") 一文詳解視覺語言模型
一文詳解視覺語言模型
視覺語言模型(VLM)是一種多模態(tài)、生成式 AI 模型,能夠理解和處理視頻、圖像和文本。
1什么是視覺語言模型?
視覺語言模型是通過將大語言模型(LLM)與視覺編碼器相結(jié)合構(gòu)建的多模態(tài) AI 系統(tǒng),使 LLM 具有“看”的能力。
憑借這種能力,VLM 可以處理并提供對提示中的視頻、圖像和文本輸入的高級理解,以生成文本響應(yīng)。
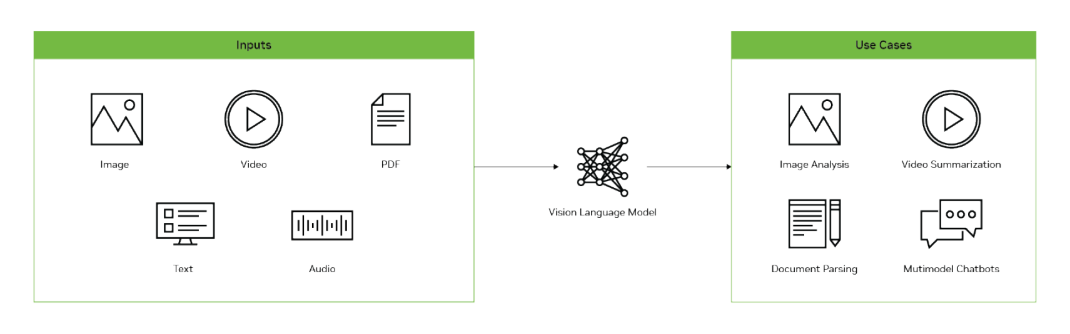
圖 1:視覺語言模型用例
與傳統(tǒng)的計算機視覺模型不同,VLM 不受固定類別集或特定任務(wù)(如分類或檢測)約束。在大量文本和圖像/視頻字幕對的語料上進(jìn)行重新訓(xùn)練,VLM 可以用自然語言進(jìn)行指導(dǎo),并用于處理許多典型的視覺任務(wù)以及新的生成式 AI 任務(wù),例如摘要和視覺問答。
2為何視覺語言模型很重要?
為了理解 VLM 的重要性,了解之前的計算機視覺(CV)模型的工作原理會很有幫助。傳統(tǒng)的基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的 CV 模型是在有限類別的(數(shù)據(jù))集(合)上針對特定任務(wù)進(jìn)行訓(xùn)練的。例如:
識別圖像中是否包含貓或狗的分類模型
讀取圖像中的文本,但不對文檔的格式或任何視覺數(shù)據(jù)進(jìn)行解讀的光學(xué)字符檢測和識別 CV 模型
以前的 CV 模型是為了特定目的而進(jìn)行訓(xùn)練的,無法超越其開發(fā)和訓(xùn)練的任務(wù)或類別集。如果用例發(fā)生根本變化或需要向模型添加新類別,開發(fā)人員則須收集和標(biāo)記大量圖像并重新訓(xùn)練模型。這是一個昂貴且耗時的過程。此外,CV 模型沒有任何自然語言理解。
VLM 結(jié)合基礎(chǔ)模型(如 CLIP)和 LLM 的功能,擁有視覺和語言能力,從而帶來了一類新能力。開箱即用,VLM 在各種視覺任務(wù)(如視覺問答、分類和光學(xué)字符識別)上具有強大的零樣本性能。它們也非常靈活,不僅可以用于一組固定類別集,而且可以通過簡單地更改文本提示用于幾乎任何用例。
使用 VLM 和與 LLM 交互非常類似。用戶提供可以與圖像交錯的文本提示。然后根據(jù)輸入來生成文本輸出。輸入提示是開放式的,允許用戶向 VLM 發(fā)出回答問題、總結(jié)、解釋內(nèi)容或使用圖像進(jìn)行推理的指令。用戶可以與 VLM 進(jìn)行多輪對話,并能夠在對話上下文中添加圖像。VLM 還可以集成到視覺智能體中,從而自主執(zhí)行視覺任務(wù)。
3視覺語言模型如何工作?
