") 一種針對該文本檢索任務(wù)的BERT算法方案DR-BERT
一種針對該文本檢索任務(wù)的BERT算法方案DR-BERT
基于微軟大規(guī)模真實場景數(shù)據(jù)的閱讀理解數(shù)據(jù)集MS MARCO,美團搜索與NLP中心提出了一種針對該文本檢索任務(wù)的BERT算法方案DR-BERT,該方案是第一個在官方評測指標MRR@10上突破0.4的模型。
本文系DR-BERT算法在文本檢索任務(wù)中的實踐分享,希望對從事檢索、排序相關(guān)研究的同學能夠有所啟發(fā)和幫助。
背景提高機器閱讀理解(MRC)能力以及開放領(lǐng)域問答(QA)能力是自然語言處理(NLP)領(lǐng)域的一大重要目標。在人工智能領(lǐng)域,很多突破性的進展都基于一些大型公開的數(shù)據(jù)集。比如在計算機視覺領(lǐng)域,基于對ImageNet數(shù)據(jù)集研發(fā)的物體分類模型已經(jīng)超越了人類的表現(xiàn)。類似的,在語音識別領(lǐng)域,一些大型的語音數(shù)據(jù)庫,同樣使得了深度學習模型大幅提高了語音識別的能力。 近年來,為了提高模型的自然語言理解能力,越來越多的MRC和QA數(shù)據(jù)集開始涌現(xiàn)。但是,這些數(shù)據(jù)集或多或少存在一些缺陷,比如數(shù)據(jù)量不夠、依賴人工構(gòu)造Query等。針對這些問題,微軟提出了一個基于大規(guī)模真實場景數(shù)據(jù)的閱讀理解數(shù)據(jù)集MS MARCO (Microsoft Machine Reading Comprehension)[1]。該數(shù)據(jù)集基于Bing搜索引擎和Cortana智能助手中的真實搜索查詢產(chǎn)生,包含100萬查詢,800萬文檔和18萬人工編輯的答案。 基于MS MARCO數(shù)據(jù)集,微軟提出了兩種不同的任務(wù):一種是給定問題,檢索所有數(shù)據(jù)集中的文檔并進行排序,屬于文檔檢索和排序任務(wù);另一種是根據(jù)問題和給定的相關(guān)文檔生成答案,屬于QA任務(wù)。在美團業(yè)務(wù)中,文檔檢索和排序算法在搜索、廣告、推薦等場景中都有著廣泛的應(yīng)用。此外,直接在所有候選文檔上進行QA任務(wù)的時間消耗是無法接受的,QA任務(wù)必須依靠排序任務(wù)篩選出排名靠前的文檔,而排序算法的性能直接影響到QA任務(wù)的表現(xiàn)。基于上述原因,我們主要將精力放在基于MS MARCO的文檔檢索和排序任務(wù)上。 自2018年10月MACRO文檔排序任務(wù)發(fā)布后,迄今吸引了包括阿里巴巴達摩院、Facebook、微軟、卡內(nèi)基梅隆大學、清華等多家企業(yè)和高校的參與。在美團的預訓練MT-BERT平臺[14]上,我們提出了一種針對該文本檢索任務(wù)的BERT算法方案,稱之為DR-BERT(Enhancing BERT-based Document Ranking Model with Task-adaptive Training and OOV Matching Method)。DR-BERT是第一個在官方評測指標MRR@10上突破0.4的模型,且在2020年5月21日(模型提交日)-8月12日期間位居榜首,主辦方也單獨發(fā)表推文表示了祝賀,如下圖1所示。DR-BERT模型的核心創(chuàng)新主要包括領(lǐng)域自適應(yīng)的預訓練、兩階段模型精調(diào)及兩種OOV(Out of Vocabulary)匹配方法。
