") Linux網(wǎng)絡(luò)子系統(tǒng)的DMA機(jī)制是如何的實(shí)現(xiàn)的
Linux網(wǎng)絡(luò)子系統(tǒng)的DMA機(jī)制是如何的實(shí)現(xiàn)的
我們先從計(jì)算機(jī)組成原理的層面介紹DMA,再簡(jiǎn)單介紹Linux網(wǎng)絡(luò)子系統(tǒng)的DMA機(jī)制是如何的實(shí)現(xiàn)的。
一、計(jì)算機(jī)組成原理中的DMA
以往的I/O設(shè)備和主存交換信息都要經(jīng)過(guò)CPU的操作。不論是最早的輪詢方式,還是我們學(xué)過(guò)的中斷方式。雖然中斷方式相比輪詢方式已經(jīng)節(jié)省了大量的CPU資源。但是在處理大量的數(shù)據(jù)時(shí),DMA相比中斷方式進(jìn)一步解放了CPU。
DMA就是Direct Memory Access,意思是I/O設(shè)備直接存儲(chǔ)器訪問(wèn),幾乎不消耗CPU的資源。在I/O設(shè)備和主存?zhèn)鬟f數(shù)據(jù)的時(shí)候,CPU可以處理其他事。
1. I/O設(shè)備與主存信息傳送的控制方式
I/O設(shè)備與主存信息傳送的控制方式分為程序輪詢、中斷、DMA、RDMA等。
先用“圖1”大體上說(shuō)明幾種控制方式的區(qū)別,其中黃線代表程序輪詢方式,綠線代表中斷方式,紅線代表DMA方式,黑線代表RDMA方式,藍(lán)線代表公用的線。可以看出DMA方式與程序輪詢方式還有中斷方式的區(qū)別是傳輸數(shù)據(jù)跳過(guò)了CPU,直接和主存交流。
“圖1”中的“接口”既包括實(shí)現(xiàn)某一功能的硬件電路,也包括相應(yīng)的控制軟件,如 “DMA接口” 就是一些實(shí)現(xiàn)DMA機(jī)制的硬件電路和相應(yīng)的控制軟件。
“DMA接口”有時(shí)也叫做“DMA控制器”(DMAC)。
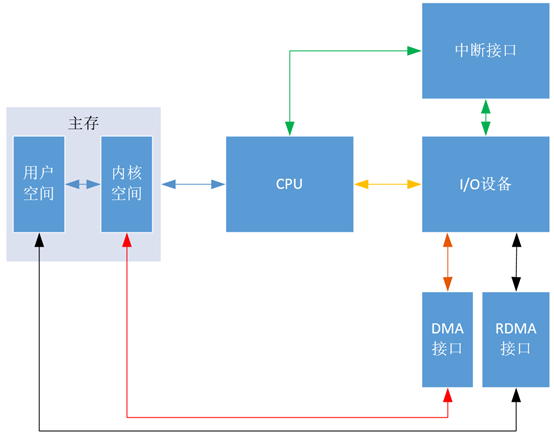
圖1
上周分享“圖1”時(shí),劉老師說(shuō)在DMA方式下, DMA控制器(即DMA接口)也是需要和CPU交流的,但是圖中沒(méi)有顯示DMA控制器與CPU交流信息。但是這張圖我是按照哈工大劉宏偉老師的《計(jì)算機(jī)組成原理》第五章的內(nèi)容畫(huà)出的,應(yīng)該是不會(huì)有問(wèn)題的。查找了相關(guān)資料,覺(jué)得兩個(gè)劉老師都沒(méi)有錯(cuò),因?yàn)檫@張圖強(qiáng)調(diào)的是數(shù)據(jù)的走向,即這里的線僅是數(shù)據(jù)線。如果要嚴(yán)格一點(diǎn),把控制線和地址線也畫(huà)出來(lái),將是“圖2”這個(gè)樣子:
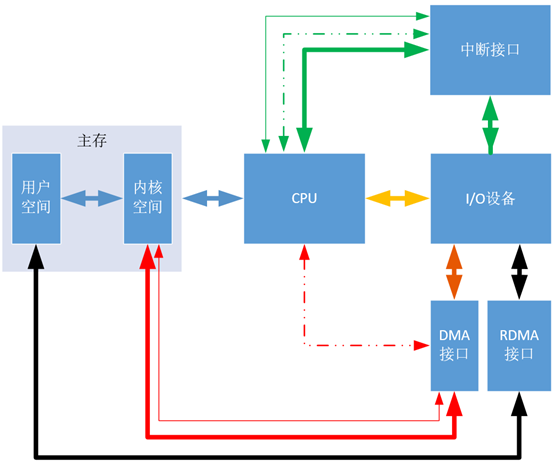
圖2
這里新增了中斷方式的地址線和控制線、DMA方式的地址線和控制線。(“圖2”也是自己繪制,其理論依據(jù)參考“圖3”,這里不對(duì)“圖3”進(jìn)行具體分析,因?yàn)樯婕暗讓拥挠布R(shí))