大多數(shù) VLM 架構(gòu)由三部分構(gòu)成:
視覺編碼器
投影器(Projector)
LLM
視覺編碼器通常是一個基于 transformer 架構(gòu)的 CLIP 模型,該模型已在數(shù)百萬個圖像-文本對進(jìn)行了訓(xùn)練,具有圖像與文本的關(guān)聯(lián)能力。投影器(Projector)由一組網(wǎng)絡(luò)層構(gòu)成,將視覺編碼器的輸出轉(zhuǎn)換為 LLM 可以理解的方式,一般解讀為圖像標(biāo)記(tokens)。投影器(Projector)可以是如 LLLaVA 與 VILA 中的簡單線性層,或者是如 Llama 3.2 Vision 中使用的交叉注意力層更復(fù)雜的結(jié)構(gòu)。
任何現(xiàn)有的 LLM 都可以用來構(gòu)建 VLM。有數(shù)百種結(jié)合了各種 LLM 與視覺編碼器的 VLM 變體。
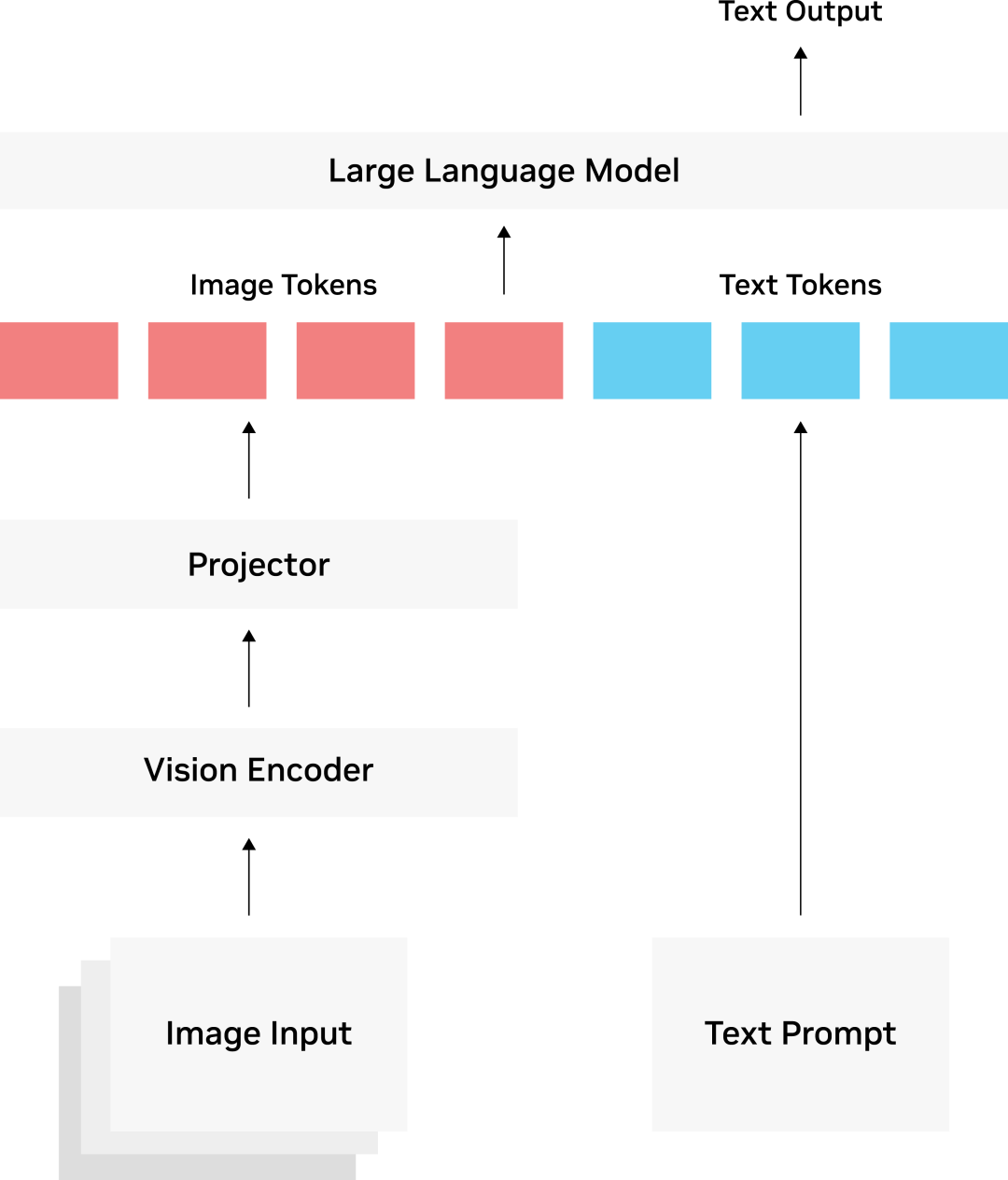
圖 2:視覺語言模型的通用三部分架構(gòu)
4如何訓(xùn)練視覺語言模型?
