") 字節(jié)發(fā)布機(jī)器人領(lǐng)域首個(gè)開(kāi)源視覺(jué)-語(yǔ)言操作大模型,激發(fā)開(kāi)源VLMs更大潛能
字節(jié)發(fā)布機(jī)器人領(lǐng)域首個(gè)開(kāi)源視覺(jué)-語(yǔ)言操作大模型,激發(fā)開(kāi)源VLMs更大潛能

還在苦苦尋找開(kāi)源的機(jī)器人大模型?試試RoboFlamingo!
近年來(lái),大模型的研究正在加速推進(jìn),它逐漸在各類(lèi)任務(wù)上展現(xiàn)出多模態(tài)的理解和時(shí)間空間上的推理能力。機(jī)器人的各類(lèi)具身操作任務(wù)天然就對(duì)語(yǔ)言指令理解、場(chǎng)景感知和時(shí)空規(guī)劃等能力有著很高的要求,這自然引申出一個(gè)問(wèn)題:能不能充分利用大模型能力,將其遷移到機(jī)器人領(lǐng)域,直接規(guī)劃底層動(dòng)作序列呢?
對(duì)此,ByteDance Research 基于開(kāi)源的多模態(tài)語(yǔ)言視覺(jué)大模型 OpenFlamingo 開(kāi)發(fā)了開(kāi)源、易用的 RoboFlamingo 機(jī)器人操作模型,只用單機(jī)就可以訓(xùn)練。使用簡(jiǎn)單、少量的微調(diào)就可以把 VLM 變成 Robotics VLM,從而適用于語(yǔ)言交互的機(jī)器人操作任務(wù)。
OpenFlamingo 在機(jī)器人操作數(shù)據(jù)集 CALVIN 上進(jìn)行了驗(yàn)證,實(shí)驗(yàn)結(jié)果表明,RoboFlamingo 只利用了 1% 的帶語(yǔ)言標(biāo)注的數(shù)據(jù)即在一系列機(jī)器人操作任務(wù)上取得了 SOTA 的性能。
隨著 RT-X 數(shù)據(jù)集開(kāi)放,采用開(kāi)源數(shù)據(jù)預(yù)訓(xùn)練 RoboFlamingo 并 finetune 到不同機(jī)器人平臺(tái),將有希望成為一個(gè)簡(jiǎn)單有效的機(jī)器人大模型 pipeline。論文還測(cè)試了各種不同 policy head、不同訓(xùn)練范式和不同 Flamingo 結(jié)構(gòu)的 VLM 在 Robotics 任務(wù)上微調(diào)的表現(xiàn),得到了一些有意思的結(jié)論。

項(xiàng)目主頁(yè):https://roboflamingo.github.io/
代碼鏈接:
https://github.com/RoboFlamingo/RoboFlamingo
論文鏈接:
https://arxiv.org/abs/2311.01378
研究背景
