") 對標(biāo)英偉達(dá)勝算幾何?這家AI芯片獨角獸首次全面揭開神秘面紗……
對標(biāo)英偉達(dá)勝算幾何?這家AI芯片獨角獸首次全面揭開神秘面紗……

在AI訓(xùn)練市場,不乏躍躍欲試想挑戰(zhàn)英偉達(dá)霸主地位的廠商。不過,英偉達(dá)GPU仍是當(dāng)前全球大規(guī)模商用部署的頭號玩家。其次,Google的TPU通過內(nèi)部應(yīng)用及TensorFlow占據(jù)第二大生態(tài)規(guī)模。
要知道,一顆AI芯片從開發(fā)定義到落地部署,中間存在著巨大的鴻溝,特別是算法越來越復(fù)雜、模型越來越大,AI芯片面臨著算力的嚴(yán)峻考驗,最終要在數(shù)據(jù)中心批量部署,能夠成功的廠商鳳毛麟角。
不過,來自于底層的顛覆性創(chuàng)新正在悄然改變著格局。Graphcore,這家成立于2016年、來自于英國的AI芯片公司,通過創(chuàng)新的IPU處理器技術(shù),已經(jīng)開始在全球數(shù)據(jù)中心批量應(yīng)用,躋身于該市場第三梯隊。
5月27日,在Intelligent Health峰會上,微軟機(jī)器學(xué)習(xí)科學(xué)家Sujeeth Bharadwaj分享了在攻克新冠病毒時的一項研究,在訓(xùn)練CXR(胸部X射線檢查)模型時,用Graphcore IPU處理器和英偉達(dá) V100同時運行微軟COVID-19影像分析算法SONIC,最終的結(jié)果可能令所有人大跌眼鏡:IPU在30分鐘內(nèi)完成了V100需5個小時的訓(xùn)練工作量!
這家年輕的公司,由此再次引起了業(yè)界的關(guān)注。日前,Graphcore面對<電子發(fā)燒友>等行業(yè)媒體,首次在中國市場全面揭開了其創(chuàng)新背后的核心技術(shù)及最新業(yè)務(wù)進(jìn)展,以及在中國市場的布局等。
為什么傳統(tǒng)的處理器架構(gòu)需要被顛覆?
Graphcore高級副總裁兼中國區(qū)總經(jīng)理盧濤(Jason Lu)介紹稱,AI時代的機(jī)器智能代表的是全新的計算負(fù)載,不同于傳統(tǒng)計算的特點有:它是非常大規(guī)模的并行計算;數(shù)據(jù)結(jié)構(gòu)非常稀疏;相較于傳統(tǒng)的科學(xué)計算或高性能計算(HPC),AI/機(jī)器智能是低精度計算;另外在訓(xùn)練、推理過程中的數(shù)據(jù)參數(shù)復(fù)用、靜態(tài)圖結(jié)構(gòu)等,都是AI應(yīng)用全新計算負(fù)載的典型代表。
盧濤 Jason Lu
Graphcore高級副總裁兼中國區(qū)總經(jīng)理
Graphcore高級副總裁兼中國區(qū)總經(jīng)理
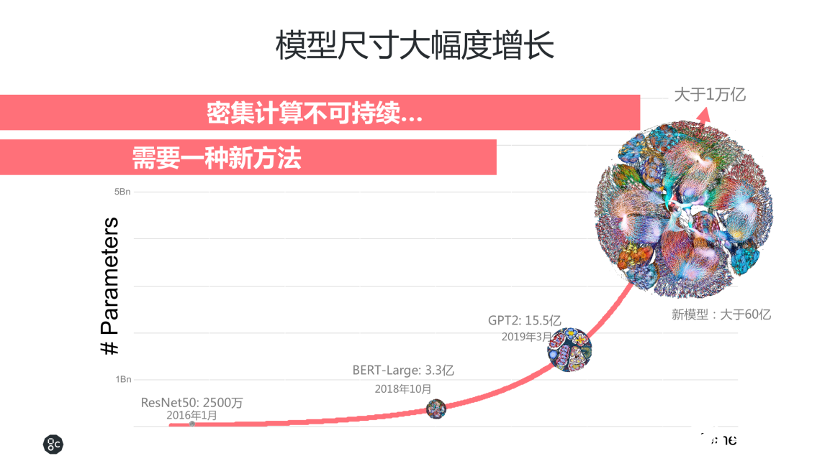
整個AI算法模型的演變,基本上從2016年1月份的ResNet50的2500萬個參數(shù),發(fā)展到2018年10月份BERT-Large的3.3億個參數(shù),而到了2019年發(fā)展到GPT2的15.5億個參數(shù),增長幅度非常大。甚至,現(xiàn)在一些領(lǐng)先的科研機(jī)構(gòu)和AI研究者在探索更大的算法模型,能夠訓(xùn)練更復(fù)雜的算法,來提高精度。密集計算并不是可持續(xù)的方法,譬如算法模型參數(shù)要從15.5億規(guī)模擴(kuò)展到一萬億,這種指數(shù)級的增長,需要成倍的算力提升。Graphcore認(rèn)為,傳統(tǒng)處理器無法很好地應(yīng)對這些變化,因此市場需要一種顛覆式的創(chuàng)新架構(gòu)。
 ?