VLM 的訓(xùn)練分為幾個階段,包括預(yù)訓(xùn)練,之后是監(jiān)督式微調(diào)。或者,參數(shù)有效微調(diào)(PEFT)也可以作為最后階段在自定義數(shù)據(jù)上構(gòu)建特定領(lǐng)域 VLM(的訓(xùn)練方法)。
預(yù)訓(xùn)練階段將視覺編碼器(encoder)、投影器(projector)和 LLM 對齊,使其在解釋文本和圖像輸入時基本上使用相同的語言。這是使用包含圖像——標(biāo)題對與交錯圖像-文本數(shù)據(jù)的大量文本及圖像語料來完成的。一旦通過預(yù)訓(xùn)練將三部分對齊,VLM 就會通過監(jiān)督微調(diào)階段來幫助了解如何響應(yīng)用戶提示。
這一階段使用的數(shù)據(jù)是示例提示與文本和/或圖像輸入以及模型的預(yù)期響應(yīng)的混合。例如,這些數(shù)據(jù)可以是提示模型描述圖像或統(tǒng)計該幀內(nèi)所有目標(biāo)數(shù)量,以及預(yù)期正確的響應(yīng)。經(jīng)過這一輪訓(xùn)練,VLM 將了解如何最好地解讀圖像并響應(yīng)用戶提示。
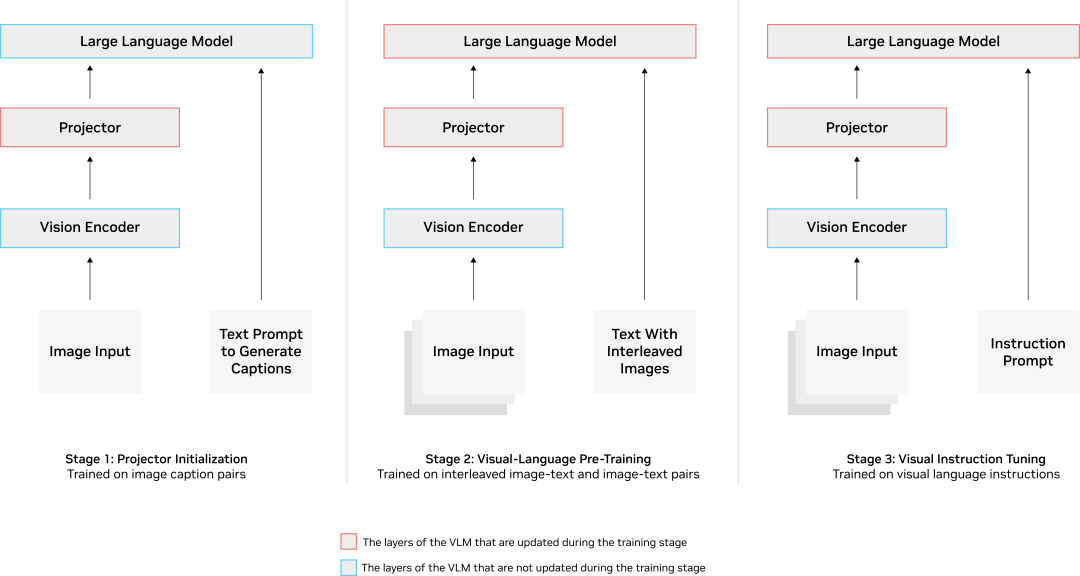
圖 3:VLM 訓(xùn)練通常針對模型的特定部分,分幾個階段完成
VLM 一旦訓(xùn)練完成,可以以與 LLM 相同的方式,即提供提示的方式使用,該提示還可以在文本中穿插圖像。然后,VLM 將根據(jù)輸入生成文本響應(yīng)。VLM 通常使用 OpenAI 風(fēng)格的 REST API 接口進(jìn)行部署,以便于與模型交互。
目前正在研究更先進(jìn)的技術(shù)來增強視覺能力:
整合視覺編碼器來處理圖像輸入
將高分辨率圖像輸入分割為更小的圖塊進(jìn)行處理
增加上下文長度,以改善長視頻理解能力
所有這些進(jìn)展都在提升 VLM 的能力,從僅僅理解單一圖像輸入發(fā)展為能夠比較與對比圖像、準(zhǔn)確閱讀文本、理解長視頻并具有強大空間理解能力的高性能模型。
5視覺語言模型如何進(jìn)行基準(zhǔn)測試?
