") 使用MATLAB進(jìn)行無監(jiān)督學(xué)習(xí)
使用MATLAB進(jìn)行無監(jiān)督學(xué)習(xí)
無監(jiān)督學(xué)習(xí)是一種根據(jù)未標(biāo)注數(shù)據(jù)進(jìn)行推斷的機(jī)器學(xué)習(xí)方法。無監(jiān)督學(xué)習(xí)旨在識(shí)別數(shù)據(jù)中隱藏的模式和關(guān)系,無需任何監(jiān)督或關(guān)于結(jié)果的先驗(yàn)知識(shí)。
無監(jiān)督學(xué)習(xí)的工作原理
無監(jiān)督學(xué)習(xí)算法發(fā)現(xiàn)數(shù)據(jù)中隱藏的模式、結(jié)構(gòu)和分組,而不需要任何關(guān)于結(jié)果的先驗(yàn)知識(shí)。這些算法依賴未標(biāo)注數(shù)據(jù),即沒有預(yù)定義標(biāo)簽的數(shù)據(jù)。
典型的無監(jiān)督學(xué)習(xí)過程涉及數(shù)據(jù)準(zhǔn)備、對(duì)其應(yīng)用正確的無監(jiān)督學(xué)習(xí)算法,以及最后的解釋和評(píng)估結(jié)果。這種方法特別適用于聚類(目標(biāo)是將相似的數(shù)據(jù)點(diǎn)組合在一起)和降維(通過減少特征(維度)的數(shù)量來簡化數(shù)據(jù))等任務(wù)。通過分析數(shù)據(jù)的固有結(jié)構(gòu),無監(jiān)督學(xué)習(xí)可以更好地理解數(shù)據(jù)集。
無監(jiān)督學(xué)習(xí)也可以在有監(jiān)督學(xué)習(xí)之前應(yīng)用,以識(shí)別探索性數(shù)據(jù)分析中的特征并基于分組建立各個(gè)類。這是特性工程的一部分,特征工程是將原始數(shù)據(jù)變換為適合有監(jiān)督機(jī)器學(xué)習(xí)的特征的過程。

使用無監(jiān)督學(xué)習(xí)將未標(biāo)注數(shù)據(jù)組織成各個(gè)組。
無監(jiān)督學(xué)習(xí)方法的類型
1)聚類
聚類是最常見的無監(jiān)督學(xué)習(xí)方法,可幫助您理解數(shù)據(jù)集的自然分組或固有結(jié)構(gòu)。它用于探索性數(shù)據(jù)分析、模式識(shí)別、異常檢測、圖像分割等。聚類算法(例如 k 均值或?qū)哟尉垲悾?duì)數(shù)據(jù)點(diǎn)分組,使得同一組(或簇)中的數(shù)據(jù)點(diǎn)彼此之間比在其他組中的數(shù)據(jù)點(diǎn)更相似。
例如,如果一家移動(dòng)電話公司想優(yōu)化其蜂窩手機(jī)信號(hào)塔的方位布局,就可以使用機(jī)器學(xué)習(xí)來估計(jì)使用其信號(hào)塔的人群數(shù)量。一部移動(dòng)電話同時(shí)間只能與一個(gè)信號(hào)塔通信,所以該團(tuán)隊(duì)使用聚類算法設(shè)計(jì)蜂窩塔的最佳布局,優(yōu)化其客戶群組(也可以稱之為客戶簇)的信號(hào)接收。
