") 關于智能MCU的性能分析介紹
關于智能MCU的性能分析介紹
隨著人工智能和物聯(lián)網(wǎng)技術的發(fā)展,我們看到智能設備正在加速普及。我們的身邊,漸漸地有智能音箱、早教機器人、掃地機器人等新智能設備品類出現(xiàn),同時在智能工業(yè)、智能城市和智能零售等領域,智能化的腳步也在向前進展。我們看到,在這樣的發(fā)展趨勢下,傳統(tǒng)的MCU芯片也在發(fā)生著深刻的變化,在向智能化的方向發(fā)展。
智能物聯(lián)網(wǎng)與MCU智能化
這一波人工智能的興起起源于大數(shù)據(jù)和深度學習。隨著互聯(lián)網(wǎng)的發(fā)展,人類社會產生了大量數(shù)據(jù),而大數(shù)據(jù)配合深度神經網(wǎng)絡等算法可以訓練出一些精度極高的機器學習模型,從而能撬動人臉識別,自動駕駛,語音識別等新應用。基于大數(shù)據(jù)的人工智能中,終端節(jié)點負責采集數(shù)據(jù)并且交給云端,云端服務器反復迭代訓練高精度模型,并最終將這些模型部署到應用中。應當說數(shù)據(jù)采集和模型訓練的任務分別在終端和云端做目前得到了一致認可,但是具體部署的機器學習模型在何處執(zhí)行在不同的應用中卻有所不同。
有些應用(如攝像頭內容分析)的模型部署在云端,即終端把原始數(shù)據(jù)完全回傳給云端,云端在該數(shù)據(jù)上執(zhí)行深度學習模型的推理,之后把結果發(fā)回給終端,終端再根據(jù)云端的結果執(zhí)行相應操作;而在自動駕駛等應用中模型必須部署在終端,即終端收集到數(shù)據(jù)后在本地執(zhí)行深度學習模型的推理,并根據(jù)結果作出相應動作。在智能工業(yè)等需要在終端執(zhí)行深度學習模型推理的場景,原來用來執(zhí)行相關動作的MCU就必須能夠支持這樣的深度學習推理計算,這也就是MCU的智能化。

通常來說,機器學習模型必須部署在終端執(zhí)行的理由包括傳輸帶寬、反應延遲和安全性等。從傳輸帶寬來考慮,目前物聯(lián)網(wǎng)中節(jié)點分布在各種場景中,如果要把原始數(shù)據(jù)直接傳輸?shù)皆贫耍瑒t帶寬開銷非常大,而且無線傳輸?shù)哪芰块_銷也不小。而如果在終端部署機器學習推理則可以省下帶寬的開銷,只需要有選擇性地把部分重要數(shù)據(jù)傳送到云端,而無需傳輸全部原始數(shù)據(jù)。
反應延遲也是把深度學習部署在終端的重要理由。目前數(shù)據(jù)到云端的來回傳送時間通常在數(shù)百毫秒級,對于工業(yè)機器人等對于延遲有高要求的應用來說無法滿足要求。即使在5G低延遲網(wǎng)絡下,無線網(wǎng)絡的可靠性對于智能工業(yè)等要求高可靠性的應用來說也難以滿足需求,偶爾的高延遲甚至數(shù)據(jù)丟包都可能會造成要求即時反應的機器發(fā)生問題,因此會傾向于選擇將深度學習推理的計算放在本地做。
最后,數(shù)據(jù)的安全性也是一個考量,對于一些敏感應用來說將數(shù)據(jù)通過網(wǎng)絡傳送給云端服務器意味著存在著數(shù)據(jù)被入侵的風險——如果黑客通過破解智能工廠與云端服務器的數(shù)據(jù)從而控制整個工廠將會給工廠帶來巨大損失——而如果把這些計算放在本地則會安全地多。
根據(jù)上述的場景,我們認為需要執(zhí)行本地機器學習推理計算的MCU主要會運行在如下場景中:
-智能生產,需要快速反應且重視數(shù)據(jù)的安全性,如根據(jù)聲音識別機器故障等;
-小型機器人,沒有人會希望機器人一旦斷網(wǎng)就無法工作,如無人機,掃地機器人等;
-智能家電,如智能空調根據(jù)人的位置智能送風等;
-智能可穿戴設備,如根據(jù)人體的生理信號給出相應提示等。
隨著上述在終端部署執(zhí)行機器學習推理計算的需求,一些原來只負責執(zhí)行基本程序的MCU也必須要有能力能跑動機器學習推理計算。這對于MCU的挑戰(zhàn)在于算力,因為在這一波人工智能的浪潮中,訓練好的模型所需要的計算量通常是數(shù)十萬次計算到數(shù)億次計算不等,如果需要實時執(zhí)行這些運算則MCU需要的算力將會比原來的MCU強幾個數(shù)量級。