?傳統(tǒng)的處理器架構(gòu),如CPU是針對應(yīng)用和網(wǎng)絡(luò)進(jìn)行設(shè)計的標(biāo)量處理器,GPU是以向量處理為核心的、針對圖形和高性能計算的處理器。而AI是全新的應(yīng)用架構(gòu),底層是以計算圖作為表征的,且從整個AI發(fā)展方向來看,大規(guī)模、稀疏化的數(shù)據(jù)會越來越多,因此,Graphcore針對這些發(fā)展趨勢設(shè)計了一種全新的處理器架構(gòu)。
全世界最復(fù)雜的擁有236億個晶體管的芯片處理器
目前為止,機(jī)器學(xué)習(xí)的算力來源主要還是傳統(tǒng)的處理器,它們的算力提升也非常快。不過,峰值算力和有效算力是兩回事,這其中,內(nèi)存帶寬成為掣肘。當(dāng)處理器算力提高了10倍,內(nèi)存如何相應(yīng)提高10倍的性能呢?盧濤介紹,如果用傳統(tǒng)的DDR4、DDR5、HBM、HBM1、HBM2、HBM3等內(nèi)存,基本上每一代能有30%或40%的提升,因此,這對傳統(tǒng)架構(gòu)是一個非常大的挑戰(zhàn)。
相較于傳統(tǒng)CPU、GPU,IPU采用了大規(guī)模并行MIMD(多指令多數(shù)據(jù))處理器核,通過緊密耦合的大型本地分布式SRAM,在片內(nèi)能夠做到300MB SRAM。相對CPU的DDR2子系統(tǒng)或GPU的GDDR、HBM來說,IPU能夠?qū)崿F(xiàn)10到320倍的性能提升。這樣帶來的好處是,能夠?qū)⒛P秃蛿?shù)據(jù)放在片內(nèi)處理,從時延的角度來看,與訪問外存相比較,時延僅為1%。
通過采用大規(guī)模分布式的片上SRAM架構(gòu),IPU處理器將所有memory都放在片上,解決了當(dāng)前機(jī)器學(xué)習(xí)中大量出現(xiàn)的內(nèi)存帶寬所造成的瓶頸。
目前,基于這一創(chuàng)新架構(gòu)的IPU處理器GC2已量產(chǎn),采用TSMC 16nm工藝,號稱是世界上最復(fù)雜的擁有236億個晶體管的芯片處理器。
GC2片內(nèi)有1216個IPU-Tiles,每個Tile有獨立的IPU核心作為計算以及In-Processor-Memory(處理器之內(nèi)的內(nèi)存),總共有7296個線程,能夠支持7296個程序并行運行。對整片來說,In-Processor-Memory總共是300MB,PCIe是16個PCIe Gen 4。
而在各個核心之間,Graphcore通過BSP同步協(xié)議,能夠支持同一個IPU處理器內(nèi)1216個核心之間的通信,以及跨不同的IPU之間進(jìn)行通信。另外,在IPU和IPU之間,擁有80個IPU-Links,總共有320GB/s的chip to chip的帶寬。正因如此,IPU處理器可以同時支持訓(xùn)練和推理。
從目前所公布的指標(biāo)來看,在自然語言處理、圖像分類、金融模型訓(xùn)練等方面,IPU在現(xiàn)有及下一代的模型上,性能均領(lǐng)先于GPU:在自然語言處理方面的速度能夠提升20%到50%;在圖像分類方面,能夠有6倍的吞吐量且時延更低;在金融模型方面,訓(xùn)練速度能夠提高26倍以上。目前,IPU在云上、在一些客戶的自建數(shù)據(jù)中心的服務(wù)器上已經(jīng)投產(chǎn)應(yīng)用。
而在場景應(yīng)用方面,IPU采用分組卷積的方式也體現(xiàn)出了獨有優(yōu)勢,特別是針對更為稀疏化的數(shù)據(jù)時。
盧濤分享了眾多AI創(chuàng)新者、算法科學(xué)家、AI應(yīng)用開發(fā)者日常工作中遇到的一大問題:當(dāng)算法模型在GPU上運行速度非常慢的時候,通常被認(rèn)為是算法或軟件問題。他指出,如果算法模型不是用稠密的卷積,而是用較為稀疏的卷積比如Fully depthwise做的,那么在GPU上運行得慢的根本原因是GPU架構(gòu)不符合算法特點,因此采用IPU能夠提供更好的支持。