目前存在的常見基準(zhǔn)測試,如 MMMU、Video-MME、MathVista、ChartQA 和 DocVQA,用于確定視覺語言模型在各種任務(wù)上的表現(xiàn),例如:
視覺問答
邏輯和推理
文檔理解
多圖像比較
視頻理解
大多數(shù)基準(zhǔn)測試由一組圖像和幾個相關(guān)問題組成,通常以多選題的形式呈現(xiàn)。多選題是一致性基準(zhǔn)測試和比較 VLM 的最簡單方法。這些問題測試 VLM 的感知、知識和推理能力。在運行這些基準(zhǔn)測試時,VLM 會收到圖像、問題以及它必須做出選擇的多選題答案。

圖4:VLMs(視覺語言類模型)使用 MMMU 基準(zhǔn)測試的多選題示例
來源:MMMU
VLM 的準(zhǔn)確度是指一組多選題中做出正確選項的數(shù)量。一些基準(zhǔn)還包括數(shù)字問題,其中 VLM 必須執(zhí)行特定的計算,并且在答案的一定百分比范圍內(nèi)才被視為正確。這些問題和圖像通常來源于學(xué)術(shù)資料,如大學(xué)教材。
6如何使用視覺語言模型?
VLM 憑借其靈活性和自然語言理解能力,正迅速成為所有視覺相關(guān)任務(wù)類型的首選工具。可以通過自然語言輕松指示 VLM 執(zhí)行各種各樣的任務(wù):
視覺問答
圖像和視頻總結(jié)
文本解析和手寫文檔
以前需要大量經(jīng)過特殊訓(xùn)練的模型的應(yīng)用程序現(xiàn)在只需一個 VLM 即可完成。
VLM 尤其擅長總結(jié)圖像內(nèi)容,并且可以根據(jù)內(nèi)容提示執(zhí)行特定任務(wù)。以教育用例為例——可以向 VLM 提供一張手寫數(shù)學(xué)問題的圖像,它可以使用其光學(xué)字符識別和推理能力來解讀該問題并生成如何解決問題的分步指南。VLM 不僅能夠理解圖像的內(nèi)容,還可進(jìn)行推理并執(zhí)行特定任務(wù)。

圖 5:視頻分析 AI 智能體將視頻和圖像數(shù)據(jù)轉(zhuǎn)換為真實世界的見解
每天都會產(chǎn)生大量的視頻,因此審查各行各業(yè)制作的大量視頻并從中提取見解是不可行的。VLM 可以集成到更大的系統(tǒng)中,以構(gòu)建在提示時具有檢測特定事件能力的視頻分析 AI 智能體。這些系統(tǒng)可用于檢測倉庫中發(fā)生故障的機器人,或在貨架變空時發(fā)出缺貨警報。其總體理解超越了單純的檢測,還可以用來生成自動報告。例如,智能交通系統(tǒng)可以檢測、分析并生成交通危險報告,如倒下的樹木、停滯的車輛或發(fā)生碰撞。
VLM 可與圖數(shù)據(jù)庫等技術(shù)一起使用來理解長視頻。這有助于其捕捉視頻中復(fù)雜的物體和活動。此類系統(tǒng)可用于總結(jié)倉庫中的操作以發(fā)現(xiàn)瓶頸和低效環(huán)節(jié),或為足球、籃球或足球比賽制作體育解說。
7視覺語言模型面臨哪些挑戰(zhàn)?
