 一文詳解知識增強的語言預訓練模型
一文詳解知識增強的語言預訓練模型
來自:復旦DISC
作者:王思遠
引言
隨著預訓練語言模型(PLMs)的不斷發展,各種NLP任務設置上都取得了不俗的性能。盡管PLMs可以從大量語料庫中學習一定的知識,但仍舊存在很多問題,如知識量有限、受訓練數據長尾分布影響魯棒性不好等,在實際應用場景中效果不好。為了解決這個問題,將知識注入到PLMs中已經成為一個非常活躍的研究領域。本次分享將介紹三篇知識增強的預訓練語言模型論文,分別通過基于知識向量、知識檢索以及知識監督的知識注入方法來增強語言預訓練模型。
文章概覽
KLMo:建模細粒度關系的知識圖增強預訓練語言模型(KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships)
這篇文章提出同時將KG中的實體以及實體間的關系結合到語言學習過程中,來得到一個知識增強預訓練模型。通過一個知識聚合器對文本中的實體片段和KG中的實體、關系向量之間的交互建模,從而將KG中的實體和關系向量融入語言模型中,還提出了關系預測和實體鏈接的預訓練任務來整合KG中關系和實體信息。
用于知識增強語言模型預訓練的基于知識圖合成語料庫生成(Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training)
檢索型語言模型通過從外部文本知識語料集中檢索知識增強模型,本文為了整合結構化知識和自然語言數據,提出了將知識圖譜轉換為自然文本,來為檢索型語言模型擴充檢索知識語料庫,從而使得結構化知識無縫地集成到現有的預訓練語言模型中。