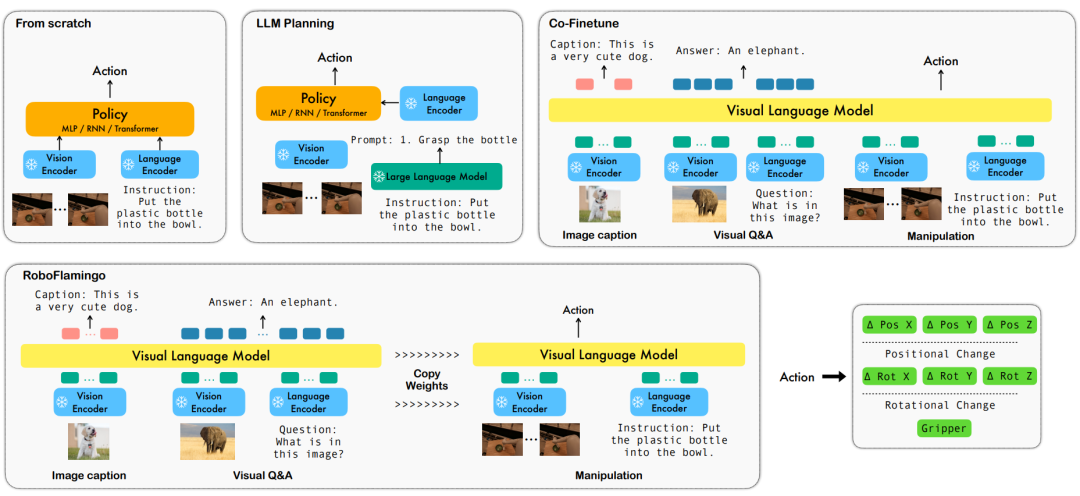
基于語(yǔ)言的機(jī)器人操作是具身智能領(lǐng)域的一個(gè)重要應(yīng)用,它涉及到多模態(tài)數(shù)據(jù)的理解和處理,包括視覺(jué)、語(yǔ)言和控制等。近年來(lái),視覺(jué)語(yǔ)言基礎(chǔ)模型(VLMs)已經(jīng)在多個(gè)領(lǐng)域取得了顯著的進(jìn)展,包括圖像描述、視覺(jué)問(wèn)答和圖像生成等。然而,將這些模型應(yīng)用于機(jī)器人操作仍然存在一些挑戰(zhàn),例如如何將視覺(jué)和語(yǔ)言信息結(jié)合起來(lái),如何處理機(jī)器人操作的時(shí)序性等。
為了解決這些問(wèn)題,ByteDance Research 的機(jī)器人研究團(tuán)隊(duì)利用現(xiàn)有的開(kāi)源 VLM,OpenFlamingo,設(shè)計(jì)了一套新的視覺(jué)語(yǔ)言操作框架,RoboFlamingo。其中 VLM 可以進(jìn)行單步視覺(jué)語(yǔ)言理解,而額外的 policy head 模組被用來(lái)處理歷史信息。只需要簡(jiǎn)單的微調(diào)方法就能讓 RoboFlamingo 適應(yīng)于基于語(yǔ)言的機(jī)器人操作任務(wù)。
RoboFlamingo 在基于語(yǔ)言的機(jī)器人操作數(shù)據(jù)集 CALVIN 上進(jìn)行了驗(yàn)證,實(shí)驗(yàn)結(jié)果表明,RoboFlamingo 只利用了 1% 的帶語(yǔ)言標(biāo)注的數(shù)據(jù)即在一系列機(jī)器人操作任務(wù)上取得了 SOTA 的性能(多任務(wù)學(xué)習(xí)的 task sequence 成功率為 66%,平均任務(wù)完成數(shù)量為 4.09,基線方法為 38%,平均任務(wù)完成數(shù)量為 3.06;zero-shot 任務(wù)的成功率為 24%,平均任務(wù)完成數(shù)量為 2.48,基線方法為 1%,平均任務(wù)完成數(shù)量是 0.67),并且能夠通過(guò)開(kāi)環(huán)控制實(shí)現(xiàn)實(shí)時(shí)響應(yīng),可以靈活部署在較低性能的平臺(tái)上。
這些結(jié)果表明,RoboFlamingo 是一種有效的機(jī)器人操作方法,可以為未來(lái)的機(jī)器人應(yīng)用提供有用的參考。
方法
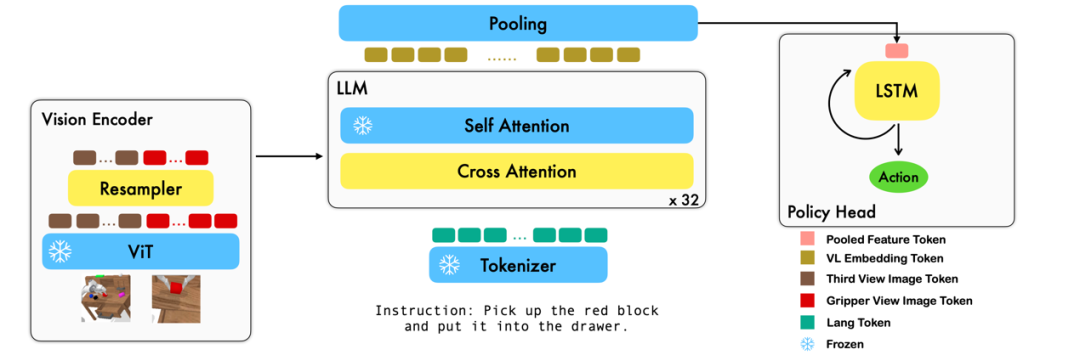
本工作利用已有的基于圖像 - 文本對(duì)的視覺(jué)語(yǔ)言基礎(chǔ)模型,通過(guò)訓(xùn)練端到端的方式生成機(jī)器人每一步的 relative action。模型的主要模塊包含了 vision encoder,feature fusion decoder 和 policy head 三個(gè)模塊。