視覺語言模型正在迅速成熟,但它們?nèi)匀淮嬖谝恍┚窒扌裕貏e是在空間理解和長上下文視頻理解方面。
多數(shù) VLM 采用基于 CLIP 的模型作為視覺編碼器,輸入圖像大小被限制為 224x224 或 336x336。這種較小的輸入圖像導(dǎo)致小物體和細(xì)節(jié)很難被檢測到。例如,視頻的高清 1080x1920 幀必須壓縮或裁剪為更小的輸入分辨率,導(dǎo)致很難保留小物體或精細(xì)的細(xì)節(jié)。為了解決這個問題,VLM 開始使用平鋪方法,將大圖像分解成更小的塊,然后輸入到模型中。目前還在進(jìn)行研究,探索使用更高分辨率的圖像編碼器。
VLM 也難以提供物體的精確位置。基于 CLIP 的視覺編碼器的訓(xùn)練數(shù)據(jù)主要由圖像的簡短文本描述(如標(biāo)題)組成。這些描述不包括詳細(xì)的、細(xì)粒度的物體位置,這種限制會影響 CLIP 的空間理解。采用其作為視覺編碼器的 VLM 繼承了這一限制。新的方法正在探索集成多個視覺編碼器來克服這些限制 2408.15998 (arxiv.org)。
長視頻理解是一項挑戰(zhàn),因為需要考慮長達(dá)數(shù)小時的視頻中的視覺信息才能正確分析或回答問題。與 LLM 一樣,VLM 具有有限的上下文長度含義——只能涵蓋視頻中的一定數(shù)量的幀來回答問題。目前正在研究增加上下文長度和在更多基于視頻的數(shù)據(jù)上訓(xùn)練 VLM 的方法,例如 LongVILA 2408.10188(arxiv.org)。
對于非常具體的用例(例如,在特定產(chǎn)品線中發(fā)現(xiàn)制造缺陷)而言,VLM 可能沒有看到足夠的數(shù)據(jù)。這些限制可以通過在特定領(lǐng)域的數(shù)據(jù)上微調(diào) VLM 來克服,或者使用帶有上下文學(xué)習(xí)的多圖像 VLM 來提供示例,這些示例可以在不顯式訓(xùn)練模型的情況下傳授模型新的信息。使用 PEFT 對特定領(lǐng)域數(shù)據(jù)進(jìn)行模型訓(xùn)練是另一種可用于提高 VLM 在自定義數(shù)據(jù)上準(zhǔn)確性的技術(shù)。
8如何開始使用視覺語言模型?
NVIDIA 提供了一些工具來簡化視覺語言模型的構(gòu)建和部署:
NVIDIA NIM:NVIDIA NIM 是一組推理微服務(wù),包括行業(yè)標(biāo)準(zhǔn) API、領(lǐng)域特定代碼、優(yōu)化推理引擎和企業(yè)運行時。點擊此處查看當(dāng)前可用的 VLM NIM。我們創(chuàng)建了 NIM 參考工作流,幫助您快速上手。
NVIDIA AI Blueprint:NVIDIA AI Blueprint 是生成式 AI 用例的參考工作流程,使用 NVIDIA NIM 微服務(wù)構(gòu)建,作為 NVIDIA AI 企業(yè)平臺的一部分。用于視頻搜索和摘要的 NVIDIA AI Blueprint 可幫助您構(gòu)建和定制交互式視頻分析 AI 智能體,該智能體能夠使用視覺 VLM、LLM 和 RAG 理解大量實時或存檔視頻中的活動。
9開始學(xué)習(xí)
學(xué)習(xí)視頻分析 AI 智能體
視頻分析 AI 智能體可以結(jié)合視覺和語言模式來理解自然語言提示并進(jìn)行視覺回答。
-
編碼器
+關(guān)注
關(guān)注
45文章
3775瀏覽量
137166 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5246瀏覽量
105775 -
AI
+關(guān)注
關(guān)注
87文章
34256瀏覽量
275414 -
模型
+關(guān)注
關(guān)注
1文章
3487瀏覽量
49996
原文標(biāo)題:麗臺科普丨讓 AI "看懂"世界!一文搞懂視覺語言模型(VLM)
文章出處:【微信號:Leadtek,微信公眾號:麗臺科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
一文詳解知識增強的語言預(yù)訓(xùn)練模型
微軟視覺語言模型有顯著超越人類的表現(xiàn)
機器人基于開源的多模態(tài)語言視覺大模型

一文理解多模態(tài)大語言模型——下

NaVILA:加州大學(xué)與英偉達(dá)聯(lián)合發(fā)布新型視覺語言模型
?VLM(視覺語言模型)?詳細(xì)解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論