 詳解計算機視覺最重要的進展
詳解計算機視覺最重要的進展
最近The M Tank發布了一份對計算機視覺領域最近一年進展的報告《A Year in Computer Vision》,詳述了四大部分的內容,包括分類/定位,目標檢測,目標追蹤等。不管對于初學者還是緊追前沿的研究者,這些都是不可多得的有用資料。
綜述:計算機視覺最重要的進展
計算機視覺通常是指賦予機器視覺的能力,或賦予機器能夠直觀地分析它們的環境和內在的刺激。這個過程通常包括對一個圖像、很多圖像或視頻的評估。英國機器視覺協會(BMVA)將計算機視覺定義為“自動提取、分析和理解來自單個圖像或一系列圖像的有用信息的過程”。
這個定義中的“理解”這個詞說明了計算機視覺的重要性和復雜性。對我們的環境的真正理解不是僅僅通過視覺表現來實現的。相反,視覺信號通過視覺神經傳遞給主視覺皮層,并由大腦來解釋。從這些感官信息中得出的解釋包含了我們的自然編程和主觀體驗的總體,即進化是如何讓我們生存下來,以及我們在生活中對世界的理解。
從這個角度看,視覺僅僅與圖像的傳輸有關;雖然計算機認為圖像與思想或認知更相似,涉及多個大腦區域的協作。因此,許多人認為由于計算機視覺的跨領域性質,對視覺環境及其背景的真正理解能為未來的強人工智能的迭代開拓道路。
然而,我們仍然處于這個迷人的領域的萌芽階段。這份報告的目的是為了讓我們對近年計算機視覺領域一些最重要的進展。盡管我們盡可能寫得簡明,但由于領域的特殊性,可能有些部分讀起來比較晦澀。我們為每個主題提供了基本的定義,但這些定義通常只是對關鍵概念的基本解釋。為了將關注的重點放在2016年的新工作,限于篇幅,這份報告會遺漏一些內容。
其中明顯省略的一個內容是卷積神經網絡(以下簡稱CNN或ConvNet)的功能,因為它在計算機視覺領域無處不在。2012年出現的 AlexNet(一個在ImageNet競賽獲得冠軍的CNN架構)的成功帶來了計算機視覺研究的轉折點,許多研究人員開始采用基于神經網絡的方法,開啟了計算機視覺的新時代。
4年過去了,CNN的各種變體仍然是視覺任務中新的神經網絡架構的主要部分,研究人員像搭樂高積木一樣創造它們,這是對開源信息和深度學習能力的有力證明。不過,解釋CNN的事情最好留給在這方面有更深入的專業知識的人。
對于那些希望在繼續進行之前快速了解基礎知識的讀者,我們推薦下面的參考資料的前兩個。對于那些希望進一步了解的人,以下的資料都值得一看:
深度神經網絡如何看待你的自拍?by Andrej Karpathy 這篇文章能很好地幫助你了解產品和應用背后的CNN技術。
Quora:什么是卷積神經網絡。這個quora問題下的回答有很多很好的參考鏈接和解釋,適合初學者。
CS231n:視覺識別的卷積神經網絡。這是斯坦福大學的一門深度的課程。
《深度學習》(Goodfellow, Bengio & Courville, 2016)第九章對CNN特征和功能提供了詳細的解釋。
對于那些希望更多地了解關于神經網絡和深度學習的讀者,我們推薦:
神經網絡和深度學習(Nielsen,2017),這是一本免費的電子版教科書,它為讀者提供了對于神經網絡和深度學習的復雜性的非常直觀的理解。
我們希望讀者能從這份報告的信息匯總中獲益,無論以往的經驗如何,都可以進一步增加知識。
本報告包括以下部分(限于篇幅,文章省略了參考文獻標識,請至原文查看):
第一部分:分類/定位,目標檢測,目標追蹤
第二部分:分割,超分辨率,自動上色,風格遷移,動作識別
第三部分:3D世界理解
第四部分:卷積網絡架構,數據集,新興應用
第一部分:分類/定位,目標檢測,目標追蹤
分類/定位
涉及到圖像時,“分類”任務通常是指給一個圖像分配一個標簽,例如“貓”。這種情況下,“定位”(locolisation)指的是找到某個對象(object)在圖像中的位置,通常輸出為對象周圍的某種形式的邊界框。當前在ImageNet競賽的圖像分類/定位技術準確性超過一個經訓練的人類。

圖:計算機視覺任務
Source: Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, Lecture 8 - Slide 8, Spatial Localization and Detection (01/02/2016). Available:http://cs231n.stanford.edu/slides/2016/winter1516_...
