 電子發燒友App
電子發燒友App


分布式存儲簡單的來說,就是將數據分散存儲到多個數據存儲存儲服務器上。分布式存儲目前多借鑒Google的經驗,在眾多的服務器搭建一個分布式文件系統,再在這個分布式文件系統上實現相關的數據存儲業務,甚至是再實現二級存儲業務如Bigtable。
???????? 分布式文件系統存儲目標以非結構化數據為主,但在實際應用中,存在大量的結構化和半結構化的數據存儲需求。分布式鍵值系統是一種有別于我們所熟悉的分布式數據庫系統的,用于存儲關系簡單的半結構化數據的存儲應用。
在分布式鍵值系統中,半結構化數據被封裝成由《key,value,timestamp》鍵值對組成的對象,其中key為唯一標示符;value為屬性值,可以為任何類型,如文字、圖片,也可以為空;timestamp為時間戳,可以提供數據的多版本支持。分布式鍵值系統以鍵值對存儲,它的結構不固定,每一元組可以有不一樣的字段,可根據需要增加鍵值對,從而不局限于固定的結構,適用面更大,可擴展性更好。
分布式鍵值系統支持針對單個《key,value,timestamp》鍵值對的增、刪、查、改操作,可以運行在PC服務器集群上,并實現集群按需擴展,從而處理大規模數據,并通過數據備份保障容錯性,避免了分割數據帶來的復雜性和成本。
總體來說,分布式鍵值系統從存儲數據結構的角度看,分布式鍵值系統與傳統的哈希表比較類似,不同的是,分布式鍵值系統支持將數據分布到集群中的多個存儲節點。分布式鍵值系統可以配置數據的備份數目,可以將一份數據的所有副本存儲到不同的節點上,當有節點發生異常無法正常提供服務時,其余的節點會繼續提供服務。
下面,我們來看看業界主流的分布式鍵值系統的架構模式。
Amazon Dynamo
Dynamo是AWS上最基礎的分布式存儲應用之一,也是AWS最早推出的云服務之一,它構建在AWS的S3基礎之上,采用去中心節點化的P2P方式,采用這種模式的,還有Facebook推出的Cassandra。
1、數據分布
Dynamo使用了改進的一致性哈希算法:每個物理節點根據其性能的差異分配多個token,每個token對應一個“虛擬節點”。所有節點每隔固定時間(比如1s)通過Gossip協議的方式從其他節點中任意選擇一個與之通信的節點。如果連接成功,雙方交換各自保存的集群信息。
Gossip協議用于P2P系統中自治的節點協調對整個集群的認識,比如集群的節點狀態、負載情況。由于種子節點的存在,新節點加入可以做得比較簡單:新節點加入時首先與種子節點交換集群信息,從而了解整個集群。
2、一致性與復制
一般來說,從機器K+i宕機開始到被認定為永久失效的時間不會太長,積累的寫操作也不會太多,可以利用Merkle樹對機器的數據文件進行快速同步。Dynamo引入向量時鐘(Vector lock)的技術手段來嘗試解決沖突,這個策略依賴集群內節點之間的時鐘同步算法,但不能完全保證準確性。Dynamo只保證最終一致性,如果多個節點之間的更新順序不一致,客戶端可能讀取不到期望的結果。
3、容錯
核心機制就是:數據回傳+Merkle樹同步+讀取修復
Dynamo在數據讀寫中采用了一種稱為弱quorum (Sloppy quorum)的機制,涉及三個參數W、R、N,見其中W代表一次成功的寫操作至少需要寫入的副本數,R代表一次成功讀操作需由服務器返回給用戶的最小副本數,N是每個數據存儲的副本數。Dynamo要求R+W〉N,滿足這個要求,保證用戶讀取數據時,始終可以獲得一個最新的數據版本。
針對臨時故障,一旦某個節點出現問題,則將這個節點值傳送給“同組”中的下一個正常節點,并在這個數據副本的元數據中記錄失效的節點位置,便于數據回傳;然后,由這個節點上一個臨時空間進行存儲和處理數據,同時該節點還對失效的節點進行監測,一旦失效的節點重新可用,則將自己所保存的最新數據回傳給它,然后刪除自己開辟的臨時空間數據。
針對永久性故障,Dynamo必須檢査和保持數據的同步 ,Dynamo采用一種稱為反熵協議的手段來保證數據的同步。為了減少數據同步檢測中需要傳輸的數據量,加快檢測速度,Dynamo使用了Merkle哈希樹技術,每個虛擬節點保存三顆Merkle樹,即每個鍵值區間建立一個Merkle樹。Dynamo中Merkle哈希樹的葉子節點是存儲每個數據分區內所有數據對應的哈希值,父節點是其所有子節點的哈希值。