他解釋稱,Graphcore設(shè)計了一個分組卷積內(nèi)核的micro-benchmark,將組維度(group dimension)分成從1到512來比較,這里512就是應(yīng)用得較多的“Dense卷積網(wǎng)絡(luò)”,典型應(yīng)用如ResNet。此時,IPU GC2性能甚至比英偉達(dá)V100要高近一倍。隨著稠密程度降低、稀疏化程度增加,在組維度為1或32時,針對EfficientNet或MobileNet,IPU對比GPU展現(xiàn)出巨大優(yōu)勢,做到成倍的性能提升,同時時延大大降低。
創(chuàng)新架構(gòu)需要軟硬協(xié)同設(shè)計
IPU所采用的片上存儲架構(gòu),確實是未來計算結(jié)構(gòu)的發(fā)展方向之一,但從芯片設(shè)計和應(yīng)用角度而言,這是一大挑戰(zhàn)。片上存儲通常有兩種架構(gòu),一是在片上規(guī)劃單塊大規(guī)模的存儲,這種方式通常會導(dǎo)致良品率極低。另一種架構(gòu)就是Graphcore這樣的分布式片上存儲架構(gòu)。但這又帶來了新的挑戰(zhàn):如何把分布式存儲架構(gòu)有效利用起來?這對編譯器的要求非常高,可以說是軟件、硬件協(xié)同設(shè)計的過程。要做出能夠真正落地的產(chǎn)品,最核心的挑戰(zhàn)就是軟硬件兩方面的專業(yè)知識和經(jīng)驗。
為了提升芯片的可用性,以及便于用戶和開發(fā)者更方便地在系統(tǒng)中進(jìn)行開發(fā)、移植、優(yōu)化,Graphcore將產(chǎn)品擴(kuò)展到囊括龐大的部署軟件和基礎(chǔ)架構(gòu)套件,通過Poplar SDK給用戶提供更好的體驗。而這通常是頭部廠商如英偉達(dá)在推進(jìn)GPU大規(guī)模應(yīng)用時才有的舉動。
Poplar SDK是架構(gòu)在機(jī)器學(xué)習(xí)上的框架軟件(比如TensorFlow、ONNX、PyTorch和PaddlePaddle)和硬件之間的一個基于計算圖的整套工具鏈和庫。Poplar SDK支持容器化部署,能夠快速啟動并運行。在標(biāo)準(zhǔn)生態(tài)方面,Poplar SDK支持Docker、Kubernetes、以及微軟的Hyper-v等虛擬化技術(shù)和安全技術(shù)。在操作系統(tǒng)方面,Poplar SDK目前支持最主要的三個Linux發(fā)行版:ubuntu、RedHat Enterprise Linux、CentOS。
今年5月,Graphcore還推出了PopVision Graph Analyser分析工具,用戶可以通過這個可視化的圖形展示工具來分析軟件運行情況、調(diào)試效率。
目前基于IPU的一些應(yīng)用已覆蓋到機(jī)器學(xué)習(xí)的各個應(yīng)用領(lǐng)域,包括自然語言處理、圖像/視頻處理、時序分析、推薦/排名及概率模型。一些應(yīng)用案例和模型已經(jīng)在TensorFlow、ONNX和Graphcore的PopART上可用,所有源代碼都可以在GitHub處下載。
新冠疫情下“小兵”立大功
當(dāng)前,全球都希望更高效地攻克新冠疫情中的難題。這時,AI在高清醫(yī)學(xué)影像領(lǐng)域就體現(xiàn)出了重要價值。第一,疫情發(fā)展非常快,不斷有新的病例、影像和數(shù)據(jù)產(chǎn)生,這就要求現(xiàn)有的模型要不斷根據(jù)新的情況來提高精度。
