 傳統機器學習方法和應用指導
傳統機器學習方法和應用指導
在上一篇文章中,我們介紹了機器學習的關鍵概念術語。在本文中,我們會介紹傳統機器學習的基礎知識和多種算法特征,供各位老師選擇。
01
傳統機器學習
傳統機器學習,一般指不基于神經網絡的算法,適合用于開發生物學數據的機器學習方法。盡管深度學習(一般指神經網絡算法)是一個強大的工具,目前也非常流行,但它的應用領域仍然有限。與深度學習相比,傳統方法在給定問題上的開發和測試速度更快。開發深度神經網絡的架構并進行訓練是一項耗時且計算成本高昂的任務,而傳統的支持向量機(SVM)和隨機森林等模型則相對簡單。此外,在深度神經網絡中估計特征重要性(即每個特征對預測的貢獻程度)或模型預測的置信度仍然不是一件容易的事。即使使用深度學習模型,通常仍應訓練一個傳統方法,與基于神經網絡的模型進行比較。
傳統方法通常期望數據集中的每個樣本具有相同數量的特征,但是生物學檢測數據很難滿足這個需求。舉例說明,當使用蛋白質、RNA的表達水平矩陣時,每個樣本表達的蛋白質、RNA數量不同。為了使用傳統方法處理這些數據,可以通過簡單的技術(如填充和窗口化)將數據調整為相同的大小。“填充”意味著將每個樣本添加額外的零值,直到它與數據集中最大的樣本大小相同。相比之下,窗口化將每個樣本縮短到給定的大小(例如,使用在所有樣品中均表達的蛋白質、RNA)。
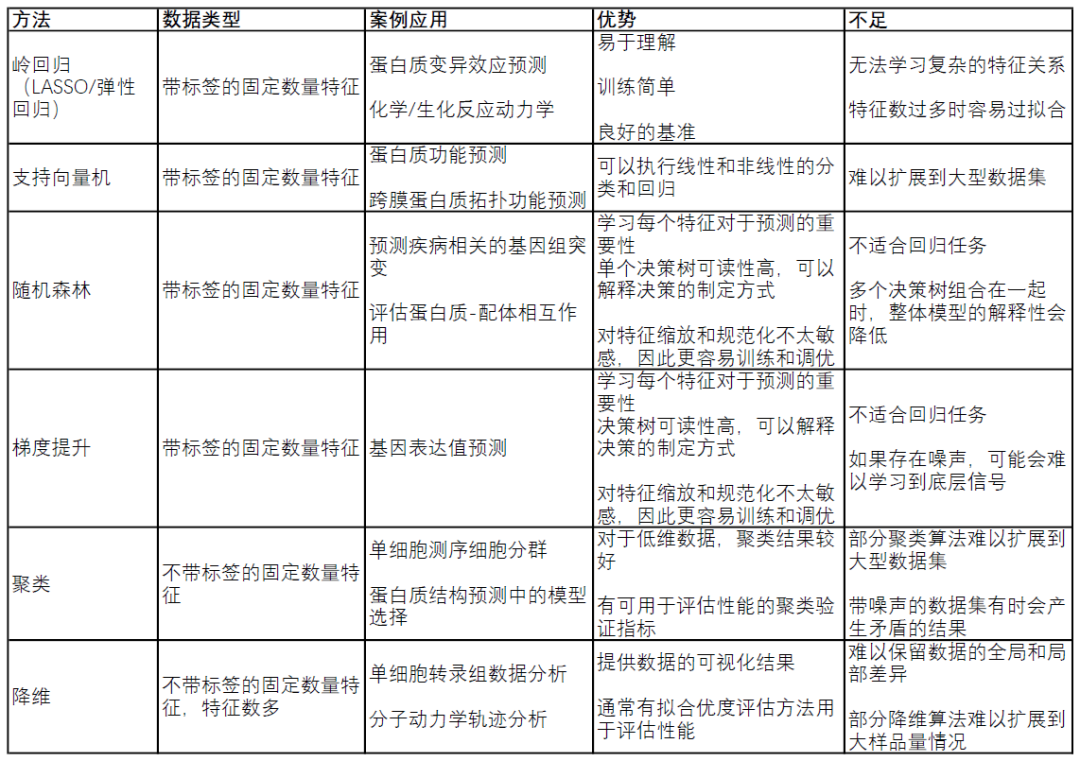
表1. 傳統機器學習方法比較
02
回歸模型
對于回歸問題,嶺回歸(帶有正則化項的線性回歸)通常是開發模型的良好起點。因為它可以為給定任務提供快速且易于理解的基準。當希望減少模型依賴的特征數時,比如篩選生物標志物研究時,其他線性回歸變體如LASSO回歸和彈性網絡回歸也是值得考慮的。數據中特征之間的關系通常是非線性的,因此在這種情況下使用如支持向量機(SVM)的模型通常是更合適的選擇。SVM是一種強大的回歸和分類模型,它使用核函數將不可分的問題轉換為更容易解決的可分問題。根據使用的核函數,SVM可以用于線性回歸和非線性回歸。一個開發模型的好方法是訓練一個線性SVM和一個帶有徑向基函數核的SVM(一種通用的非線性SVM),以量化非線性模型是否能帶來任何增益。非線性方法可以提供更強大的模型,但代價是難以解釋哪些特征在影響模型。
03
分類模型
