 電子發燒友App
電子發燒友App


1嵌入式數據庫
通常, 我們采用數據庫來實現對數據的存儲、檢索等功能。像MySQL這類基于C/S結構的關系型數據庫系統, 雖然代表著目前數據庫應用的主流, 卻并不能滿足所有應用場合的需要。很多的應用,僅僅利用到了這些數據庫產品的基本特性而已。有時我們需要的可能只是一個簡單的基于磁盤文件的數據庫系統,這樣就不必安裝龐大的數據庫服務器, 以簡化數據庫應用程序的設計。在某些特殊應用場合,比如在嵌入式系統中,由于系統的硬件軟件資源都有限,這些數據庫產品就明顯有一些臃腫,甚至是不可實現的。在這些情況下,嵌入式數據庫的優勢就特別明顯了。
嵌入式數據庫通常與操作系統和具體應用集成在一起, 無須獨立運行的數據庫引擎,由程序直接調用相應的API去實現對數據的存取操作。更直白地講, 嵌入式數據庫是一種具備了基本數據庫特性的數據文件。嵌入式數據庫與其它數據庫產品的區別是,前者是程序驅動式,而后者是引擎響應式。嵌入式數據庫的一個很重要的特點是它們的體積非常小,編譯后的產品也不過幾十KB, 在一些移動設備上極具競爭力。
從目前嵌入式應用的發展趨勢來看,嵌入式數據庫的實現必須充分體現系統的可定制性,即系統選擇的技術路線要面向具體的行業應用,因而研究源碼開放的嵌入式數據庫具有特殊意義。
2 Berkeley DB
Berkeley DB是由sleepycat software開發的輕量級嵌入式數據庫,它不僅適用于嵌入式系統,而且可以直接連接到應用程序內部,和應用程序運行在同一地址空間。傳統的數據庫一般作為獨立服務器工作,而Berkeley DB是軟件開發庫,開發者將它嵌入到應用程序中,應用程序本身就是一個服務器,而只是利用嵌入式數據庫開發來實現定制的數據庫邏輯,避免了與應用服務器進程間通信的開銷,因此Berkeley DB具有較高的運行效率,適用于資源受限的嵌入式系統。
一般而言,Berkeley DB數據庫系統可以大致分為五個子系統,如圖1所示。
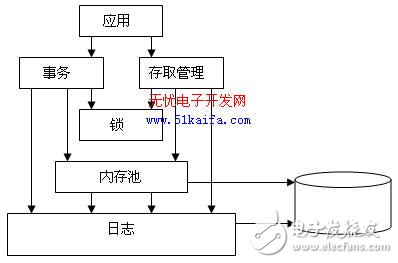
圖1 Berkeley DB 子系統圖
1、 存取管理子系統(Access Methods)
該子系統為創建和訪問數據庫文件提供基本的支持。在沒有事務管理的情況下,該子系統中的模塊可單獨使用,為應用程序提供快速高效的數據存取服務。
2、 內存池管理子系統(Memory Pool)
該子系統就是Berkeley DB所使用的通用共享內存緩沖區,該子系統可以被應用程序單獨使用。
3、 事務子系統(Transaction)
該子系統為Berkekey DB提供事務管理功能,保證操作的原則性、一致性和孤立性。事務子系統適用于對需要事務保證的數據進行修改的場合。
4、 鎖子系統(Locking)
該子系統提供進程之間以及進程內部的并發管理機制,為系統提供多用戶讀取和單用戶修改同一對象的共享控制。該子系統可以被應用程序單獨使用。
5、 日志子系統(Logging)
該子系統采用的是先寫日志的策略,支持事務子系統進行數據恢復,保證數據一致性。
3 基于嵌入式數據庫的海量存儲技術在網絡性能管理系統中的應用
3.1 嵌入式數據庫Berkeley DB 處理海量數據存儲