圖1 官方祝賀推文及MARCO 排行榜相關(guān)介紹Learning to Rank在信息檢索領(lǐng)域,早期就已經(jīng)存在很多機器學習排序模型(Learning to Rank)用來解決文檔排序問題,包括LambdaRank[2]、AdaRank[3]等,這些模型依賴很多手工構(gòu)造的特征。而隨著深度學習技術(shù)在機器學習領(lǐng)域的流行,研究人員提出了很多神經(jīng)排序模型,比如DSSM[4]、KNRM[5]等。這些模型將問題和文檔的表示映射到連續(xù)的向量空間中,然后通過神經(jīng)網(wǎng)絡(luò)來計算它們的相似度,從而避免了繁瑣的手工特征構(gòu)建。
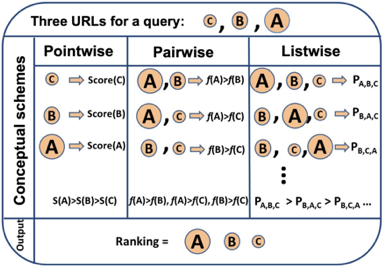
圖2 Pointwise、Pairwise、Listwise訓練的目標 根據(jù)學習目標的不同,排序模型大體可以分為Pointwise、Pairwise和Listwise。這三種方法的示意圖如上圖2所示。其中,Pointwise方法直接預測每個文檔和問題的相關(guān)分數(shù),盡管這種方法很容易實現(xiàn),然而對于排序來說,更重要的是學到不同文檔之間的排序關(guān)系。基于這種思想,Pairwise方法將排序問題轉(zhuǎn)換為對兩兩文檔的比較。具體來講,給定一個問題,每個文檔都會和其他的文檔兩兩比較,判斷該文檔是否優(yōu)于其他文檔。這樣的話,模型就學習到了不同文檔之間的相對關(guān)系。 然而,Pairwise的排序任務(wù)存在兩個問題:第一,這種方法優(yōu)化兩兩文檔的比較而非更多文檔的排序,跟文檔排序的目標不同;第二,隨機從文檔中抽取Pair容易造成訓練數(shù)據(jù)偏置的問題。為了彌補這些問題,Listwise方法將Pairwsie的思路加以延伸,直接學習排序之間的相互關(guān)系。根據(jù)使用的損失函數(shù)形式,研究人員提出了多種不同的Listwise模型。比如,ListNet[6]直接使用每個文檔的top-1概率分布作為排序列表,并使用交叉熵損失來優(yōu)化。ListMLE[7]使用最大似然來優(yōu)化。SoftRank[8]直接使用NDCG這種排序的度量指標來進行優(yōu)化。大多數(shù)研究表明,相比于Pointwise和Pairwise方法,Listwise的學習方式能夠產(chǎn)生更好的排序結(jié)果。BERT自2018年谷歌的BERT[9]的提出以來,預訓練語言模型在自然語言處理領(lǐng)域取得了很大的成功,在多種NLP任務(wù)上取得了SOTA效果。BERT本質(zhì)上是一個基于Transformer架構(gòu)的編碼器,其取得成功的關(guān)鍵因素是利用多層Transoformer中的自注意力機制(Self-Attention)提取不同層次的語義特征,具有很強的語義表征能力。如圖3所示,BERT的訓練分為兩部分,一部分是基于大規(guī)模語料上的預訓練(Pre-training),一部分是在特定任務(wù)上的微調(diào)(Fine-tuning)。
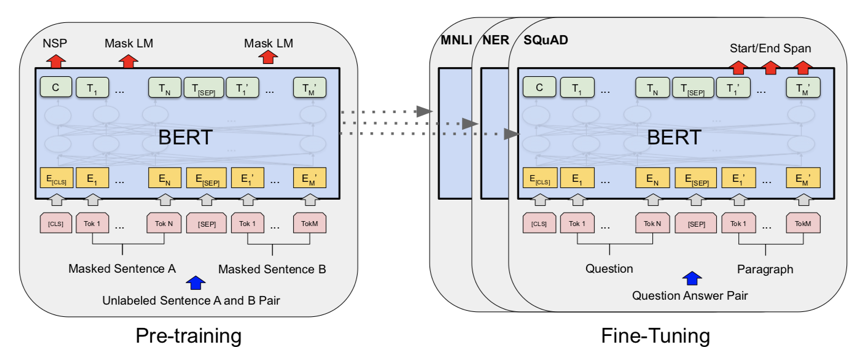
圖3 BERT的結(jié)構(gòu)和訓練模式 在信息檢索領(lǐng)域,很多研究人員也開始使用BERT來完成排序任務(wù)。比如,[10][11]就使用BERT在MS MARCO上進行實驗,得到的結(jié)果大幅超越了當時最好的神經(jīng)網(wǎng)絡(luò)排序模型。[10]使用了Pointwise學習方式,而[11]使用了Pairwise學習方式。這些工作雖然取得了不錯的效果,但是未利用到排序本身的比較信息。基于此,我們結(jié)合BERT本身的語義表征能力和Listwise排序,取得了很大的進步。模型介紹任務(wù)描述