另外,智能MCU對功耗和實時性也有很高要求,這就需要MCU設計能有相應改變。目前,MCU正處于8位更新?lián)Q代到32位的過程中,我們預計在32位MCU的基礎上,智能化會成為下一個MCU的演進方向。

智能化技術路徑一:整合加速器IP
目前MCU領域,ARM占據(jù)了領導者的地位,其IP占據(jù)了大量的市場份額。對于智能化MCU的興起,ARM自然也不會袖手旁觀,而是起到了推動者的作用,幫助MCU實現(xiàn)智能化。
ARM的Cortex系列架構占據(jù)著32位MCU的主導位置,所以ARM推進智能MCU的方法需要兼顧其Cortex架構,不能為了推智能化MCU結果把自己的命給革了。因此,ARM選擇的方法是給Cortex核搭配一個獨立的加速器IP,當需要執(zhí)行機器學習相關算法時調用這個加速器IP去做計算,而當做傳統(tǒng)操作時還是使用Cortex。
ARM的機器學習加速器系列產品即Project Trillium,其中包括了機器學習處理器(ML Processor),物體檢測處理器等硬件IP,同時還包括可以在這些加速器以及Cortex核和Mali GPU上最優(yōu)化執(zhí)行相關算法的軟件棧ARM NN。以ARM ML Processor為例(如下圖),其架構包含了用于加速專用函數(shù)的加速引擎Fixed-function Engine,用于加速神經網(wǎng)絡的可編程層引擎Programmable Layer Engine,片上內存,用于控制加速器執(zhí)行的網(wǎng)絡控制單元以及用于訪問片外內存的DMA。
ARM ML Processor是典型的加速器架構,它有自己的指令集,只能執(zhí)行和機器學習相關的運算加速而無法運行其他程序,因此必須搭配Cortex核才能發(fā)揮作用。ARM ML Processor可以最高實現(xiàn)4.6TOPS的算力,同時最高能效比可達3TOPS/W,性能實屬優(yōu)秀,對于算力需求不高的場合也可以通過降低運行速度來降低功耗,以滿足MCU的需求。

除了ARM之外,其他MCU巨頭也在紛紛布局AI加速器,其中意法半導體屬于技術領先的位置。在去年,意法發(fā)布了其用于超低功耗MCU的專用卷積神經網(wǎng)絡加速器,代號為Orlando Project,在28nm FD-SOI上可以實現(xiàn)2.9TOPS/W的超高能效比,相信隨著技術和市場需求的進一步需求將會轉為商用化。
應該說目前基于專用機器學習加速器IP的智能MCU尚處于蓄勢待發(fā)階段。顧名思義,專用機器學習加速器通過專用化的設計實現(xiàn)了很高的能效比,然而這也限制了應用范圍,只能加速一部分機器學習算法,而無法顧及通用性。
目前,機器學習加速器最主要的加速對象算法是神經網(wǎng)絡算法,尤其是卷積神經網(wǎng)絡。從技術上說,卷積神經網(wǎng)絡在執(zhí)行過程中并行度高,存在加速空間,一個加速器相比傳統(tǒng)處理器往往能把神經網(wǎng)絡的執(zhí)行速度和能效比提升幾個數(shù)量級。從人工智能的發(fā)展脈絡來看,這一波人工智能中最成功的應用也是基于卷積神經網(wǎng)絡的機器視覺應用,因此大家都專注于卷積神經網(wǎng)絡的加速也是順理成章。
然而,對于MCU來說,專注于卷積神經網(wǎng)絡加速卻未必是一個最優(yōu)化的選擇。首先,MCU市場的應用存在一定碎片化,而一個專用的加速器很難覆蓋多個應用,因此對于習慣了設計標準化MCU并走量覆蓋許多個市場的半導體廠商來說是否使用專用化加速器是一個需要仔細考慮的選擇。換句話說,許多應用中希望智能MCU能高效執(zhí)行基于非卷積神經網(wǎng)絡的機器學習算法(例如SVM,決策樹等等),那么這些應用就無法被一個專用的卷積神經網(wǎng)絡加速器覆蓋到,而需要設計另外一套加速器。當然,這對于IP商ARM來說不是件壞事,因為ARM可以快速提升其機器學習加速器的IP品類數(shù)量并從中獲利,但是對于半導體公司來說卻有些頭疼。
此外,卷積神經網(wǎng)絡最成功的應用是機器視覺,然而在MCU應用中除了機器視覺之外還有許多其他應用,甚至可以說智能MCU的應用中機器視覺并非最大的市場,這也限制了只能處理卷積神經網(wǎng)絡的專用加速器IP的市場。
智能化路徑二:處理器架構改良