“圖2”對(duì)“圖1”的數(shù)據(jù)線加粗,新增細(xì)實(shí)線表示地址線,細(xì)虛線表示控制線。可以看出在中斷方式下,無(wú)論是傳輸數(shù)據(jù)、地址還是控制信息,都要經(jīng)過(guò)CPU,即都要在CPU的寄存器中暫存一下,都要浪費(fèi)CPU的資源;但是在DMA方式下,傳輸數(shù)據(jù)和地址時(shí),I/O設(shè)備可以通過(guò)“DMA接口”直接與主存交流,只有傳輸控制信息時(shí),才需要用到CPU。而傳輸控制信息占用的時(shí)間是極小的,可以忽略不計(jì),所以可以認(rèn)為DMA方式完全沒(méi)有占用CPU資源,這等價(jià)于I/O設(shè)備和CPU可以實(shí)現(xiàn)真正的并行工作,這比中斷方式下的并行程度要更高很多。
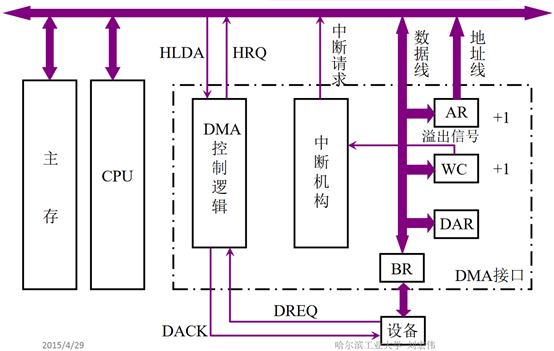
圖3
2. 三種方式的CPU工作效率比較
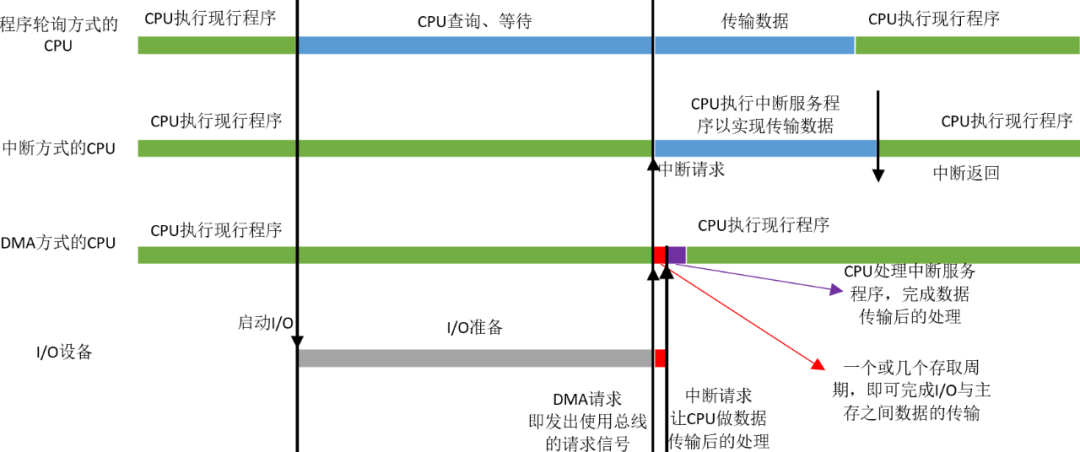
在I/O準(zhǔn)備階段,程序輪詢方式的CPU一直在查詢等待,而中斷方式的CPU可以繼續(xù)執(zhí)行現(xiàn)行程序,但是當(dāng)I/O準(zhǔn)備就緒,設(shè)備向CPU發(fā)出中斷請(qǐng)求,CPU響應(yīng)以實(shí)現(xiàn)數(shù)據(jù)的傳輸,這個(gè)過(guò)程會(huì)占用CPU一段時(shí)間,而且這段時(shí)間比使用程序輪詢方式的CPU傳輸數(shù)據(jù)的時(shí)間還要長(zhǎng),因?yàn)镃PU除了傳輸數(shù)據(jù)還要做一些準(zhǔn)備工作,如把CPU寄存器中的數(shù)據(jù)都轉(zhuǎn)移到棧中。
但是DMA方式不一樣,當(dāng)I/O準(zhǔn)備就緒,設(shè)備向CPU發(fā)出DMA請(qǐng)求,CPU響應(yīng)請(qǐng)求,關(guān)閉對(duì)主存的控制器,只關(guān)閉一個(gè)或者幾個(gè)存取周期,在這一小段時(shí)間內(nèi),主存和設(shè)備完成數(shù)據(jù)交換。而且在這一小段時(shí)間內(nèi),CPU并不是什么都不能做,雖然CPU不能訪問(wèn)主存,即不能取指令,但是CPU的cache中已經(jīng)保存了一些指令,CPU可以先執(zhí)行這些指令,只要這些指令不涉及訪存,CPU和設(shè)備還是并行執(zhí)行。數(shù)據(jù)傳輸完成后,DMA接口向CPU發(fā)出中斷請(qǐng)求,讓CPU做后續(xù)處理。大家可能會(huì)奇怪DMA接口為什么也能發(fā)出中斷請(qǐng)求,其實(shí)DMA接口內(nèi)有一個(gè)中斷機(jī)構(gòu),見(jiàn)“圖3”,DMA技術(shù)其實(shí)是建立在中斷技術(shù)之上的,它包含了中斷技術(shù)。
總之,在同樣的時(shí)間內(nèi),DMA方式下CPU執(zhí)行現(xiàn)行程序的時(shí)間最長(zhǎng),即CPU的效率最高。