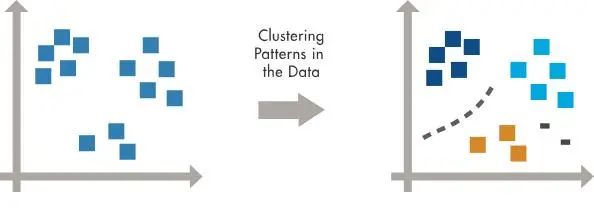
使用聚類找到數(shù)據(jù)中隱藏的模式。
聚類分為兩個(gè)主要類別:
硬聚類或互斥聚類,其中每個(gè)數(shù)據(jù)點(diǎn)僅屬于一個(gè)簇,例如常見的 k 均值方法。
軟聚類或重疊聚類,其中每個(gè)數(shù)據(jù)點(diǎn)可以屬于多個(gè)簇,例如在高斯混合模型中。
常見的聚類算法包括:
層次聚類通過創(chuàng)建聚類樹來構(gòu)建一個(gè)多級(jí)聚類層次結(jié)構(gòu)。
k 均值根據(jù)到簇質(zhì)心的距離將數(shù)據(jù)劃分為 k 個(gè)不同簇。
高斯混合模型將簇形成為多元正態(tài)密度分量的混合。
基于密度的含噪數(shù)據(jù)空間聚類 (DBSCAN)將高密度區(qū)中臨近的點(diǎn)進(jìn)行組合,跟蹤低密度區(qū)中的離群值。它可以處理任意非凸形狀。
自組織映射使用學(xué)習(xí)數(shù)據(jù)的拓?fù)浜头植嫉?a href="http://m.xsypw.cn/tags/神經(jīng)網(wǎng)絡(luò)/" target="_blank">神經(jīng)網(wǎng)絡(luò)。
譜聚類將輸入數(shù)據(jù)變換為基于圖的表示形式,其中的簇比原始特征空間中的簇分離效果更好。簇的數(shù)量可以通過研究圖的特征值來估計(jì)。
隱馬爾可夫模型可用于發(fā)現(xiàn)序列中的模式,如生物信息學(xué)中的基因和蛋白質(zhì)。
模糊 c 均值 (FCM) 將數(shù)據(jù)分成 N 個(gè)簇,數(shù)據(jù)集中的每個(gè)數(shù)據(jù)點(diǎn)在一定程度上都屬于每個(gè)簇。
聚類用于各種應(yīng)用,例如圖像分割、異常檢測以及模式識(shí)別。
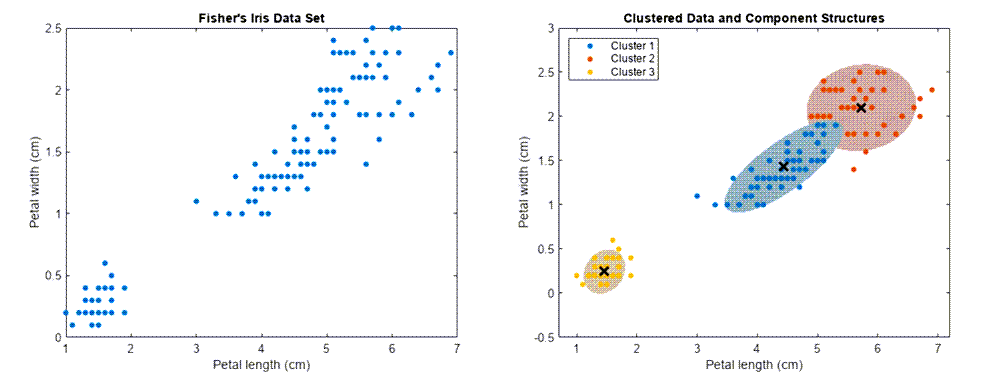
左圖:三種鳶尾花品種的幾個(gè)標(biāo)本的花瓣測量值的 MATLAB 散點(diǎn)圖。右圖:使用高斯混合模型 (GMM) 聚類方法將花瓣測量值分割成三個(gè)簇。
2)降維
多元數(shù)據(jù)通常包含大量變量或特征。這可能會(huì)影響運(yùn)行時(shí)間和內(nèi)存要求。降維方法能夠減少特征(維度)的數(shù)量,同時(shí)保留原始數(shù)據(jù)的必要信息。使用無監(jiān)督學(xué)習(xí)進(jìn)行降維有助于降低計(jì)算負(fù)載,提高機(jī)器學(xué)習(xí)算法的速度和效率。
具有許多變量的數(shù)據(jù)的另一個(gè)固有困難是其可視化問題。降維方法可以在不丟失重要信息的情況下簡化數(shù)據(jù),從而使可視化和分析變得更加容易。
