") Python開(kāi)源機(jī)器學(xué)習(xí)建模庫(kù)PyCaret,發(fā)布了2.0版本
Python開(kāi)源機(jī)器學(xué)習(xí)建模庫(kù)PyCaret,發(fā)布了2.0版本
Python開(kāi)源機(jī)器學(xué)習(xí)建模庫(kù)PyCaret,最近發(fā)布了2.0版本。
這款堪稱(chēng)調(diào)包俠神器的模型訓(xùn)練工具包,幾行代碼就能搞定模型編寫(xiě)、改進(jìn)和微調(diào)。 從數(shù)據(jù)預(yù)處理到模型效果對(duì)比,PyCaret都能自動(dòng)實(shí)現(xiàn)。 所以,PyCaret長(zhǎng)啥樣,2.0的版本又做了什么改進(jìn)? 一起來(lái)看看。
機(jī)器學(xué)習(xí)庫(kù)的煉丹爐
PyCaret說(shuō)白了,有點(diǎn)像一個(gè)機(jī)器學(xué)習(xí)庫(kù)的煉丹爐。 以下是它熔進(jìn)來(lái)的部分庫(kù):
數(shù)據(jù)處理:pandas、numpy…
數(shù)據(jù)可視化:matplotlib、seaborn…
各種模型:sklearn、xgboost、catboost、lightgbm…
嗯…sklearn直接就給封裝進(jìn)去了,調(diào)用很方便。 然后,PyCaret這個(gè)煉丹爐,自帶功能“按鍵”(定義了一些函數(shù)),包括數(shù)據(jù)預(yù)處理、模型訓(xùn)練、模型集成、模型分析、模型測(cè)試等。 