第二,疫情造成全球醫(yī)療資源緊缺。放射影片往往需要富有經(jīng)驗的醫(yī)生進(jìn)行判斷,而在資源緊張的情況下,AI工具可以幫助更多醫(yī)生獲得更專業(yè)的判斷力。
第三,全球都迫切需要攻克病毒的研究成果,如何提高研究效率至關(guān)重要。
Graphcore中國銷售總監(jiān)朱江,就本文開頭所提到的微軟訓(xùn)練CXR(胸部X光射線檢查)的應(yīng)用案例,詳細(xì)介紹了IPU與英偉達(dá) V100的對比情況。
朱江
Graphcore中國銷售總監(jiān)
Graphcore中國銷售總監(jiān)
微軟專門開發(fā)了SONIC CV模型進(jìn)行訓(xùn)練,IPU和GPU的訓(xùn)練結(jié)果對比如下圖:左邊是訓(xùn)練時間,IPU優(yōu)勢明顯。右邊紅色曲線代表訓(xùn)練時精度上升的情況,藍(lán)色曲線代表測試精度。可以看到測試精度和訓(xùn)練精度較為接近甚至吻合,這也說明SONIC模型在泛化性能上更好,在針對未知的新數(shù)據(jù)方面,其處理能力比微軟傳統(tǒng)的EfficientNet模型更好。整體上,SONIC的模型通過30分鐘的訓(xùn)練達(dá)到94%的訓(xùn)練精度和測試精度,訓(xùn)練速度方面,IPU需要30分鐘,而GPU差不多需要5個小時。
通過這一訓(xùn)練,微軟認(rèn)為能夠訓(xùn)練到SOTA的精度的模型不一定是大模型,可以用小模型來達(dá)到這樣的精度要求。另外,IPU的MIMD架構(gòu)非常適用于以分組卷積為代表的新模型。
據(jù)了解,目前微軟已采用IPU來進(jìn)行計算機(jī)視覺中分類方面的訓(xùn)練,能達(dá)到一個數(shù)量級的速度提升。未來,微軟期望把IPU在CV領(lǐng)域的應(yīng)用擴(kuò)展到更多方面,包括監(jiān)測、分割以及配準(zhǔn)。
創(chuàng)新帶給Graphcore的底氣
迄今為止,Graphcore獲得了AI領(lǐng)域多位重量級人物的背書。英國半導(dǎo)體之父、Arm聯(lián)合創(chuàng)始人Hermann爵士認(rèn)為:“在計算機(jī)歷史上只發(fā)生過三次革命,一次是70年代的CPU,第二次是90年代的GPU,而Graphcore就是第三次革命。”意指其率先提出了為AI計算而生的IPU。
AI教父Geoff Hinton教授在接受Wired采訪時,被問到 “我們應(yīng)該如何構(gòu)建功能更像大腦的機(jī)器學(xué)習(xí)系統(tǒng)”時,從錢包中掏出了一個又大又亮的硅片,并回答說:“我們需要轉(zhuǎn)向不同類型的計算機(jī)來處理新的機(jī)器學(xué)習(xí)系統(tǒng)。”他認(rèn)為Graphcore的IPU正在滿足這樣的系統(tǒng)需求。
迄今為止,Graphcore總?cè)谫Y超過4.5億美金,其中包括全球知名的金融投資者和戰(zhàn)略投資者。
不論是技術(shù)本身所帶來的創(chuàng)新地位,還是大佬的站臺或融資歷程,Graphcore的履歷都堪稱漂亮。
不過,作為一家初創(chuàng)企業(yè),Graphcore直面的都是業(yè)界巨擘。強如英偉達(dá),也已經(jīng)感受了種種威脅,正在加速創(chuàng)新。上個月,英偉達(dá)推出了基于Ampere架構(gòu)的NVIDIA A100,將AI訓(xùn)練和推理性能提高20倍,可以說是英偉達(dá)GPU迄今為止最大的性能飛躍。
對于未來的競爭,Graphcore方面信心滿滿。盧濤表示,雖然目前對比的都是與V100這樣的大量部署的旗艦級產(chǎn)品,但即使是第一代IPU產(chǎn)品也不會輸于A100,且下一代IPU處理器也將有重磅發(fā)布。
