 機器學習中的數據分割方法
機器學習中的數據分割方法
在機器學習中,數據分割是一項至關重要的任務,它直接影響到模型的訓練效果、泛化能力以及最終的性能評估。本文將從多個方面詳細探討機器學習中數據分割的方法,包括常見的分割方法、各自的優缺點、適用場景以及實際應用中的注意事項。
一、引言
機器學習模型的性能在很大程度上取決于所使用的數據。為了有效地訓練和評估模型,通常需要將數據集分割為不同的部分,如訓練集、驗證集和測試集。這種分割有助于確保模型在未見過的數據上也能表現出良好的泛化能力。
二、常見的數據分割方法
1. 留出法(Hold-Out Method)
定義與過程 :
留出法是最簡單直接的數據分割方法,它將數據集直接劃分為兩個互斥的集合:訓練集和測試集。通常,大部分數據(如70%-80%)用于訓練模型,剩余部分(如20%-30%)用于測試模型性能。
優點 :
- 實現簡單,易于理解。
- 能夠快速評估模型性能。
缺點 :
- 數據分割的隨機性可能導致評估結果的不穩定。
- 無法充分利用所有數據進行模型訓練。
注意事項 :
- 訓練集和測試集的數據分布應盡量保持一致,以避免引入偏差。
- 可以采用分層采樣(Stratified Sampling)來確保類別比例在訓練集和測試集中相似。
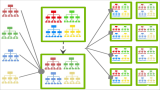
2. 交叉驗證法(Cross-Validation)
定義與過程 :
交叉驗證法將數據集劃分為k個大小相似的互斥子集,每次使用k-1個子集的并集作為訓練集,剩余的一個子集作為測試集。這樣進行k次訓練和測試,最終返回k個測試結果的均值。這種方法稱為k折交叉驗證(k-fold Cross-Validation)。
優點 :
- 充分利用了所有數據進行訓練和測試。
- 評估結果更加穩定可靠。
缺點 :
- 計算成本較高,特別是對于大數據集和復雜的模型。
- 仍受數據集劃分方式的影響。
注意事項 :
- k的取值應適中,常用的k值有5、10等。
- 可以結合分層采樣來確保每個子集的類別比例相似。
3. 自助法(Bootstrap Method)
定義與過程 :
自助法通過有放回的隨機抽樣來生成訓練集和測試集。具體來說,對于原始數據集中的每個樣本,都有相同的概率被選中(或不被選中)到訓練集中,且每次抽樣都是獨立的。這樣,原始數據集中的某些樣本可能在訓練集中出現多次,而有些樣本則可能一次都不出現。那些未出現在訓練集中的樣本則構成測試集。
優點 :
- 能夠生成多個不同的訓練集和測試集組合。
- 適用于小數據集。
缺點 :
- 改變了原始數據集的分布,可能引入偏差。
- 測試集可能不包含原始數據集中的某些樣本。
注意事項 :
- 自助法通常用于數據量較小或數據集難以分割的情況。
- 評估結果可能受到數據分布改變的影響。
4. 留一法(Leave-One-Out, LOO)
定義與過程 :
留一法是交叉驗證法的一個特例,當k等于數據集樣本數m時,每次只留一個樣本作為測試集,其余樣本作為訓練集。這樣,模型將被訓練m次,并產生m個測試結果。
優點 :
- 評估結果非常穩定,因為幾乎使用了所有數據。
- 避免了數據劃分帶來的偏差。
缺點 :
- 計算成本極高,特別是對于大數據集。
- 可能導致模型訓練過程中的過擬合現象。
注意事項 :
- 留一法通常用于小數據集或需要極高評估準確性的場景。
- 在實際應用中,需要權衡計算成本和評估準確性之間的關系。
三、數據分割的注意事項
- 數據分布一致性 :
無論是采用哪種數據分割方法,都需要確保訓練集和測試集(或驗證集)的數據分布盡可能一致。這包括樣本的類別比例、特征分布等。如果數據分布存在顯著差異,將導致評估結果產生偏差。 - 避免數據泄露 :
在數據分割過程中,需要避免數據泄露問題。即,測試集(或驗證集)中的數據不應以任何形式出現在訓練集中。否則,模型將能夠利用這部分信息來“作弊”,導致評估結果過于樂觀。 - 合理選擇分割比例 :