在示例中,我們使用在五種不同活動(dòng)(坐、站、走、跑和跳舞)期間通過智能手機(jī)加速度計(jì)傳感器采集的 60 個(gè)維度的人類活動(dòng)數(shù)據(jù)。高維度使得這些數(shù)據(jù)難以可視化和分析。通過降維,您可以將這些維度減少到兩維或三維,而不會(huì)丟失大量信息。(https://ww2.mathworks.cn/help/stats/visualize-high-dimensional-data-using-t-sne.html)
一些常見的無監(jiān)督學(xué)習(xí)降維方法有:
主成分分析 (PCA) 將數(shù)據(jù)變換為一組正交分量,以較少的變量獲取最大方差。這些新變量稱為主成分。每個(gè)主成分都是原始變量的一種線性組合。第一個(gè)主成分是空間中的單軸。當(dāng)您將每個(gè)觀測值投影到該軸上時(shí),生成的值會(huì)形成一個(gè)新變量,此變量的方差是第一個(gè)軸的所有可能選擇中的最大值。第二個(gè)主成分是空間中的另一個(gè)軸,垂直于第一個(gè)軸。將觀測值投影到此軸上會(huì)生成另一個(gè)新變量。此變量的方差是這第二個(gè)軸的所有可能選擇中的最大值。主成分的完整集合與原始變量的集合大小相同,但通常前幾個(gè)成分占原始數(shù)據(jù)總方差的 80% 以上。
t 分布隨機(jī)近鄰嵌入 (t-SNE) 非常適合可視化高維數(shù)據(jù)。它以遵守點(diǎn)之間相似性的方式將高維數(shù)據(jù)點(diǎn)嵌入到低維中。通常,您可以可視化低維點(diǎn)來查看原始高維數(shù)據(jù)中的自然簇。
因子分析是一種對(duì)多元數(shù)據(jù)進(jìn)行模型擬合的方法,它通過識(shí)別解釋變量間觀測到的相關(guān)性的基礎(chǔ)因子來估計(jì)變量間的相互依賴關(guān)系。在這種無監(jiān)督學(xué)習(xí)方法中,已測變量依賴數(shù)量較少的未發(fā)現(xiàn)(潛在)因子。由于每個(gè)因子可能共同影響幾個(gè)變量,因此稱為公因子。每個(gè)變量都假定依賴于公因子的線性組合,且系數(shù)稱為載荷。每個(gè)已測變量還包括一個(gè)由獨(dú)立隨機(jī)變異性引起的成分,稱為特定方差,因?yàn)樗囟ㄓ谝粋€(gè)變量。
自編碼器是經(jīng)過訓(xùn)練的用于復(fù)制其輸入數(shù)據(jù)的神經(jīng)網(wǎng)絡(luò)。自編碼器可用于不同數(shù)據(jù)類型,包括圖像、時(shí)間序列和文本。它們?cè)谠S多應(yīng)用中非常有用,例如異常檢測、文本生成、圖像生成、圖像去噪以及數(shù)字通信。自編碼器通常用于降維。自編碼器由兩個(gè)較小的網(wǎng)絡(luò)組成:編碼器和解碼器。在訓(xùn)練過程中,編碼器從輸入數(shù)據(jù)中學(xué)習(xí)一組特征,稱為潛在表示。同時(shí),解碼器的訓(xùn)練目的是基于這些特征重新構(gòu)造數(shù)據(jù)。
