據倉庫共享同一份數據,無需在數據湖和數據倉庫間進行數據流轉,從而實現實時、主動決策。
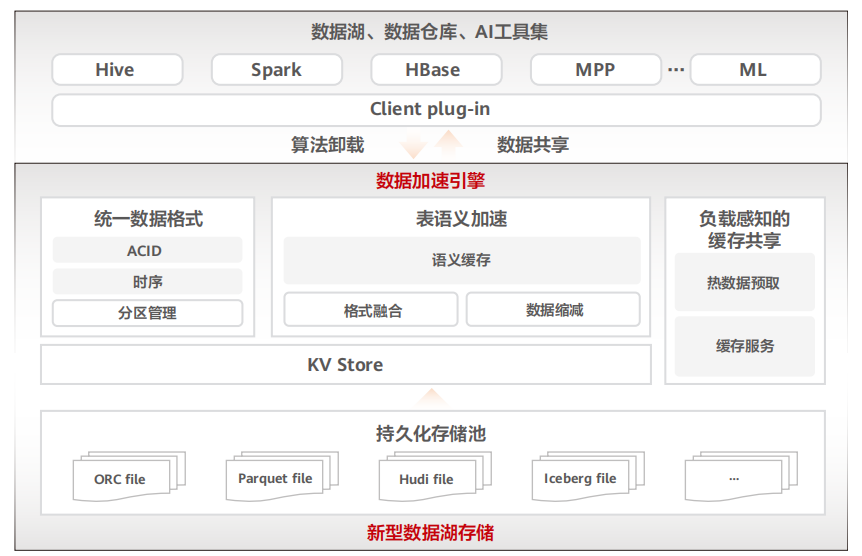
3、分布式數據庫
開源數據庫MySQL和PostgreSQL占據全球數據庫市場格局TOP2。開源數據庫正在重構企業核心系統。同時為確保業務平穩運行,分布式數據庫存算分離架構正在成為事實標準。
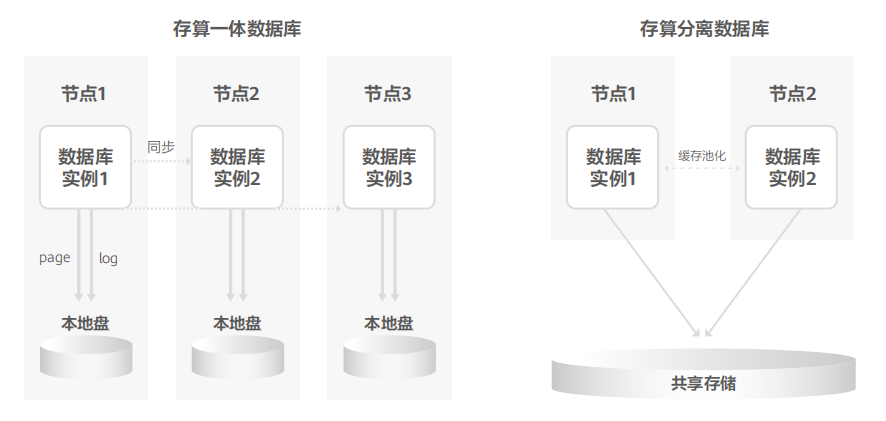
目前,全球主要銀行均已通過存算分離架構分布式數據庫建設新核心系統,亞馬遜Aurora、阿里PolarDB、華為GaussDB、騰訊TDSQL等主要新型數據庫廠商均已將其架構轉向存算分離,存算分離架構已經成為分布式數據庫建設的事實標準。
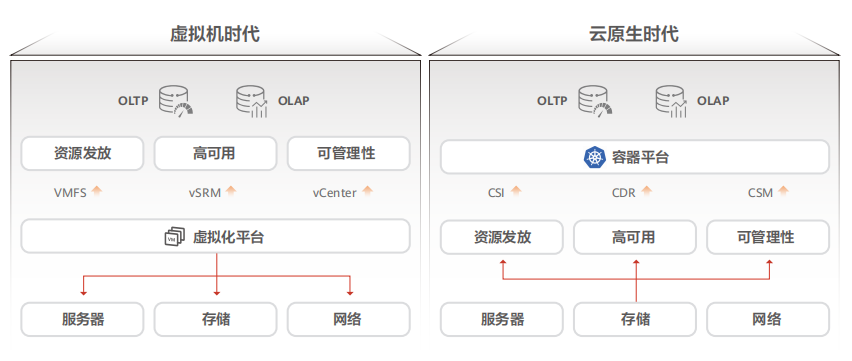
4、云原生
企業云計算基礎設施已經從單云走向多云。不論哪一朵云都無法同時滿足企業所有對應用與成本的訴求。因此,89%的企業選擇建設多個公有云和私有云并存的多云IT架構。
目前基礎設施面向多云打造的關鍵能力大致可分為兩類。第一類是使能數據跨云流動,如華為和NetApp存儲支持數據跨云分級、跨云備份能力,使數據始終使用性價比最高的存儲服務;另一類是數據跨云管理,讓用戶通過全局數據視圖把握數據總體情況,并將數據調度到產生價值最大的應用中。
企業采用開放解耦架構建設,讓硬件資源可被多個云共享,數據可在多個云間按需流動,方可真正發揮多云架構優勢。
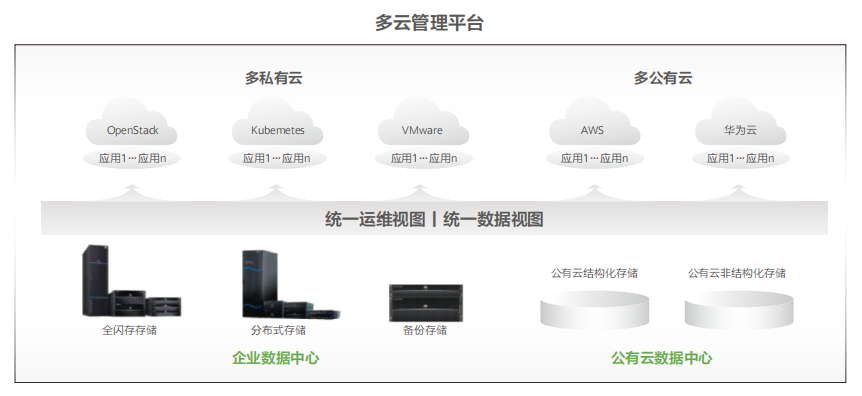
