") CogBERT:腦認(rèn)知指導(dǎo)的預(yù)訓(xùn)練語(yǔ)言模型
CogBERT:腦認(rèn)知指導(dǎo)的預(yù)訓(xùn)練語(yǔ)言模型
介紹
本文研究了利用認(rèn)知語(yǔ)言處理信號(hào)(如眼球追蹤或 EEG 數(shù)據(jù))指導(dǎo) BERT 等預(yù)訓(xùn)練模型的問題。現(xiàn)有的方法通常利用認(rèn)知數(shù)據(jù)對(duì)預(yù)訓(xùn)練模型進(jìn)行微調(diào),忽略了文本和認(rèn)知信號(hào)之間的語(yǔ)義差距。為了填補(bǔ)這一空白,我們提出了 CogBERT 這個(gè)框架,它可以從認(rèn)知數(shù)據(jù)中誘導(dǎo)出細(xì)粒度的認(rèn)知特征,并通過自適應(yīng)調(diào)整不同 NLP 任務(wù)的認(rèn)知特征的權(quán)重將認(rèn)知特征納入 BERT。
實(shí)驗(yàn)結(jié)果表明:1)認(rèn)知指導(dǎo)下的預(yù)訓(xùn)練模型在 10 個(gè) NLP 任務(wù)上可以一致地比基線預(yù)訓(xùn)練模型表現(xiàn)更好;2)不同的認(rèn)知特征對(duì)不同的 NLP 任務(wù)有不同的貢獻(xiàn)。基于這一觀察,我們給出為什么認(rèn)知數(shù)據(jù)對(duì)自然語(yǔ)言理解有幫助的一個(gè)細(xì)化解釋;3)預(yù)訓(xùn)練模型的不同 transformer 層應(yīng)該編碼不同的認(rèn)知特征,詞匯級(jí)的認(rèn)知特征在 transformer 層底部,語(yǔ)義級(jí)的認(rèn)知特征在 transformer 層頂部;4)注意力可視化證明了 CogBERT 可以與人類的凝視模式保持一致,并提高其自然語(yǔ)言理解能力。

▲ 圖1. 人類眼球動(dòng)作捕捉數(shù)據(jù)示意圖
背景與簡(jiǎn)介
隨著預(yù)訓(xùn)練模型的出現(xiàn),當(dāng)代人工智能模型在諸多任務(wù)上得到了超越人類的表現(xiàn)。隨著預(yù)訓(xùn)練模型取得越來(lái)越好的結(jié)果,但是研究人員對(duì)于預(yù)訓(xùn)練模型卻并沒有知道更多。
另一方面,從語(yǔ)言處理的角度來(lái)看,認(rèn)知神經(jīng)科學(xué)研究人類大腦中語(yǔ)言處理的生物和認(rèn)知過程。研究人員專門設(shè)計(jì)了預(yù)訓(xùn)練的模型來(lái)捕捉大腦如何表示語(yǔ)言的意義。之前的工作主要是通過明確微調(diào)預(yù)訓(xùn)練的模型來(lái)預(yù)測(cè)語(yǔ)言誘導(dǎo)的大腦記錄,從而納入認(rèn)知信號(hào)。 