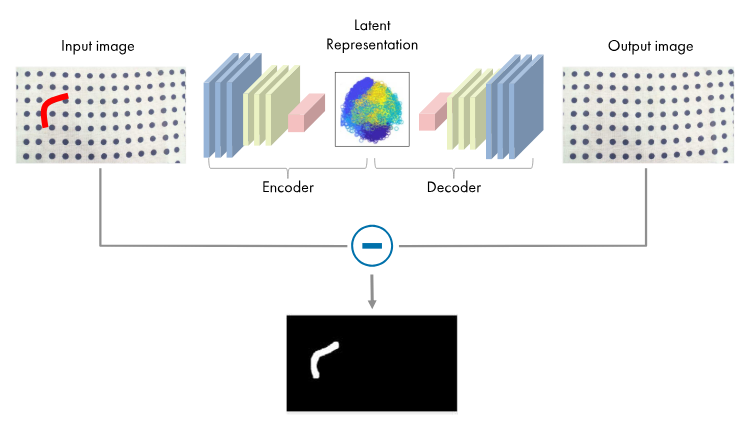
使用自編碼器的基于圖像的異常檢測。
3)關(guān)聯(lián)規(guī)則
關(guān)聯(lián)規(guī)則學(xué)習(xí)可識(shí)別大型數(shù)據(jù)庫中變量之間的有趣關(guān)系。例如,在交易數(shù)據(jù)中,關(guān)聯(lián)規(guī)則可用于識(shí)別哪些項(xiàng)目最可能被用戶一起購買。關(guān)聯(lián)規(guī)則挖掘中使用的算法包括:
Apriori 算法。這種算法通過執(zhí)行廣度優(yōu)先搜索來識(shí)別數(shù)據(jù)中的頻繁項(xiàng)目集,然后從這些項(xiàng)目集中派生關(guān)聯(lián)規(guī)則。
等效類聚類和自下而上的格型遍歷 (ECLAT) 算法。這種算法使用深度優(yōu)先搜索策略來查找頻繁項(xiàng)目集。
關(guān)聯(lián)規(guī)則在購物籃分析中最常見,但也可用于預(yù)測性維護(hù)。例如,基于不同傳感器的數(shù)據(jù),可以使用算法來識(shí)別故障模式并創(chuàng)建規(guī)則來預(yù)測組件故障。
其他應(yīng)用無監(jiān)督學(xué)習(xí)的方法包括半監(jiān)督學(xué)習(xí)和無監(jiān)督特征排名。半監(jiān)督學(xué)習(xí)可減少有監(jiān)督學(xué)習(xí)中對(duì)標(biāo)注數(shù)據(jù)的需求。應(yīng)用于整個(gè)數(shù)據(jù)集的聚類會(huì)在標(biāo)注數(shù)據(jù)和未標(biāo)注數(shù)據(jù)之間建立相似性,并且標(biāo)簽會(huì)傳播到先前未標(biāo)注的相似簇成員。無監(jiān)督特征排名在沒有給定預(yù)測目標(biāo)或響應(yīng)的情況下為特征分配得分。
為什么無監(jiān)督學(xué)習(xí)如此重要
無監(jiān)督學(xué)習(xí)是機(jī)器學(xué)習(xí)和人工智能的主要領(lǐng)域,它在探索和理解數(shù)據(jù)方面發(fā)揮著至關(guān)重要的作用。與依賴標(biāo)注數(shù)據(jù)來訓(xùn)練模型的有監(jiān)督學(xué)習(xí)不同,無監(jiān)督學(xué)習(xí)處理未標(biāo)注數(shù)據(jù),這使其在標(biāo)注數(shù)據(jù)通常成本高、耗時(shí)或不切實(shí)際的真實(shí)場景中非常有價(jià)值。
通過揭示數(shù)據(jù)中隱藏的模式、結(jié)構(gòu)和關(guān)系,無監(jiān)督學(xué)習(xí)使企業(yè)和研究人員能夠獲得以前無法獲得的有意義的深入信息。無監(jiān)督學(xué)習(xí)中的常見任務(wù)包括模式識(shí)別、探索性數(shù)據(jù)分析、分割、異常檢測和特征約簡。