ERICA:通過對比學習提高預訓練語言模型對實體和關系的理解(ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning)
這篇文章提出對文本中的關系事實進行建模來增強語言模型,具體地設計了實體判別和關系判別兩個預訓練任務來以知識監督的方式加深對實體和關系的理解,并通過對比學習的框架實現。
論文細節
1論文動機
本文類似ERNIE-THU[1],通過引入知識向量增強預訓練語言模型,然而以前的知識增強模型只利用實體信息,而忽略了實體之間的細粒度關系。而實體間的關系對于語言表示學習也至關重要,如圖KG中的關系信息影響了實體Trio of Happiness的類別預測。
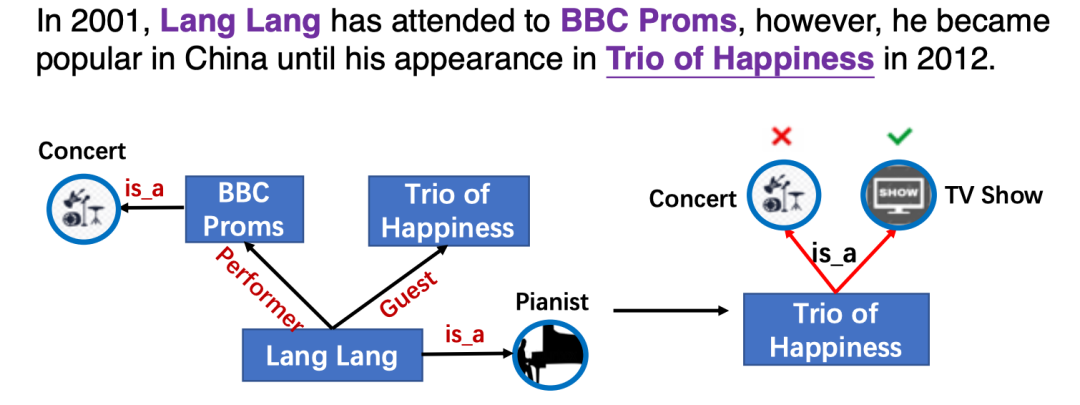
將KG中的實體和關系明確地整合到PLMs中的主要挑戰是文本知識(實體和關系)對齊(TKA)問題,為了解決這個問題,文章提出了一個知識增強預訓練語言模型(KLMo),通過一個知識聚合器對文本中的實體片段和KG中的實體、關系向量之間的交互建模,使得文本中token關注到高度相關的KG實體和關系。文章還提出了關系預測和實體鏈接的兩個預訓練任務,來整合KG中關系和實體信息,從而實現將KG中的實體和關系信息融入語言模型中。
模型