二、Linux網(wǎng)絡(luò)子系統(tǒng)中DMA機(jī)制的實(shí)現(xiàn)
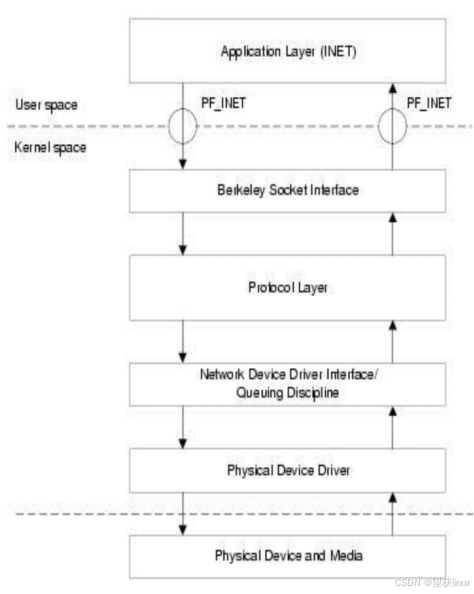
1. DMA機(jī)制在TCP/IP協(xié)議模型中的位置
網(wǎng)卡明顯是一個(gè)數(shù)據(jù)流量特別大的地方,所以特別需要DMA方式和主存交換數(shù)據(jù)。
主存的內(nèi)核空間中為接收和發(fā)送數(shù)據(jù)分別建立了兩個(gè)環(huán)形緩沖區(qū)(Ring Buffer)。分別叫接受環(huán)形緩沖區(qū)(Receive Ring Buffer)和發(fā)送環(huán)形緩沖區(qū)(Send Ring Buffer),通常也叫DMA環(huán)形緩沖區(qū)。
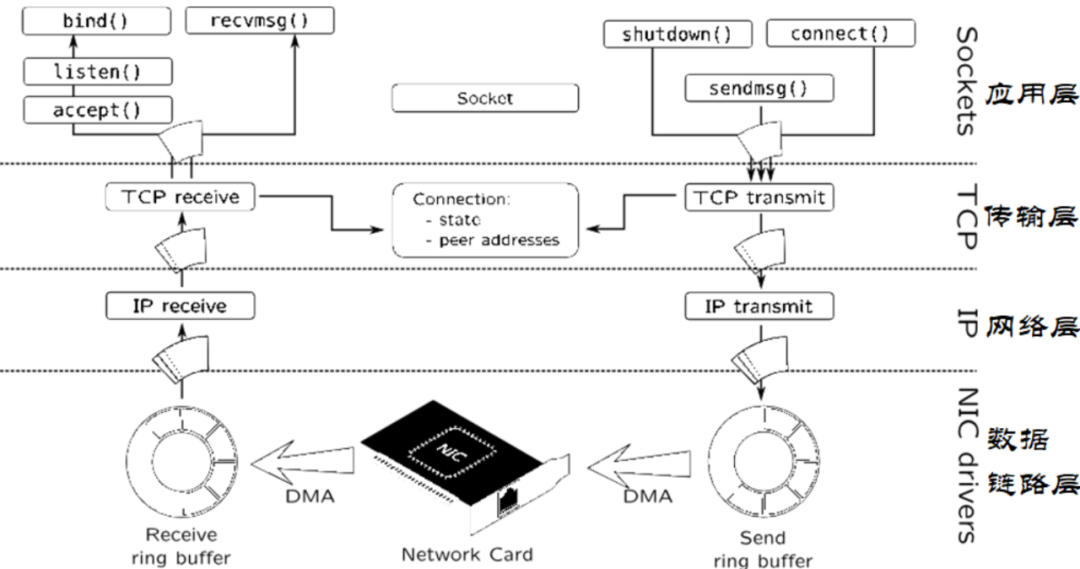
下圖可以看到DMA機(jī)制位于TCP/IP協(xié)議模型中的位置數(shù)據(jù)鏈路層。
網(wǎng)卡通過(guò)DMA方式將數(shù)據(jù)發(fā)送到Receive Ring Buffer,然后Receive Ring Buffer把數(shù)據(jù)包傳給IP協(xié)議所在的網(wǎng)絡(luò)層,然后再由路由機(jī)制傳給TCP協(xié)議所在的傳輸層,最終傳給用戶進(jìn)程所在的應(yīng)用層。下一節(jié)在數(shù)據(jù)鏈路層上分析具體分析網(wǎng)卡是如何處理數(shù)據(jù)包的。
2. 數(shù)據(jù)鏈路層上網(wǎng)卡對(duì)數(shù)據(jù)包的處理
DMA 環(huán)形緩沖區(qū)建立在與處理器共享的內(nèi)存中。每一個(gè)輸入數(shù)據(jù)包被放置在環(huán)形緩沖區(qū)中下一個(gè)可用緩沖區(qū),然后發(fā)出中斷。接著驅(qū)動(dòng)程序?qū)⒕W(wǎng)絡(luò)數(shù)據(jù)包傳給內(nèi)核的其它部分處理,并在環(huán)形緩沖區(qū)中放置一個(gè)新的 DMA 緩沖區(qū)。
驅(qū)動(dòng)程序在初始化時(shí)分配DMA緩沖區(qū),并使用驅(qū)動(dòng)程序直到停止運(yùn)行。
準(zhǔn)備工作:
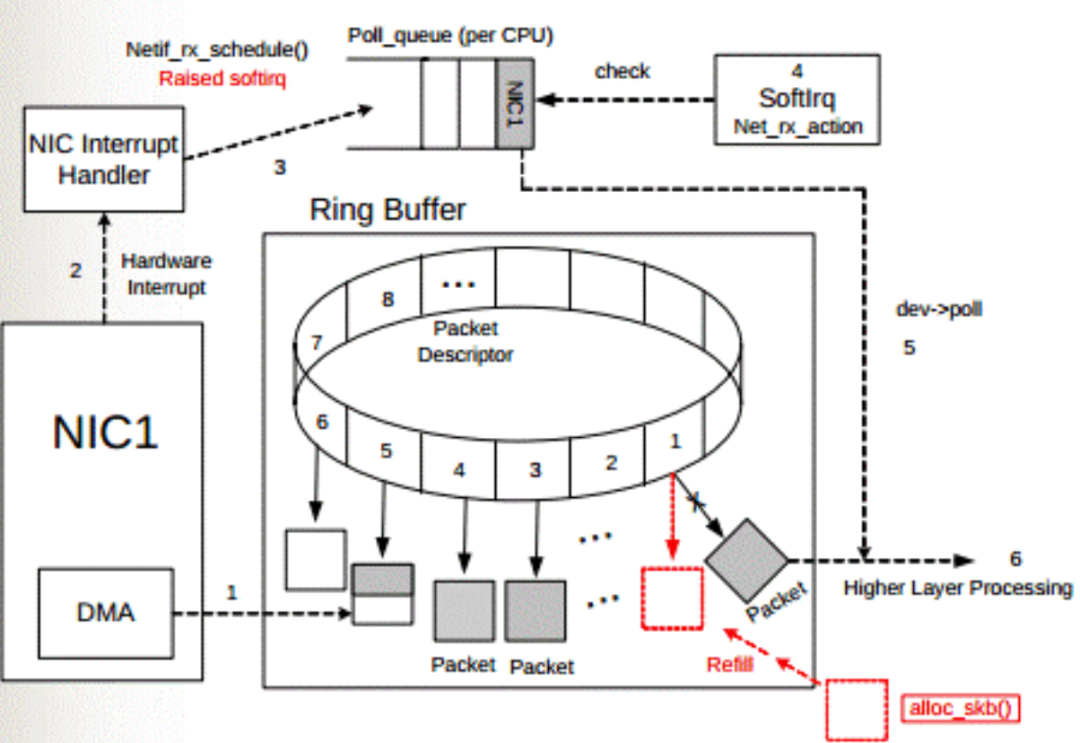
系統(tǒng)啟動(dòng)時(shí)網(wǎng)卡(NIC)進(jìn)行初始化,在內(nèi)存中騰出空間給Ring Buffer。Ring Buffer隊(duì)列每個(gè)中的每個(gè)元素Packet Descriptor指向一個(gè)sk_buff,狀態(tài)均為ready。
上圖中虛線步驟的解釋:
1.DMA 接口將網(wǎng)卡(NIC)接收的數(shù)據(jù)包(packet)逐個(gè)寫(xiě)入 sk_buff ,被寫(xiě)入數(shù)據(jù)的 sk_buff 變?yōu)?used 狀態(tài)。一個(gè)數(shù)據(jù)包可能占用多個(gè) sk_buff , sk_buff讀寫(xiě)順序遵循先入先出(FIFO)原則。