有監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)的區(qū)別
有監(jiān)督學(xué)習(xí)涉及基于標(biāo)注數(shù)據(jù)集訓(xùn)練模型以執(zhí)行分類或回歸。這意味著每個(gè)訓(xùn)練示例都與一個(gè)輸出標(biāo)簽配對(duì)。它使用已知的數(shù)據(jù)集(稱為訓(xùn)練數(shù)據(jù)集)和已知的輸入數(shù)據(jù)(稱為特征)以及已知的響應(yīng)來訓(xùn)練模型以進(jìn)行預(yù)測。有監(jiān)督學(xué)習(xí)的一個(gè)示例是根據(jù)房間的大小和數(shù)量等特征預(yù)測房價(jià)。常見的機(jī)器學(xué)習(xí)模型有線性回歸、邏輯回歸、k 最近鄰 (KNN) 和支持向量機(jī)。深度學(xué)習(xí)模型也是用大型標(biāo)注數(shù)據(jù)集訓(xùn)練的,它們通常可以直接從數(shù)據(jù)中學(xué)習(xí)特征,而無需手動(dòng)提取特征。
相反,無監(jiān)督學(xué)習(xí)處理的是未標(biāo)注數(shù)據(jù)。無監(jiān)督學(xué)習(xí)算法嘗試在沒有任何先驗(yàn)知識(shí)的情況下學(xué)習(xí)數(shù)據(jù)的底層結(jié)構(gòu)。無監(jiān)督學(xué)習(xí)的主要目標(biāo)是發(fā)現(xiàn)輸入數(shù)據(jù)中隱藏的模式或內(nèi)在結(jié)構(gòu)。無監(jiān)督學(xué)習(xí)的一個(gè)示例是在不知道是什么水果的情況下根據(jù)顏色、大小和味道的相似性對(duì)水果進(jìn)行分組。常見的無監(jiān)督學(xué)習(xí)算法包括 k 均值、層次聚類等聚類方法,以及主成分分析 (PCA) 等降維方法。
由于缺失標(biāo)注數(shù)據(jù),無監(jiān)督學(xué)習(xí)結(jié)果通常不如有監(jiān)督學(xué)習(xí)結(jié)果準(zhǔn)確。然而,獲取標(biāo)注數(shù)據(jù)需要人工干預(yù),并且往往相當(dāng)耗時(shí),在某些情況下甚至無法獲得標(biāo)注數(shù)據(jù),例如對(duì)于生物數(shù)據(jù)。真實(shí)值標(biāo)注還可能需要專業(yè)知識(shí),尤其是在標(biāo)注復(fù)雜信號(hào)而不是常見物體的圖像時(shí)。
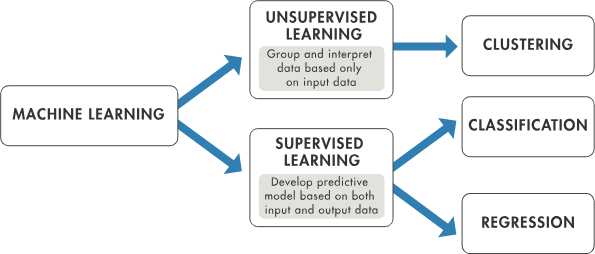
有監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)是機(jī)器學(xué)習(xí)的不同類型。
無監(jiān)督學(xué)習(xí)的示例