KLMo模型如下圖,結構上類似ERNIE-THU,文本序列首先經過一個文本編碼器,然后會被輸入到知識聚合器中來將實體和關系的知識向量融入到文本序列中,最后通過優化關系預測和實體鏈接兩個預訓練目標,從而將KG中高度相關的實體和關系信息合并到文本表示中。
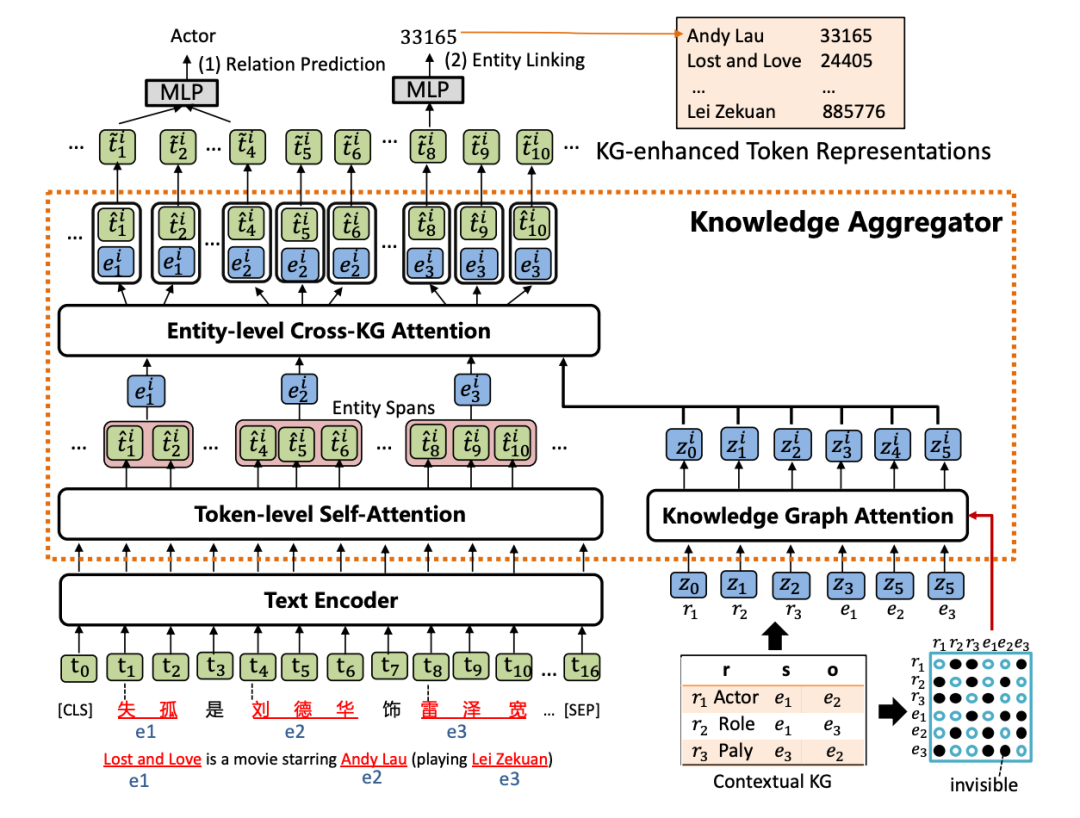
1. 知識聚合器
知識聚合器包含兩個獨立的注意力機制:token級別自注意力和知識圖譜注意力,分別對輸入文本和KG進行編碼,聚合器通過實體級別的交叉KG注意力,對文本中的實體片段與KG中的實體和關系之間的交互進行建模,以將知識融入文本表示。
(1) 知識圖譜注意力機制
首先通過TransE得到KG中的實體和關系表示,并將其轉成一條實體和關系向量序列,作為聚合器的輸入。然后采用一個知識圖譜注意力機制,通過在傳統注意力機制中引入一個可視矩陣,從而在知識表示學習過程中考慮圖結構,該矩陣只允許相鄰節點和關系可以關注到彼此。
(2) 實體級別交叉KG注意力機制
給定一個實體提及列表,通過在文本中實體范圍內的所有tokens上pooling計算得到文本中實體片段表示,然后將文本中的實體片段表示作為query,將KG中的實體和關系表示作為key和value,進行注意力計算,從而得到知識增強的實體表示。
(3) 知識增強的文本表示
為了將知識增強的實體表示注入到文本表示中,文章采用一個知識融入操作,公式如下,得到的知識增強文本表示將會被傳入下一層知識聚合器中。
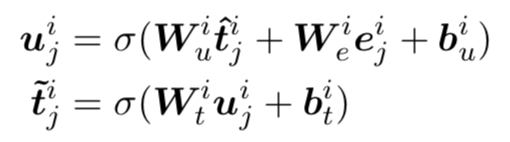
2. 預訓練目標