2.DMA 寫(xiě)完數(shù)據(jù)之后,網(wǎng)卡(NIC)向網(wǎng)卡中斷控制器(NIC Interrupt Handler)觸發(fā)硬件中斷請(qǐng)求。
3.NIC driver 注冊(cè) poll 函數(shù)。
4.poll 函數(shù)對(duì)數(shù)據(jù)進(jìn)行檢查,例如將幾個(gè) sk_buff 合并,因?yàn)榭赡芡粋€(gè)數(shù)據(jù)可能被分散放在多個(gè) sk_buff 中。
5.poll 函數(shù)將 sk_buff 交付上層網(wǎng)絡(luò)棧處理。
后續(xù)處理:
poll 函數(shù)清理 sk_buff,清理 Ring Buffer 上的 Descriptor 將其指向新分配的 sk_buff 并將狀態(tài)設(shè)置為 ready。
3.源碼分析具體網(wǎng)卡(4.19內(nèi)核)
Intel的千兆以太網(wǎng)卡e1000使用非常廣泛,我虛擬機(jī)上的網(wǎng)卡就是它。
這里就以該網(wǎng)卡的驅(qū)動(dòng)程序?yàn)槔醪椒治鏊窃趺唇MA機(jī)制的。
源碼目錄及文件:
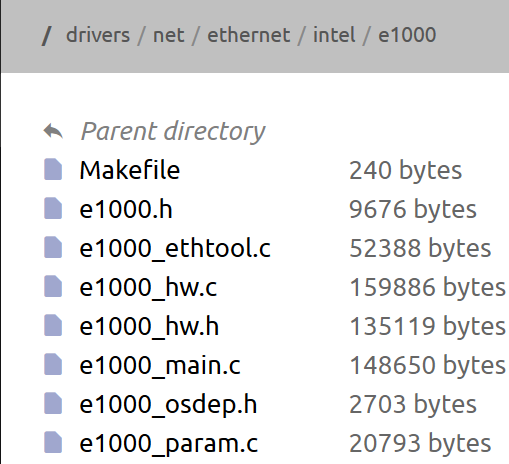
內(nèi)核模塊插入函數(shù)在e1000_main.c文件中,它是加載驅(qū)動(dòng)程序時(shí)調(diào)用的第一個(gè)函數(shù)。
/** * e1000_init_module - Driver Registration Routine * * e1000_init_module is the first routine called when the driver is * loaded. All it does is register with the PCI subsystem. **/ static int __init e1000_init_module(void) { int ret; pr_info("%s - version %s ", e1000_driver_string, e1000_driver_version); pr_info("%s ", e1000_copyright); ret = pci_register_driver(&e1000_driver); if (copybreak != COPYBREAK_DEFAULT) { if (copybreak == 0) pr_info("copybreak disabled "); else pr_info("copybreak enabled for " "packets <= %u bytes ", copybreak); } return ret; } module_init(e1000_init_module);
該函數(shù)所做的只是向PCI子系統(tǒng)注冊(cè),這樣CPU就可以訪問(wèn)網(wǎng)卡了,因?yàn)镃PU和網(wǎng)卡是通過(guò)PCI總線相連的。