Vision encoder 模塊先將當(dāng)前視覺(jué)觀測(cè)輸入到 ViT 中,并通過(guò) resampler 對(duì) ViT 輸出的 token 進(jìn)行 down sample。
Feature fusion decoder 將 text token 作為輸入,并在每個(gè) layer 中先將 vision encoder 的 output 作為 query 進(jìn)行 cross attention,之后進(jìn)行 self attention 以完成視覺(jué)與語(yǔ)言特征的融合。
最后,對(duì) feature fusion decoder 進(jìn)行 max pooling 后將其送入 policy head 中,policy head 根據(jù) feature fusion decoder 輸出的當(dāng)前和歷史 token 序列直接輸出當(dāng)前的 7 DoF relative action,包括了 6-dim 的機(jī)械臂末端位姿和 1-dim 的 gripper open/close。
在訓(xùn)練過(guò)程中,RoboFlamingo 利用預(yù)訓(xùn)練的 ViT、LLM 和 Cross Attention 參數(shù),并只微調(diào) resampler、cross attention 和 policy head 的參數(shù)。
實(shí)驗(yàn)結(jié)果
數(shù)據(jù)集:
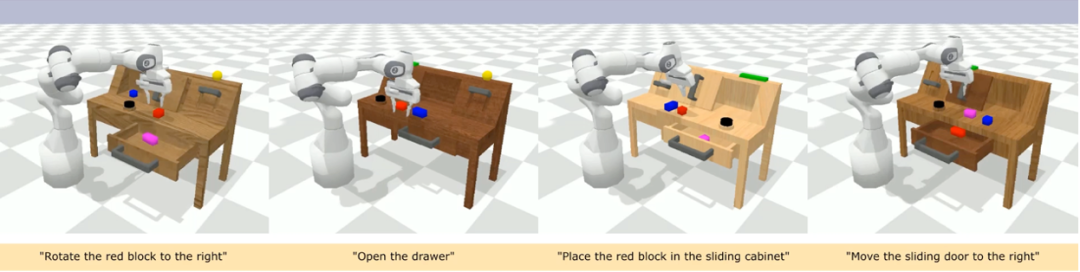
CALVIN(Composing Actions from Language and Vision)是一個(gè)開(kāi)源的模擬基準(zhǔn)測(cè)試,用于學(xué)習(xí)基于語(yǔ)言的 long-horizon 操作任務(wù)。與現(xiàn)有的視覺(jué) - 語(yǔ)言任務(wù)數(shù)據(jù)集相比,CALVIN 的任務(wù)在序列長(zhǎng)度、動(dòng)作空間和語(yǔ)言上都更為復(fù)雜,并支持靈活地指定傳感器輸入。CALVIN 分為 ABCD 四個(gè) split,每個(gè) split 對(duì)應(yīng)了不同的 context 和 layout。
定量分析:
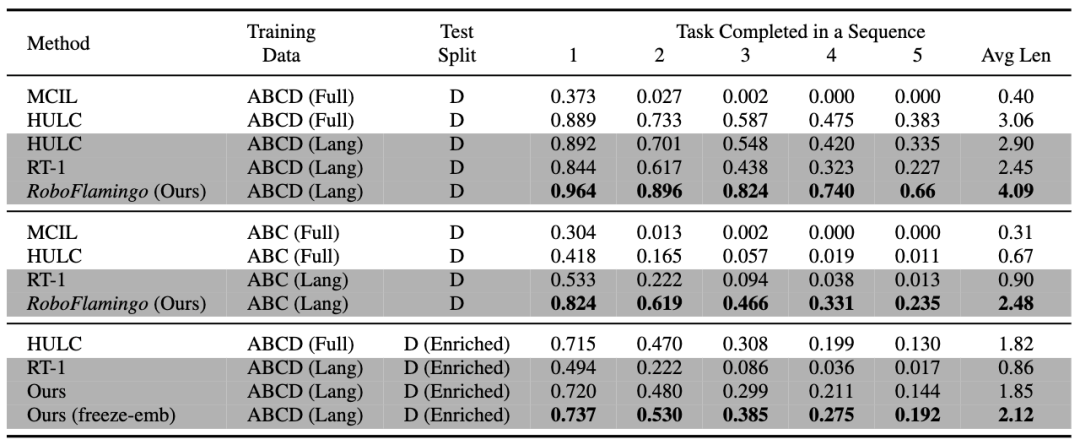