只需要寫(xiě)上幾行Python代碼,這些功能“按鍵”就會(huì)被按下,PyCaret自動(dòng)幫你實(shí)現(xiàn)。 至于實(shí)現(xiàn)過(guò)程中需要調(diào)用什么基本庫(kù),哪些可以放棄絲毫不需要考慮。 從下圖來(lái)看,僅僅是預(yù)處理階段,就包含樣本劃分、數(shù)據(jù)預(yù)處理、缺失值處理、歸一化、獨(dú)熱編碼等功能。
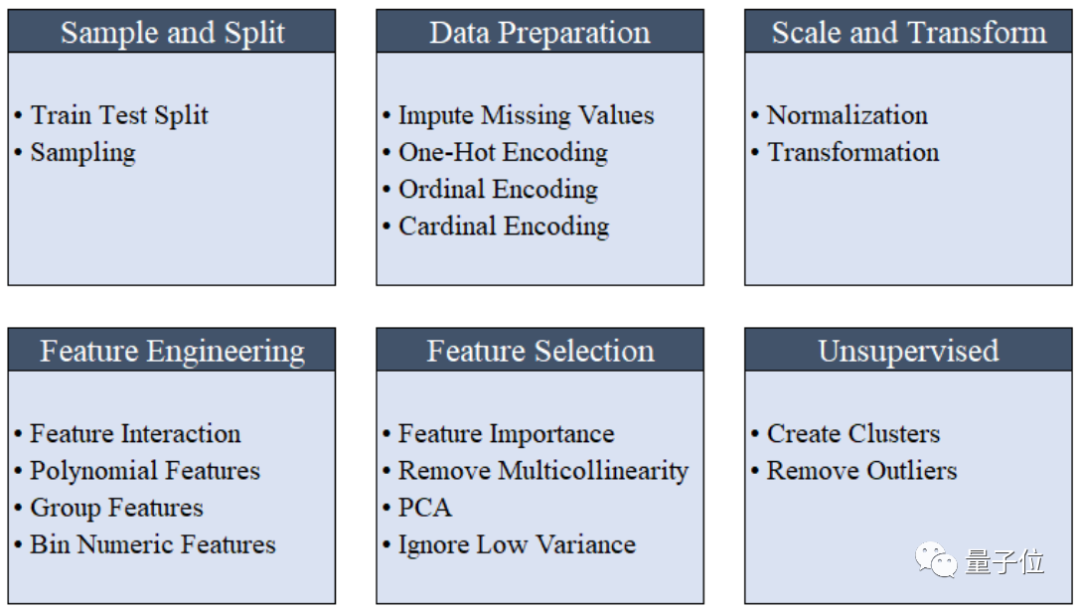
如果要實(shí)現(xiàn)必需的預(yù)處理功能,需要多少行代碼來(lái)調(diào)用? 答案是0行。 因?yàn)椋?dāng)使用setup()進(jìn)行初始化時(shí),PyCaret將自動(dòng)執(zhí)行機(jī)器學(xué)習(xí)必需的數(shù)據(jù)預(yù)處理步驟,包括缺失值插入、分類(lèi)變量編碼、標(biāo)簽編碼、數(shù)據(jù)集拆分等。 例如,在數(shù)據(jù)處理前,你發(fā)現(xiàn)數(shù)據(jù)集有空缺的地方(下圖中NaN部分)。

別怕,PyCaret會(huì)自動(dòng)分析數(shù)據(jù),進(jìn)行缺失值插入。

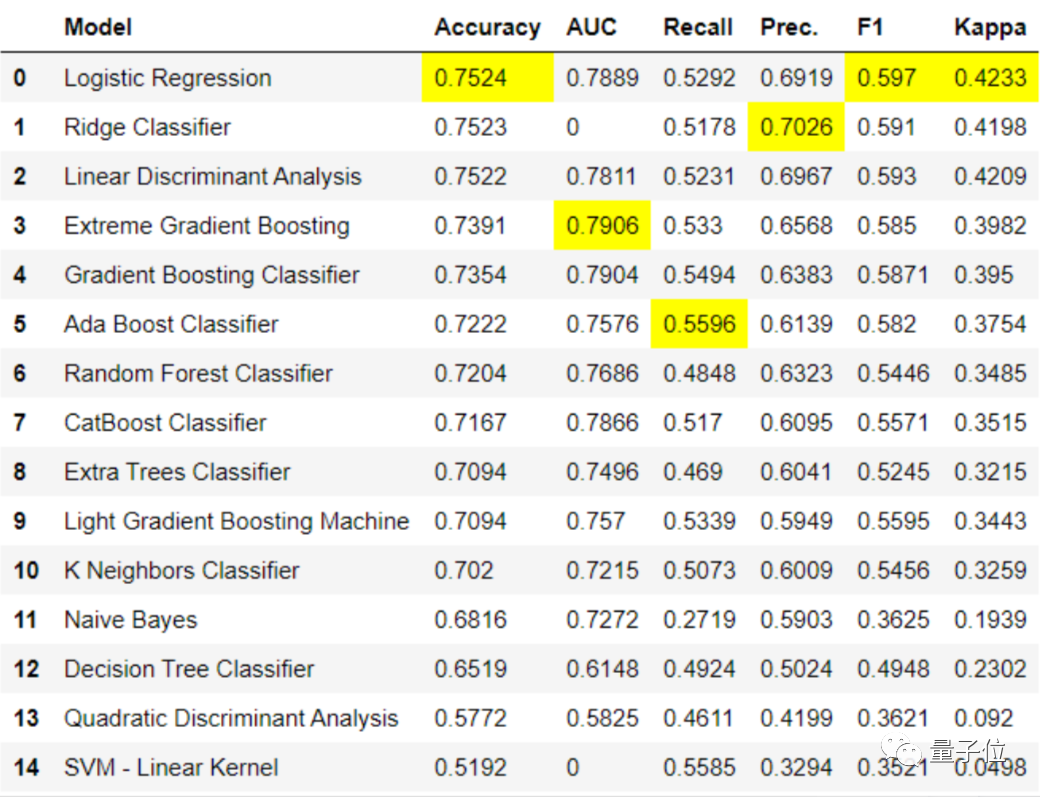
預(yù)處理后,PyCaret還貼心地幫你準(zhǔn)備了各種模型。 從模型訓(xùn)練、選用到測(cè)試,只有你想不到的,沒(méi)有它做不了的。 如果已經(jīng)將數(shù)據(jù)處理好,并交給PyCaret,一個(gè)compare_models函數(shù)就能訓(xùn)練庫(kù)中的所有模型,進(jìn)行結(jié)果比較后,標(biāo)出最佳模型。 如下圖,各種模型指標(biāo)的最優(yōu)值會(huì)被一鍵標(biāo)黃,就看你怎么選擇了。