4、負載均衡
采用改進的一致性Hash+虛擬節點模式。
在傳統的一致性哈希算法上,服務節點跟哈希環上的點是一一對應的。這里會存在一個問題,就是每一個節點的負載最后是不均勻的,而我們也無法進行調整。Dynamo通過一個服務節點可以有多個哈希環上的虛擬節點的方法,使得每一個服務節點的負載都是均勻的。并且假如發現了某一個節點的負載過高,少分配虛擬節點給它便可以降低該服務節點的負載,從而實現了自動地負載均衡。
5、讀寫流程
由于采用了去中心化的模式,因此,需要采用較復雜的模式來控制并發,Dynamo使用Paxos協議結合Gossip來進行并發處理。具體處理模式如圖1所示。
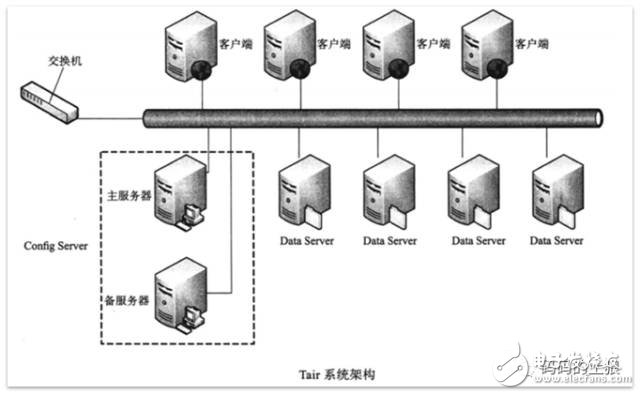
圖1 Dynamo 寫入和讀取流程
Dynamo采用去中心節點的P2P設計,增加了系統可擴展性,但同時帶來了一致性問題,影響上層應用。一致性問題使得異常情況下的測試變得更加困難,由于Dynamo只保證最基本的最終一致性,多客戶端并發操作的時候很難預測操作結果,也很難預測不一致的時間窗口,影響測試用例設計。
由于去中心化模式所導致的復雜性和不確定性。目前主流的分布式系統一般都帶有中心節點,這樣能夠簡化設計,而且中心節點只維護少量元數據,一般不會成為性能瓶頸。
淘寶Tair
Tair是阿里巴巴推出的一個高性能,分布式,可擴展,高可靠的key/value結構存儲系統,它專門針對小文件的存儲做了優化,并提供簡單易用的接口(類似Map)。
1、整體架構
Tair作為一個分布式系統,是由一個中心控制節點和若干個服務節點組成。Config Server是控制點,而且是單點,目前采用一主一備的形式來保證可靠性,所有的Data Server地位都是等價的。
圖2 Tair系統架構
2、數據分布
Tair根據數據的主鍵計算哈希值后,分布到Q個桶中,根據Dynamo論文中的實驗結論,Q取值需要遠大于集群的物理機器數,例如Q取值102400。
3、容錯
如果是備副本,則直接遷移;如果是主副本,則先切換再遷移。
4、數據遷移
機器加入或者負載不均衡可能導致桶遷移,遷移的過程中需要保證對外服務。當遷移發生時,假設Data Server A要把桶1、2、3遷移到Data Server B。遷移完成前,客戶端的路由表沒有變化,客戶端對1、2、3的訪問請求都會路由到A。現在假設1還沒開始遷移,2正在遷移中,3已經遷移完成。那么如果對1訪問,A直接服務;如果對3訪問,A會把請求轉發給B,并且將B的返回結果返回給用戶;如果對2訪問,由A處理,同時如果是對2的修改操作,會記錄修改日志,等到桶2遷移完成時,還要把修改日志發送到B,在B上應用這些修改操作,直到A和B之間數據完全一致遷移才真正完成。
5、配置服務器(Config Server)
客戶端緩存路由表,大多數情況下,客戶端不需要訪問配置服務器(Config Server),Config Server宕機也不影響客戶端正常訪問。如果Data Server發現客戶端的版本號過舊,則會通知客戶端去Config Server獲取一份新的路由表。如果客戶端訪問某臺Data Server發生了不可達的情況(該Data Server可能宕機了),客戶端會主動去Config Server獲取新的路由表。
6、數據服務器(Data Server)
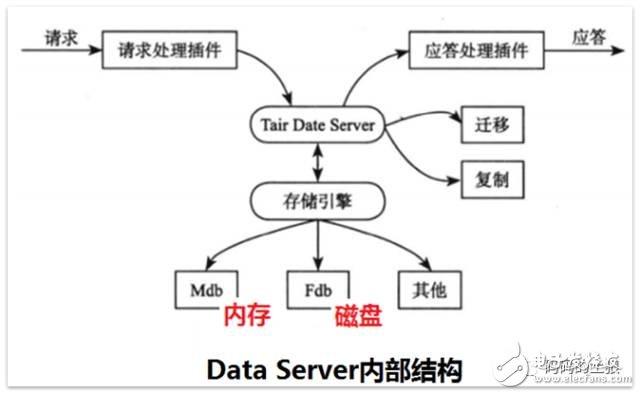
Tair存儲引擎有一個抽象層,只要滿足存儲引擎需要的接口,就可以很方便地替換Tair底層的存儲引擎。
Tair最主要的用途在于分布式緩存,持久化存儲起步比較晚,在實現細節上也有一些不盡如人意的地方。例如,Tair持久化存儲通過復制技術來提高可靠性,然而,這種復制是異步的。因此,當有Data Server發生故障時,客戶有可能在一定時間內讀不到最新的數據,甚至發生最新修改的數據丟失的情況。








 工商網監
工商網監
評論