從硬件、平臺到應用,最優的服務往往來自不同供應商,因此通過開放解耦的建設方式企業能搭建最優的IT堆棧。以AI為例。當前市面上最為火熱的AI大模型供應商,如openAI、Meta等,其硬件基礎設施能力遠不如NVIDIA、DDN、華為等IT巨頭。沒有任何一個廠商能夠提供端到端的最優AI訓練/推理方案,因此企業在搭建自己的AI訓練/推理集群時,會選擇開放解耦的架構,選擇最優的硬件和訓練/推理模型。
5、非結構化數據
隨著5G、云計算、大數據、AI、高性能數據分析(HPDA)等新技術、新應用的蓬勃發展,企業非結構化數據快速增長,如視頻,語音,圖片,文件等,容量正在從PB到EB級跨越。例如,一臺基因測序儀每年產生數據達到8.5PB,某運營商集團每天平均處理數據量達到15PB,一顆遙感衛星每年采集數據量可以達到18PB,一輛自動駕駛訓練車每年產生訓練數據達到180PB。
首先需要讓數據“存得下”:以最低的成本、最小的機房空間、最低的功耗存下更多的數據。
其次要讓數據都要“流得動”:數據中心間和數據中心內的數據需要根據策略按需高效流動。
最后還需要讓數據“用得好”:企業的視頻、音頻、圖片、文本等多種混合負載應用都能滿足要求。
6、存儲內生安全
數據作為AI的根基,其重要性進一步凸顯,數據的安全就是企業核心資產的安全。據splunk公司發布的《2023年安全現狀報告》顯示,超過52%的組織遭受了惡意攻擊導致數據泄露,66%的機構遭受勒索軟件攻擊,數據安全的重要性正在不斷上升。
數據在產生、采集、傳輸、使用、銷毀的全生命周期處理過程中始終離不開存儲設備。存儲作為數據的最終載體,數據的“保險箱”,擁有近數據的保護能力,近介質的控制能力,在數據安全防護、數據備份與恢復、數據安全銷毀等領域有不可替代的作用。