為了將知識融入到語言預訓練中,KLMo采取了一個多任務損失函數,除了傳統的masked language model損失,還引入了一個關系預測以及實體鏈接的損失函數。
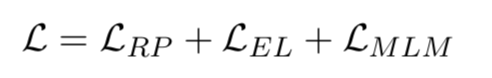
實驗
模型在百度百科網頁數據以及百科知識圖譜上進行預訓練,并在兩個分別用于實體分類以及關系分類的中文數據集上進行了比較和評估,結果顯示實體之間的細粒度關系信息有助于KLMo更準確地預測實體和關系的類別。
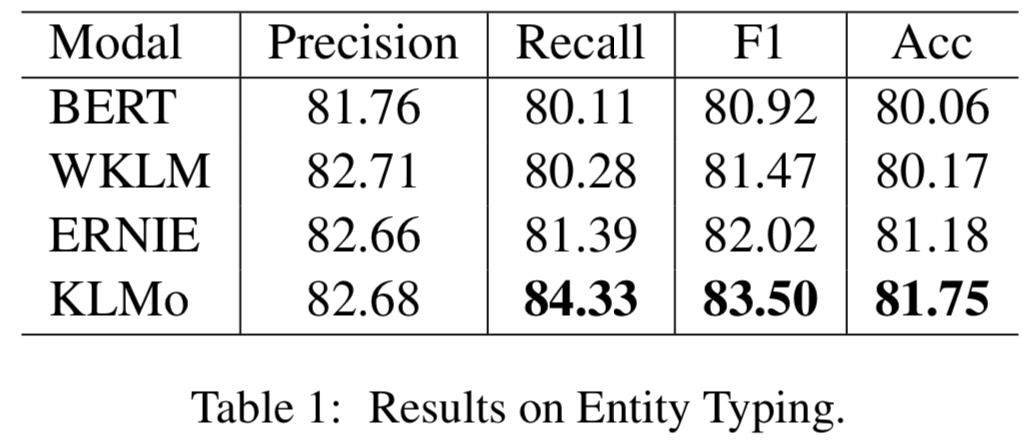
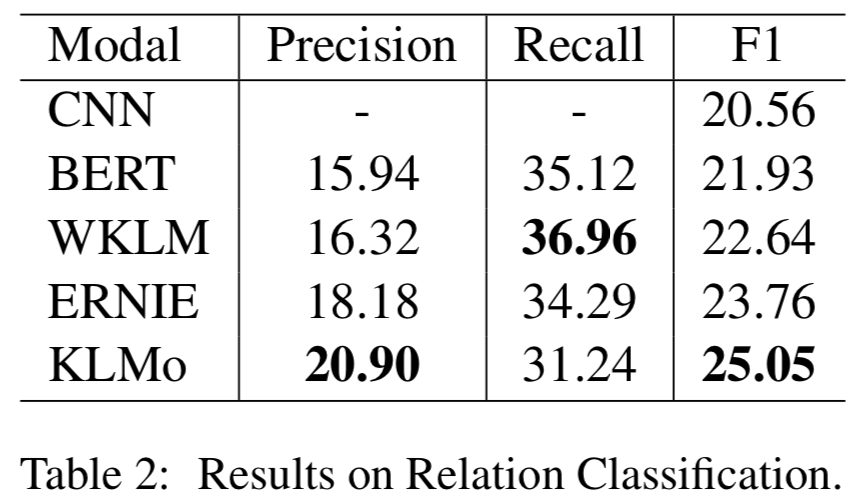
同時文章還在實體分類上對KLMo中實體和關系知識進行了消融實驗,結果如下可以看出通過預訓練,知識信息已經被融入KLMo中。
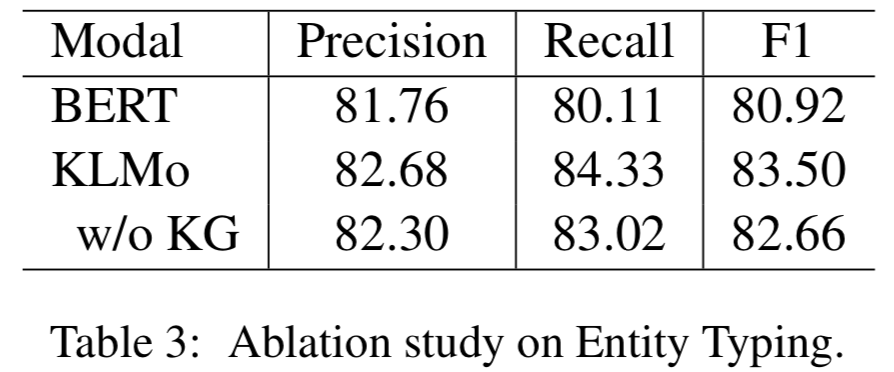
2

論文動機
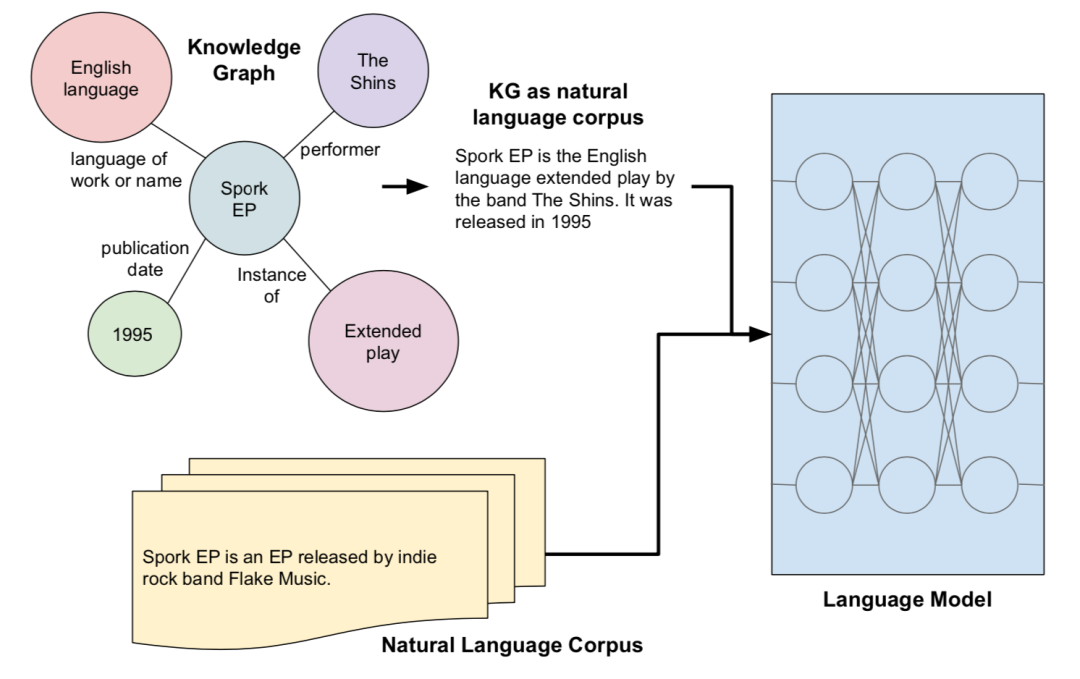
本文基于檢索型預訓練語言模型,通過從外部知識語料集檢索知識來增強語言模型,然而以前都是從文本語料集中檢索知識,只能覆蓋有限的世界知識而忽略了結構化知識,并且知識在文本中的表達沒有在KG中那么明確,文本質量的變化也會導致結果模型中的偏差。為了將結構化知識整合到語言模型中,文章將結構化知識圖譜轉換為自然文本,來為檢索型語言模型REALM[2]擴充檢索知識語料庫KELM,從而使得結構化知識無縫地集成到現有的預訓練語言模型中。