然而,由于更大的數據集(增加了11個類別)的引入,這很可能為近期的進展提供新的度量標準。在這一點上,Keras的作者Fran?ois Chollet已經在有超過3.5億的多標簽圖像,包含17000個類的谷歌內部數據集應用了新的技術,包括流行的Xception架構。
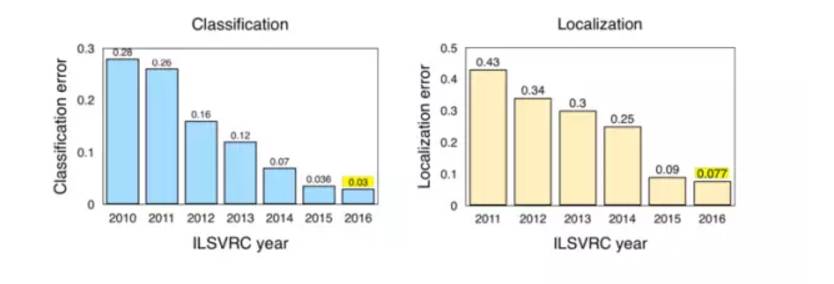
圖:ILSVRC(2010-2016)圖像分類/定位結果
Source: Jia Deng (2016). ILSVRC2016 object localisation: introduction, results. Slide 2.
2016年在ImageNet LSVRC 的一些主要進步:
場景分類(Scene Classification)是指用“溫室”、“體育館”、“大教堂”等特定場景來給圖像貼上標簽的任務。去年,ImageNet 進行了一個場景分類競賽,使用Places2數據集的一個子集:包含800萬張圖片,用365類場景訓練。Hikvision 以 9% top-5 error贏了比賽,利用一個深 Inception-style 網絡,以及一個不特別深的殘差網絡。
Trimps-Soushen以 2.99% 的top-5分類錯誤和7.71%的定位錯誤贏得了ImageNet分類任務。
Facebook的ResNeXt通過使用擴展原始ResNet架構的新架構,以3.03%在top-5 分類錯誤中排名第二。
對象檢測(Object Dection)
對象檢測的過程即檢測圖像中的某個對象。ILSVRC 2016 對對象檢測的定義包括為單個對象輸出邊界框和標簽。這不同于分類/定位任務,分類和定位的應用是多個對象,而不是一個對象。
圖:對象檢測(人臉是該情況需要檢測的唯一一個類別)
Source: Hu and Ramanan (2016, p. 1)
2016年對象檢測的主要趨勢是轉向更快、更高效的檢測系統。這在YOLO、SSD和R-FCN等方法中表現出來,目的是為了在整個圖像上共享計算。因此,這些與計算昂貴的Fast R-CNN和Faster R-CNN相區別。這通常被稱為“端到端訓練/學習”。
其基本原理是避免將單獨的算法集中在各自的子問題上,因為這通常會增加訓練時間,并降低網絡的準確性。也就是說,這種網絡的端到端適應通常是在初始的子網絡解決方案之后進行的,因此,是一種回顧性優化( retrospective optimisation)。當然,Fast R-CNN和Faster R-CNN仍然是非常有效的,并且被廣泛應用于物體檢測。
SSD:Single Shot MultiBox Detector這篇論文利用單個神經網絡來封裝所有必要的計算,它實現了“75.1%的mAP,超越了更先進的R-CNN模型”(Liu et al., 2016)。我們在2016年看到的最令人印象深刻的系統之一是“YOLO9000:Better, Faster, Stronger”,其中介紹了YOLOv2和YOLO9000檢測系統。YOLOv2大大改善了初始的YOLO模型,并且能夠以非常高的FPS獲得更好的結果。除了完成速度之外,系統在特定對象檢測數據集上的性能優于使用ResNet和SSD的Faster-RCNN。
FAIR的Feature Pyramid Networks for Object Detection
R-FCN:Object Detection via Region-based Fully Convolutional Networks
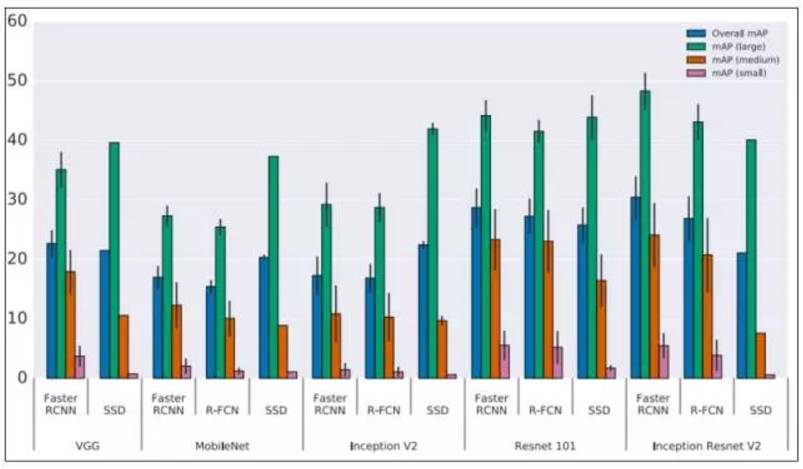
圖:不同架構在對象檢測任務的準確率
Source: Huang et al. (2016, p. 9)
ILSVRC 和 COCO Challenge的結果
COCO(Common Objects in Context)是另一個流行的圖像數據集。不過,它比ImageNet小,也更具有策略性,在更廣泛的場景理解的背景下著重于對象識別。組織者每年都要針對對象檢測,分割和關鍵點組織競賽。 ILSVRC 和COCO 對象檢測挑戰的檢測是:
ImageNet LSVRC Object Detection from Images (DET):CUImage 66% meanAP. Won 109 out of 200 object categories.