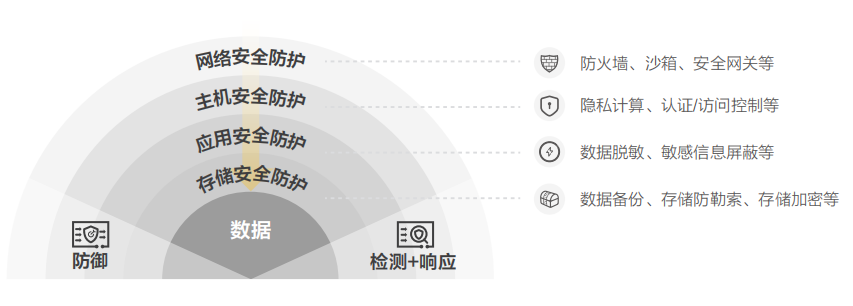
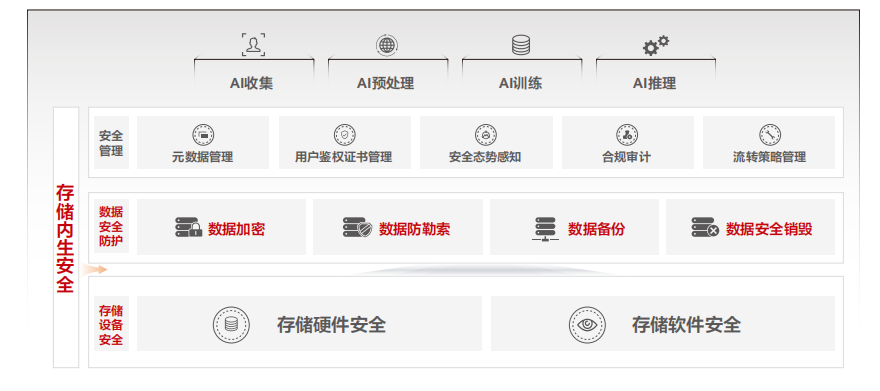
存儲內生安全體系通過先天的架構與設計,不斷增強存儲的安全能力,包含兩個方面:存儲設備自身的安全能力、存儲的數據安全防護能力。
7、全場景閃存
根據市場統計到2022年,SSD的市場份額和出貨數量已經是機械盤的2倍以上,占比超過了65%。我們有理由相信企業正在迎來全面閃存化的時代。
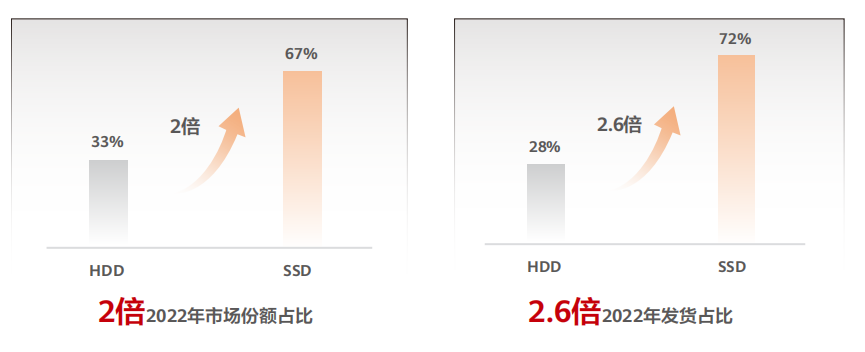
企業級 SSD 的核心組成部分——NAND顆粒,很大程度上決定其成本。而3D NAND堆疊層數升級與QLC顆粒的應用,推動全閃存物料成本不斷降低。目前,主流顆粒廠商量產的3DNAND顆粒堆疊層數已經達到176L,并紛紛給出200層以上設計路標,比2018年提升接近2倍。除了堆疊層數,在顆粒類型方面,TLC顆粒已經成為企業級SSD主流選擇,QLC SSD也已登上舞臺。
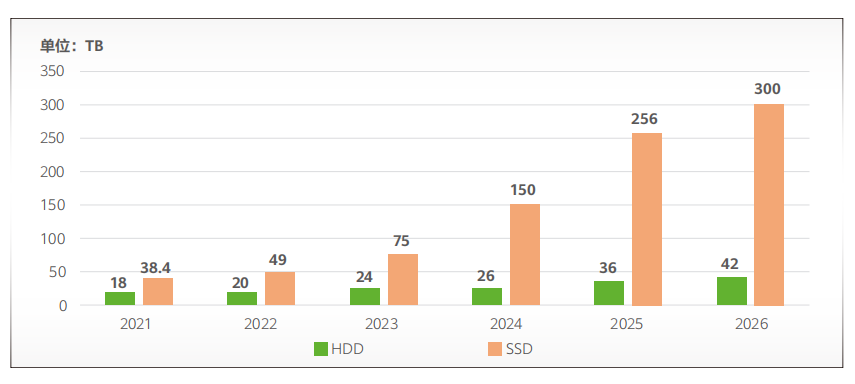
更多SSD內容,參考“2023年計算機SSD固態硬盤詞條報告”,“企業級SSD技術和行業發展(匯總) ”、“《中國企業級SSD行業技術合集》”、“《SSD技術白皮書系列》”和“《SSD介質技術》”。
8、以數據為中心的架構
近年來,AI和實時大數據分析應用蓬勃發展,以CPU為主的算力向CPU+GPU+NPU+DPU的多樣化算力發展。
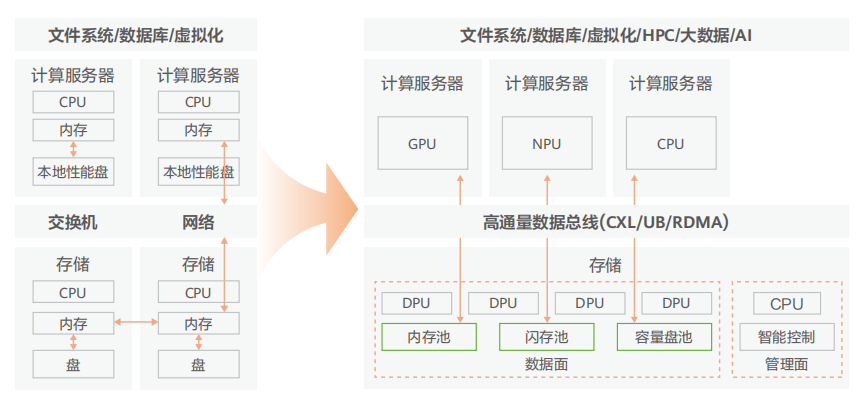