未來的推進(jìn)策略,Graphcore還是會在訓(xùn)練和推理兩方面并行,聚焦對高精度、低時延、高吞吐量要求更高的場景。另外還有一個趨勢是訓(xùn)練和推理混布的需求,例如視頻平臺、電商網(wǎng)站等希望通過算法同時進(jìn)行訓(xùn)練和推理,能夠根據(jù)用戶數(shù)據(jù)實時更新算法模型;未來的汽車應(yīng)用也是訓(xùn)練和推理混布的場景,都將有一定的增長。
積極擁抱中國AI生態(tài)圈
在中國,Graphcore剛與兩大頭部客戶有了重大進(jìn)展。一是阿里巴巴新的開放式深度學(xué)習(xí)API ODLA(Open Deep Learning API)支持Graphcore IPU,某種程度上,這也反映了數(shù)據(jù)中心對IPU的計算需求正在增長。
二是成為百度飛槳(PaddlePaddle)硬件生態(tài)圈共建計劃伙伴之一,這一合作使Graphcore進(jìn)入了中國深度學(xué)習(xí)開源框架的生態(tài)系統(tǒng)中,觸及百萬以上的AI開發(fā)者。
盧濤表示,Graphcore正在積極擁抱中國的AI生態(tài)圈,中國市場未來有望占據(jù)其全球市場的40%甚至50%。
本文由電子發(fā)燒友網(wǎng)原創(chuàng),未經(jīng)授權(quán)禁止轉(zhuǎn)載。如需轉(zhuǎn)載,請?zhí)砑游?a target="_blank">信號elecfans999.
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
gpu
+關(guān)注
關(guān)注
28文章
4938瀏覽量
131196 -
IPU
+關(guān)注
關(guān)注
0文章
35瀏覽量
15799 -
AI芯片
+關(guān)注
關(guān)注
17文章
1983瀏覽量
35891 -
AI2020
+關(guān)注
關(guān)注
1文章
22瀏覽量
6098
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
隼眼科技榮獲2025年度南京市培育獨角獸企業(yè)
近日,備受矚目的《2025年度南京市獨角獸、培育獨角獸、瞪羚企業(yè)榜單》正式揭曉,隼眼科技成功入選“2025年度南京市培育獨角獸企業(yè)”。這一榮譽不僅是對隼眼科技過往成績的高度認(rèn)可,更是對其未來發(fā)展?jié)摿Φ某浞挚隙ā?/div>
![的頭像]() 發(fā)表于 06-05 17:49
?554次閱讀
發(fā)表于 06-05 17:49
?554次閱讀
士模微電子上榜“中國潛在獨角獸企業(yè)”
2024年10月下旬,長城戰(zhàn)略咨詢發(fā)布《中國潛在獨角獸企業(yè)研究報告2024》,北京士模微電子有限責(zé)任公司入選中國“潛在獨角獸”企業(yè)榜單。“獨角獸”指具有發(fā)展速度快、數(shù)量稀少、備受投資者青睞等屬性

墨芯人工智能斬獲2024創(chuàng)業(yè)邦100未來獨角獸
在近日舉行的第十六屆創(chuàng)業(yè)邦100未來獨角獸大會上,備受矚目的「2024創(chuàng)業(yè)邦100未來獨角獸」榜單正式揭曉,墨芯人工智能(Moffett AI)憑借其卓越的技術(shù)實力與顯著的市場價值榮登該榜單。 該
匯頂科技擬并購芯片獨角獸云英谷
近日,半導(dǎo)體領(lǐng)域再次發(fā)生一起引人注目的并購事件。國內(nèi)知名芯片企業(yè)匯頂科技宣布,計劃通過發(fā)行股份及支付現(xiàn)金的方式,收購芯片獨角獸云英谷的控制權(quán)。
億鑄科技榮登中國潛在獨角獸企業(yè)榜單
在近日舉辦的“2024中國潛在獨角獸企業(yè)發(fā)展大會”上,長城戰(zhàn)略咨詢隆重發(fā)布了《GEI中國潛在獨角獸企業(yè)研究報告2024》,深度剖析了中國潛在獨角獸企業(yè)的最新發(fā)展動態(tài)。該報告連續(xù)第五年發(fā)布,億鑄科技榮譽入選《中國潛在
