 數據中心依靠服務器為其計算密集型架構提供支持
數據中心依靠服務器為其計算密集型架構提供支持
(文章來源:教育新聞網)
支持AI和ML部署的數據中心依靠基于圖形處理單元(GPU)的服務器為其計算密集型架構提供支持。在多個行業中,到2024年,GPU使用量的增長將落后于GPU服務器預計超過31%的復合年增長率。這意味著將承擔更多的系統架構師的職責,以確保GPU系統具有最高的性能和成本效益。
然而,為這些基于GPU的AI / ML工作負載優化存儲并非易事。存儲系統必須高速處理海量數據,同時應對兩個挑戰:
服務器利用率1)。GPU服務器對于訓練大型AI / ML數據集所需的矩陣乘法和卷積非常高效。但是,GPU服務器的成本是典型CPU服務器的3倍。為了保持ROI,IT員工需要保持GPU繁忙。不幸的是,豐富的部署經驗表明GPU僅以30%的容量使用。
該2)。ML訓練數據集通常遠遠超過GPU的本地RAM容量,從而創建了一個I / O瓶頸,分析人員將其稱為GPU存儲瓶頸。AI和ML系統最終要等待訪問存儲資源,這是因為它們的龐大規模阻礙了及時訪問,從而影響了性能。為了解決這個問題,NVMe閃存固態硬盤逐漸取代了標準閃存固態硬盤,成為Al / ML存儲的首選。
NVMe支持大規模的IO并行性,性能約為同類SATA SSD的6倍,并且延遲降低了10倍,并且具有更高的電源效率。正如GPU推動了高性能計算的發展一樣,NVMe閃存在降低延遲的同時,實現了更高的存儲性能,帶寬和IO / s。NVMe閃存解決方案可以將AI和ML數據集加載到應用程序的速度更快,并且可以避免GPU匱乏。
此外,可通過高速網絡虛擬化NVMe資源的基于光纖的NVMe(NVMeoF)啟用了特別適用于AI和ML的存儲架構。NVMeoF使GPU可以直接訪問NVMe的彈性池,因此可以使用本地閃存性能來訪問所有資源。它使AI數據科學家和HPC研究人員可以向應用程序提供更多數據,以便他們更快地獲得更好的結果。
要獲得最佳的GPU存儲性能,就需要根據業務目標對基礎架構進行微調。這里有四種方法可供考慮:
有效擴展GPU存儲容量1)例如,InstaDeep為可能不需要或不需要運行自己的AI堆棧的組織提供了AI即服務解決方案。因此,InstaDeep需要最大的ROI和可擴展性。特別是,對多租戶的需求意味著基礎架構必須隨時準備就緒,以滿足各種工作負載和客戶端的性能要求。
InstaDeep基礎架構團隊在部署其第一個GPU服務器系統的早期就了解到,本地GPU服務器的存儲容量將太有限,只有4TB的本地存儲,而客戶的工作量則需要10到100 TB的TB。該團隊研究了外部存儲選項,并注意到,使用傳統陣列它們將獲得更多的容量,但性能最終會阻礙AI工作負載,因為應用程序需要將數據移入和移出GPU系統,從而中斷工作流程并影響系統效率。
通過使用軟件定義的存儲在快速的RDMA網絡上合并NVMe閃存(一種將數據集加載速度提高10倍的方法),InstaDeep可以實現更高的GPU容量利用率,消除了GPU瓶頸并提高了ROI,因為現有的GPU變得更加完整利用。
(責任編輯:fqj)
-
服務器
+關注
關注
12文章
9547瀏覽量
86830 -
數據中心
+關注
關注
16文章
5039瀏覽量
72957
發布評論請先 登錄
相關推薦
適用于數據中心和AI時代的800G網絡
優化800G數據中心:高速線纜、有源光纜和光纖跳線解決方案
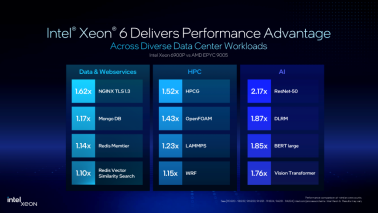
英特爾至強6:如何煉就數據中心“全能型選手”
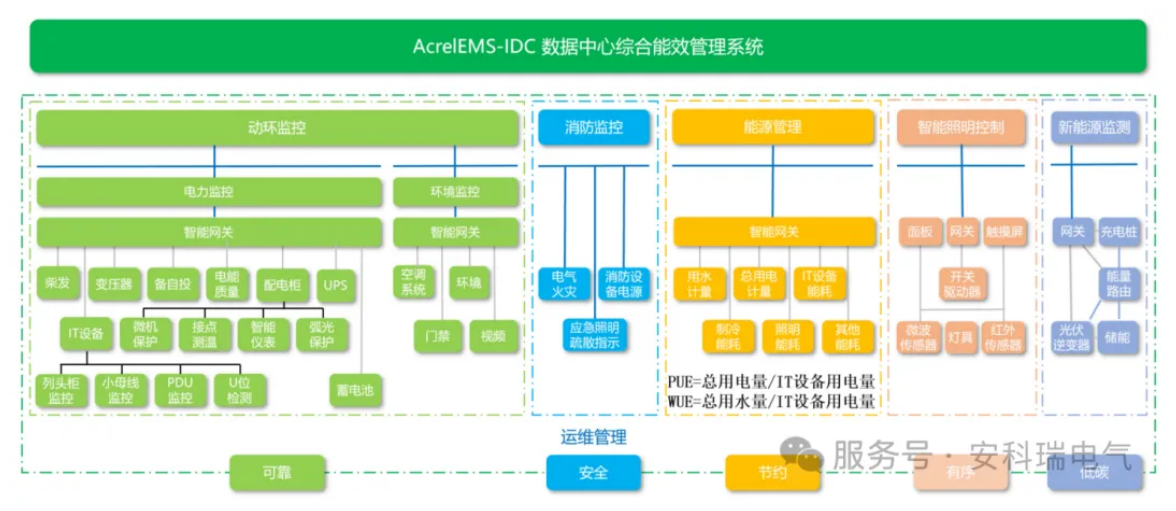
數據中心發展與改造
云計算與數據中心的關系
就服務器而言,ARM架構與X86架構有什么區別?各自的優勢在哪里?
需要合理規劃數據中心不能盲目建設
哪些是數據中心的重要系統?
機房托管服務器說明
借助電源完整性測試提高人工智能數據中心的能效

數據中心液冷需求、技術及實際應用





 工商網監
工商網監
評論