基于DeepCT候選初篩由于MS MARCO中的數(shù)據(jù)量很大,直接使用深度神經(jīng)網(wǎng)絡(luò)模型做Query和所有文檔的相關(guān)性計算會消耗大量的時間。因此,大部分的排序模型都會使用兩階段的排序方法。第一階段初步篩選出top-k的候選文檔,然后第二階段使用深度神經(jīng)網(wǎng)絡(luò)對候選文檔進行精排。這里我們使用BM25算法來進行第一步的檢索,BM25常用的文檔表示方法包括TF-IDF等。 但是TF-IDF不能考慮每個詞的上下文語義。DeepCT[12]為了改進這種問題,首先使用BERT對文檔單獨進行編碼,然后輸出每個單詞的重要性程度分數(shù)。通過BERT強大的語義表征能力,可以很好衡量單詞在文檔中的重要性。如下圖4所示,顏色越深的單詞,其重要性越高。其中的“stomach”在第一個文檔中的重要性更高。

圖4 DeepCT估單詞的重要性,同一個詞在不同文檔中的重要性不同
DeepCT的訓練目標如下所示:
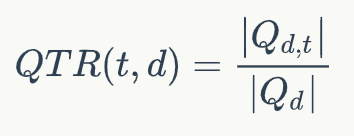
其中QTR(t,d)表示文檔d中單詞t的重要性分數(shù),Qd表示和文檔d相關(guān)的問題,Q{d,t}表示文檔d對應(yīng)的問題中包含單詞t的子集。輸出的分數(shù)可以當做詞頻(TF)使用,相當于對文檔的詞的重要性進行了重新估計,因此可以直接使用BM25算法進行檢索。我們使用DeepCT作為第一階段的檢索模型,得到top-k個文檔作為文檔候選集合D={D1,D2,...,Dk}。領(lǐng)域自適應(yīng)預訓練由于我們的模型是基于BERT的,而BERT本身的預訓練使用的語料和當前的任務(wù)使用的語料并不是同一個領(lǐng)域。我們得出這個結(jié)論是基于對兩部分語料中top-10000高頻詞的分析,我們發(fā)現(xiàn)MARCO的top-10000高頻詞和BERT基線使用的語料有超過40%的差異。因此,我們有必要使用當前領(lǐng)域的語料對BERT進行預訓練。由于MS MARCO屬于大規(guī)模語料,我們可以直接使用該數(shù)據(jù)集中的文檔內(nèi)容對BERT進行預訓練。我們在第一階段使用MLM和NSP預訓練目標函數(shù)在MS MARCO上進行預訓練。兩階段精調(diào)
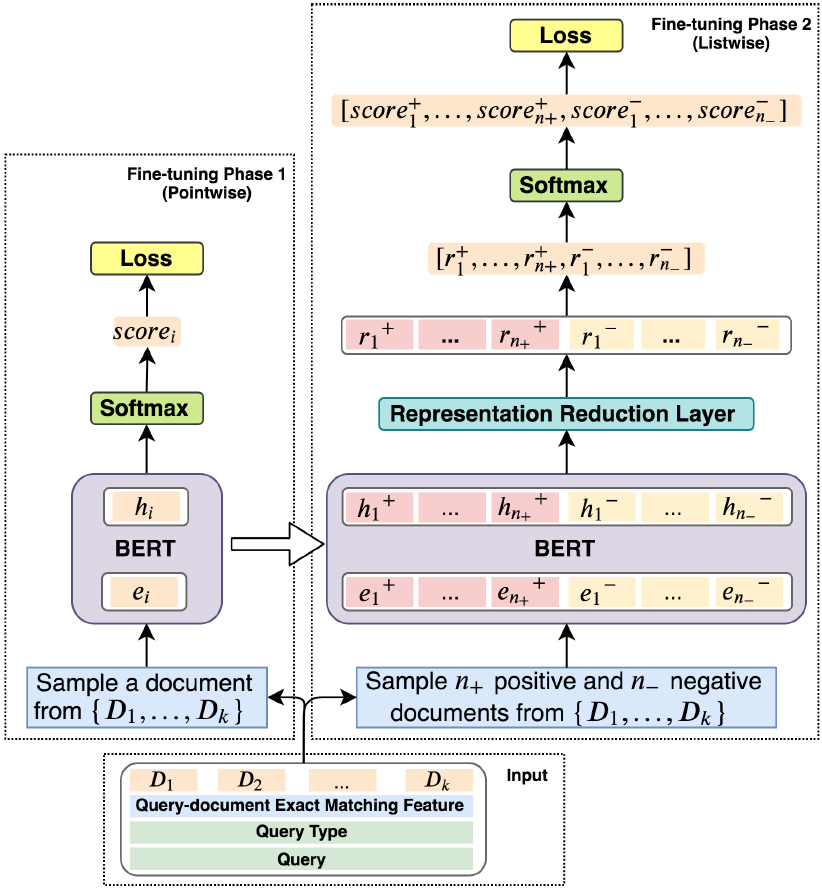
圖5 模型結(jié)構(gòu) 下面介紹我們提出的精調(diào)模型,上圖5展示了我們提出的模型的結(jié)構(gòu)。精調(diào)分為兩個階段:Pointwise精調(diào)和Listwise精調(diào)。Pointwise問題類型感知的精調(diào)
第一階段的精調(diào),我們的目標是通過Pointwise的訓練方式建立問題和文檔的關(guān)系。我們將Query-Document作為輸入,使用BERT對其編碼,匹配問題和文檔。考慮到問題和文檔的匹配模式和問題的類型有很大的關(guān)系,我們認為在該階段還需要考慮問題的類型。因此,我們使用問題,問題類型和文檔一起通過BERT進行編碼,得到一個深層交互的語義表示。具體的,我們將問題類型T、問題Q和第i個文檔Di拼接成一個序列輸入,如下式所示:

其中

經(jīng)過BERT編碼后,我們?nèi)∽詈笠粚又?CLS>位置的表示hi為Query-Document的關(guān)系表示。然后通過Softmax計算他們的得分,得到:
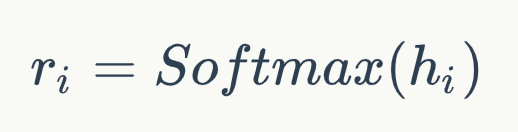
該分數(shù)Ti通過交叉熵損失函數(shù)進行優(yōu)化。通過以上的預訓練,模型對不同的問題學到了不同的匹配模式。該階段的預訓練可以稱為類型自適應(yīng)(Type-Adaptive)模型精調(diào)。Listwise 精調(diào)為了使得模型直接學習不同排序的比較關(guān)系,我們通過Listwise的方式對模型進行精調(diào)。具體的,在訓練過程中,對于每個問題,我們采樣n+個正例以及n-個負例作為輸入,這些文檔是從候選文檔集合D中隨機產(chǎn)生。注意,由于硬件的限制,我們不能將所有的候選文檔都輸入到當前模型中。因此我們選擇了隨機采樣的方式來進行訓練。
和預訓練中使用BERT的方式類似,我們得到正例和負例中每個文檔的表示,hi+和hi-。然后通過一個單層感知機將上面得到的表示降維并轉(zhuǎn)換成一個分數(shù),即:
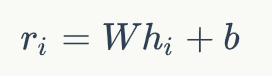
其中W和b是模型中可學習的參數(shù)。接下來對于每個文檔的分數(shù),我們通過一個文檔級別的比較和歸一化得到:
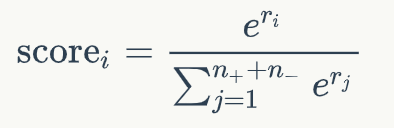
這一步,我們將文檔中的正例的分數(shù)和負例的分數(shù)進行比較,得到Listwise的排名分數(shù)。我通過這一步,我們得到了一個文檔排序列表,我們可以將文檔排序的優(yōu)化轉(zhuǎn)化為最大化正例的分數(shù)。因此,模型可以通過負對數(shù)似然損失優(yōu)化,如下式所示:
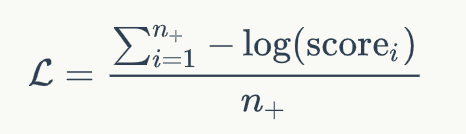
至于為什么使用兩個階段的精調(diào)模型,主要出于如下兩點考慮:
1. 我們發(fā)現(xiàn)首先學習問題和文檔的相關(guān)性特征然后學習排序的特征相比,直接學習排序特征效果好。
2. MARCO是標注不充分的數(shù)據(jù)集合。換句話說,許多和問題相關(guān)的文檔未被標注為1,這些噪聲容易造成模型過擬合。第一階段的模型可以用來過濾訓練數(shù)據(jù)中的噪聲,從而可以有更好的數(shù)據(jù)監(jiān)督第二階段的精調(diào)模型。解決OOV的錯誤匹配問題在BERT中,為了減少詞表的規(guī)模以及解決Out-of-vocabulary(OOV)的問題,使用了WordPiece方法來分詞。WordPiece會把不在詞表里的詞,即OOV詞拆分成片段,如圖6所示,原始的問題中包含詞“bogue”,而文檔中包含詞“bogus”。在WordPiece方法下,將“bogue”切分成”bog”和“##ue”,并且將“bogus”切分成”bog”和“##us”。我們發(fā)現(xiàn),“bogus”和“bogue”是不相關(guān)的兩個詞,但是由于WordPiece切分出了匹配的片段“bog”,導致兩者的相關(guān)性計算分數(shù)比較高。