具體做法是,在第230行,通過(guò)pci_register_driver()函數(shù)將e1000_driver這個(gè)驅(qū)動(dòng)程序注冊(cè)到PCI子系統(tǒng)。
e1000_driver是struct pci_driver類型的結(jié)構(gòu)體,
static struct pci_driver e1000_driver = { .name = e1000_driver_name, .id_table = e1000_pci_tbl, .probe = e1000_probe, .remove = e1000_remove, #ifdef CONFIG_PM /* Power Management Hooks */ .suspend = e1000_suspend, .resume = e1000_resume, #endif .shutdown = e1000_shutdown, .err_handler = &e1000_err_handler };
e1000_driver```里面初始化了設(shè)備的名字為“e1000”,

還定義了一些操作,如插入新設(shè)備、移除設(shè)備等,還包括電源管理相關(guān)的暫停操作和喚醒操作。下面是struct pci_driver一些主要的域。

對(duì)該驅(qū)動(dòng)程序稍微了解后,先跳過(guò)其他部分,直接看DMA相關(guān)代碼。在e1000_probe函數(shù),即“插入新設(shè)備”函數(shù)中,下面這段代碼先對(duì)DMA緩沖區(qū)的大小進(jìn)行檢查
如果是64位DMA地址,則把pci_using_dac標(biāo)記為1,表示可以使用64位硬件,掛起32位的硬件;如果是32位DMA地址,則使用32位硬件;若不是64位也不是32位,則報(bào)錯(cuò)“沒(méi)有可用的DMA配置,中止程序”。
/* there is a workaround being applied below that limits * 64-bit DMA addresses to 64-bit hardware. There are some * 32-bit adapters that Tx hang when given 64-bit DMA addresses */ pci_using_dac = 0; if ((hw->bus_type == e1000_bus_type_pcix) && !dma_set_mask_and_coherent(&pdev->dev, DMA_BIT_MASK(64))) { pci_using_dac = 1; } else { err = dma_set_mask_and_coherent(&pdev->dev, DMA_BIT_MASK(32)); if (err) { pr_err("No usable DMA config, aborting "); goto err_dma; } }
