 騰訊優圖10篇論文入選人工智能頂級會議AAAI
騰訊優圖10篇論文入選人工智能頂級會議AAAI

人工智能領域的國際頂級會議AAAI 2020將于2月7日-2月12日在美國紐約舉辦。近年來隨著人工智能的興起,AAAI每年舉辦的學術會議也變得越來越火熱,每年都吸引了大量來自學術界、產業界的研究員、開發者投稿、參會。
以AAAI2019為例,論文提交數量高達7745篇,創下當年AAAI歷史新高。和其他頂會一樣,AAAI 2020顯得更為火熱,大會官方發送的通知郵件顯示,最終收到有效論文8800篇,接收1591篇,接受率僅為20.6%。
作為人工智能領域最悠久、涵蓋內容最廣泛的學術會議之一,會議的論文內容涉及AI和機器學習所有領域,關注的傳統主題包括但不限于自然語言處理、深度學習等,同時大會還關注跨技術領域主題,如AI+行業應用等。
此次騰訊優圖實驗室共計入選10篇論文,涉及速算批改、視頻識別等。
以下為具體解讀
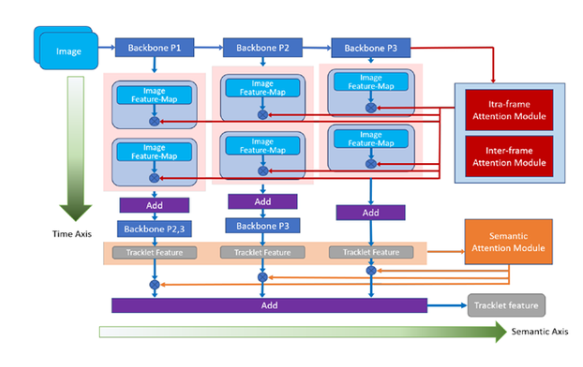
1.從時間和語義層面重新思考時間域融合用于基于視頻的行人重識別(Oral)
Rethinking Temporal Fusion for Video-basedPerson Re-identification on Semantic and Time Aspect (Oral)
關鍵詞:行人重識別、時間和語義、時間融合
下載鏈接:https://arxiv.org/abs/1911.12512
近年來對行人重識別(ReID)領域的研究不斷深入,越來越多的研究者開始關注基于整段視頻信息的聚合,來獲取人體特征的方法。然而,現有人員重識別方法,忽視了卷積神經網絡在不同深度上提取信息在語義層面的差別,因此可能造成最終獲取的視頻特征表征能力的不足。此外,傳統方法在提取視頻特征時沒有考慮到幀間的關系,導致時序融合形成視頻特征時的信息冗余,和以此帶來的對關鍵信息的稀釋。
為了解決這些問題,本文提出了一種新穎、通用的時序融合框架,同時在語義層面和時序層面上對幀信息進行聚合。在語義層面上,本文使用多階段聚合網絡在多個語義層面上對視頻信息進行提取,使得最終獲取的特征更全面地表征視頻信息。而在時間層面上,本文對現有的幀內注意力機制進行了改進,加入幀間注意力模塊,通過考慮幀間關系來有效降低時序融合中的信息冗余。
實驗結果顯示本文的方法能有效提升基于視頻的行人識別準確度,達到目前最佳的性能。
2.速算批改中的帶結構文本識別
Accurate Structured-Text Spotting forArithmetical Exercise Correction
關鍵字:速算批改,算式檢測與識別
對于中小學教師而言,數學作業批改一直是一項勞動密集型任務,為了減輕教師的負擔,本文提出算術作業檢查器,一個自動評估圖像上所有算術表達式正誤的系統。其主要挑戰是,算術表達式往往是由具有特殊格式(例如,多行式,分數式)的印刷文本和手寫文本所混合組成的。面臨這個挑戰,傳統的速算批改方案在實際業務中暴露出了許多問題。本文在算式檢測和識別兩方面,針對實際問題提出了解決方案。針對算式檢測中出現的非法算式候選問題,文中在無需錨框的檢測方法CenterNet的基礎上,進一步設計了橫向邊緣聚焦的損失函數。CenterNet通過捕捉對象的兩個邊角位置來定位算式對象,同時學習對象內部的信息作為補充,避免生成 ”中空“的對象,在算式檢測任務上具有較好的適性。