圖6 BERT WordPiece處理前/后的文本 為了解決這個問題,我們提出了一種是對原始詞(WordPiece切詞之前)做精準匹配的特征。所謂“精確匹配”,指的是某個詞在文檔和問題中同時出現(xiàn)。精準匹配是信息檢索和機器閱讀理解中非常重要的一個技術(shù)。根據(jù)以往的研究,很多閱讀理解模型加入該特征之后都可以有一定的效果提升。具體的,在Fine-tuning階段,我們對于每個詞構(gòu)造了一個精準匹配特征,該特征表示該單詞是否出現(xiàn)在問題以及文檔中。在編碼階段之前,我們就將這個特征映射到一個向量,和原本的Embedding進行組合:

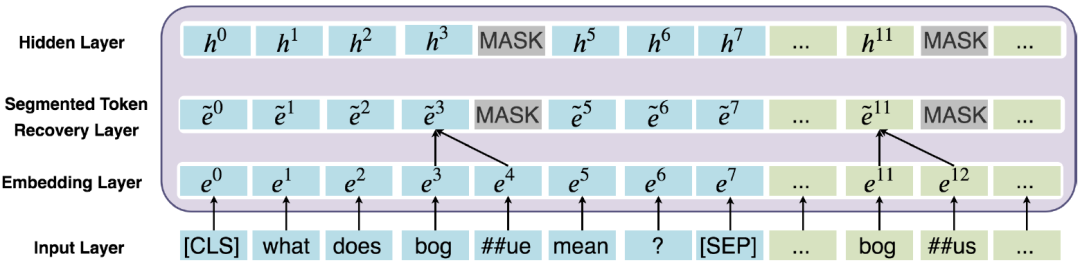
圖7 詞還原機制的工作原理 除此之外,我們還提出了一種詞還原機制如圖7所示,詞還原機制能夠?qū)ordPiece切分的Subtoken的表示合并,從而能更好地解決OOV錯誤匹配的問題。具體來說,我們使用Average Pooling對Subtoken的表示合并作為隱層的輸入。除此之外,如上圖7所示,我們使用了MASK處理Subtoken對應(yīng)的非首位的隱層位置。值得注意的是,詞還原機制也能很好地避免模型的過擬合問題。這是因為MARCO的集合標注是比較稀疏的,換句話說,有很多正例未被標注為1,因此容易導致模型過擬合這些負樣本。詞還原機制一定程度上起到了Dropout的作用。總結(jié)與展望以上內(nèi)容就對我們提出的DR-BERT模型進行了詳細的介紹。我們提出的DR-BERT模型主要采用了任務(wù)自適應(yīng)預訓練以及兩階段模型精調(diào)訓練。除此之外,還提出了詞還原機制和精確匹配特征提高OOV詞的匹配效果。通過在大規(guī)模數(shù)據(jù)集MS MARCO的實驗,充分驗證了該模型的優(yōu)越性,希望這些能對大家有所幫助或者啟發(fā)。
-
微軟
+關(guān)注
關(guān)注
4文章
6676瀏覽量
105447 -
算法
+關(guān)注
關(guān)注
23文章
4702瀏覽量
94931 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25313
原文標題:MT-BERT在文本檢索任務(wù)中的實踐
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于 NXP NCJ29D5D UWB 定位算法方案
?VLM(視覺語言模型)?詳細解析

【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+Embedding技術(shù)解讀
智能工具視頻特輯上線!5分鐘速通AI視覺算法方案和模型構(gòu)建

淺談加密芯片的一種破解方法和對應(yīng)加密方案改進設(shè)計
淺談加密芯片的一種破解方法和加密方案改進設(shè)計
一種使用LDO簡單電源電路解決方案
內(nèi)置誤碼率測試儀(BERT)和采樣示波器一體化測試儀器安立MP2110A






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論