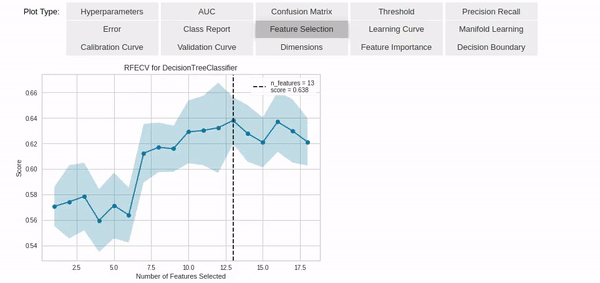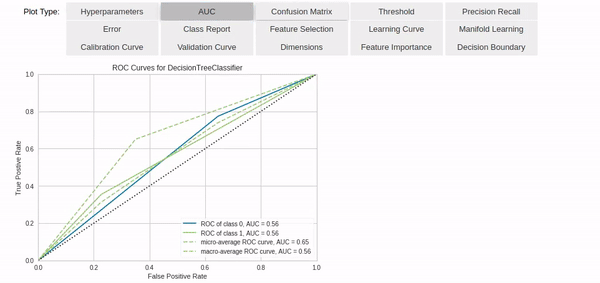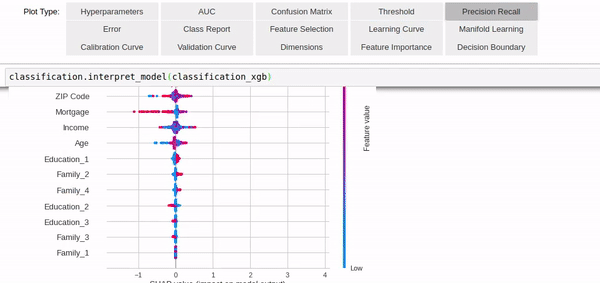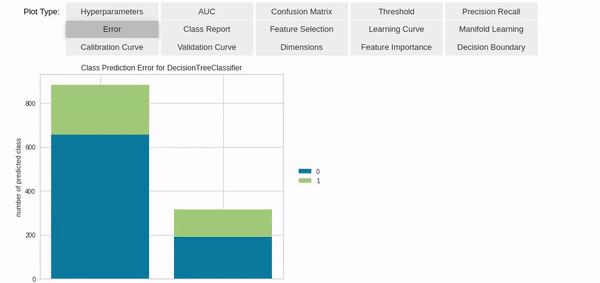
選好后,想對(duì)模型進(jìn)行一點(diǎn)優(yōu)化?一個(gè)tune_model函數(shù)就能幫你搞定。 或者,不想僅僅選用一個(gè)模型? PyCaret也準(zhǔn)備了模型集成的函數(shù),blend和stack任你選。 除此之外,模型參數(shù)的分析(包括可視化)也只需要幾行代碼就能實(shí)現(xiàn),功能非常強(qiáng)大。
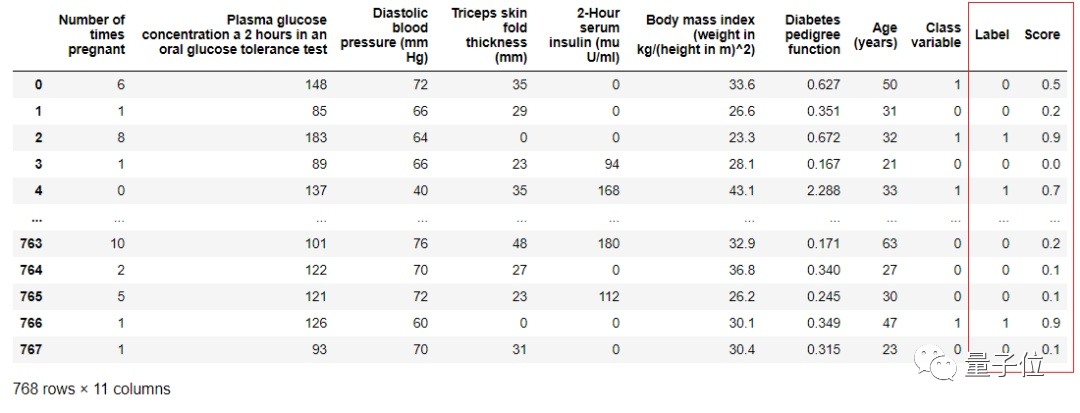
最后,PyCaret還能為新數(shù)據(jù)提供迭代預(yù)測(cè)結(jié)果,下面的效果,同樣只需要幾行代碼就能完成。
那么,這次PyCaret增強(qiáng),進(jìn)行了什么改進(jìn)呢?(項(xiàng)目見(jiàn)傳送門(mén))
PyCaret 2.0增強(qiáng)版
這是PyCaret 2.0的6大特色,有些在1.0就有了,有些功能如實(shí)驗(yàn)日志,看起來(lái)是更新后新加入的功能。

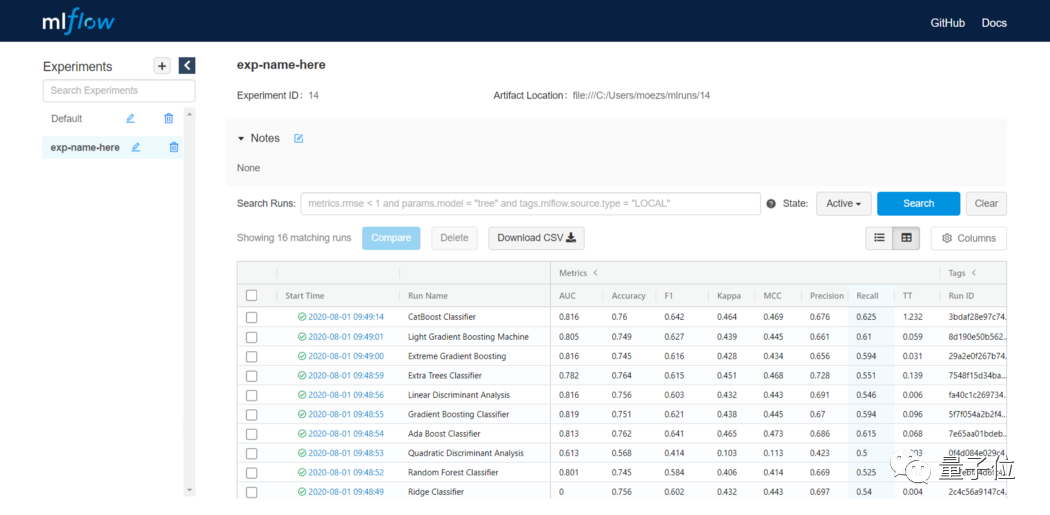