無監(jiān)督學(xué)習(xí)無需預(yù)定義標(biāo)簽即可識(shí)別隱藏的模式和關(guān)系,這種能力使其成為各種應(yīng)用中不可或缺的工具,包括:
探索性數(shù)據(jù)分析:無監(jiān)督學(xué)習(xí)方法廣泛用于探索數(shù)據(jù)以揭示隱藏的內(nèi)在結(jié)構(gòu),并從中提煉深入信息。例如,因子分析可用于分析同一行業(yè)內(nèi)的公司是否經(jīng)歷類似的每周股票價(jià)格變化。
異常檢測:無監(jiān)督學(xué)習(xí)方法,如孤立森林和高斯混合模型 (GMM),用于檢測異常。
醫(yī)學(xué)成像:聚類是一種無監(jiān)督學(xué)習(xí)方法,對(duì)于圖像分割非常有用。聚類算法可以應(yīng)用于醫(yī)學(xué)圖像,并基于像素密度、顏色或其他特征對(duì)醫(yī)學(xué)圖像進(jìn)行分割。醫(yī)生可以使用這些信息來識(shí)別感興趣區(qū)域,例如區(qū)分健康組織和腫瘤,或?qū)⒋竽X圖像分割成白質(zhì)、灰質(zhì)和腦脊液區(qū)域。
基因組學(xué)和生物信息學(xué):遺傳聚類和序列分析在生物信息學(xué)領(lǐng)域也有應(yīng)用。例如,聚類可用于識(shí)別基因表達(dá)譜之間的關(guān)系。
推薦系統(tǒng):奇異值分解 (SVD) 等無監(jiān)督學(xué)習(xí)方法用于協(xié)作過濾來分解用戶-項(xiàng)目交互矩陣。常見的視頻流平臺(tái)使用這種方法向個(gè)人用戶推薦內(nèi)容。
自然語言處理 (NLP):在自然語言處理中,無監(jiān)督學(xué)習(xí)方法用于主題建模、文檔聚類和構(gòu)建 AI 語言模型等任務(wù)。
無監(jiān)督學(xué)習(xí)在不同領(lǐng)域有不同應(yīng)用。通過揭示隱藏的模式和關(guān)系,無監(jiān)督學(xué)習(xí)使工程師和研究人員能夠作出明智的決策。隨著數(shù)據(jù)繼續(xù)呈指數(shù)級(jí)增長,無監(jiān)督學(xué)習(xí)的重要性和影響只會(huì)繼續(xù)擴(kuò)大。
使用 MATLAB 進(jìn)行無監(jiān)督學(xué)習(xí)
MATLAB 使您能夠創(chuàng)建從數(shù)據(jù)準(zhǔn)備到模型評(píng)估和部署的無監(jiān)督學(xué)習(xí)管道:
使用 Statistics and Machine Learning Toolbox,您可以對(duì)數(shù)據(jù)應(yīng)用無監(jiān)督學(xué)習(xí)方法(如聚類和降維)并評(píng)估模型性能。
使用 Deep Learning Toolbox,您可以通過自編碼器神經(jīng)網(wǎng)絡(luò)執(zhí)行無監(jiān)督學(xué)習(xí)。