ImageNet LSVRC Object Detection from video (VID):NUIST 80.8% mean AP
ImageNet LSVRC Object Detection from video with tracking:CUvideo 55.8% mean AP
COCO 2016 Detection Challenge (bounding boxes):G-RMI (Google) 41.5% AP (4.2% absolute percentage increase from 2015 winner MSRAVC)
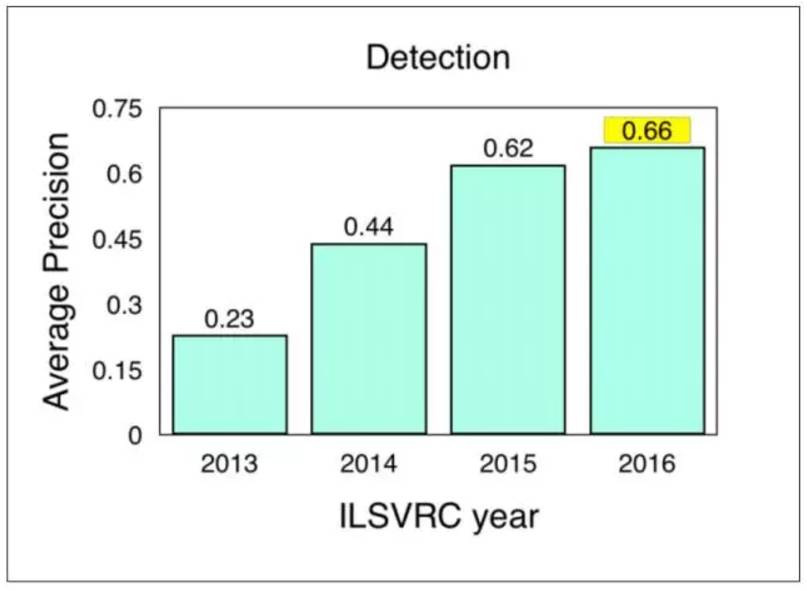
圖:ILSVRC 對象檢測結果(2013-2016)
Source: ImageNet. 2016. [Online] Workshop Presentation, Slide 2. Available:http://image-net.org/challenges/talks/2016/ECCV2016_ilsvrc_coco_detection_segmentation.pdf
對象跟蹤
對象跟蹤(Object Tracking)是指在給定場景中跟蹤特定對象或多個對象的過程。傳統上,它在視頻和現實世界的交互中都有應用,例如,對象跟蹤對自動駕駛系統至關重要。
用于對象跟蹤的全卷積的Siamese網絡(Fully-Convolutional Siamese Networks for Object Tracking)結合了一個基本的跟蹤算法和一個Siamese網絡,經過端到端的訓練,它實現了SOTA,并且可以在幀速率超過實時的情況下進行操作。
利用深度回歸網絡學習以100 FPS跟蹤(Learning to Track at 100 FPS with Deep Regression Networks)是另一篇試圖通過在線訓練方法改善現有問題的論文。作者提出了一種利用前饋網絡的跟蹤器來學習對象運動、外觀和定位的一般關系,從而有效地跟蹤沒有在線訓練的新對象。它提供了SOTA標準跟蹤基準,同時實現了“以100 fps跟蹤通用對象”(Held et al., 2016)。
Deep Motion Features for Visual Tracking綜合了人工特征,deep RGB/外觀特征(來自CNN),以及深度運動特性(在光流圖像上訓練)來實現SOTA。雖然Deep Motion Feature在動作識別和視頻分類中很常見,但作者稱這是第一次使用視覺追蹤技術。這篇論文獲得了2016年ICPR的最佳論文,用于“計算機視覺和機器人視覺”跟蹤。
Virtual Worlds as Proxy for Multi-Object Tracking Analysis,這篇文章在現有的視頻跟蹤基準和數據集中,提出了一種新的現實世界克隆方法,該方法可以從零開始生成豐富的、虛擬的、合成的、逼真的環境,并使用全標簽來克服現有數據集的不足。這些生成的圖像被自動地標記為準確的ground truth,允許包括對象檢測/跟蹤等一系列應用。
全卷積網絡的全局最優對象跟蹤(Globally Optimal Object Tracking with Fully Convolutional Networks),這篇文章解決了對象的變化和遮擋問題,并將它們作為對象跟蹤中的兩個根限制。作者稱,“我們提出的方法利用一個全卷積的網絡解決了對象的外形變化問題,并處理了動態規劃的遮擋問題”(Lee et al., 2016)。
第二部分:分割、 超分辨率/色彩化/風格遷移、 行為識別
計算機視覺的中心就是分割的過程,它將整個圖像分成像素組,然后可以對這些組進行標記和分類。此外,語義分割通過試圖在語義上理解圖像中每個像素的角色是貓,汽車還是其他類型的,又在這一方向上前進了一步。實例分割通過分割不同類的實例來進一步實現這一點,比如,用三種不同顏色標記三只不同的狗。這是目前在自動駕駛技術套件中使用的計算機視覺應用的一大集中點。
也許今年分割領域的一些最好的提升來自FAIR,他們從2015年開始繼續深入研究DeepMask。DeepMask生成粗糙的“mask”作為分割的初始形式。 2016年,Fair推出了SharpMask ,它改進了DeepMask提供的“mask”,糾正了細節的缺失,改善了語義分割。除此之外,MultiPathNet 標識了每個mask描繪的對象。
“為了捕捉一般的物體形狀,你必須對你正在看的東西有一個高水平的理解(DeepMask),但是要準確地描述邊界,你需要再回過去看低水平的特征,一直到像素(SharpMask)。“ - Piotr Dollar,2016