同星智能榮獲“中國汽車隱形獨角獸”稱號
TOSUNNEWS11月11日,第二屆中國汽車獨角獸大會在安徽省馬鞍山市舉辦。此次大會以“匯聚耐心資本賦能獨角獸,搶抓新汽車新布局新機(jī)遇”為主題,吸引了來自國內(nèi)汽車行業(yè)的專家學(xué)者和汽車零部件領(lǐng)軍企業(yè)

主線科技榮登中國潛在獨角獸企業(yè)榜單
日前,長城咨詢重磅發(fā)布2024年GEI中國潛在獨角獸企業(yè)榜單及研究報告。主線科技憑借卓越的技術(shù)硬實力、前瞻性的市場布局以及持續(xù)的創(chuàng)新活力,從眾多競爭者中脫穎而出,榮獲“潛在獨角獸”稱號。中國潛在
萬協(xié)通亮相2024中國潛在獨角獸企業(yè)發(fā)展大會
近日,2024中國潛在獨角獸企業(yè)發(fā)展大會成功舉辦,會上重磅發(fā)布《GEI中國潛在獨角獸企業(yè)研究報告2024》揭示了中國潛在獨角獸企業(yè)群體的最新發(fā)展態(tài)勢,萬協(xié)通以技術(shù)創(chuàng)新力和強勁的發(fā)展?jié)摿s登榜單,展現(xiàn)了公司在新興領(lǐng)域的創(chuàng)新引領(lǐng)能力
實力登榜!廣域銘島入選中國潛在獨角獸企業(yè)
近日,2024中國潛在獨角獸企業(yè)發(fā)展大會在中國工業(yè)博物館舉辦,會上發(fā)布的《中國潛在獨角獸企業(yè)研究報告2024》,揭曉了“2023中國潛在獨角獸榜單”,展示了中國潛在獨角獸企業(yè)的最新發(fā)展

潤芯微科技榮獲中國潛在獨角獸企業(yè)
近日,長城戰(zhàn)略咨詢在2024東北亞(沈陽)人才交流大會暨中國潛在獨角獸企業(yè)發(fā)展大會上揭曉了“中國潛在獨角獸企業(yè)榜單”,潤芯微科技(江蘇)有限公司憑借卓越的創(chuàng)新能力和快速發(fā)展勢頭,成功入選該榜單。此前
芯百特入選2024年江蘇潛在獨角獸企業(yè)
近日,江蘇省生產(chǎn)力促進(jìn)中心揭曉了“2024年江蘇獨角獸企業(yè)”評估結(jié)果,芯百特微電子(無錫)有限公司(簡稱“芯百特”)憑借其卓越的射頻芯片技術(shù)創(chuàng)新及顯著的市場表現(xiàn),成功入選江蘇潛在獨角獸企業(yè)榜單。
用智能DAC揭開醫(yī)療報警設(shè)計的神秘面紗
電子發(fā)燒友網(wǎng)站提供《用智能DAC揭開醫(yī)療報警設(shè)計的神秘面紗.pdf》資料免費下載
發(fā)表于 09-14 10:50
?0次下載

AI芯片獨角獸壁仞科技啟動上市輔導(dǎo)
近日,備受矚目的AI芯片獨角獸企業(yè)——上海壁仞科技股份有限公司正式在上海證監(jiān)局完成輔導(dǎo)備案登記,標(biāo)志著其向首次公開發(fā)行股票并上市的目標(biāo)邁出了堅實的一步。此次輔導(dǎo)券商選定為國泰君安,彰顯
正力新能再次入選中國獨角獸企業(yè)名單
日前,2024中國(重慶)獨角獸企業(yè)大會在重慶舉行。本次大會以“渝見中國獨角獸·發(fā)展新質(zhì)生產(chǎn)力”為主題,由重慶市經(jīng)濟(jì)和信息化委員會、重慶兩江新區(qū)管理委員會以及長城戰(zhàn)略咨詢共同主辦,大會匯聚獨角獸企業(yè)代表、投資機(jī)構(gòu)和各界行業(yè)專家參
消息稱谷歌25億美元收購AI獨角獸Character.AI
近日,科技界傳來重磅消息,谷歌宣布成功收購人工智能獨角獸公司Character.AI,標(biāo)志著雙方在AI領(lǐng)域的合作邁入新階段。此次收購不僅吸引了業(yè)界的廣泛關(guān)注,也再次凸顯了大型科技公司在AI
- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論