訓練集、驗證集和測試集的分割比例應根據具體任務和數據集的特點來合理選擇。一般來說,訓練集應占大部分比例(如70%-80%),以確保模型能夠充分學習數據的特征;驗證集用于在訓練過程中調整模型的超參數和進行早停(early stopping)等操作,其比例適中即可(如10%-20%);測試集則用于最終評估模型的性能,其比例也應足夠(如10%-20%),以提供可靠的評估結果。 - 考慮數據集的規模和復雜性 :
數據集的規模和復雜性會影響數據分割方法的選擇。對于小數據集,留出法和留一法可能更為合適,因為它們能夠最大限度地利用有限的數據進行訓練和評估。然而,這兩種方法可能導致評估結果的不穩定,特別是對于留一法,其計算成本隨著數據集規模的增加而急劇上升。對于大數據集,交叉驗證法則更為常用,因為它能夠更穩定地評估模型的性能,并且可以通過調整k值來平衡計算成本和評估準確性。 - 分層采樣與不平衡數據集 :
當數據集存在類別不平衡問題時,即某些類別的樣本數量遠多于其他類別,分層采樣變得尤為重要。通過分層采樣,可以確保訓練集、驗證集和測試集中各類別的樣本比例與原始數據集保持一致。這樣可以避免模型因數據不平衡而偏向于多數類,從而提高模型的泛化能力和評估結果的可靠性。 - 數據預處理與標準化 :
在進行數據分割之前,通常需要對數據集進行預處理和標準化。預處理步驟可能包括數據清洗(如去除噪聲、處理缺失值等)、特征選擇(選擇對模型性能有正面影響的特征)和特征降維(減少特征數量以降低模型復雜度)等。標準化則是將數據轉換為統一的尺度,以便不同特征之間可以進行比較和計算。這些步驟對于提高模型的訓練效率和性能至關重要。 - 交叉驗證的變種 :
除了標準的k折交叉驗證外,還存在一些變種方法,如時間序列數據的滾動交叉驗證(Rolling Cross-Validation)和分層交叉驗證(Stratified Cross-Validation)等。滾動交叉驗證特別適用于時間序列數據,它按照時間順序將數據劃分為連續的子集,并確保每個子集都包含一定時間段內的數據。分層交叉驗證則確保在每次分割時,訓練集和測試集中各類別的樣本比例都保持一致,從而進一步提高評估結果的可靠性。 - 模型選擇與評估 :
數據分割的最終目的是為了更好地選擇和評估模型。通過比較不同模型在訓練集、驗證集和測試集上的性能表現,可以選擇出最適合當前任務的模型。同時,還可以利用驗證集來調整模型的超參數,如學習率、批量大小、網絡結構等,以進一步提高模型的性能。最終,通過測試集上的評估結果來驗證模型的泛化能力和實用性。
四、結論與展望
數據分割是機器學習中不可或缺的一環,它直接影響到模型的訓練和評估效果。通過合理選擇數據分割方法、注意數據分布一致性、避免數據泄露、合理選擇分割比例、考慮數據集的規模和復雜性、采用分層采樣處理不平衡數據集、進行必要的數據預處理和標準化以及利用交叉驗證的變種方法等手段,可以提高數據分割的準確性和可靠性,進而提升模型的性能和泛化能力。
未來,隨著大數據和機器學習技術的不斷發展,數據分割方法也將不斷創新和完善。例如,可以利用無監督學習方法來自動發現數據中的隱藏結構和模式,以指導數據分割過程;也可以結合深度學習等先進技術來構建更加復雜和高效的模型評估框架。這些都將為機器學習領域帶來更多的機遇和挑戰。
-
測試模型
+關注
關注
0文章
5瀏覽量
5935 -
機器學習
+關注
關注
66文章
8496瀏覽量
134218
發布評論請先 登錄
一種基于機器學習的建筑物分割掩模自動正則化和多邊形化方法
機器學習簡介與經典機器學習算法人才培養
深度學習中圖像分割的方法和應用
分析總結基于深度神經網絡的圖像語義分割方法

深度學習在視頻對象分割中的應用及相關研究







 工商網監
工商網監
評論