橫向邊緣聚焦的損失函數進一步把損失更新的關注點放在更易產生、更難定位的算式左右邊緣上,避免產生合理卻不合法的算式候選。該方法在檢測召回率和準確率上都有較為明顯的提升。在算式識別框方面,為避免無意義的上下文信息干擾識別結果,文中提出基于上下文門函數的識別方法。該方法利用一個門函數來均衡圖像表征和上下文信息的輸入權重,迫使識別模型更多地學習圖像表征,從而避免無意義的上下文信息干擾識別結果。

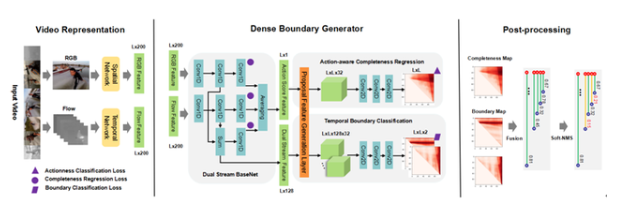
3. 基于稠密邊界生成器的時序動作提名的快速學習
Fast Learning of Temporal Action Proposal via Dense Boundary Generator
關鍵詞:DBG動作檢測法、算法框架、開源
下載鏈接:https://arxiv.org/abs/1911.04127
視頻動作檢測技術是精彩視頻集錦、視頻字幕生成、動作識別等任務的基礎,隨著互聯網的飛速發展,在產業界中得到越來越廣泛地應用,而互聯網場景視頻內容的多樣性也對技術提出了很多的挑戰,如視頻場景復雜、動作長度差異較大等。
針對這些挑戰,本文針對DBG動作檢測算法,提出3點創新:
(1)提出一種快速的、端到端的稠密邊界動作生成器(Dense Boundary Generator,DBG)。該生成器能夠對所有的動作提名(proposal)估計出稠密的邊界置信度圖。
(2)引入額外的時序上的動作分類損失函數來監督動作概率特征(action score feature,asf),該特征能夠促進動作完整度回歸(Action-aware Completeness Regression,ACR)。
(3)設計一種高效的動作提名特征生成層(Proposal Feature Generation Layer,PFG),該Layer能夠有效捕獲動作的全局特征,方便實施后面的分類和回歸模塊。
其算法框架主要包含視頻特征抽取(Video Representation),稠密邊界動作檢測器(DBG),后處理(Post-processing)三部分內容。目前騰訊優圖DBG的相關代碼已在github上開源,并在ActivityNet上排名第一。
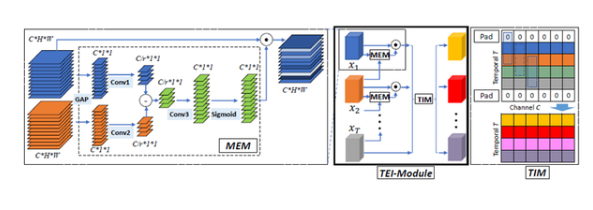
4. TEINet:邁向視頻識別的高效架構
TEINet: Towards an Efficient Architecture for Video Recognition
關鍵詞:TEI模塊、時序建模、時序結構
下載鏈接:https://arxiv.org/abs/1911.09435
本文提出了一種快速的時序建模模塊,即TEI模塊,該模塊能夠輕松加入已有的2D CNN網絡中。與以往的時序建模方式不同,TEI通過channel維度上的attention以及channel維度上的時序交互來學習時序特征。
首先,TEI所包含的MEM模塊能夠增強運動相關特征,同時抑制無關特征(例如背景),然后TEI中的TIM模塊在channel維度上補充前后時序信息。這兩個模塊不僅能夠靈活而有效地捕捉時序結構,而且在inference時保證效率。本文通過充分實驗在多個benchmark上驗證了TEI中兩個模塊的有效性。