使用 MATLAB Coder,您可以生成 C/C++ 代碼以將無監(jiān)督學(xué)習(xí)方法部署到各種硬件平臺(tái)。
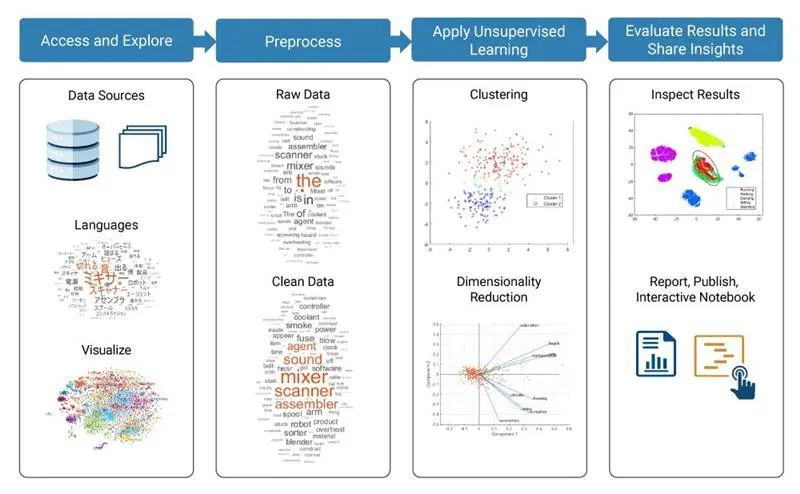
使用 MATLAB 的擴(kuò)展無監(jiān)督學(xué)習(xí)工作流。
數(shù)據(jù)準(zhǔn)備
您可以通過編程方式清洗數(shù)據(jù),也可以使用低代碼數(shù)據(jù)清洗器和預(yù)處理文本數(shù)據(jù)實(shí)時(shí)編輯器任務(wù)進(jìn)行交互式數(shù)據(jù)準(zhǔn)備和自動(dòng)代碼生成。
聚類
MATLAB 支持所有常見的聚類算法,如 k 均值、層次聚類、DBSCAN 和 GMM。使用 Fuzzy Logic Toolbox,您還可以對(duì)數(shù)據(jù)集執(zhí)行模糊 c 均值聚類。
您也可以使用數(shù)據(jù)聚類實(shí)時(shí)編輯器任務(wù)以交互方式執(zhí)行 k 均值和層次聚類。指定聚類算法、簇?cái)?shù)和距離度量。該任務(wù)計(jì)算簇索引并顯示聚類數(shù)據(jù)的可視化。
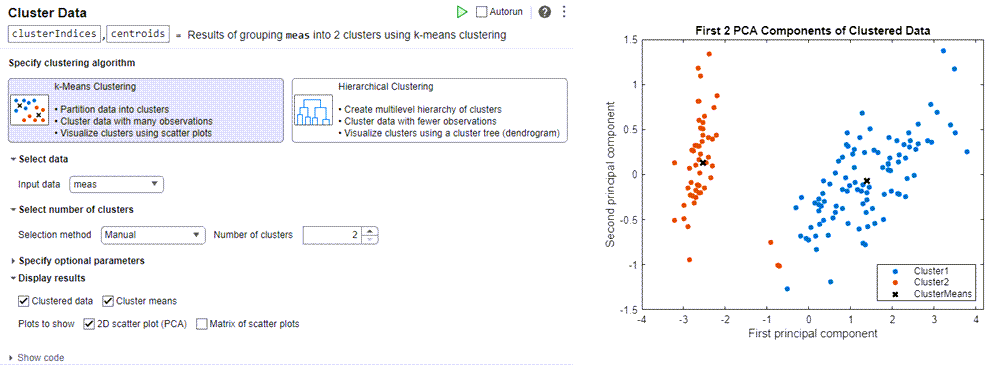
使用數(shù)據(jù)聚類實(shí)時(shí)編輯器任務(wù)的 k 均值聚類。(參閱 MATLAB 文檔: https://ww2.mathworks.cn/help/stats/clusterdatatask.html。)
降維
MATLAB 支持所有常見的降維方法,包括 PCA、t-SNE 和因子分析。您可以使用內(nèi)置函數(shù)將這些方法應(yīng)用于您的數(shù)據(jù)。對(duì)于 PCA,您還可以使用降維實(shí)時(shí)編輯器任務(wù)以交互方式執(zhí)行這些步驟。

使用實(shí)時(shí)編輯器任務(wù)進(jìn)行降維。(參閱 MATLAB 文檔:https://ww2.mathworks.cn/help/stats/reducedimensionalitytask.html。)
使用 MATLAB,您還可以使用拉普拉斯分?jǐn)?shù)對(duì)用于無監(jiān)督學(xué)習(xí)的特征進(jìn)行排名。
結(jié)果評(píng)估
您可以使用散點(diǎn)圖、樹狀圖和輪廓圖來可視化簇以評(píng)估聚類結(jié)果。您還可以通過使用 evalclusters 函數(shù)評(píng)估數(shù)據(jù)簇的最佳數(shù)量來評(píng)估聚類結(jié)果。要確定將數(shù)據(jù)劃分為特定數(shù)目的簇的良好程度,可以使用不同的評(píng)估標(biāo)準(zhǔn)(例如間距或輪廓)來計(jì)算索引值。
為了降維,您可以使用散點(diǎn)圖、碎石圖和雙標(biāo)圖來檢查結(jié)果。使用降維實(shí)時(shí)編輯器任務(wù),您可以確定解釋固定百分比數(shù)據(jù)(如 95% 或 99%)的方差所需的成分?jǐn)?shù)量。