實(shí)驗(yàn)日志,對(duì)于模型的調(diào)整不可或缺。 例如,想要將訓(xùn)練過(guò)程中模型的精度變化可視化,通常我們會(huì)在模型中加入生成日志文件的函數(shù),生成一個(gè)更直觀的時(shí)間-精度變化圖。 PyCaret 2.0加入了實(shí)驗(yàn)日志的功能,自動(dòng)幫你跟蹤模型實(shí)驗(yàn)過(guò)程中的各項(xiàng)指標(biāo),以及生成視覺(jué)效果等。 不僅如此,在2.0中,模型生成到預(yù)測(cè)的所有工作流程,現(xiàn)在可以被設(shè)計(jì)了。 也就是說(shuō),你可以設(shè)置一條自定義流水線,在這個(gè)過(guò)程中,從訓(xùn)練到測(cè)試,所有模塊的功能都會(huì)被自動(dòng)化完成。 甚至,PyCaret 2.0還提供了機(jī)器學(xué)習(xí)模型前端軟件的搭建工具。 以及,PyCaret 2.0現(xiàn)在幾乎支持所有算法的并行處理,xgboost和catboost模型也支持GPU訓(xùn)練。
除此之外,還有一些新的程序功能,等待你去發(fā)現(xiàn)。
-
代碼
+關(guān)注
關(guān)注
30文章
4891瀏覽量
70299 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8493瀏覽量
134155 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86259