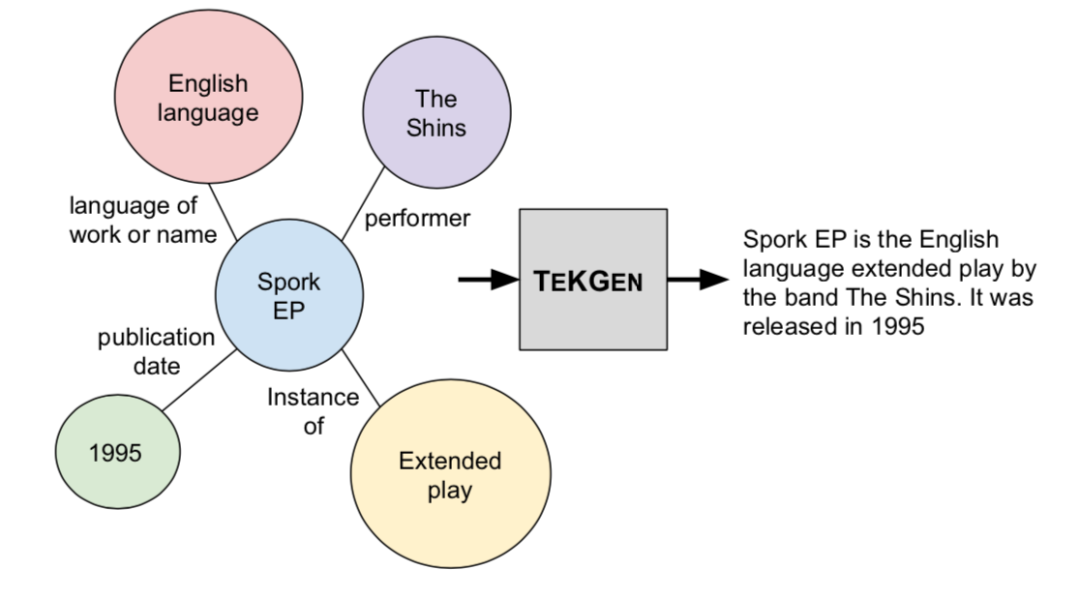
本文提出將英文維基百科知識圖譜轉化成自然語言文本,如上圖,并構建了一個英文Wikidata KG-Wikipedia Text的對齊數據集來訓練文本化模型,從而生成了KELM數據集,擴充REALM的檢索知識語料庫。
模型
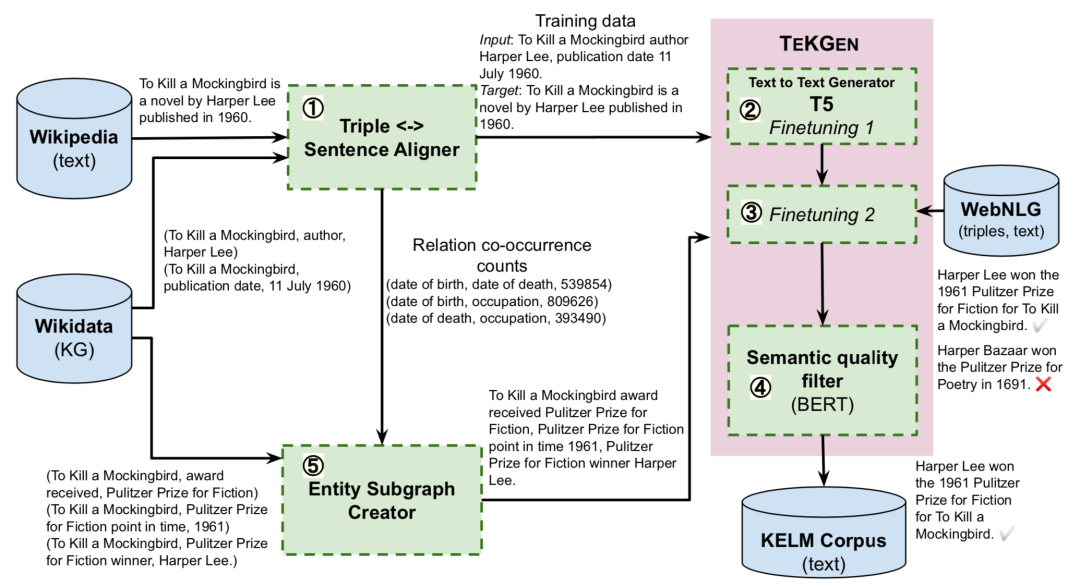
1. 基于KG的文本生成器TEKGEN
文章首先提出了一個端到端的基于KG的文本化模型TEKGEN,具體流程如上圖:首先使用遠程監督來對齊維基百科文本和KG三元組;隨后T5模型按順序首先在這個語料庫上進行微調來提升實體和關系覆蓋率,隨后在標準WebNLG語料庫上進行少量步驟的訓練來減少錯誤;最后通過對BERT微調構建一個過濾器,為生成文本針對三元組的語義質量打分。
2. 合成知識檢索數據集KELM Corpus
這一步利用TEKGEN模型和過濾器來構建一個合成語料庫KELM,以自然語言的格式捕獲KG知識。首先使用前面構造的英文Wikidata KG-Wikipedia Text的對齊數據集的關系對創建實體子圖,隨后子圖中的知識三元組通過TEKGEN模型轉化為自然語言文本,從而構建KELM數據集。
3.知識增強語言模型
文章將生成的KELM語料庫作為將KGs集成到預訓練語言模型,如下圖所示,采用了基于檢索的預訓練語言模型REALM,預訓練過程中,除了掩碼句還會從檢索語料集中抽取一個文本作為輔助知識用來聯合預測掩蓋的單詞,而KELM則被用來替換/擴充REALM中的檢索語料集,幫助語言模型引入結構化知識。