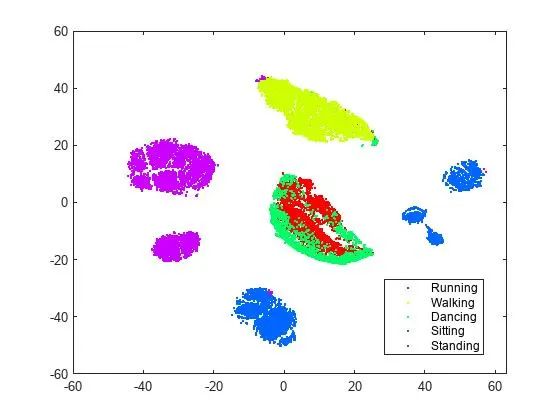
使用 t 分布隨機(jī)近鄰嵌入 (t-SNE) 將具有 60 個(gè)原始維度的高維數(shù)據(jù)的散點(diǎn)圖降低到二維。(請(qǐng)參閱 MATLAB 代碼:https://ww2.mathworks.cn/help/stats/visualize-high-dimensional-data-using-t-sne.html。)
-
matlab
+關(guān)注
關(guān)注
188文章
2994瀏覽量
233001 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8483瀏覽量
133955 -
無監(jiān)督學(xué)習(xí)
+關(guān)注
關(guān)注
1文章
17瀏覽量
2808
原文標(biāo)題:什么是無監(jiān)督學(xué)習(xí)?工作原理、方法類型、示例應(yīng)用
文章出處:【微信號(hào):MATLAB,微信公眾號(hào):MATLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于半監(jiān)督學(xué)習(xí)的跌倒檢測系統(tǒng)設(shè)計(jì)_李仲年
基于半監(jiān)督學(xué)習(xí)框架的識(shí)別算法
Python無監(jiān)督學(xué)習(xí)的幾種聚類算法包括K-Means聚類,分層聚類等詳細(xì)概述

利用機(jī)器學(xué)習(xí)來捕捉內(nèi)部漏洞的工具運(yùn)用無監(jiān)督學(xué)習(xí)方法可發(fā)現(xiàn)入侵者
你想要的機(jī)器學(xué)習(xí)課程筆記在這:主要討論監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)
如何用Python進(jìn)行無監(jiān)督學(xué)習(xí)
無監(jiān)督機(jī)器學(xué)習(xí)如何保護(hù)金融
機(jī)器學(xué)習(xí)算法中有監(jiān)督和無監(jiān)督學(xué)習(xí)的區(qū)別
最基礎(chǔ)的半監(jiān)督學(xué)習(xí)
半監(jiān)督學(xué)習(xí)最基礎(chǔ)的3個(gè)概念
為什么半監(jiān)督學(xué)習(xí)是機(jī)器學(xué)習(xí)的未來?
半監(jiān)督學(xué)習(xí):比監(jiān)督學(xué)習(xí)做的更好
機(jī)器學(xué)習(xí)中的無監(jiān)督學(xué)習(xí)應(yīng)用在哪些領(lǐng)域
自監(jiān)督學(xué)習(xí)的一些思考






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論