圖:Demonstration of FAIR techniques in action
視頻傳播網絡(Vedio Propagation Network)試圖創建一個簡單的模型來傳播準確的對象mask,在第一幀分配整個視頻序列以及一些附加信息。
2016年,研究人員開始尋找替代網絡配置來解決上述的規模和本地化問題。 DeepLab 就是這樣一個例子,它為語義圖像分割任務取得了令人激動的結果。 Khoreva等人(2016)基于Deeplab早期的工作(大約在2015年),提出了一種弱監督訓練方法,可以獲得與完全監督網絡相當的結果。
計算機視覺通過使用端到端網絡進一步完善了有用信息網絡的共享方式,減少了分類中,多個全向子任務的計算需求。兩個關鍵的論文使用這種方法是:
100 Layers Tiramisu是一個完全卷積的DenseNet,它以前饋的方式將每一層連接到每一層。它還通過較少的參數和訓練/處理在多個基準數據集上實現SOTA。
Fully Convolutional Instance-aware Semantic Segmentation共同執行實例掩碼預測和分類(兩個子任務)。COCO分割挑戰冠軍MSRA。 37.3%AP。比起2015 COCO挑戰賽中的MSRAVC,絕對躍升了9.1%。
雖然ENet是一種用于實時語義分割的DNN體系結構,但它并不屬于這一類別,它證明了降低計算成本和提供更多移動設備訪問的商業價值。
我們的工作希望將盡可能多的這些進步回溯到有形的公開應用。考慮到這一點,以下內容包含2016年一些最有意義的醫療保健應用細分市場:
A Benchmark for Endoluminal Scene Segmentation of Colonoscopy Images
3D fully convolutional networks for subcortical segmentation in MRI: A large-scale study
Semi-supervised Learning using Denoising Autoencoders for Brain Lesion Detection and Segmentation
3D Ultrasound image segmentation: A Survey
A Fully Convolutional Neural Network based Structured Prediction Approach Towards the Retinal Vessel Segmentation
3-D Convolutional Neural Networks for Glioblastoma Segmentation
我們最喜歡的準醫學分割應用之一是FusionNet——一個深度全卷積神經網絡,用于連接組學的圖像分割,基于SOTA電子顯微鏡(EM)分割方法。
超分辨率、風格遷移和著色
并非計算機視覺領域的所有研究都是為了擴展機器的偽認知能力,而且神經網絡的神話般的可塑性以及其他ML技術常常適用于各種其他新穎的應用,這些應用可以滲透到公共空間中。超分辨率方案,風格轉移和著色去年的進步占據了整個領域。
超分辨率指的是從低分辨率對應物估計高分辨率圖像的過程,以及不同放大倍數下圖像特征的預測,這是人腦幾乎毫不費力地完成的。最初的超分辨率是通過簡單的技術,如bicubic-interpolation和最近鄰。在商業應用方面,克服低分辨率限制和實現“CSI Miami”風格圖像增強的愿望推動了該領域的研究。以下是今年的一些進展及其潛在的影響:
Neural Enhance是Alex J. Champandard的創意,結合四篇不同研究論文的方法來實現超分辨率方法。
實時視頻超分辨率解決方案也在2016年進行了兩次著名的嘗試。
RAISR:來自Google的快速而準確的圖像超分辨率方法。通過使用低分辨率和高分辨率圖像對訓練濾波器,避免了神經網絡方法的昂貴內存和速度要求。作為基于學習的框架,RAISR比同類算法快兩個數量級,并且與基于神經網絡的方法相比,具有最小的存儲器需求。因此超分辨率可以擴展到個人設備。
生成對抗網絡(GAN)的使用代表了當前用于超分辨率的SOTA:
SRGAN通過訓練區分超分辨率和原始照片真實圖像的辨別器網絡,在公共基準測試中提供多采樣圖像的逼真紋理。
盡管SRResNet在峰值信噪比(PSNR)方面的表現最佳,但SRGAN獲得更精細的紋理細節并達到最佳的平均評分(MOS),SRGAN表現最佳。
“據我們所知,這是第一個能夠推出4倍放大因子的照片般真實的自然圖像的框架。”以前所有的方法都無法在較大的放大因子下恢復更精細的紋理細節。