傳統的網絡管理軟件在海量數據存儲方面大部分采取大型關系型數據庫,由于網絡管理軟件要與數據庫服務器進行通信,這種方式造成了系統性能的極大下降,另外隨著所管網絡規模的增大,信息采集的急劇增加,緩慢而頻繁的數據庫讀寫操作來不及處理實時采集到的海量數據,導致數據丟失,網絡管理失真,甚至會導致系統的癱瘓。也有少數網絡管理軟件采取使用一種日志文件以ASCII 文本形式來記錄采集到的流量數據,通常該種日志文件具有常量大小的特征,能夠支持長期的網絡監測任務,如國內外最為流行的免費且開放源代碼的流量監測軟件MRTG 就是采用這種方式實現海量數據存儲的。MRTG 定期對數據進行整合,根據記錄數據的日期不同而以不同的粒度保存數據,隨著時間的推移,相應數據的粒度逐漸變大,但這種方式存在兩個缺點:(1)所存儲的數據粒度受到限制,如不能從中得到一個月前的某天平均每半個小時的數據;(2)每次數據采集后,MRTG 都根據日志文件進行流量圖生成,并以HTML 格式呈現,而在實際應用場合,一個端口的流量統計分析圖形被用戶調用查看的概率遠遠小于不被調用的概率,因此浪費了大量用于生成圖形的系統開銷,隨著網絡規模的擴大,MTRG 在性能上明顯不能滿足要求。本文提出了一種如圖2所示的流量數據采集及存儲方案。網絡性能管理軟件實時地接收路由器發送過來的Netflow/sFlow 包(當然這里也包括用SNMP 協議定時采集到的流量數據),將其結果存儲到嵌入式數據庫Berkeley DB 當中,供長期歷史保存。與MRTG 不同的是:(1)它采用了嵌入式數據庫Berkeley DB, Berkeley DB可以直接連接到應用程序內部,和應用程序運行在同一地址空間,因此它不需要與另外的數據庫應用程序進行通信,提高了應用程序的速度,減少磁盤操作的時間,防止了數據因磁盤操作緩慢而導致的數據丟失現象。(2)它并非每次采集都生成圖形,而是引入觸發控制方式的“按需成圖”,當客戶需要查看某一段時間里的圖形、或者是某一端口流量、或者是某一種服務的圖形等時,只需對成圖控制模塊執行相應的操作,成圖模塊則向數據庫里查找特定的數據生成相應的圖形。
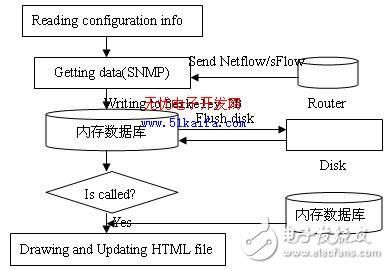
圖2 流量數據采集及存儲方案圖
3.2 多進程、多數據庫加鎖機制在網絡性能管理系統中處理海量數據的實現
網絡管理的前提是信息采集,全面而實時地采集到所有的信息,然后對信息進行分類匯總,進而使網絡管理軟件實現:網絡性能實時監測、系統性能實時監測、應用性能實時監測、SLA 服務質量管理、故障預警、DOS 攻擊定位、病毒掃描、統計分析報告、網絡容量趨勢分析、系統管理與維護等功能。由于Berkeley DB 單個數據庫的容量只能為256T,而網絡管理信息龐大,為了擴充其存儲容量,采取了多個數據庫的方法。另外客戶在使用網絡性能管理系統軟件的成圖控制模塊時,往往關注的是某一段時間里的圖形如:某一段時間里某一端口流量圖、某一段時間里某一種服務圖等等,因此為了日后的成圖,我們以時間(年、月、日)為單位建立若干個數據庫。數據庫名以某年某月某日某小時(24 小時制)命名,來存放該小時里采集到的信息。另外為了緩沖網絡管理當中采集到的海量信息,我們采取了消息隊列機制,父進程將采集到的信息先寫入消息隊列。然后子進程從消息隊列中讀出信息寫入數據庫(為了防止消息隊列中信息過多單進程來不及讀消息隊列并寫數據庫而導致消息隊列阻塞,整個系統效率低下。為此我們創建了多個子進程來讀消息隊列寫數據庫)。
采用上述方法以時間點(小時)為單位命名數據庫,存放對應時間里的信息。但由于路由器偶爾會發生信息滯留現象(路由器滯留時間最大為30 分鐘,例如:可能6 點30 以后收到的信息7 點才轉發),如果按照上述存儲方法將會存入7 點的數據庫。導致存儲信息失真,不是網絡某一時刻的真實反映。為解決這一現象,每次打開兩個數據庫,即既打開當前點的數據庫亦打開前一時間點的數據庫。當收到數據包時,根據數據包中Netflow/sFlow流到達路由器的時間來判別寫哪個數據庫。
由于上述兩個原因系統當中存在著多個子進程寫多個數據庫,如果不采取一定的措施很容易發生一序列的問題如:哪個進程負責創建數據庫、那個進程負責關閉數據庫、多個進程之間如何管理。為解決這些問題系統采取了基于多進程、多數據庫的加鎖機制和心跳機制。
