 機器學習的6個關鍵概念
機器學習的6個關鍵概念

機器學習是一種將傳統數學與現代強大的計算處理相結合的技術,以學習數據集中固有的模式。 在機器學習中,目標是產生一種可以使用這些模式執行某些指定任務的算法。
在監督式機器學習的情況下,目標可能是開發一個模型,該模型可以識別一組輸入所屬的類別或類別,或預測連續值,例如房屋價格。
在本文中,我將介紹機器學習中的一些關鍵概念。 如果您是機器學習的新手,這將使您對本領域中使用的一些術語和技術有一個很好的了解。
1.特征
在機器學習中,我們上面討論的輸入稱為特征。 要素是分配給數據點的一組屬性。
以下示例數據集是著名的數據集,通常用于機器學習實踐問題(稱為"波士頓住房價格")。 它由一組與房屋相關的功能(在下圖中以紅色突出顯示)組成,例如年齡,平均房間數和物業稅值以及相應的房價。
為了使機器學習模型成功完成其任務,至少其中一些功能與房屋價格之間需要存在統計關系。
> Boston housing prices dataset — features are highlighted red
2.特征選擇與工程
優化機器學習模型的重要一步是優化。 我們開發的模型需要以最佳狀態執行,而要確保做到這一點的一種方法是使用最佳功能來訓練模型。
包括每個特征并不總是有用的。 有些特征可能與我們嘗試預測的變量沒有有意義的統計關系,而另一些特征可能彼此緊密相關。 這兩種情況都將噪聲引入訓練階段,這可能會降低模型性能。 特征選擇是選擇最佳特征以包含在訓練階段中的過程。
同樣,原始形式的特征可能無法提供足夠的有意義的數據來訓練性能模型。 另外,某些特征根本不能以其原始形式使用,一個很好的例子就是基于日期/時間的功能。 機器學習模型不能使用日期或時間戳作為特征,我們需要首先從日期中導出有意義的特征,才能包含此信息。 我們可以使用整數形式的日期部分(例如月,日或星期數),或計算兩個日期之間的差,以提供算法可以理解的模式。 這就是所謂的特征工程。
3.標簽
有監督的機器學習需要一些被稱為標記數據的東西。 這意味著每組要素都具有相應標簽的數據。 這些標簽可以是類別或類型(例如貓或狗),也可以是連續值,例如在波士頓房屋價格數據集中以標簽為價格的情況。
在開發機器學習模型時,功能通常稱為X,標簽稱為y。
> Boston housing prices dataset — labels are highlighted red
4.訓練
監督式機器學習需要標記數據,因為算法使用這些示例特征值及其對應的標記來"學習"模式,如果成功,則將使模型能夠準確地預測新的未標記數據上的標記。
在機器學習過程中,學習的這一階段稱為訓練階段。 在此階段結束時,您將擁有一個可用于預測新的未標記數據的標簽或值的模型。 訓練階段通常稱為擬合模型。
5.調參
在本文前面介紹功能選擇時,我曾討論過一個優化過程。 此過程的另一部分稱為調參,涉及優化算法參數以找到適合您特定數據集的最佳組合。
所有機器學習模型都包含具有多種選項的參數。 例如,隨機森林模型具有許多可調參數。 一個示例是n_estimators,它確定森林中樹木的數量。 通常,樹的數量越多,結果越好,但是在特定點(并且這取決于數據集),隨著您添加更多的樹,改進會降低。 為您的數據集找到最佳樹數是一種調整隨機森林算法參數的方法。
每種算法都有許多可調參數,并且每個參數都有大量潛在的選項。 幸運的是,有自動方法可以找到這些參數的最佳組合,這就是所謂的超參數優化。
6.驗證
建立模型后,我們需要確定其執行給定任務的能力。 在我們的示例數據中,我們將要了解模型可以多么準確地預測房屋價格。 在機器學習中,建立最佳性能指標很重要,這將根據我們要解決的問題而有所不同。
通常,在開始機器學習項目時,我們將首先將要使用的數據集分為兩部分。 我們一個用來訓練模型,另一個用于測試階段。
機器學習中的測試通常稱為驗證。 我們使用模型對保留的測試數據集進行預測,并測量所選的性能指標,以確定模型能夠很好地執行給定任務。
本文概述了討論機器學習時最常用的一些術語和概念。 如果您剛剛開始學習,它應該可以幫助您了解機器學習教程中使用的一些術語。 如果您想深入學習使用python創建您的第一個模型,可以在這里閱讀我的教程"如何創建您的第一個機器學習模型"。
-
機器學習
+關注
關注
66文章
8500瀏覽量
134506
發布評論請先 登錄
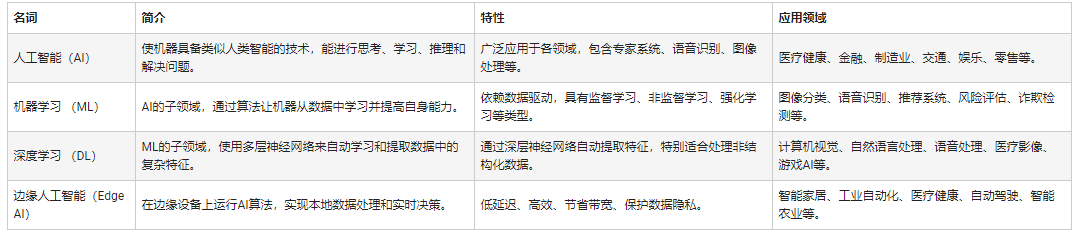
人工智能和機器學習以及Edge AI的概念與應用

如何選擇云原生機器學習平臺
自然語言處理與機器學習的關系 自然語言處理的基本概念及步驟
ASR和機器學習的關系
什么是機器學習?通過機器學習方法能解決哪些問題?

NPU與機器學習算法的關系
eda在機器學習中的應用
具身智能與機器學習的關系
人工智能、機器學習和深度學習存在什么區別






 工商網監
工商網監
評論