") ?VLM(視覺語言模型)?詳細(xì)解析
?VLM(視覺語言模型)?詳細(xì)解析

視覺語言模型(Visual Language Model, VLM)是一種結(jié)合視覺(圖像/視頻)和語言(文本)處理能力的多模態(tài)人工智能模型,能夠理解并生成與視覺內(nèi)容相關(guān)的自然語言。以下是關(guān)于VLM的詳細(xì)解析:

1. 核心組成與工作原理
- 視覺編碼器:提取圖像特征,常用CNN(如ResNet)或視覺Transformer(ViT)。
- 語言模型:處理文本輸入/輸出,如GPT、BERT等,部分模型支持生成式任務(wù)。
- 多模態(tài)融合:通過跨模態(tài)注意力機(jī)制、投影層(如CLIP將圖像文本映射到同一空間)或適配器(Adapter)連接兩種模態(tài),實(shí)現(xiàn)信息交互。
訓(xùn)練數(shù)據(jù):依賴大規(guī)模圖像-文本對(如LAION、COCO),通過對比學(xué)習(xí)、生成式目標(biāo)(如看圖說話)或指令微調(diào)進(jìn)行訓(xùn)練。
2. 典型應(yīng)用場景
- 圖像描述生成:為圖片生成自然語言描述(如Alt文本)。
- 視覺問答(VQA):回答與圖像內(nèi)容相關(guān)的問題(如“圖中人的穿著顏色?”)。
- 多模態(tài)對話:結(jié)合圖像和文本進(jìn)行交互(如GPT-4V、Gemini的對話功能)。
- 輔助工具:幫助視障人士理解周圍環(huán)境(如微軟Seeing AI)。
- 內(nèi)容審核:識別違規(guī)圖像并生成審核理由。
- 教育/醫(yī)療:解釋醫(yī)學(xué)影像、輔助圖表理解或解題。
3. 關(guān)鍵挑戰(zhàn)
- 模態(tài)對齊:精確匹配圖像區(qū)域與文本描述(如區(qū)分“貓在沙發(fā)上”與“狗在椅子上”)。
- 計算資源:訓(xùn)練需大量GPU算力,推理成本高。
- 數(shù)據(jù)偏差:訓(xùn)練數(shù)據(jù)中的偏見可能導(dǎo)致模型輸出不公或錯誤(如性別/種族刻板印象)。
- 可解釋性:模型決策過程不透明,難以追蹤錯誤根源。
4. 未來發(fā)展方向
- 高效架構(gòu):減少參數(shù)量的輕量化設(shè)計(如LoRA微調(diào))、蒸餾技術(shù)。
- 多模態(tài)擴(kuò)展:支持視頻、3D、音頻等多模態(tài)輸入。
- 少樣本學(xué)習(xí):提升模型在低資源場景下的適應(yīng)能力(如Prompt Engineering)。
- 倫理與安全:開發(fā)去偏見機(jī)制,確保生成內(nèi)容符合倫理規(guī)范。
- 具身智能:結(jié)合機(jī)器人技術(shù),實(shí)現(xiàn)基于視覺-語言指令的物理交互。
5. 代表模型
- CLIP(OpenAI):通過對比學(xué)習(xí)對齊圖像與文本。
- Flamingo(DeepMind):支持多圖多輪對話。
- BLIP-2:利用Q-Former高效連接視覺與語言模型。
- LLaVA/MiniGPT-4:開源社區(qū)推動的輕量化VLM。
總結(jié)
VLM正在推動人機(jī)交互的邊界,從基礎(chǔ)研究到實(shí)際應(yīng)用(如智能助手、自動駕駛)均有廣闊前景。隨著技術(shù)的演進(jìn),如何在性能、效率與倫理間取得平衡,將是其發(fā)展的關(guān)鍵課題。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
發(fā)布評論請先 登錄
相關(guān)推薦
熱點(diǎn)推薦
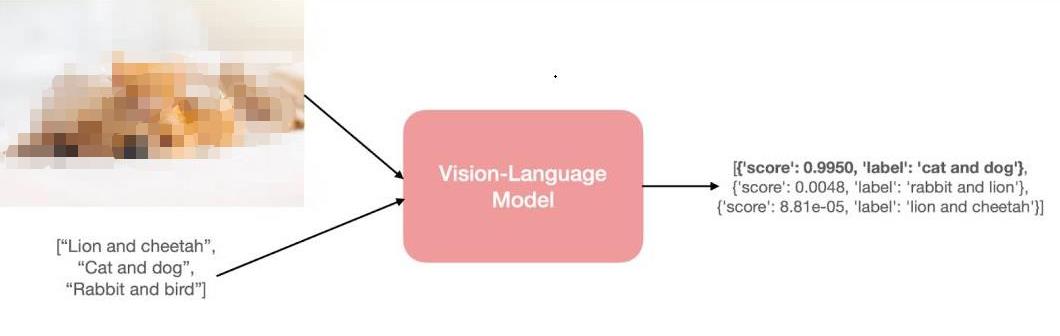
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
全面剖析大語言模型的核心技術(shù)與基礎(chǔ)知識。首先,概述自然語言的基本表示,這是理解大語言模型技術(shù)的前提。接著,
發(fā)表于 05-05 12:17
微軟視覺語言模型有顯著超越人類的表現(xiàn)
視覺語言(Vision-Language,VL)系統(tǒng)允許為文本查詢搜索相關(guān)圖像(或反之),并使用自然語言描述圖像的內(nèi)容。一般來說,一個VL系統(tǒng)使用一個圖像編碼模塊和一個視覺
利用視覺+語言數(shù)據(jù)增強(qiáng)視覺特征
傳統(tǒng)的多模態(tài)預(yù)訓(xùn)練方法通常需要"大數(shù)據(jù)"+"大模型"的組合來同時學(xué)習(xí)視覺+語言的聯(lián)合特征。但是關(guān)注如何利用視覺+語言數(shù)據(jù)提升
機(jī)器人接入大模型直接聽懂人話,日常操作輕松完成!
接著,LLM(大語言模型)根據(jù)這些內(nèi)容編寫代碼,所生成代碼與VLM(視覺語言模型)進(jìn)行交互,指導(dǎo)