未來,隨著AI、大數據等應用更高的性能時延要求、CPU性能增速放緩,在服務器架構演進為Composable架構的同時,存儲架構也將演進為以數據為中心的Composable架構,從而大幅提升存儲系統的性能。存儲系統的多樣化處理器(CPU、DPU)、內存池、閃存池、容量盤池,將通過新型數據總線互聯,從而實現數據進入存儲系統之后可以直接存放至內存或閃存,避免CPU成為數據訪問的瓶頸。
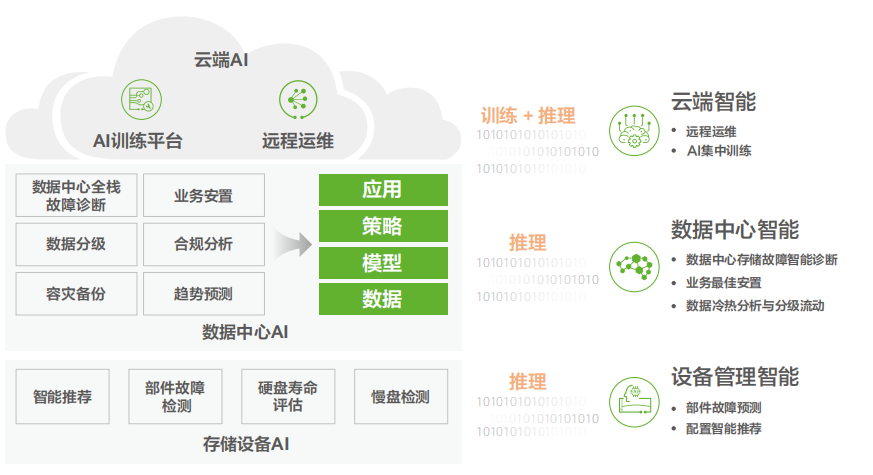
9、AI賦能存儲
基于傳統AI實現性能、容量、備件故障等趨勢提前預測,降低異常發生概率;在復雜的異常處理場景,存儲管理系統可基于AI大模型快速強化交互邏輯,輔助人工快速定位問題,從而大幅縮短故障處理周期。
10、存儲綠色節能
在“碳達峰、碳中和”大背景下,綠色低碳成為數據中心的重要發展方向。存儲能耗在數據中心占比超過30%。因此,除了降低PUE之外,降低以存儲為代表的IT設備能耗,對于促進數據中心零碳排至關重要。

通過多協議融合和孤島融合,實現多合一,提升資源利用率。一套存儲可支持文件、對象、HDFS等多種協議,滿足多樣化需求,整合多種類型存儲;同時通過融合資源池,實現資源池化,從而提升利用率。
存儲有83%的能耗來自于存儲介質,在相同容量下,SSD相比機械硬盤的能耗降低70%,空間占用節省50%。通過大容量SSD和高密硬盤框,提升存儲容量功耗占比,減少相同數據量附帶產生的數據處理和存儲能耗,進而推動存儲單位容量能耗降低,用更小的空間存儲更大的容量。
審核編輯:黃飛













 工商網監
工商網監
評論