Amortised MAP Inference for Image Super-resolution提出了一種使用卷積神經網絡計算最大后驗(MAP)推斷的方法。但是,他們的研究提出了三種優化方法,GAN在其中實時圖像數據上表現明顯更好。
毫無疑問,Style Transfer集中體現了神經網絡在公共領域的新用途,特別是去年的Facebook集成以及像Prisma 和Artomatix 這樣的公司。風格轉換是一種較舊的技術,但在2015年出版了一個神經算法的藝術風格轉換為神經網絡。從那時起,風格轉移的概念被Nikulin和Novak擴展,并且也被用于視頻,就像計算機視覺中其他的共同進步一樣。
圖:風格遷移的例子
風格轉換作為一個主題,一旦可視化是相當直觀的,比如,拍攝一幅圖像,并用不同的圖像的風格特征呈現。例如,以著名的繪畫或藝術家的風格。今年Facebook發布了Caffe2Go,將其深度學習系統整合到移動設備中。谷歌也發布了一些有趣的作品,試圖融合多種風格,生成完全獨特的圖像風格。
除了移動端集成之外,風格轉換還可以用于創建游戲資產。我們團隊的成員最近看到了Artomatix的創始人兼首席技術官Eric Risser的演講,他討論了該技術在游戲內容生成方面的新穎應用(紋理突變等),因此大大減少了傳統紋理藝術家的工作。
著色
著色是將單色圖像更改為新的全色版本的過程。最初,這是由那些精心挑選的顏色由負責每個圖像中的特定像素的人手動完成的。2016年,這一過程自動化成為可能,同時保持了以人類為中心的色彩過程的現實主義的外觀。雖然人類可能無法準確地表現給定場景的真實色彩,但是他們的真實世界知識允許以與圖像一致的方式和觀看所述圖像的另一個人一致的方式應用顏色。
著色的過程是有趣的,因為網絡基于對物體位置,紋理和環境的理解(例如,圖像)為圖像分配最可能的著色。它知道皮膚是粉紅色,天空是藍色的。
“而且,我們的架構可以處理任何分辨率的圖像,而不像現在大多數基于CNN的方法。”
在一個測試中,他們的色彩是多么的自然,用戶從他們的模型中得到一個隨機的圖像,并被問到,“這個圖像看起來是自然的嗎?
他們的方法達到了92.6%,基線達到了大約70%,而實際情況(實際彩色照片)被認為是自然的97.7%。
行為識別
行為識別的任務是指在給定的視頻幀內動作的分類,以及最近才出現的,用算法預測在動作發生之前幾幀的可能的相互作用的結果。在這方面,我們看到最近的研究嘗試將上下文語境嵌入到算法決策中,類似于計算機視覺的其他領域。這個領域的一些關鍵論文是:
Long-term Temporal Convolutions for Action Recognition利用人類行為的時空結構,即特定的移動和持續時間,以使用CNN變體正確識別動作。為了克服CNN在長期行為的次優建模,作者提出了一種具有長時間卷積(LTC-CNN)的神經網絡來提高動作識別的準確性。簡而言之,LTC可以查看視頻的較大部分來識別操作。他們的方法使用和擴展了3D CNN,以便在更充分的時間尺度上進行行動表示。
“我們報告了人類行為識別UCF101(92.7%)和HMDB51(67.2%)兩個具有挑戰性的基準的最新成果。
用于視頻動作識別的時空殘差網絡將兩個流CNN的變體應用于動作識別的任務,該任務結合了來自傳統CNN方法和最近普及的殘留網絡(ResNet)的技術。這兩種方法從視覺皮層功能的神經科學假設中獲得靈感,即分開的路徑識別物體的形狀/顏色和運動。作者通過注入兩個CNN流之間的剩余連接來結合ResNets的分類優勢。
Anticipating Visual Representations from Unlabeled Video[89]是一個有趣的論文,盡管不是嚴格的行為分類。該程序預測了在一個動作之前一個視頻幀序列可能發生的動作。該方法使用視覺表示而不是逐像素分類,這意味著程序可以在沒有標記數據的情況下運行,利用深度神經網絡的特征學習特性。
Thumos Action Recognition Challenge 的組織者發表了一篇論文,描述了最近幾年來Action Action Recognition的一般方法。本文還提供了2013-2015年挑戰的概要,以及如何通過行動識別讓計算機更全面地了解視頻的挑戰和想法的未來方向。
第三部分 走向理解3D世界
在計算機視覺中,正如我們所看到的,場景,對象和活動的分類以及邊界框和圖像分割的輸出是許多新研究的重點。實質上,這些方法應用計算來獲得圖像的二維空間的“理解”。然而,批評者指出,3D理解對于解釋系統成功和現實世界導航是必不可少的。
例如,一個網絡可能會在圖像中找到一只貓,為它的所有像素著色,并將其歸類為一只貓。但是,在貓所處的環境中,網絡是否完全理解圖像中貓的位置?