其中的函數(shù)dma_set_mask_and_coherent()用于對(duì)dma_mask和coherent_dma_mask賦值。
dma_mask表示的是該設(shè)備通過(guò)DMA方式可尋址的物理地址范圍,coherent_dma_mask表示所有設(shè)備通過(guò)DMA方式可尋址的公共的物理地址范圍,
因?yàn)椴皇撬械挠布O(shè)備都能夠支持64bit的地址寬度。
/include/linux/dma-mapping.h
/* * Set both the DMA mask and the coherent DMA mask to the same thing. * Note that we don't check the return value from dma_set_coherent_mask() * as the DMA API guarantees that the coherent DMA mask can be set to * the same or smaller than the streaming DMA mask. */ static inline int dma_set_mask_and_coherent(struct device *dev, u64 mask) { int rc = dma_set_mask(dev, mask); if (rc == 0) dma_set_coherent_mask(dev, mask); return rc; }
rc==0表示該設(shè)備的dma_mask賦值成功,所以可以接著對(duì)coherent_dma_mask賦同樣的值。
繼續(xù)閱讀e1000_probe函數(shù),
if (pci_using_dac) { netdev->features |= NETIF_F_HIGHDMA; netdev->vlan_features |= NETIF_F_HIGHDMA; }
如果pci_using_dac標(biāo)記為1,則當(dāng)前網(wǎng)絡(luò)設(shè)備的features域(表示當(dāng)前活動(dòng)的設(shè)備功能)和vlan_features域(表示VLAN設(shè)備可繼承的功能)都賦值為NETIF_F_HIGHDMA,NETIF_F_HIGHDMA表示當(dāng)前設(shè)備可以通過(guò)DMA通道訪問(wèn)到高地址的內(nèi)存。
因?yàn)榍懊娣治鲞^(guò),pci_using_dac標(biāo)記為1時(shí),當(dāng)前設(shè)備是64位的。e1000_probe函數(shù)完成了對(duì)設(shè)備的基本初始化,接下來(lái)看如何初始化接收環(huán)形緩沖區(qū)。