然而,前人基于認(rèn)知的預(yù)訓(xùn)練模型的工作,其思路無(wú)法對(duì)認(rèn)知數(shù)據(jù)為何對(duì) NLP 有幫助進(jìn)行精細(xì)的分析和解釋。而這對(duì)于指導(dǎo)未來(lái)的認(rèn)知啟發(fā)式 NLP 研究,即應(yīng)該從認(rèn)知數(shù)據(jù)中誘導(dǎo)出什么樣的認(rèn)知特征,以及這些認(rèn)知特征如何對(duì) NLP 任務(wù)做出貢獻(xiàn),具有重要意義,否則這只是相當(dāng)于往預(yù)訓(xùn)練模型加入更多的數(shù)據(jù),而對(duì)認(rèn)知數(shù)據(jù)如何幫助預(yù)訓(xùn)練模型任然知之甚少。 例如,圖 1 顯示了以英語(yǔ)為母語(yǔ)的人的眼球追蹤數(shù)據(jù),其中圖 1(a) 說(shuō)明了人類正常閱讀時(shí)的關(guān)注次數(shù)。圖 2(b) 和 (c) 分別顯示了在 NLP 任務(wù)中的情感分類(SC)和命名實(shí)體識(shí)別(NER)的關(guān)注次數(shù)。我們可以看到,對(duì)于同一個(gè)句子,在不同的 NLP 任務(wù)下,人類的注意力是不同的。特別是,對(duì)于情感分類任務(wù),人們更關(guān)注情感詞,如``terrible'和``chaos'。而對(duì)于 NER 任務(wù),人們傾向于關(guān)注命名的實(shí)體詞,如``ISIS'和``Syria'。但是先前的研究不能通過簡(jiǎn)單地在認(rèn)知數(shù)據(jù)上微調(diào)預(yù)先訓(xùn)練好的模型來(lái)給出這種細(xì)粒度的分析。 為了促進(jìn)這一點(diǎn),我們提出了 CogBERT,一個(gè)認(rèn)知指導(dǎo)的預(yù)訓(xùn)練模型。具體來(lái)說(shuō),我們專注于使用眼球追蹤數(shù)據(jù)的效果,該數(shù)據(jù)通過追蹤眼球運(yùn)動(dòng)和測(cè)量固定時(shí)間來(lái)提供母語(yǔ)者的凝視信息。我們沒有直接在認(rèn)知數(shù)據(jù)上對(duì) BERT 進(jìn)行微調(diào),而是首先根據(jù)認(rèn)知理論提取心理語(yǔ)言學(xué)特征。
然后,我們?cè)谘蹌?dòng)數(shù)據(jù)中過濾掉統(tǒng)計(jì)學(xué)上不重要的特征(這意味著具有這些特征的單詞的人類注意力并不明顯高于/低于單詞的平均注意力)。隨后,我們通過在不同的 NLP 任務(wù)上進(jìn)行微調(diào),將這些經(jīng)過認(rèn)知驗(yàn)證的特征納入 BERT。在微調(diào)過程中,我們將根據(jù)不同的 NLP 任務(wù),為每一類特征學(xué)習(xí)不同的權(quán)重。