有人認為,從上述任務中,計算機對于3D世界的了解很少。與此相反,即使在看2D圖片(即,透視圖,遮擋,深度,場景中的對象如何相關)等情況下,人們也能夠以3D來理解世界。將這些3D表示及其相關知識傳遞給人造系統代表了下一個偉大計算機視覺的前沿。一般認為這樣做的一個主要原因是:
“場景的2D投影是構成場景的相機,燈光和物體的屬性和位置的復雜功能的組合。如果賦予3D理解,智能體可以從這種復雜性中抽象出來,形成穩定的,不受限制的表示,例如,認識到在不同的光照條件下,或者在部分遮擋下,是從上面或從側面看的椅子。“
但是,3D理解傳統上面臨著幾個障礙。首先關注“自我和正常遮擋”問題以及適合給定2D表示的眾多3D形狀。由于無法將相同結構的不同圖像映射到相同的3D空間以及處理這些表示的多模態,所以理解問題變得更加復雜。最后,實況3D數據集傳統上相當昂貴且難以獲得,當與表示3D結構的不同方法結合時,可能導致訓練限制。
我們認為,在這個領域進行的工作很重要,需要注意。從早期的AGI系統和機器人技術的早期理論應用,到在不久的將來會影響我們社會,盡管還在萌芽期,由于利潤豐厚的商業應用,我們謹慎地預測這一計算機視覺領域的指數級增長,這意味著計算機很快就可以開始推理世界,而不僅僅是像素。
OctNet: Learning Deep 3D Representations at High Resolutions
ObjectNet3D: A Large Scale Database for 3D Object Recognition
3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction
3D Shape Induction from 2D Views of Multiple Objects
Unsupervised Learning of 3D Structure from Images
人類姿勢預估和關鍵點監測
人體姿勢估計試圖找出人體部位的方向和構型。 2D人體姿勢估計或關鍵點檢測一般是指定人體的身體部位,例如尋找膝蓋,眼睛,腳等的二維位置。
然而,三維姿態估計通過在三維空間中找到身體部位的方向來進一步進行,然后可以執行形狀估計/建模的可選步驟。這些分支已經有了很大的改進。
在過去的幾年中,在競爭性評估方面,“COCO2016挑戰包括同時檢測人和本地化關鍵點”。 ECCV 供了有關這些主題的更多的文獻,但是我們想強調以下幾篇論文:
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image
重構
如前所述,前面的部分介紹了重構的一些例子,但總的來說重點是物體,特別是它們的形狀和姿態。雖然其中一些在技術上是重構的,但是該領域本身包括許多不同類型的重構,例如,場景重構,多視點和單視點重建,運動結構(SfM),SLAM等。此外,一些重構方法利用附加(和多個)傳感器和設備,例如事件或RGB-D攝像機,多種技術來推動進步。
結果?整個場景可以非剛性地重建并且在時空上改變,例如,對你自己的高保真重構,以及你的動作進行實時更新。
如前所述,圍繞2D圖像映射到3D空間的問題持續存在。以下文章介紹了大量創建高保真實時重建的方法:
Fusion4D: Real-time Performance Capture of Challenging Scenes
Real-Time 3D Reconstruction and 6-DoF Tracking with an Event Camera
Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue
其他未分類3D
IM2CA
Learning Motion Patterns in Videos
Deep Image Homography Estimation
gvnn: Neural Network Library for Geometric Computer Vision
3D summation and SLAM
在整個這一節中,我們在3D理解領域進行了一個橫切面似的介紹,主要側重于姿態估計,重構,深度估計和同形目錄。但是,還有更多的精彩的工作被我們忽略了,我們在數量上受到限制。所以,我們希望給讀者提供一個寶貴的出發點。
大部分突出顯示的作品可能被歸類于幾何視覺,它通常涉及從圖像直接測量真實世界的數量,如距離,形狀,面積和體積。我們的啟發是基于識別的任務比通常涉及幾何視覺中的應用程序更關注更高級別的語義信息。但是,我們經常發現,這些3D理解的不同領域大部分是密不可分的。
最大的幾何問題之一是SLAM,研究人員正在考慮SLAM是否會成為深度學習所面臨的下一個問題。所謂“深度學習的普遍性”的懷疑論者,其中有很多都指出了SLAM作為算法的重要性和功能性:
“視覺SLAM算法能夠同時建立世界三維地圖,同時跟蹤攝像機的位置和方向。” SLAM方法的幾何估計部分目前不適合深度學習方法,所以端到端學習不太可能。 SLAM代表了機器人中最重要的算法之一,并且是從計算機視覺領域的大量輸入設計的。該技術已經在Google Maps,自動駕駛汽車,Google Tango 等AR設備,甚至Mars Luver等應用。