實驗
實驗在知識探測(LAMA數據集)和開放域QA(NaturalQuestions和WebQuestions)上進行,作者分別嘗試REALM上的三種檢索語料集設定:ORIGINAL(Wikipedia Text)、REPLACED(only KELM Corpus)和AUGMENTED(Wikipedia text + KELM Corpus),結果如下:
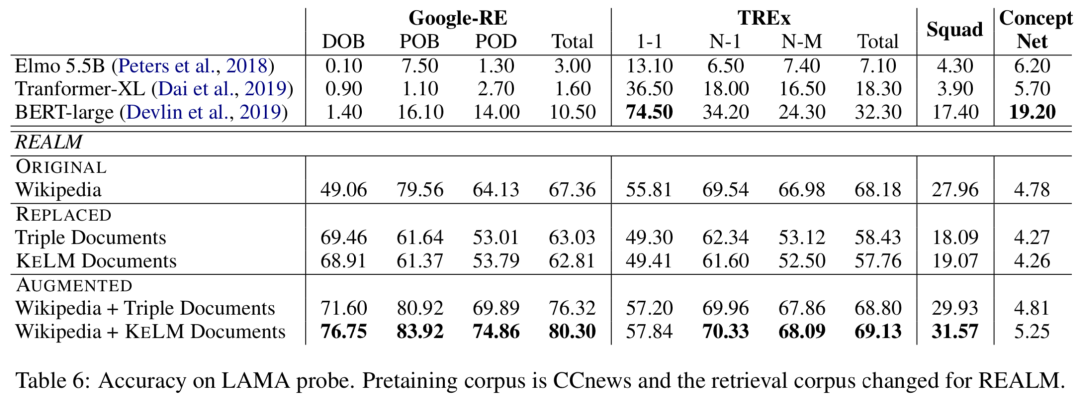
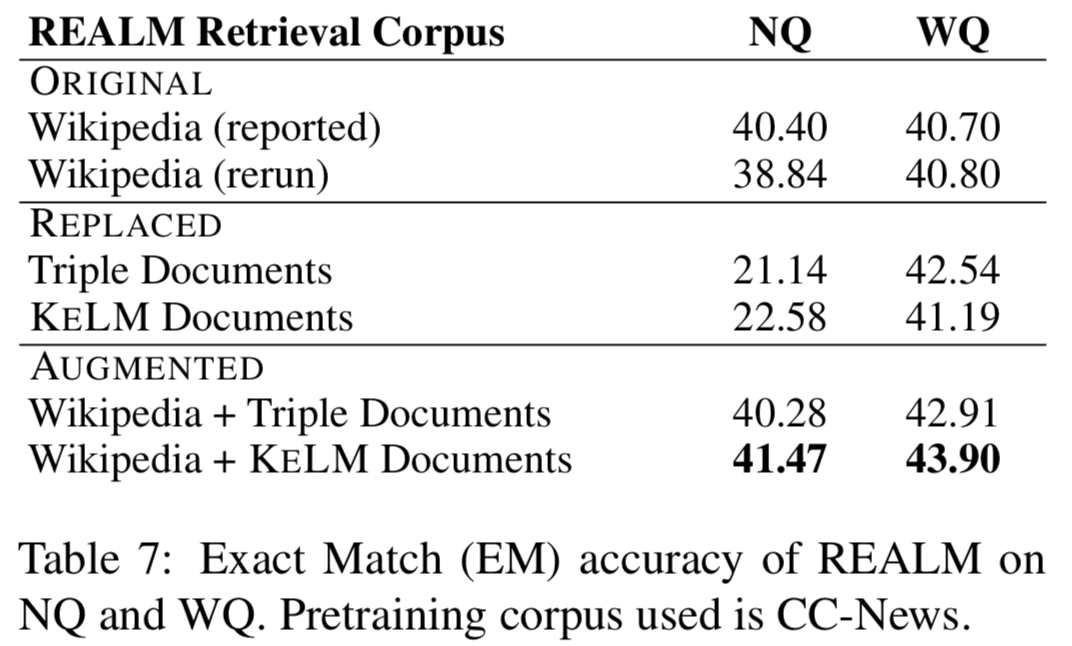
可以看出通過文本化結構知識來擴充檢索語料集,在知識探測和開放域QA上都有提升。作者還進行了實驗,將原始的Wikidata三元組而非KELM語料庫整合進語言模型,結果確認了結構化知識文本化的有效性。
3

論文動機
本文通過知識監督的方式來建模文本中的關系事實從而增強預訓練語言模型,包括同時建模句子內以及跨句子的關系信息,并提出對比學習的框架ERICA來全面學習實體和關系的交互,從而更好捕捉文本中關系事實。具體包含了兩個預訓練任務:(1)實體判別:給定一個頭實體和關系,推斷可能的尾實體;(2)關系判別:判別兩個關系是否語義相似。
模型
ERICA根據無監督數據集和外部知識圖譜構建遠程監督幫助預訓練。給定一個段落,枚舉出所有實體以及它們之間存在的關系,從而構建整個對比學習的正樣本集。
1. 實體&關系表示