多進程、多數據庫的加鎖機制實現流程如圖3所示

圖3 多進程、多數據庫的加鎖機制實現流程圖
3.3 多個附加數據庫查詢機制的實現
由于Berkeley DB 不是關系型數據庫,因此我們不能像對關系型數據庫一樣對其進行復合條件查詢,而經常客戶需要查看某一段時間里的圖形如:某一段時間里某一端口流量圖、某一段時間里某一種服務圖等等,而這些圖形的成圖數據都是基于復合條件查詢所得到的。為解決這個問題Berkeley DB 為我們提供了附加數據庫(二級數據庫),在附加數據庫中我們可以設定任意的key(可以是關系數據庫中多列屬性的組合),因此我們可以根據附加數據庫的key方便地在附加數據庫中進行查詢,得到所需要的數據然后在成圖模塊展示,為此我們引入了在對網絡流量數據做統計時使用頻率較高、方便成圖模塊查詢的的5 個附加數據庫分別是: SCRIP_SUBDB 、DSTIP_SUBDB 、SRCPORT_SUBDB 、DSTPORT_SUBDB 、STARTTIME_SUBDB。而且根據實際的情況我們還可以增加附加數據庫的個數。另外為了提高數據庫的查詢效率和數據的插入速度,結合Berkeley DB 的四種訪問方式,我們為主數據庫采取Queue 訪問方式以提高數據插入速度,并且以時間作為key。而對于附加數據庫我們則BTree 訪問方式以提高查詢效率,而其key 則根據不同的關聯函數產生,這里我們以附加數據庫SCRIP_SUBDB 為例討論主數據庫與附加數據庫之間的關系:
initenv(const conf_ST *conf)//初始化數據庫環境
initalldb (const conf_ST *conf ,int type) //初始化所有數據庫
{
??
init_primary_db(conf,&last-db,LAST,type);//初始化前一時間點數據庫
init_primary_db(conf,&(current-db),CURRENT,type); //初始化當前時間點數據庫
??
INIT_SEC_DB(srcip,SRCIP,type); //該函數實際上是定義為初始化附加數據庫的一個宏
??
}
int get_item_srcip(DB *sdbp,const DBT *pkey,const DBT *pdata,DBT *skey)
//附加數據庫到主數據庫設定key 的關聯函數
int init_sub_db(const conf_ST *conf, DB**primary_db, DB **sub_db, int sub_db_type, int\time_db_type, int type)//初始化附加數據庫
{
??
ret =(*primary)-》associate(*primary_db,NULL,*sub_db,get_item_srcip,\
DB_CREATE); //調用Berkeley DB 系統函數將附加數據關聯到主數據庫并設定附加數據庫中的key
??
}
??
4 小結:
本文作者創新點是在項目的開發和實踐過程中,我們分別以不同數量級的記錄寫入關系型數據庫Mysql 和嵌入試數據庫BerkeleyDB,比較發現引入嵌入試數據庫Berkeley DB 大大提高了系統的存儲速度,使存取時間成倍減少。由此看來,嵌入式數據庫Berkeley DB 在處理海量數據存儲上比關系型數據庫贏得了時間和速度上的優勢,但網絡管理性能系統中采集到的信息龐大,如何將Berkeley DB 數據庫中存儲的海量數據進行壓縮仍然是值得探討的問題。











 工商網監
工商網監
評論