/** * e1000_setup_rx_resources - allocate Rx resources (Descriptors) * @adapter: board private structure * @rxdr: rx descriptor ring (for a specific queue) to setup * * Returns 0 on success, negative on failure **/ static int e1000_setup_rx_resources(struct e1000_adapter *adapter, struct e1000_rx_ring *rxdr) { ''''''' rxdr->desc = dma_alloc_coherent(&pdev->dev, rxdr->size, &rxdr->dma, GFP_KERNEL); '''''' memset(rxdr->desc, 0, rxdr->size); rxdr->next_to_clean = 0; rxdr->next_to_use = 0; rxdr->rx_skb_top = NULL; return 0; }
這里dma_alloc_coherent()的作用是申請(qǐng)一塊DMA可使用的內(nèi)存,它的返回值是這塊內(nèi)存的虛擬地址,賦值給rxdr->desc。其實(shí)這個(gè)函數(shù)還隱式的返回了物理地址,物理地址存在第三個(gè)參數(shù)中。指針rxdr指向的是struct e1000_rx_ring這個(gè)結(jié)構(gòu)體,該結(jié)構(gòu)體就是接收環(huán)形緩沖區(qū)。
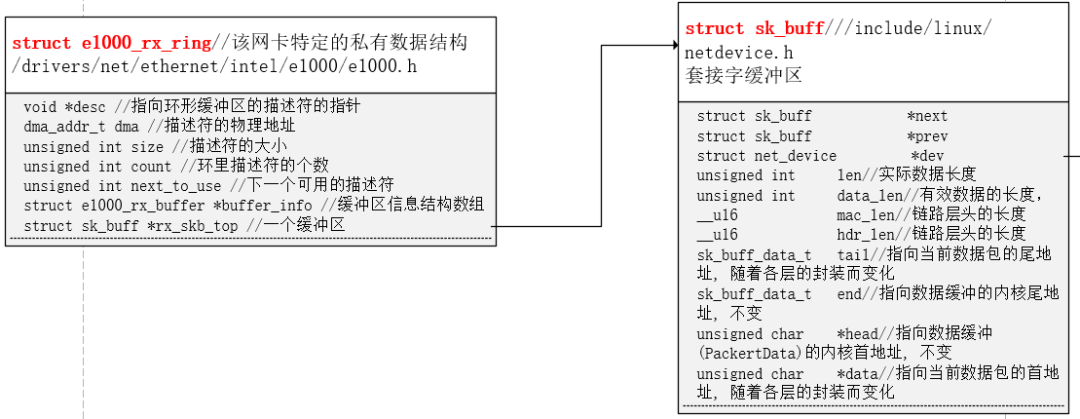
若成功申請(qǐng)到DMA內(nèi)存,則用memset()函數(shù)把申請(qǐng)的內(nèi)存清零,rxdr的其他域也清零。
對(duì)于現(xiàn)在的多核CPU,每個(gè)CPU都有自己的接收環(huán)形緩沖區(qū),e1000_setup_all_rx_resources()中調(diào)用e1000_setup_rx_resources(),初始化所有的接收環(huán)形緩沖區(qū)。
int e1000_setup_all_rx_resources(struct e1000_adapter *adapter) { int i, err = 0; for (i = 0; i < adapter->num_rx_queues; i++) { err = e1000_setup_rx_resources(adapter, &adapter->rx_ring[i]); if (err) { e_err(probe, "Allocation for Rx Queue %u failed ", i); for (i-- ; i >= 0; i--) e1000_free_rx_resources(adapter, &adapter->rx_ring[i]); break; } } return err; }
e1000_setup_all_rx_resources()由e1000_open()調(diào)用,也就是說(shuō)只要打開(kāi)該網(wǎng)絡(luò)設(shè)備,接收和發(fā)送環(huán)形緩沖區(qū)就會(huì)建立好。