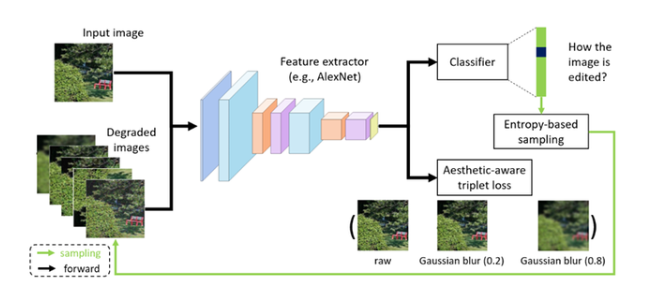
5. 通過自監督特征學習重新審視圖像美學質量評估
Revisiting Image AestheticAssessment via Self-Supervised Feature Learning
關鍵詞:美學評估、自我監督、計算機視覺
下載鏈接:https://arxiv.org/abs/1911.11419
圖像美學質量評估是計算機視覺領域中一個重要研究課題。近年來,研究者們提出了很多有效的方法,在美學評估問題上取得了很大進展。這些方法基本上都依賴于大規模的、與視覺美學相關圖像標簽或屬性,但這些信息往往需要耗費巨大人力成本。
為了能夠緩解人工標注成本,“使用自監督學習來學習具有美學表達力的視覺表征”是一個具有研究價值的方向。本文在這個方向上提出了一種簡單且有效的自監督學習方法。我們方法的核心動機是:若一個表征空間不能鑒別不同的圖像編輯操作所帶來的美學質量的變化,那么這個表征空間也不適合圖像美學質量評估任務。從這個動機出發,本文提出了兩種不同的自監督學習任務:一個用來要求模型識別出施加在輸入圖像上的編輯操作的類型;另一個要求模型區分同一類操作在不同控制參數下所產生的美學質量變動的差異,以此來進一步優化視覺表征空間。
為了對比實驗的需要,本文將提出的方法與現有的經典的自監督學習方法(如,Colorization,Split-brain,RotNet等)進行比較。實驗結果表明:在三個公開的美學評估數據集上(即AVA,AADB,和CUHK-PQ),本文的方法都能取得頗具競爭力的性能。而且值得注意的是:本文的方法能夠優于直接使用 ImageNet 或者 Places 數據集的標簽來學習表征的方法。此外,我們還驗證了:在 AVA 數據集上,基于我們方法的模型,能夠在不使用 ImageNet 數據集的標簽的情況下,取得與最佳方法相當的性能。
6.基于生成模型的視頻域適應技術
Generative Adversarial Networks forVideo-to-Video Domain Adaptation
關鍵字:視頻生成,無監督學習,域適應
來自多中心的內窺鏡視頻通常具有不同的成像條件,例如顏色和照明,這使得在一個域上訓練的模型無法很好地推廣到另一個域。域適應是解決該問題的潛在解決方案之一。但是,目前很少工作能集中在視頻數據域適應處理任務上。
為解決上述問題,本文提出了一種新穎的生成對抗網絡(GAN)即VideoGAN,以在不同域之間轉換視頻數據。實驗結果表明,由VideoGAN生成的域適應結腸鏡檢查視頻,可以顯著提高深度學習網絡在多中心數據集上結直腸息肉的分割準確度。由于我們的VideoGAN是通用的網絡體系結構,因此本文還將CamVid駕駛視頻數據集上進行了測試。實驗表明,我們的VideoGAN可以縮小域間差距。
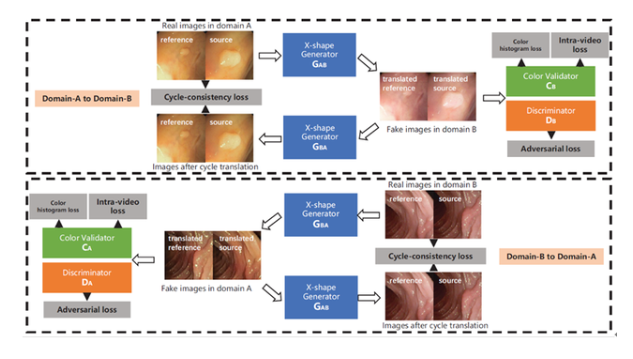
7. 非對稱協同教學用于無監督的跨領域行人再識別
Asymmetric Co-Teaching for UnsupervisedCross-Domain Person Re-Identification
關鍵詞:行人重識別、非對稱協同教學、域適應
下載鏈接:https://arxiv.org/abs/1912.01349
