") AI頂會(huì) “云”舉行,優(yōu)必選科技論文入選ICLR
AI頂會(huì) “云”舉行,優(yōu)必選科技論文入選ICLR

受全球范圍疫情爆發(fā)的影響,原定于4月25日在埃塞俄比亞首都亞的斯亞貝巴舉行的人工智能頂會(huì) ICLR 2020,宣布取消線(xiàn)下會(huì)議,完全改為線(xiàn)上。此前,2月7日在美國(guó)紐約舉辦的人工智能頂級(jí)會(huì)議AAAI2020,也采取了部分線(xiàn)上模式,讓不能到場(chǎng)的學(xué)者遠(yuǎn)程參會(huì)。
雖然疫情讓這些人工智能頂會(huì)充滿(mǎn)變數(shù),但絲毫不影響全球人工智能學(xué)者和研究人員的熱情,他們提交了大量重要研究成果的論文。優(yōu)必選悉尼大學(xué)人工智能研究中心今年也有數(shù)篇論文被人工智能頂會(huì)接收,其中,ICLR 2020有2篇,AAAI 2020有4篇,CVPR 2020有12篇。
ICLR(國(guó)際學(xué)習(xí)表征會(huì)議)于2013年成立,由Lecun,Hinton和Bengio三位神經(jīng)網(wǎng)絡(luò)的元老聯(lián)手發(fā)起。近年來(lái)隨著深度學(xué)習(xí)在工程實(shí)踐中的成功,ICLR也在短短的幾年中發(fā)展成為了神經(jīng)網(wǎng)絡(luò)的頂會(huì)。
今年,ICLR共收到了2594篇論文投稿,相比去年的1591篇論文投稿,增加了38.7%,其中687篇論文被接收,優(yōu)必選悉尼大學(xué)人工智能中心有2篇論文被接收。
一:分段線(xiàn)性激活實(shí)質(zhì)上塑造了神經(jīng)網(wǎng)絡(luò)的損失平面
摘要:理解神經(jīng)網(wǎng)絡(luò)的損失平面對(duì)于理解深度學(xué)習(xí)至關(guān)重要。本文介紹了分段線(xiàn)性激活函數(shù)是如何從根本上塑造神經(jīng)網(wǎng)絡(luò)損失平面的。我們首先證明了許多神經(jīng)網(wǎng)絡(luò)的損失平面具有無(wú)限的偽局部極小值,這些偽局部極小值被定義為經(jīng)驗(yàn)風(fēng)險(xiǎn)比全局極小值更高的局部極小值。我們的結(jié)果表明,分段線(xiàn)性激活網(wǎng)絡(luò)與已被人們充分研究的線(xiàn)性神經(jīng)網(wǎng)絡(luò)有著本質(zhì)區(qū)別。實(shí)踐中,這一結(jié)果適用于大多數(shù)損失函數(shù)中任何具有任意深度和任意分段線(xiàn)性激活函數(shù)(不包括線(xiàn)性函數(shù))的神經(jīng)網(wǎng)絡(luò)。本質(zhì)上,基本假設(shè)與大多數(shù)實(shí)際情況是一致的,即輸出層比任何隱藏層都窄。此外,利用不可微分的邊界將具有分段線(xiàn)性激活的神經(jīng)網(wǎng)絡(luò)的損失平面分割成多個(gè)光滑的多線(xiàn)性單元。所構(gòu)造的偽局部極小值以底谷的形式集中在一個(gè)單元中:它們通過(guò)一條經(jīng)驗(yàn)風(fēng)險(xiǎn)不變的連續(xù)路徑相互連接。對(duì)于單隱層網(wǎng)絡(luò),我們進(jìn)一步證明了一個(gè)單元中的所有局部最小值均構(gòu)成一個(gè)等價(jià)類(lèi)別;它們集中在一個(gè)底谷里;它們都是單元中的全局極小值。
二:理解遞歸神經(jīng)網(wǎng)絡(luò)中的泛化
摘要:在本文中,我們闡述了分析遞歸神經(jīng)網(wǎng)絡(luò)泛化性能的理論。我們首先基于矩陣1-范數(shù)和 Fisher-Rao 范數(shù)提出了一種新的遞歸神經(jīng)網(wǎng)絡(luò)的泛化邊界。Fisher-Rao 范數(shù)的定義依賴(lài)于有關(guān) RNN 梯度的結(jié)構(gòu)引理。這種新的泛化邊界假設(shè)輸入數(shù)據(jù)的協(xié)方差矩陣是正定的,這可能限制了它在實(shí)際中的應(yīng)用。為了解決這一問(wèn)題,我們提出在輸入數(shù)據(jù)中加入隨機(jī)噪聲,并證明了經(jīng)隨機(jī)噪聲(隨機(jī)噪聲是輸入數(shù)據(jù)的擴(kuò)展)訓(xùn)練的一個(gè)泛化邊界。與現(xiàn)有結(jié)果相比,我們的泛化邊界對(duì)網(wǎng)絡(luò)的規(guī)模沒(méi)有明顯的依賴(lài)關(guān)系。我們還發(fā)現(xiàn),遞歸神經(jīng)網(wǎng)絡(luò)(RNN)的 Fisher-Rao 范數(shù)可以解釋為梯度的度量,納入這種梯度度量不僅可以收緊邊界,而且可以在泛化和可訓(xùn)練性之間建立關(guān)系。在此基礎(chǔ)上,我們從理論上分析了特征協(xié)方差對(duì)神經(jīng)網(wǎng)絡(luò)泛化的影響,并討論了訓(xùn)練中的權(quán)值衰減和梯度裁剪可以如何改善神經(jīng)網(wǎng)絡(luò)泛化。