int e1000_open(struct net_device *netdev) { struct e1000_adapter *adapter = netdev_priv(netdev); struct e1000_hw *hw = &adapter->hw; int err; /* disallow open during test */ if (test_bit(__E1000_TESTING, &adapter->flags)) return -EBUSY; netif_carrier_off(netdev); /* allocate transmit descriptors */ err = e1000_setup_all_tx_resources(adapter); if (err) goto err_setup_tx; /* allocate receive descriptors */ err = e1000_setup_all_rx_resources(adapter); if (err) goto err_setup_rx;
-
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7637瀏覽量
166548 -
Linux
+關(guān)注
關(guān)注
87文章
11469瀏覽量
212923 -
dma
+關(guān)注
關(guān)注
3文章
574瀏覽量
102420
原文標(biāo)題:LINUX網(wǎng)絡(luò)子系統(tǒng)中DMA機(jī)制的實(shí)現(xiàn)
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
NTP網(wǎng)絡(luò)子鐘的技術(shù)架構(gòu)與行業(yè)應(yīng)用解析
如何將FX3與WSL(Linux 的 Windows 子系統(tǒng))一起使用?
Linux系統(tǒng)中通過(guò)預(yù)留物理內(nèi)存實(shí)現(xiàn)ARM與FPGA高效通信的方法

嵌入式學(xué)習(xí)-飛凌嵌入式ElfBoard ELF 1板卡-input子系統(tǒng)之input子系統(tǒng)簡(jiǎn)介
飛凌嵌入式ElfBoard ELF 1板卡-input子系統(tǒng)之input子系統(tǒng)簡(jiǎn)介
詳解deepin 25 Preview的Distrobox子系統(tǒng)
DMA是什么?詳細(xì)介紹
使用bq4845實(shí)現(xiàn)低成本RTC/NVSRAM子系統(tǒng)

使用bq4845實(shí)現(xiàn)低成本RTC/NVSRAM子系統(tǒng)
詳解linux內(nèi)核的uevent機(jī)制
深度解析linux時(shí)鐘子系統(tǒng)
Simplelink? Wi-Fi? CC3x3x網(wǎng)絡(luò)子系統(tǒng)電源管理
Linux網(wǎng)絡(luò)協(xié)議棧的實(shí)現(xiàn)
Linux內(nèi)核中的頁(yè)面分配機(jī)制

linux--LED子系統(tǒng)一文讀懂





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論