RoboFlamingo 在各設(shè)置和指標(biāo)上的性能均為最佳,說(shuō)明了其具有很強(qiáng)的模仿能力、視覺(jué)泛化能力以及語(yǔ)言泛化能力。Full 和 Lang 表示模型是否使用未配對(duì)的視覺(jué)數(shù)據(jù)進(jìn)行訓(xùn)練(即沒(méi)有語(yǔ)言配對(duì)的視覺(jué)數(shù)據(jù));Freeze-emb 指的是凍結(jié)融合解碼器的嵌入層;Enriched 表示使用 GPT-4 增強(qiáng)的指令。
消融實(shí)驗(yàn):
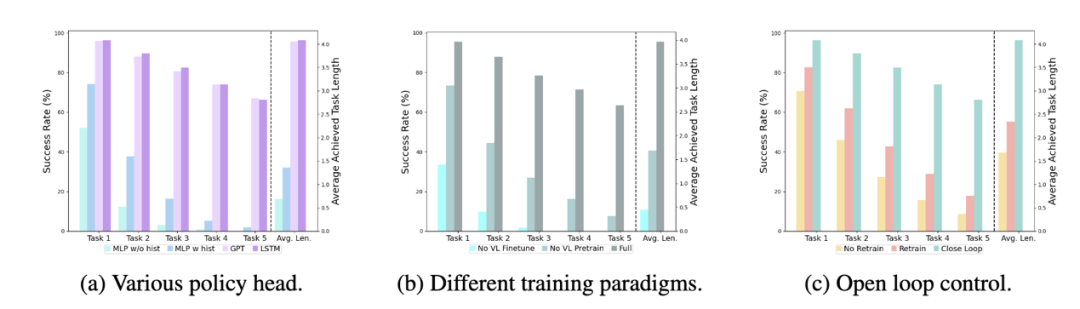
不同的 policy head:
實(shí)驗(yàn)考察了四種不同的策略頭部:MLP w/o hist、MLP w hist、GPT 和 LSTM。其中,MLP w/o hist 直接根據(jù)當(dāng)前觀測(cè)預(yù)測(cè)歷史,其性能最差,MLP w hist 將歷史觀測(cè)在 vision encoder 端進(jìn)行融合后預(yù)測(cè) action,性能有所提升;GPT 和 LSTM 在 policy head 處分別顯式、隱式地維護(hù)歷史信息,其表現(xiàn)最好,說(shuō)明了通過(guò) policy head 進(jìn)行歷史信息融合的有效性。
視覺(jué)-語(yǔ)言預(yù)訓(xùn)練的影響:
預(yù)訓(xùn)練對(duì)于 RoboFlamingo 的性能提升起到了關(guān)鍵作用。實(shí)驗(yàn)顯示,通過(guò)預(yù)先在大型視覺(jué)-語(yǔ)言數(shù)據(jù)集上進(jìn)行訓(xùn)練,RoboFlamingo 在機(jī)器人任務(wù)中表現(xiàn)得更好。
模型大小與性能:
雖然通常更大的模型會(huì)帶來(lái)更好的性能,但實(shí)驗(yàn)結(jié)果表明,即使是較小的模型,也能在某些任務(wù)上與大型模型媲美。
指令微調(diào)的影響:
指令微調(diào)是一個(gè)強(qiáng)大的技巧,實(shí)驗(yàn)結(jié)果表明,它可以進(jìn)一步提高模型的性能。






定性結(jié)果相較于基線方法,RoboFlamingo 不但完整執(zhí)行了 5 個(gè)連續(xù)的子任務(wù),且對(duì)于基線頁(yè)執(zhí)行成功的前兩個(gè)子任務(wù),RoboFlamingo 所用的步數(shù)也明顯更少。
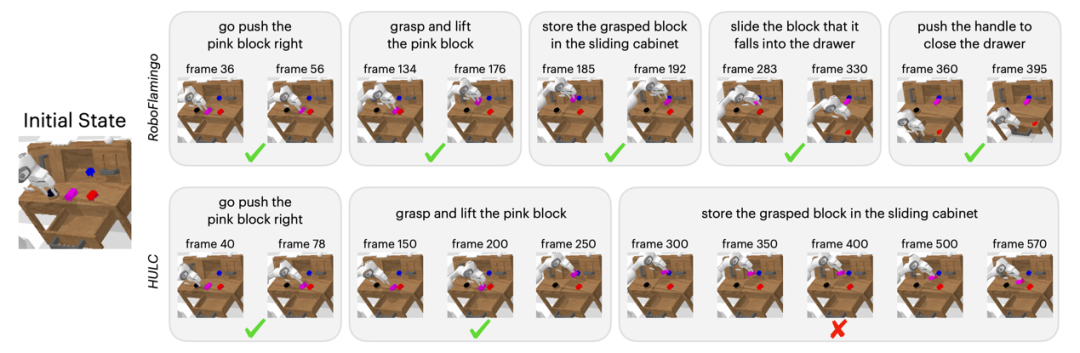
總結(jié)本工作為語(yǔ)言交互的機(jī)器人操作策略提供了一個(gè)新穎的基于現(xiàn)有開(kāi)源 VLMs 的框架,使用簡(jiǎn)單微調(diào)就能實(shí)現(xiàn)出色的效果。RoboFlamingo 為機(jī)器人技術(shù)研究者提供了一個(gè)強(qiáng)大的開(kāi)源框架,能夠更容易地發(fā)揮開(kāi)源 VLMs 的潛能。工作中豐富的實(shí)驗(yàn)結(jié)果或許可以為機(jī)器人技術(shù)的實(shí)際應(yīng)用提供寶貴的經(jīng)驗(yàn)和數(shù)據(jù),有助于未來(lái)的研究和技術(shù)發(fā)展。