第四部分:卷積架構、數據集、新興應用
ConvNet架構最近在計算機視覺之外發現了許多新穎的應用程序,其中一些應用程序將在我們即將發布的論文中出現。然而,他們繼續在計算機視覺領域占有突出的地位,架構上的進步為本文提到的許多應用和任務提供了速度,準確性和訓練方面的改進。
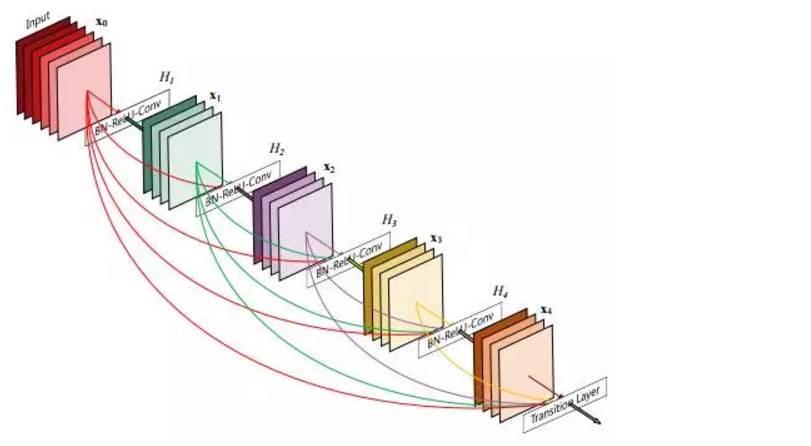
圖:DenseNet架構
基于這個原因,ConvNet體系結構對整個計算機視覺至關重要。以下是2016年以來一些值得關注的ConvNet架構,其中許多從ResNets最近的成功中獲得靈感。
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Densely Connected Convolutional Networks
FractalNet Ultra-Deep Neural Networks without Residuals
Lets keep it simple: using simple architectures to outperform deeper architectures
Swapout: Learning an ensemble of deep architectures
SqueezeNet
Concatenated Rectified Linear Units (CRelu)
Exponential Linear Units (ELUs)
Parametric Exponential Linear Unit (PELU)
Harmonic CNNs
Exploiting Cyclic Symmetry in Convolutional Neural Networks
Steerable CNNs
殘差網絡(Residual Networks)
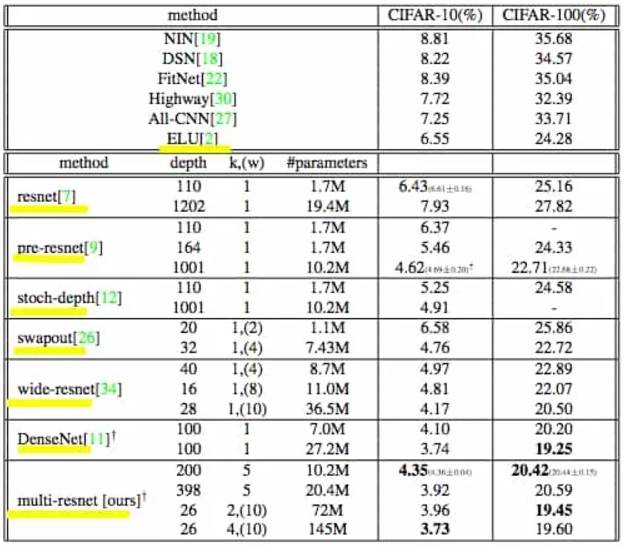
圖:Test-Error Rates on CIFAR Datasets
隨著微軟ResNet的成功,Residual Networks及其變體在2016年變得非常受歡迎,現在提供了許多開源版本和預訓練模型。在2015年,ResNet在ImageNet的檢測,本地化和分類任務以及COCO的檢測和分段挑戰中獲得了第一名。雖然深度問題仍然存在,但ResNet處理梯度消失的問題為“深度增加產生超級抽象”提供了更多的動力,這是目前深度學習的基礎。
ResNet通常被概念化為一個較淺的網絡集合,它通過運行平行于其卷積層的快捷連接來抵消深度神經網絡(DNN)的層次性。這些快捷方式或跳過連接可減輕與DNN相關的消失/爆炸梯度問題,從而允許在網絡層中更容易地反向傳播梯度。
殘差學習、理論與進展
Wide Residual Networks
Deep Networks with Stochastic Depth
Learning Identity Mappings with Residual Gates
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
Identity Mappings in Deep Residual Networks
Multi-Residual Networks: Improving the Speed and Accuracy of Residual Networks
Highway and Residual Networks learn Unrolled Iterative Estimation
Residual Networks of Residual Networks: Multilevel Residual Networks
Resnet in Resnet: Generalizing Residual Architectures
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex
Convolutional Residual Memory Networks
Identity Matters in Deep Learning
Deep Residual Networks with Exponential Linear Unit
Weighted Residuals for Very Deep Networks
數據集
Places2
SceneNet RGB-D
CMPlaces
MS-Celeb-1M
Open Images
YouTube-8M
一些用例和趨勢
來自Facebook的盲人應用程序和百度的硬件
情感檢測結合了面部檢測和語義分析,并且正在迅速增長。目前有20多個API可用。
從航空影像中提取道路,從航空地圖和人口密度地圖中分類土地。
盡管目前還存在一些功能性問題,但Amazon Go進一步提高了計算機視覺的形象,證明了無排隊的購物體驗。