根據(jù)上面的討論,ARM因為之前使用Cortex核占領了MCU市場,因此其保留Cortex架構不變并力推能搭配Cortex核使用的專用加速器IP也是必然的商業(yè)邏輯。然而,基于專用機器學習加速器IP的智能MCU在碎片化應用中會遇到應用覆蓋過窄的問題,這也就是為什么還存在第二條MCU智能化的技術路徑——改良處理器架構。
處理器架構改良意味著直接設計一個低功耗高算力的通用處理器,這樣就可以覆蓋幾乎所有MCU應用,從而避免了專用加速器的通用性問題。當然,在處理器設計中,往往需要從指令集開始全盤重新設計,因此需要很大的投入。
根據(jù)半導體行業(yè)的傳統(tǒng),從頭設計一套新的自有指令集往往是吃力而不討好,因為指令集的設計、驗證、可擴展性考慮等等往往不是一個團隊就能完成的,而是需要大量人長時間的努力。然而,最近隨著RISC-V開源指令集得到越來越多的認可,使用基于RISC-V指令集去做新處理器架構可以大大節(jié)省指令集和架構開發(fā)的成本以及風險。RISC-V指令集經過開源社區(qū)的認證,已經證明非常靠譜,可以無需從頭造輪子,而只需要把精力集中在需要改良的部分,因此在這個時間點做新處理器架構可謂是正逢其時。
使用新架構做智能MCU的代表公司是來自法國的初創(chuàng)公司Greenwaves Technologies。Greenwaves正是使用了基于RISC-V的指令集,同時在架構上在MCU中也引入了多核的概念,通過多數(shù)據(jù)流(SIMD)的方式來加速人工智能算法中的并行計算,可謂是MCU架構上的一個革新。

目前,Greenwaves的第一款產品GAP8已經處于出樣階段。根據(jù)網(wǎng)站資料,GAP8擁有8個核,可以在數(shù)十毫瓦的功耗下實現(xiàn)8GOPS的算力,該算力已經能滿足許多智能MCU的需求。更關鍵的是,由于GAP8使用的是多核通用處理器而非專用加速器去加速人工智能算法,因此其可以通用性非常好,可以覆蓋各種算法以及應用。在應用存在碎片化的MCU市場,這無疑是一個很大的優(yōu)勢。由于使用的是通用處理器,GAP8的能效比相對于ARM的專用加速器在特定的領域較弱,但是GAP8的通用性卻是ARM的專用加速器無法企及的。
另外值得指出的是,新處理器架構和專用加速器并非水火不容,完全可以在使用新處理器架構的同時集成一個專用加速器,從而使用專用加速器去加速特定的應用,而使用通用化的新架構處理器去處理高效處理其他應用。這里專用與通用的選擇完全則很大程度上取決于市場的需求以及潛在的商業(yè)回報。
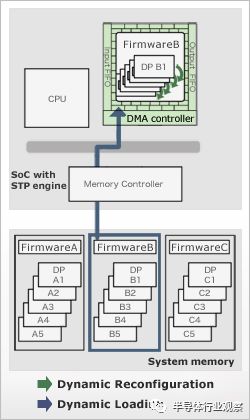
除了Greenwaves之外,瑞薩也推出了類似的新處理器架構。與Greenwaves略有不同的是,瑞薩并不是做一個新的通用處理器架構,而是做了一個可配置的協(xié)處理器,該協(xié)處理器可以使用高級語言(如C/C++)編程,在不同的應用場景可以配置為不同的架構,從而兼顧了通用性和專用性。瑞薩將該架構稱作為動態(tài)可重構處理器(Dynamic Reconfigurable Processor, DRP),該架構之前已經在瑞薩的視頻處理器中已經得到了驗證,現(xiàn)在瑞薩準備將該架構也搬到MCU中,并將在今年十月正式發(fā)布第一代集成DRP的MCU。
結語
人工智能和物聯(lián)網(wǎng)的結合推進了智能MCU概念。我們預計在未來幾年將會看到智能MCU的普及,而在智能MCU的兩條技術路徑之間選擇則不僅會影響MCU市場,更有可能會對于半導體生態(tài)造成深遠影響——如果專用加速器IP獲勝,則ARM將繼續(xù)成為智能MCU的領導者,反之如果新架構獲勝則ARM將會遇到強力的挑戰(zhàn)。
-
處理器
+關注
關注
68文章
19488瀏覽量
231560 -
物聯(lián)網(wǎng)
+關注
關注
2914文章
45072瀏覽量
378597 -
人工智能
+關注
關注
1799文章
47967瀏覽量
241313
發(fā)布評論請先 登錄
相關推薦
基于雙核MCU提高系統(tǒng)性能
介紹的是高性能MCU之人工智能物聯(lián)網(wǎng)應用開發(fā)相關知識
介紹的是i.MX RTyyyy系列MCU的性能
什么是MCU?MCU市場現(xiàn)狀分析
關于MEMS的性能分析和介紹
關于GD32 MCU的性能分析和應用介紹
關于GD32 MCU助力IEC60730-1的性能分析和介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論