方法
本文的方法主要基于一個(gè)二階段的過程,其中一個(gè)階段被用來(lái)產(chǎn)生基于認(rèn)知的特征模板,第二個(gè)階段在于將這些認(rèn)知啟發(fā)的特征模板通過特殊設(shè)定的架構(gòu)融入預(yù)訓(xùn)練模型當(dāng)中。3.1 方法心理語(yǔ)言學(xué)研究表明 [1],人類閱讀能力的獲得體現(xiàn)在兩個(gè)方面。底層線索 (ower strands) 和高層線索 (upper strands)。底層線索(包括語(yǔ)音學(xué)、形態(tài)學(xué)等)隨著閱讀者的重復(fù)和練習(xí)而變得準(zhǔn)確和自動(dòng)。同時(shí),高層線索(包括語(yǔ)言結(jié)構(gòu)、語(yǔ)義等)相互促進(jìn),并與底層線索交織在一起,形成一個(gè)熟練的讀者。即意味著,人類本質(zhì)上的語(yǔ)言習(xí)得能力,其中一個(gè)重要的關(guān)鍵是對(duì)文本中的一系列特征進(jìn)行越來(lái)越熟練的提取和識(shí)別。 這意味著,人類的眼球動(dòng)作行為一定程度上可以被語(yǔ)言特征所反應(yīng),受以往工作的啟發(fā),我們構(gòu)建了一個(gè)初始的認(rèn)知特征集,包括使用 spaCy 工具 [2] 從文本中提取的 46 個(gè)細(xì)粒度的認(rèn)知特征,并將其分為下層特征(詞級(jí))和上層特征(語(yǔ)義/語(yǔ)法級(jí))。我們對(duì)這 46 種語(yǔ)言特征進(jìn)行了廣泛的統(tǒng)計(jì)顯著性分析,找到了其中 14 個(gè)對(duì)于人類眼球動(dòng)作有顯著影響的特征,并根據(jù)特征特點(diǎn),將其分為了上層特征和下層特征,展示在下表 1 當(dāng)中。
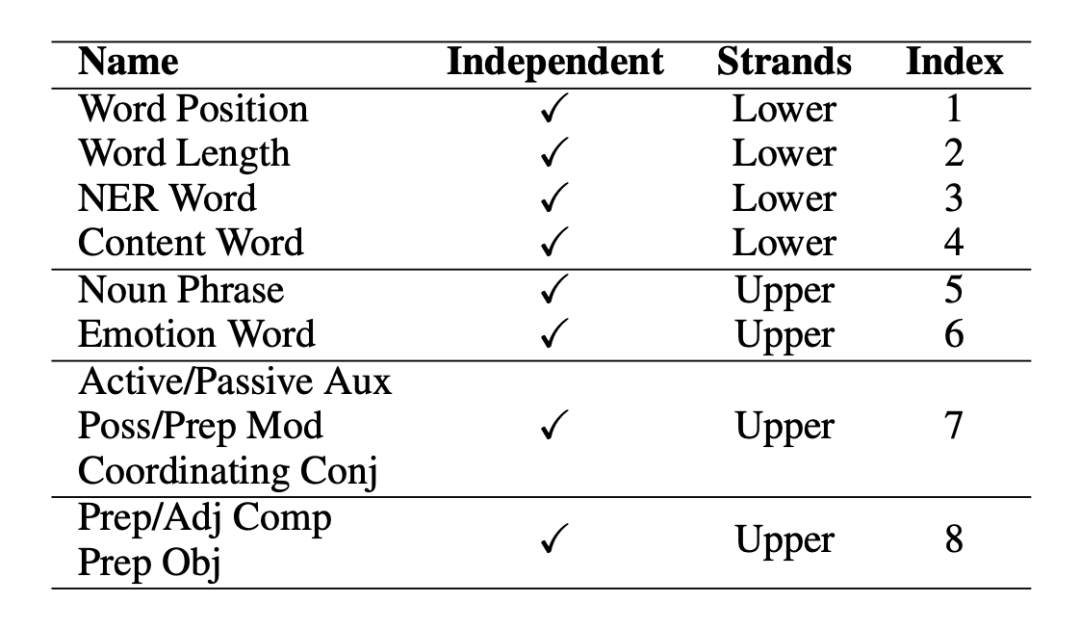
▲表1. 特征層級(jí)分類圖
3.2加權(quán)認(rèn)知特征向量學(xué)習(xí)
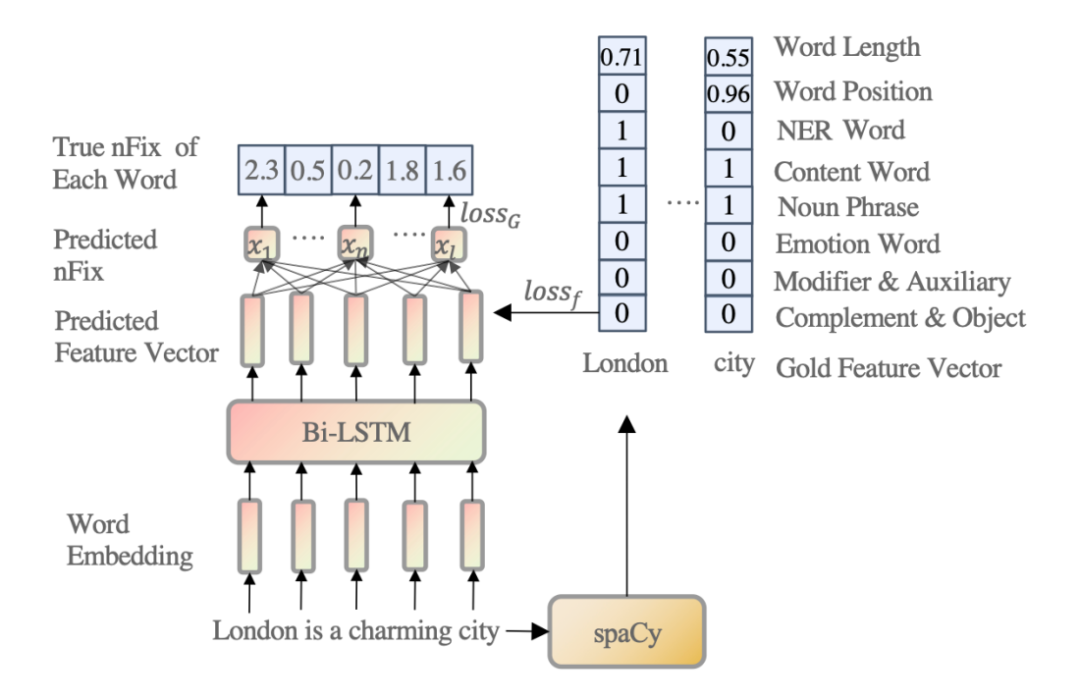
▲圖2. 加權(quán)認(rèn)知特征向量學(xué)習(xí)模型
我們可以通過使用 spaCy 工具從文本中提取特征。然而,這些特征不應(yīng)該被賦予相同或隨機(jī)的權(quán)重,因?yàn)樗鼈儗?duì)適應(yīng)人類對(duì)句子的理解的貢獻(xiàn)是不同的。因此,如圖 2 所示,給定一個(gè)輸入句子,我們訓(xùn)練一個(gè)四層的 Bi-LSTM [3],將每個(gè)單詞嵌入到一個(gè)加權(quán)的八維認(rèn)知特征向量。