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
29719瀏覽量
212779 -
開(kāi)源
+關(guān)注
關(guān)注
3文章
3677瀏覽量
43808 -
大模型
+關(guān)注
關(guān)注
2文章
3135瀏覽量
4056
原文標(biāo)題:字節(jié)發(fā)布機(jī)器人領(lǐng)域首個(gè)開(kāi)源視覺(jué)-語(yǔ)言操作大模型,激發(fā)開(kāi)源VLMs更大潛能
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Al大模型機(jī)器人
ROS讓機(jī)器人開(kāi)發(fā)更便捷,基于RK3568J+Debian系統(tǒng)發(fā)布!
大象機(jī)器人攜手進(jìn)迭時(shí)空推出 RISC-V 全棧開(kāi)源六軸機(jī)械臂產(chǎn)品
ColorSky雙足機(jī)器人開(kāi)源項(xiàng)目
ROS讓機(jī)器人開(kāi)發(fā)更便捷,基于RK3568J+Debian系統(tǒng)發(fā)布!
檢測(cè)機(jī)器人開(kāi)源分享

國(guó)內(nèi)首個(gè)!北京人形機(jī)器人創(chuàng)新中心成立
機(jī)器人基于開(kāi)源的多模態(tài)語(yǔ)言視覺(jué)大模型

英偉達(dá)GROOT N1 全球首個(gè)開(kāi)源人形機(jī)器人基礎(chǔ)模型
NVIDIA發(fā)布全球首個(gè)開(kāi)源人形機(jī)器人基礎(chǔ)模型Isaac GR00T N1
NVIDIA Isaac GR00T N1開(kāi)源人形機(jī)器人基礎(chǔ)模型+開(kāi)源物理引擎Newton加速機(jī)器人開(kāi)發(fā)
全國(guó)首個(gè)基于開(kāi)源鴻蒙的機(jī)器人操作系統(tǒng)M-Robots OS正式發(fā)布,中國(guó)機(jī)器人產(chǎn)業(yè)進(jìn)入“群體智能”新時(shí)代

開(kāi)源鴻蒙助力人形機(jī)器人產(chǎn)業(yè)發(fā)展
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車(chē)電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專(zhuān)欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論