許多常用的回歸模型也用于分類。對于分類任務,訓練一個線性SVM和一個帶有徑向基函數核的SVM也是一個好的默認起點。另一種可以嘗試的方法是k近鄰分類(KNN)。作為最簡單的分類方法之一,KNN提供了與其他更復雜的模型(如SVM)進行比較的有用基線性能指標。另一類強大的非線性方法是基于集成的模型,如隨機森林和XGBoost。這兩種方法都是強大的非線性模型,具有提供特征重要性估計和通常需要最少超參數調優的優點。由于特征重要性值的分配和決策樹結構,這些模型可分析哪些特征對預測貢獻最大,這對于生物學理解至關重要。
無論是分類還是回歸,許多可用的模型都有令人眼花繚亂的變體。試圖預測特定方法是否適合特定問題可能會有誤導性,因此采取經驗性的試錯方法來找到最佳模型是明智的選擇。選擇最佳方法的一個好策略是訓練和優化上述多種方法,并選擇在驗證集上表現最好的模型,最后再在獨立的測試集上比較它們的性能。
04
聚類模型和降維
聚類算法在生物學中廣泛應用。k-means是一種強大的通用聚類方法,像許多其他聚類算法一樣,需要將聚類的數量設置為超參數。DBSCAN是一種替代方法,不需要預先定義聚類的數量,但需要設置其他超參數。在聚類之前進行降維也可以提高具有大量特征的數據集的性能。
降維技術用于將具有大量屬性(或維度)的數據轉換為低維形式,同時盡可能保留數據點之間的不同關系。例如,相似的數據點(如兩個同源蛋白序列)在低維形式中也應保持相似,而不相似的數據點(如不相關的蛋白序列)應保持不相似。通常選擇兩維或三維,以便在坐標軸上可視化數據,盡管在機器學習中使用更多維度也有其用途。這些技術包括數據的線性和非線性變換。生物學中常見的例子包括主成分分析(PCA)、均勻流形逼近和投影(UMAP)以及t分布隨機鄰域嵌入(t-SNE)。
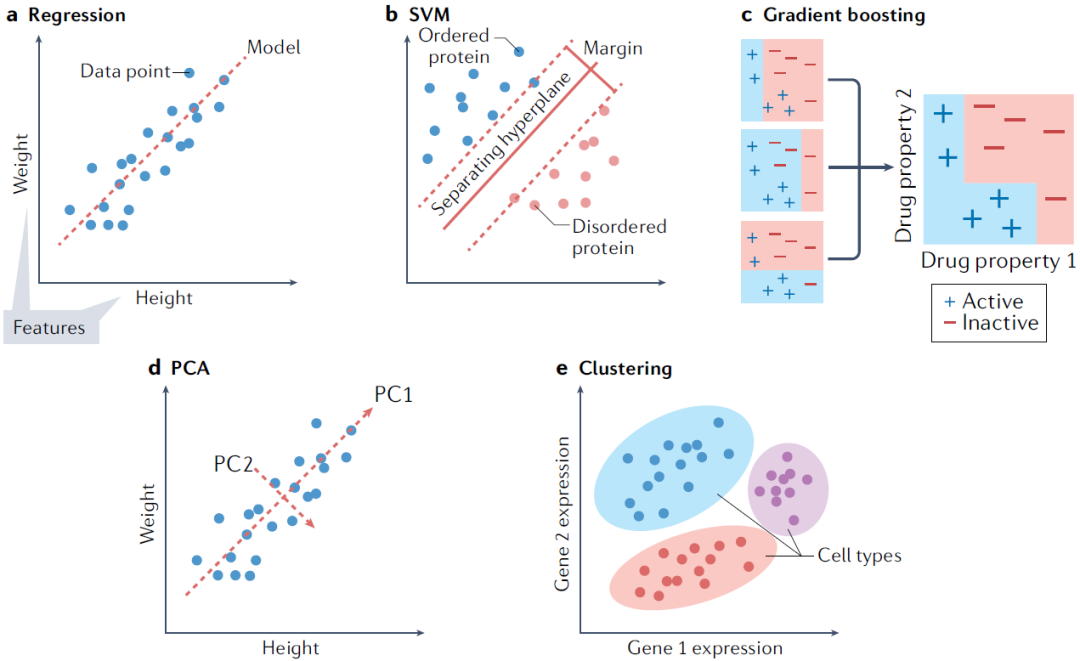
圖1. 各種傳統機器學習模型
本文詳細介紹了傳統機器學習方法和應用指導,下一篇文章將介紹深度神經網絡算法模型,敬請期待。
-
神經網絡
+關注
關注
42文章
4811瀏覽量
103048 -
機器學習
+關注
關注
66文章
8497瀏覽量
134227
原文標題:生物學家的機器學習指南(三)
文章出處:【微信號:SBCNECB,微信公眾號:上海生物芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

使用MATLAB進行無監督學習

一種無刷直流電機霍耳信號與定子繞組關系自學習方法
什么是機器學習?通過機器學習方法能解決哪些問題?






 工商網監
工商網監
評論