給定一個文本,首先使用PLM進行編碼并得到每個token的隱表示,然后對提及實體的連續tokens上的表示做mean pooling得到當前實體表示,如果一個文本多次提及一個實體,則對多個表示進行平均得到最終實體表示,而對于關系表示,通過組合關系的首尾實體的表示得到其表示。
2. 實體判別任務
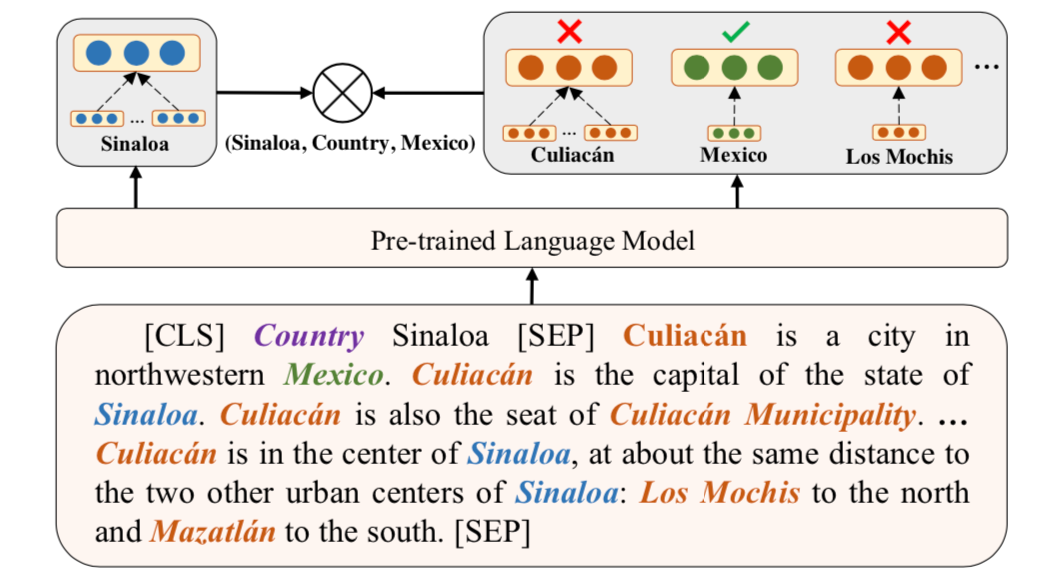
從正樣本集中選擇一個元組,給定其中的頭實體和關系,通過對比學習使得正確尾實體相較于文本中其他實體,要和頭實體更相近,具體公式如下。
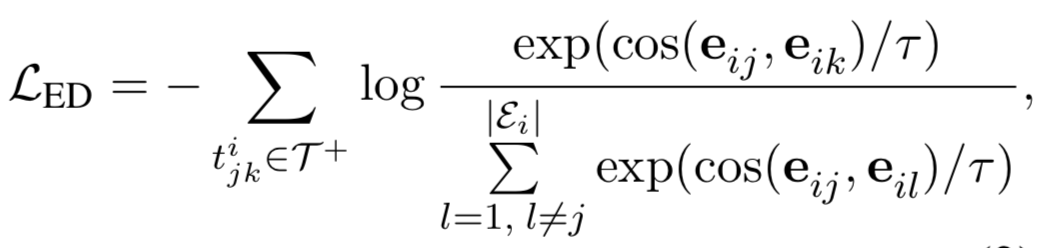
3. 關系判別任務
這個任務需要判別兩個關系是否語義相似,這里考慮到了句子內以及跨句子的關系,從而使得模型隱式地學習到了復雜關系鏈。具體方法如上圖,通過對比學習使得相同的關系表示(由實體對表示計算得到)應該更相近。
實驗
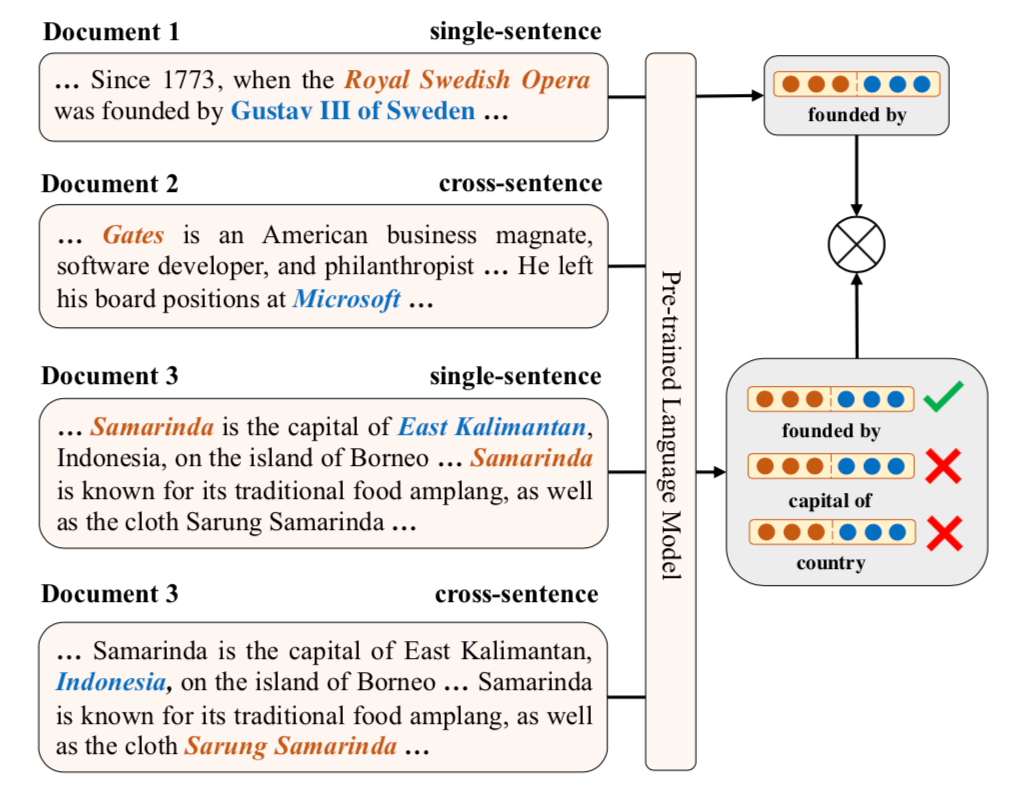
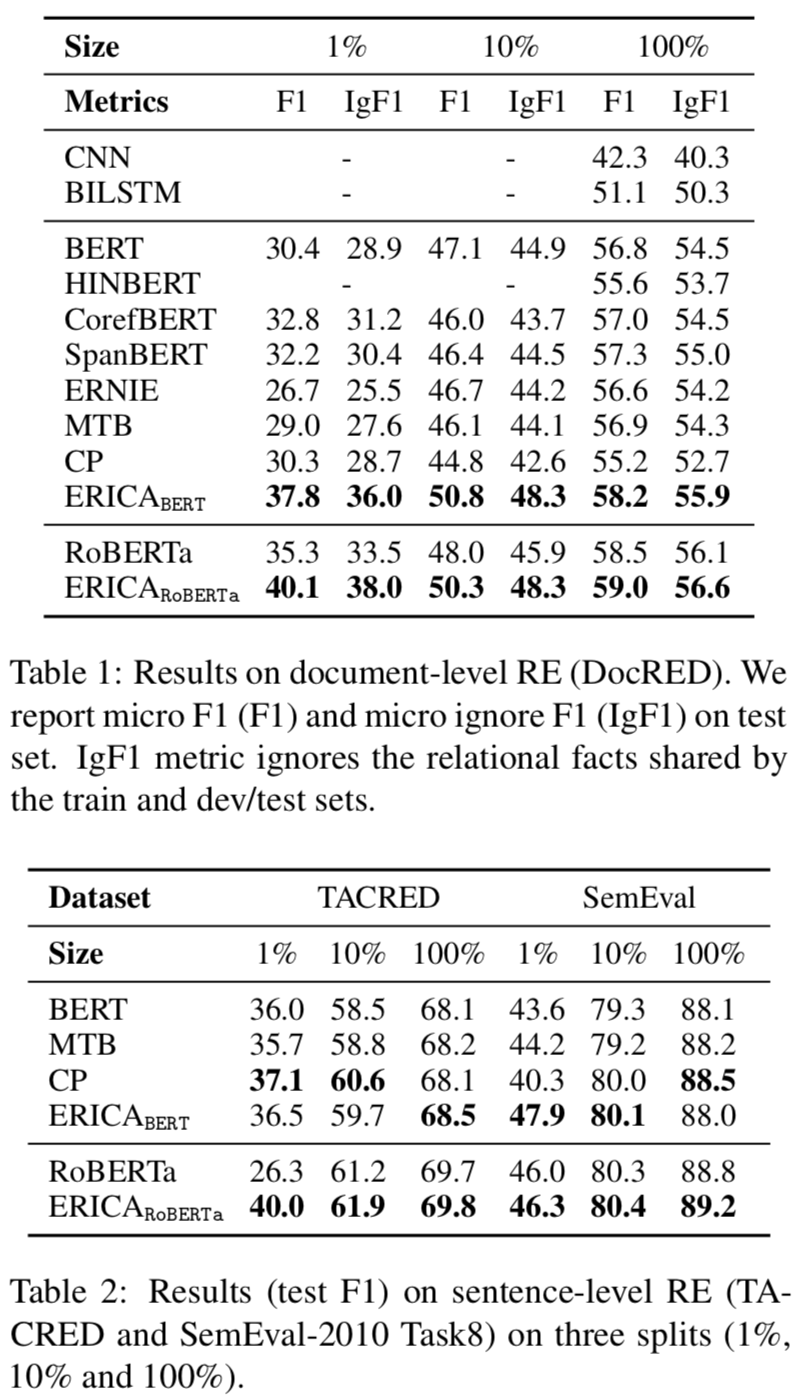
本文在BERT和RoBERTa都進行了增強訓練,遠程監督根據English Wikipedia和Wikidata構建,評估實驗在關系抽取、實體分類和問題回答任務上進行的,實驗結果分別如下:
Relation Extraction
Entity Typing
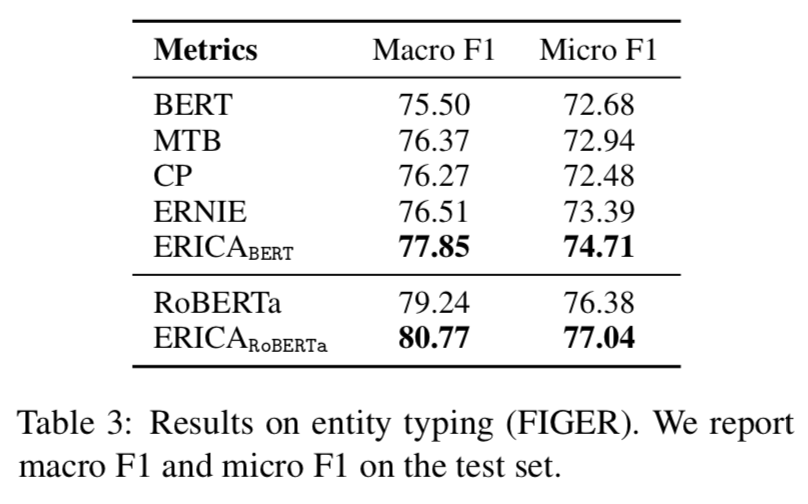
Question Answering