行人重識別由于樣本的高方差及成圖質量,一直以來都是極具挑戰性的課題。雖然在一些固定場景下的re-ID取得了很大進展(源域),但只有極少的工作能夠在模型未見過的目標域上得到很好的效果。目前有一種有效解決方法,是通過聚類為無標記數據打上偽標簽,輔助模型適應新場景,然而,聚類往往會引入標簽噪聲,并且會丟棄低置信度樣本,阻礙模型精度提升。
本文通過提出非對稱協同教學方法,更有效地利用挖掘樣本,提升域適應精度。具體來說,就是使用兩個網絡,一個網絡接收盡可能純凈的樣本,另一個網絡接收盡可能多樣的樣本,在“類協同教學”的框架下,該方法在濾除噪聲樣本的同時,可將更多低置信度樣本納入到訓練過程中。多個公開實驗可說明此方法能有效提升現階段域適應精度,并可用于不同聚類方法下的域適應。

8. 帶角度正則的朝向敏感損失用于行人再識別
Viewpoint-Aware Loss with AngularRegularization for Person Re-Identification
關鍵詞:行人重識別、朝向、建模
下載鏈接:https://arxiv.org/abs/1912.01300
近年來有監督的行人重識別(ReID)取得了重大進展,但是行人圖像間巨大朝向差異,使得這一問題仍然充滿挑戰。大多數現有的基于朝向的特征學習方法,將來自不同朝向的圖像映射到分離和獨立的子特征空間當中。這種方法只建模了一個朝向下人體圖像的身份級別的特征分布,卻忽略了朝向間潛在的關聯關系。
為解決這一問題,本文提出了一種新的方法,叫帶角度正則的朝向敏感損失(VA-ReID)。相比每一個朝向學習一個子空間,該方法能夠將來自不同朝向的特征映射到同一個超球面上,這樣就能同時建模身份級別和朝向級別的特征分布。在此基礎上,相比傳統分類方法將不同的朝向建模成硬標簽,本文提出了朝向敏感的自適應標簽平滑正則方法(VALSR)。這一方法能夠給予特征表示自適應的軟朝向標簽,從而解決了部分朝向無法明確標注的問題。
大量在Market1501和DukeMTMC數據集上的實驗證明了本文的方法有效性,其性能顯著超越已有的最好有監督ReID方法。
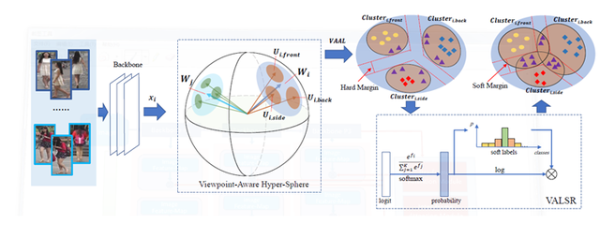
9. 如何利用弱監督信息訓練條件對抗生成模型
Robust Conditional GAN fromUncertainty-Aware Pairwise Comparisons
關鍵詞:CGAN、弱監督、成對比較
下載鏈接:https://arxiv.org/abs/1911.09298
條件對抗生成網絡(conditinal GAN,CGAN)已在近些年取得很大成就,并且在圖片屬性編輯等領域有成功的應用。但是,CGAN往往需要大量標注。為了解決這個問題,現有方法大多基于無監督聚類,比如先用無監督學習方法得到偽標注,再用偽標注當作真標注訓練CGAN。然而,當目標屬性是連續值而非離散值時,或者目標屬性不能表征數據間的主要差異,那么這種基于無監督聚類的方法就難以取得理想效果。本文進而考慮用弱監督信息去訓練CGAN,在文中我們考慮成對比較這種弱監督。成對比較相較于絕對標注具有以下優點:1.更容易標注;2.更準確;3.不易受主觀影響。