語言模型的發(fā)展歷程 基于神經(jīng)網(wǎng)絡(luò)的語言模型解析
簡單來說,語言模型能夠以某種方式生成文本。它的應(yīng)用十分廣泛,例如,可以用語言模型進(jìn)行情感分析、標(biāo)記有害內(nèi)容、回答問題、概述文檔等等。但理論上,語言
發(fā)表于 07-14 11:45
?1144次閱讀

機(jī)器人基于開源的多模態(tài)語言視覺大模型
ByteDance Research 基于開源的多模態(tài)語言視覺大模型 OpenFlamingo 開發(fā)了開源、易用的 RoboFlamingo 機(jī)器人操作模型,只用單機(jī)就可以訓(xùn)練。
發(fā)表于 01-19 11:43
?684次閱讀

字節(jié)發(fā)布機(jī)器人領(lǐng)域首個開源視覺-語言操作大模型,激發(fā)開源VLMs更大潛能
對此,ByteDance Research 基于開源的多模態(tài)語言視覺大模型 OpenFlamingo 開發(fā)了開源、易用的 RoboFlamingo 機(jī)器人操作模型,只用單機(jī)就可以訓(xùn)練。

使用ReMEmbR實(shí)現(xiàn)機(jī)器人推理與行動能力
視覺語言模型(VLM)通過將文本和圖像投射到同一個嵌入空間,將基礎(chǔ)大語言模型(LLM)強(qiáng)大的
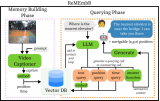
基于視覺語言模型的導(dǎo)航框架VLMnav
本文提出了一種將視覺語言模型(VLM)轉(zhuǎn)換為端到端導(dǎo)航策略的具體框架。不依賴于感知、規(guī)劃和控制之間的分離,而是使用VLM在一步中直接選擇動作
利用VLM和MLLMs實(shí)現(xiàn)SLAM語義增強(qiáng)
語義同步定位與建圖(SLAM)系統(tǒng)在對鄰近的語義相似物體進(jìn)行建圖時面臨困境,特別是在復(fù)雜的室內(nèi)環(huán)境中。本文提出了一種面向?qū)ο骃LAM的語義增強(qiáng)(SEO-SLAM)的新型SLAM系統(tǒng),借助視覺語言模型

NaVILA:加州大學(xué)與英偉達(dá)聯(lián)合發(fā)布新型視覺語言模型
(VLM)是一種具備多模態(tài)生成能力的先進(jìn)AI模型。它能夠智能地處理文本、圖像以及視頻等多種提示,并通過復(fù)雜的推理過程,實(shí)現(xiàn)對這些信息的準(zhǔn)確理解和應(yīng)用。NaVILA正是基于這一原理,通過將大型語言
小米汽車接入VLM視覺語言大模型,OTA更新帶來多項(xiàng)升級
小米汽車近日宣布,其SU7車型的1.4.5版OTA(空中升級)已經(jīng)開始推送。此次更新帶來了多項(xiàng)新增功能和體驗(yàn)優(yōu)化,旨在進(jìn)一步提升用戶的駕駛體驗(yàn)。 其中最引人注目的是,小米汽車正式接入了VLM視覺語言

拒絕“人工智障”!VLM讓RDK X5機(jī)器狗真正聽懂“遛彎”和“避障
項(xiàng)目思路現(xiàn)有跨形態(tài)機(jī)器人控制需為不同硬件單獨(dú)設(shè)計策略,開發(fā)成本高且泛化性差。本課題嘗試使用語言指令統(tǒng)一接口,用戶用自然語言指揮不同形態(tài)機(jī)器人完成同一任務(wù),通過分層強(qiáng)化學(xué)習(xí)框架,高層視覺語言






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論