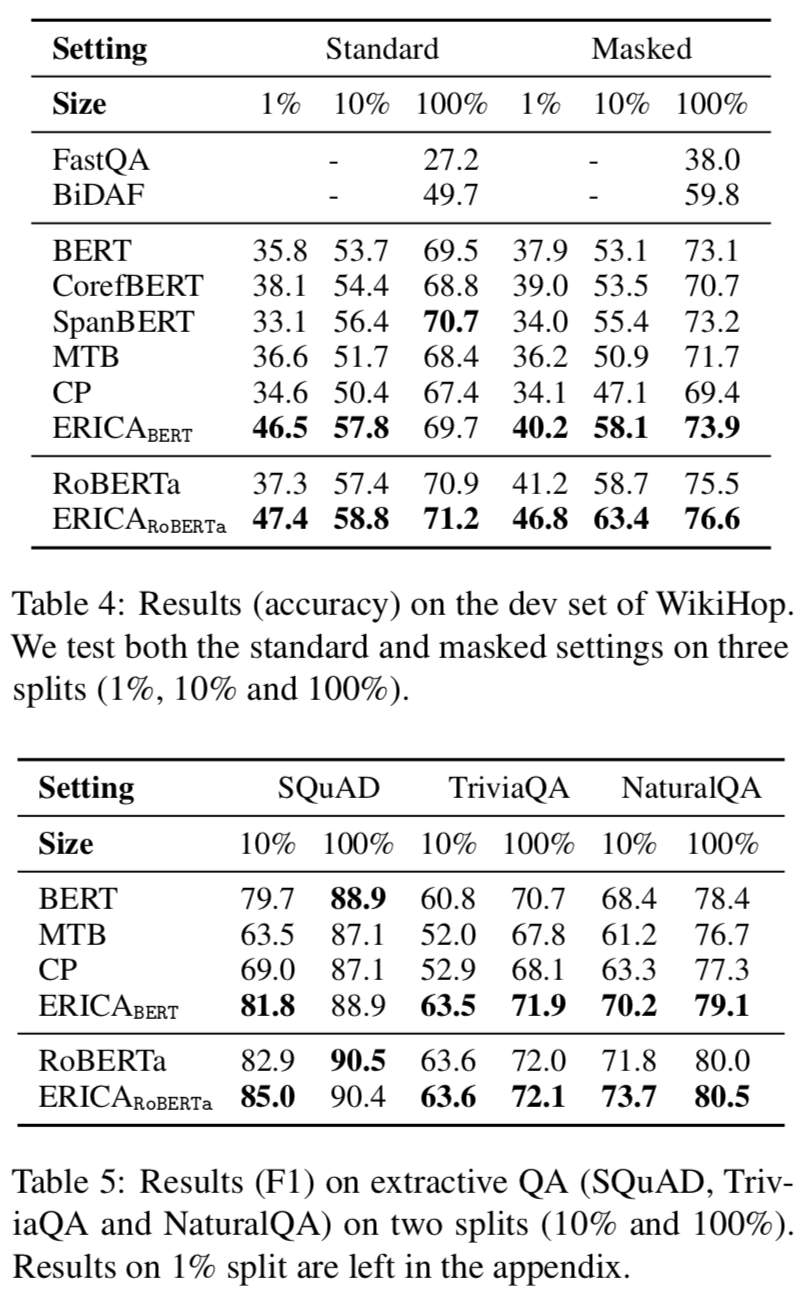
可以看出ERICA模型在不同任務不同數據集合上都有一定的提升。
總結
本次分享我們介紹了三篇知識增強的預訓練語言模型文章,分別圍繞知識向量、知識檢索以及知識監督的方法來向語言模型中注入知識。第一篇通過一個知識聚合器將KG中的實體和關系向量顯式注入語言模型;第二篇通過將知識圖譜轉換為自然文本,為檢索型語言模型擴充檢索知識語料庫,從而將結構化知識無縫地注入到語言模型中;第三篇基于知識監督的方式來建模文本中的關系事實從而增強預訓練語言模型。
原文標題:從最新的ACL、NAACL和EMNLP中詳解知識增強的語言預訓練模型
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
語言模型
+關注
關注
0文章
560瀏覽量
10696
原文標題:從最新的ACL、NAACL和EMNLP中詳解知識增強的語言預訓練模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【大語言模型:原理與工程實踐】大語言模型的預訓練
檢索增強型語言表征模型預訓練

Multilingual多語言預訓練語言模型的套路
一種基于亂序語言模型的預訓練模型-PERT
CogBERT:腦認知指導的預訓練語言模型
預訓練數據大小對于預訓練模型的影響
基于預訓練模型和語言增強的零樣本視覺學習

基于醫學知識增強的基礎模型預訓練方法





 工商網監
工商網監
評論