原文標(biāo)題:調(diào)包俠神器2.0發(fā)布,Python機(jī)器學(xué)習(xí)模型搭建只需要幾行代碼
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開(kāi)發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
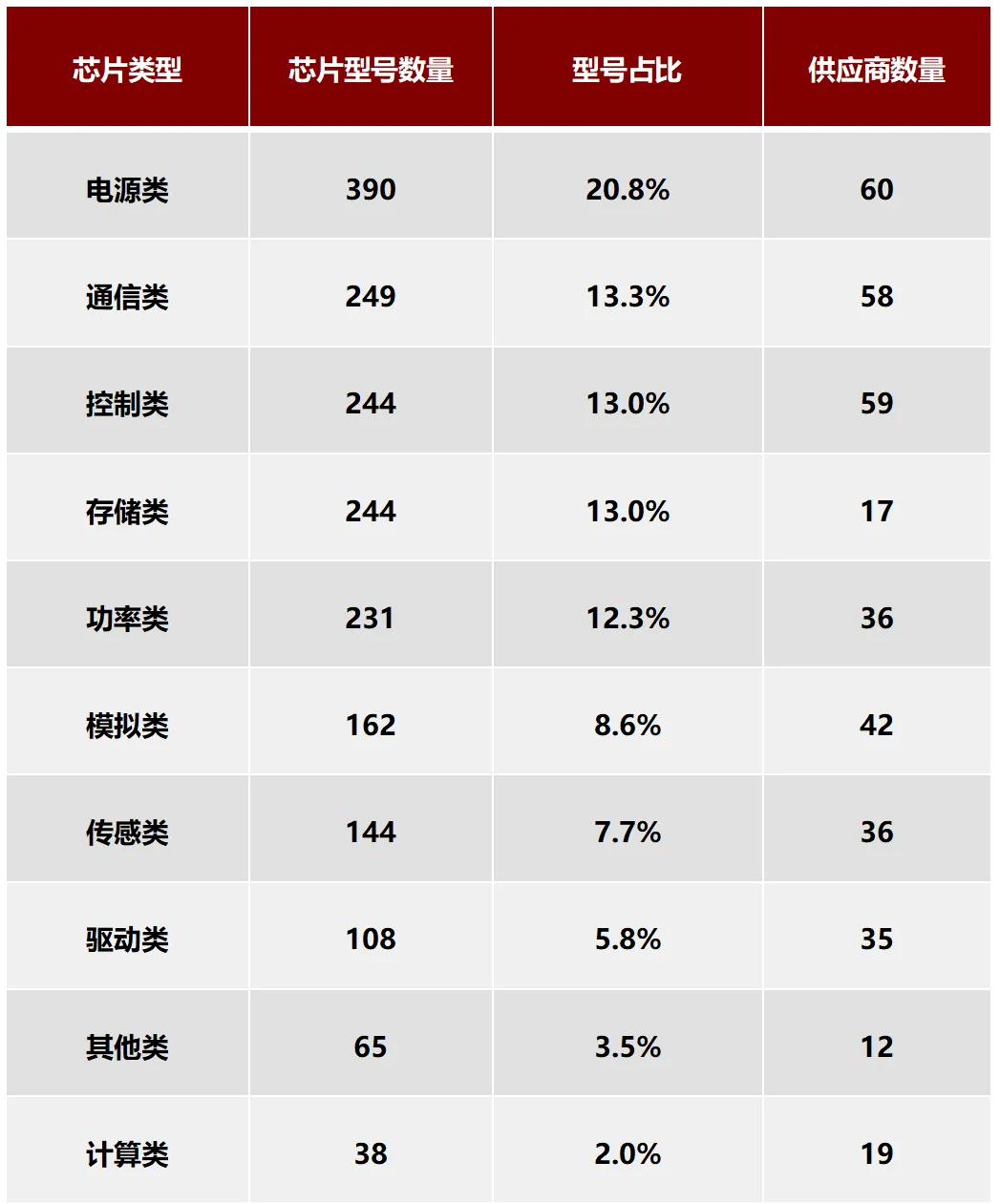
《中國(guó)汽車(chē)芯片聯(lián)盟白名單》2.0版本發(fā)布,覆蓋300多家廠商的超1800款產(chǎn)品
如何在Ubuntu 24.04上運(yùn)行5.4.47版本?
芯來(lái)科技發(fā)布Nuclei Studio 2025.02版本
國(guó)地中心將推出人形機(jī)器人“Deep Snake”2.0版本
如何使用Python構(gòu)建LSTM神經(jīng)網(wǎng)絡(luò)模型
USB4 2.0版本的重大更新
如何幫助孩子高效學(xué)習(xí)Python:開(kāi)源硬件實(shí)踐是最優(yōu)選擇
pycharm如何調(diào)用pytorch
Python建模算法與應(yīng)用
opencv-python和opencv一樣嗎
ROS讓機(jī)器人開(kāi)發(fā)更便捷,基于RK3568J+Debian系統(tǒng)發(fā)布!
天數(shù)智芯主導(dǎo)的DeepSpark開(kāi)源社區(qū)發(fā)布百大應(yīng)用開(kāi)放平臺(tái)24.06版本







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論