對于我們基本上沒有提到無人駕駛,我們做了大量的工作。然而,對于那些希望深入研究一般市場趨勢的人來說,莫里茨·穆勒 - 弗雷塔格(Moritz Mueller-Freitag)就德國汽車工業和自動駕駛汽車的影響作了精彩的介紹。
其他有趣的領域:圖像檢索/搜索,手勢識別,修復和面部重建。
數字成像與醫學通訊(DICOM)和其他醫學應用(特別是與成像相關的)。例如,有許多Kaggle檢測競賽(肺癌,宮頸癌),其中一些有較大的金錢誘因,其中的算法試圖在分類/檢測任務中勝過專家。
硬件和市場
機器人視覺/機器視覺(獨立領域)和物聯網的潛在目標市場不斷壯大。我們個人最喜歡的是一個日本的農民的孩子使用深度學習,樹莓派和TensorFlow對黃瓜形狀,大小和顏色進行分類。這使他的母親分揀黃瓜所花的人力時間大大減少。
計算需求的縮減和移動到移動的趨勢是顯而易見的,但是它也是通過硬件加速來實現的。很快我們會看到口袋大小的CNN和視覺處理單元(VPUs)到處都是。例如,Movidius Myriad2被谷歌的Project Tango和無人機所使用。
Movidius Fathom 也使用了Myriad2的技術,允許用戶將SOTA計算機視覺性能添加到消費類設備中。具有USB棒的物理特性的Fathom棒將神經網絡的能力帶到幾乎任何設備:一根棒上的大腦。
傳感器和系統使用可見光以外的東西。例子包括雷達,熱像儀,高光譜成像,聲納,磁共振成像等。
LIDAR的成本降低,它使用光線和雷達來測量距離,與普通的RGB相機相比具有許多優點。目前有不少于500美元的LIDAR設備。
Hololens和近乎無數的其他增強現實頭盔進入市場。
Google的Project Tango 代表了SLAM的下一個大型商業化領域。 Tango是一個增強現實計算平臺,包含新穎的軟件和硬件。 Tango允許在不使用GPS或其他外部信息的情況下檢測移動設備相對于世界的位置,同時以3D形式繪制設備周圍的區域。
Google合作伙伴聯想于2016年推出了價格適中的Tango手機,允許數百名開發人員開始為該平臺創建應用程序。 Tango采用以下軟件技術:運動跟蹤,區域學習和深度感知。
與其他領域結合的前沿研究:
唇語
生成模型
結論
總之,我們想突出一些在我們的研究回顧過程中反復出現的趨勢和反復出現的主題。首先,我們希望引起人們對機器學習研究社區極度追求優化的關注。這是最值得注意的,體現在這一年里精確率的不斷提升。
錯誤率不是唯一的狂熱優化參數,研究人員致力于提高速度、效率,甚至算法能夠以全新的方式推廣到其他任務和問題。我們意識到這是研究的前沿,包括one-shot learning、生成模型、遷移學習,以及最近的evolutionary learning,我們認為這些研究原則正逐漸產生更大的影響。
雖然這最后一點毫無疑問是值得稱贊的,而不是對這一趨勢的貶低,但人們還是禁不住要把他們的注意力放在(非常)的通用人工智能。我們只是希望向專家和非專業人士強調,這一擔憂源自于此,來自計算機視覺和其他人工智能領域的驚人進展。通過對這些進步及其總體影響的教育,可以減少公眾不必要的擔憂。這可能會反過來冷卻媒體的情緒和減少有關AI的錯誤信息。
出于兩個原因,我們選擇專注于一年的時間里的進展。第一個原因與這一領域的新工作數量之大有關。即使對那些密切關注這一領域的人來說,隨著出版物數量呈指數級的增長,跟上研究的步伐也變得越來越困難。第二個原因,讓我們回頭看看這一年內的變化。
在了解這一年的進展的同時,讀者可以了解目前的研究進展。在這么短的時間跨度里,我們看到了這么多的進步,這是如何得到的?研究人員形成了以以前的方法(架構、元架構、技術、想法、技巧、結果等)和基礎設施(Keras、TensorFlow、PyTorch、TPU等)的全球社區,這不禁值得鼓勵,也值得慶祝。很少有開源社區像這樣不斷吸引新的研究人員,并將它的技術應用于經濟學、物理學和其他無數領域。
對于那些尚未注意到的人來說,理解這一點非常重要,即在許多不同聲音中,宣稱對這種技術的本質有理解,至少有共識,認同這項技術將以新的令人興奮的方式改變世界。然而,在這些改變實現之前,仍存在許多分歧。
我們將繼續盡最大的努力提供信息。有了這樣的資源,我們希望滿足那些希望跟蹤計算機視覺和人工智能的進展的人的需求,我們的項目希望為開源革命增添一些價值,而這個革命正在技術領域悄然發生。
*推薦文章*
【ICCV2017論文技術解讀】阿里-基于層次化多模態LSTM的視覺語義聯合嵌入
NIPS 2017論文深度離散哈希算法,可用于圖像檢索
原文標題:計算機視覺這一年:這是最全的一份CV技術報告
文章出處:【微信公眾號:ADAS】歡迎添加關注!文章轉載請注明出處。
-
3D
+關注
關注
9文章
2953瀏覽量
109914 -
人工智能
+關注
關注
1804文章
48788瀏覽量
246913 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46594
發布評論請先 登錄
什么是計算機視覺?計算機視覺的三種方法

計算機最重要的特點是什么

基于計算機視覺的多維圖像智能
計算機視覺中的重要研究方向
計算機視覺為何重要?
計算機視覺的十大算法






 工商網監
工商網監
評論