今年首場(chǎng)人工智能頂會(huì)AAAI 2020已于2月份在美國(guó)紐約舉辦,共評(píng)審了 7737 篇論文,最終接收了 1591 篇,接收率為 20.6%,優(yōu)必選悉尼大學(xué)人工智能中心有4篇論文被接收。
一:閱讀理解中的無(wú)監(jiān)督域自適應(yīng)學(xué)習(xí)
摘要:深度神經(jīng)網(wǎng)絡(luò)模型在很多閱讀理解(RC)任務(wù)數(shù)據(jù)集上已經(jīng)實(shí)現(xiàn)顯著的性能提升。但是,這些模型在不同領(lǐng)域的泛化能力仍然不清楚。為彌補(bǔ)這一空缺,我們研究了閱讀理解任務(wù)(RC)上的無(wú)監(jiān)督域自適應(yīng)問(wèn)題。研究過(guò)程中,我們?cè)跇?biāo)記源域上訓(xùn)練模型,并在僅有未標(biāo)記樣本的目標(biāo)域應(yīng)用模型。我們首先證明,即便使用強(qiáng)大的轉(zhuǎn)換器雙向編碼表征(BERT)上下文表征,在一個(gè)域上訓(xùn)練好的模型也不能在另一個(gè)域?qū)崿F(xiàn)很好的泛化能力。為了解決這個(gè)問(wèn)題,我們提供了一種新的條件對(duì)抗自訓(xùn)練方法(CASe)。具體來(lái)說(shuō),我們的方法利用在源數(shù)據(jù)集上微調(diào)的 BERT 模型以及置信度過(guò)濾,在目標(biāo)域中生成可靠的偽標(biāo)記樣本以進(jìn)行自訓(xùn)練。另一方面,我們的方法通過(guò)跨域的條件對(duì)抗學(xué)習(xí),進(jìn)一步減小了域之間的分布差異。大量實(shí)驗(yàn)表明,我們的方法在多個(gè)大規(guī)模基準(zhǔn)數(shù)據(jù)集上實(shí)現(xiàn)了與監(jiān)督模型相當(dāng)?shù)男阅堋?/p>
特征圖:方法框架
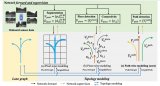
二:Grapy-ML:跨數(shù)據(jù)集人體解析的圖像金字塔相互學(xué)習(xí)
摘要:人體解析,即人體部位語(yǔ)義分割,因其具有廣泛的潛在應(yīng)用前景而成為一個(gè)研究熱點(diǎn)。在本文中,我們提出一種新的圖金字塔互學(xué)習(xí)(Grapy-ML)方法來(lái)解決標(biāo)注粒度不同的跨數(shù)據(jù)集的人體解析問(wèn)題。從人體層次結(jié)構(gòu)的先驗(yàn)知識(shí)出發(fā),我們將三層圖結(jié)構(gòu)按照粗粒度到細(xì)粒度的順序進(jìn)行疊加,設(shè)計(jì)出了一個(gè)新的圖金字塔模型(GPM)。GPM在每一層都會(huì)利用自關(guān)注機(jī)制對(duì)上下文節(jié)點(diǎn)之間的相關(guān)性進(jìn)行建模。然后,它采用了自上而下的機(jī)制來(lái)逐步細(xì)化各個(gè)層級(jí)的特征。GPM還使得高效的互學(xué)習(xí)成為可能。具體來(lái)說(shuō),為了在不同的數(shù)據(jù)集之間交換所學(xué)習(xí)到的粗粒度信息,我們共享了GPM前兩級(jí)的網(wǎng)絡(luò)權(quán)值并使用跨數(shù)據(jù)集的多粒度標(biāo)簽,使得所提出的Grapy-ML模型可以學(xué)習(xí)到更具區(qū)分性的特征表示并獲得了最先進(jìn)的性能。這點(diǎn)在三個(gè)流行基準(zhǔn)(例如:CIHP 數(shù)據(jù)集)的大量實(shí)驗(yàn)中得到了證明。源代碼已經(jīng)對(duì)外公開(kāi),參見(jiàn):https://github.com/Charleshhy/Grapy-ML。
特征圖:提出的 Grapy-ML 圖
三:多元貝葉斯非負(fù)矩陣分解