我們提出先訓練一個比較網絡來預測每張圖片的得分,再將這個得分當做條件訓練CGAN。第一部分的比較網絡我們受到國際象棋等比賽中常用的等級分(Elo ratingsystem)算法的啟發,將一次成對比較的標注視為一次比賽,用一個網絡預測圖片的得分,我們根據等級分設計了可以反向傳播學習的神經網絡。我們還考慮了網絡的貝葉斯版本,使網絡具有估計不確定性的能力。對于圖像生成部分,我們將魯棒條件對抗生成網絡(RObust Conditional GAN, RCGAN)拓展到條件是連續值的情形。具體的,與生成的假圖對應的預測得分在被判別器接收之前會被一個重采樣過程污染。這個重采樣過程需要用到貝葉斯比較網絡的不確定性估計。
我們在四個數據集上進行了實驗,分別改變人臉圖像的年齡和顏值。實驗結果表明提出的弱監督方法和全監督基線相當,并遠遠好于非監督基線。
10. 基于對抗擾動的無監督領域自適應語義分割
An Adversarial PerturbationOriented Domain Adaptation Approach for Semantic Segmentation
關鍵詞:無監督領域自適應、語義分割、對抗訓練
下載鏈接:https://arxiv.org/pdf/1912.08954.pdf
如今神經網絡借助大量標注數據已經能夠達到很好的效果,但是往往不能很好的泛化到一個新的環境中,而且大量數據標注是十分昂貴的。因此,無監督領域自適應就嘗試借助已有的有標注數據訓練出模型,并遷移到無標注數據上。
對抗對齊(adversarialalignment)方法被廣泛應用在無監督領域自適應問題上,全局地匹配兩個領域間特征表達的邊緣分布。但是,由于語義分割任務上數據的長尾分布(long-tail)嚴重且缺乏類別上的領域適配監督,領域間匹配的過程最終會被大物體類別(如:公路、建筑)主導,從而導致這種策略容易忽略尾部類別或小物體(如:紅路燈、自行車)的特征表達。
本文提出了一種生成對抗擾動并防御的框架。首先該框架設計了幾個對抗目標(分類器和鑒別器),并通過對抗目標在兩個領域的特征空間分別逐點生成對抗樣本。這些對抗樣本連接了兩個領域的特征表達空間,并蘊含網絡脆弱的信息。然后該框架強制模型防御對抗樣本,從而得到一個對于領域變化和物體尺寸、類別長尾分布都更魯棒的模型。
本文提出的對抗擾動框架,在兩個合成數據遷移到真實數據的任務上進行了驗證。該方法不僅在圖像整體分割上取得了優異的性能,并且提升了模型在小物體和類別上的精度,證明了其有效性。

-
神經網絡
+關注
關注
42文章
4812瀏覽量
103263 -
人工智能
+關注
關注
1805文章
48922瀏覽量
248155 -
騰訊
+關注
關注
7文章
1678瀏覽量
50225
發布評論請先 登錄
墨芯人工智能入選中國戰略性新興產業典型案例
睿創微納AI芯片技術登上國際計算機體系結構領域頂級會議
后摩智能5篇論文入選國際頂會

嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
Nullmax視覺感知能力再獲國際頂級學術會議認可
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
揭秘生成式人工智能如何重塑視頻會議體驗
鯤云科技AI視頻分析解決方案入選人工智能典型應用示范案例

FPGA在人工智能中的應用有哪些?
亮風臺“空間智能”產品入選WAIC “人工智能 +” 創新案例標桿






 工商網監
工商網監
評論