摘要:由于具有誘導(dǎo)含有語(yǔ)義的基于部位的表示的能力,非負(fù)矩陣分解(NMF)已被廣泛應(yīng)用于各種場(chǎng)景。但是,由于其目標(biāo)函數(shù)的非凸性,部位分解通常不是唯一的,因此可能無(wú)法準(zhǔn)確地發(fā)現(xiàn)數(shù)據(jù)內(nèi)在的“部位”。在本文中,我們使用貝葉斯框架來(lái)處理這個(gè)問(wèn)題。首先,基于有用部位應(yīng)該是有區(qū)別的且覆蓋性廣的假設(shè),賦予分解中的多個(gè)部位多元性先驗(yàn),從而來(lái)誘導(dǎo)分解部位的正確性。其次,包含這種多元性先驗(yàn)的貝葉斯框架被建立了起來(lái)。該框架得到的分解部位既有極大似然誘導(dǎo)的較高的數(shù)據(jù)適合度,又有多元性先驗(yàn)帶來(lái)的較高的可分離性。具體來(lái)說(shuō),多元性先驗(yàn)通過(guò)行列式點(diǎn)過(guò)程(DPP)建模,并無(wú)縫嵌入到貝葉斯 NMF 框架中。推斷基于蒙特卡洛馬爾可夫鏈(MCMC)的方法。最后,我們通過(guò)一個(gè)合成數(shù)據(jù)集和一個(gè)用于多標(biāo)簽學(xué)習(xí)(MLL)任務(wù)的實(shí)際數(shù)據(jù)集-MULAN-展示了該方法的優(yōu)越性。
特征圖:提議的架構(gòu)的圖示
四:生成-判別互補(bǔ)學(xué)習(xí)
摘要:目前最先進(jìn)的深度學(xué)習(xí)方法大多是對(duì)給定輸入特征的標(biāo)簽的條件分布進(jìn)行建模的判別法。這種方法的成功在很大程度上依賴(lài)于高質(zhì)量的帶標(biāo)簽的實(shí)例,此類(lèi)實(shí)例并不容易獲得,特別是在候選類(lèi)別數(shù)量增加的情況下。本文研究了互補(bǔ)學(xué)習(xí)問(wèn)題。與普通標(biāo)簽不同,互補(bǔ)標(biāo)簽很容易獲得,因?yàn)樽⑨屍髦恍枰獮槊總€(gè)實(shí)例隨機(jī)選擇的候選類(lèi)別提供一個(gè)“是/否”的答案。我們提出了一種生成-判別互補(bǔ)學(xué)習(xí)方法。該方法通過(guò)對(duì)條件(判別)分布和實(shí)例(生成)分布的建模,對(duì)普通標(biāo)簽進(jìn)行估計(jì)。我們將該方法稱(chēng)為互補(bǔ)條件生成對(duì)抗網(wǎng)絡(luò)(CCGAN)。這種方法提高了預(yù)測(cè)普通標(biāo)簽的準(zhǔn)確性,并能夠在弱監(jiān)督的情況下生成高質(zhì)量的實(shí)例。除了大量的實(shí)證研究外,我們還從理論上證明,我們的模型可以從互補(bǔ)標(biāo)記數(shù)據(jù)中檢索出真實(shí)的條件分布。
特征圖:模型結(jié)構(gòu)
計(jì)算機(jī)視覺(jué)頂會(huì)CVPR 2020將于6月14日-19日在美國(guó)西雅圖舉行,今年的論文錄取率降至22.1%(2019年錄取率25.1%,2018年錄取率29.6% )。雖然論文錄取難度逐年增大,但是優(yōu)必選悉尼大學(xué)人工智能中心在CVPR的成績(jī)依舊斐然,后續(xù)將會(huì)帶來(lái)12篇錄取論文的詳細(xì)介紹。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103440 -
人工智能
+關(guān)注
關(guān)注
1806文章
48984瀏覽量
248915 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5560瀏覽量
122750
發(fā)布評(píng)論請(qǐng)先 登錄
人形機(jī)器人風(fēng)向標(biāo)!優(yōu)必選全球首次批量入廠,并斬獲萬(wàn)臺(tái)大單
格靈深瞳六篇論文入選ICCV 2025
比亞迪騰勢(shì)N9第1萬(wàn)輛交付優(yōu)必選科技創(chuàng)始人
后摩智能四篇論文入選三大國(guó)際頂會(huì)
云知聲四篇論文入選自然語(yǔ)言處理頂會(huì)ACL 2025

優(yōu)必選人形科研組合拳閃亮FAIR plus展 全方位帶動(dòng)共研共創(chuàng)
后摩智能5篇論文入選國(guó)際頂會(huì)

領(lǐng)克汽車(chē)成都工廠引入優(yōu)必選無(wú)人物流方案
優(yōu)必選公告:擬斥資不超2億實(shí)施股權(quán)激勵(lì)計(jì)劃
云知聲榮登2024全球AIGC先鋒者系列榜單
優(yōu)必選與UQI優(yōu)奇發(fā)布全棧式無(wú)人物流解決方案
經(jīng)緯恒潤(rùn)功能安全AI 智能體論文成功入選EMNLP 2024!

麥迪科技與優(yōu)必選達(dá)成合作,共推AI醫(yī)療康養(yǎng)發(fā)展
地平線(xiàn)科研論文入選國(guó)際計(jì)算機(jī)視覺(jué)頂會(huì)ECCV 2024





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論