根據(jù)前述的心里語(yǔ)言學(xué)理論,我們認(rèn)為認(rèn)知特征可以解釋人類眼動(dòng)信息的分配。因此,我們使用眼球追蹤數(shù)據(jù)(Zuco 1.0、Zuco 2.0 和 Geco)[4,5,6] 的眼球動(dòng)作信息中的關(guān)注次數(shù) (nFix) 作為監(jiān)督信號(hào)來(lái)訓(xùn)練 Bi-LSTM 模型。
這部分的目的在實(shí)踐上實(shí)現(xiàn)前述所提到的理論,即人類的閱讀行為可以被特征解釋,同樣的,在模型層面上即意味著,模型要學(xué)會(huì)去利用語(yǔ)言特征的組合去逼近人類的閱讀行為。但是在本模型中,所需要的本不是最后對(duì)于眼球動(dòng)作數(shù)據(jù)的逼近,而是需要其中通過眼球動(dòng)作數(shù)據(jù)學(xué)來(lái)的特征向量。3.3 特征向量融入預(yù)訓(xùn)練語(yǔ)言模型
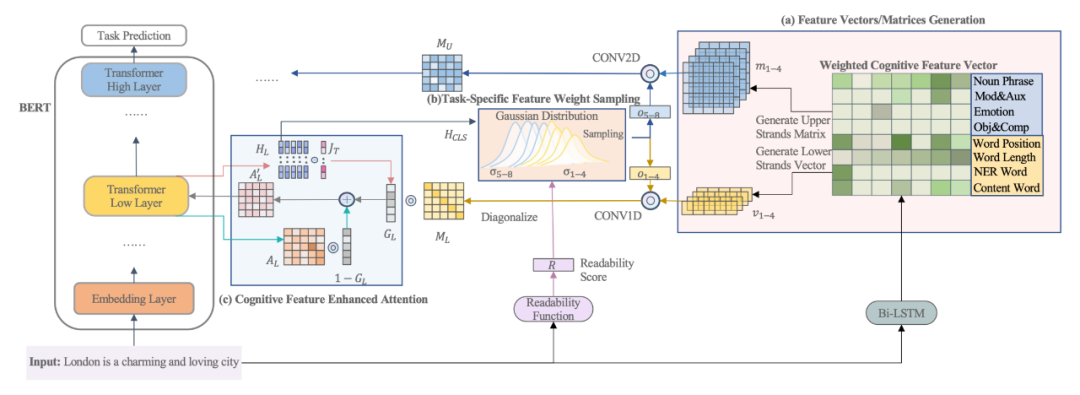
▲圖3. 特征向量融入預(yù)訓(xùn)練語(yǔ)言模型
如圖 3(a) 所示,對(duì)于每個(gè)有單詞的輸入句子,我們可以從 Bi-LSTM 模型中獲得其對(duì)應(yīng)的特征矩陣。對(duì)于每個(gè)底層特征(即詞長(zhǎng)、詞位、NER 和內(nèi)容詞),我們可以從 Bi-LSTM 模型中為其生成一個(gè)初始特征向量,隨后這些特征向量將會(huì)被對(duì)角化放在一個(gè)矩陣的對(duì)角線上。
對(duì)于每個(gè)上層特征(即 NP chunk、情感詞、Mod&Aux 和 Obj&Comp),我們可以從 Bi-LSTM 模型中分別為其生成一個(gè)初始的特征矩陣。如果相鄰的詞組成了一個(gè)上層特征,它在特征矩陣中的值是由 Bi-LSTM 模型得到的相鄰詞的平均特征得分,而其余數(shù)值都填為 0。同時(shí)對(duì)于每一個(gè)特征,會(huì)有一個(gè)經(jīng)由高斯采樣出的權(quán)重每個(gè)特征進(jìn)行放縮,用來(lái)提來(lái)該特征在該條數(shù)據(jù)或者任務(wù)當(dāng)中的重要性。
經(jīng)由上述過程生成的特征矩陣經(jīng)過放縮后分別被卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行處理用于提取特征形成基于特征的注意力矩陣,同時(shí)為了保留原始的模型注意力信息和特征的注意力矩陣,本文添加了一個(gè)門控向量,該向量會(huì)分別與模型原本的注意力矩陣和特征注意力矩陣進(jìn)行相乘并求和,求得一個(gè)原注意力矩陣和當(dāng)前注意力矩陣的線性加權(quán)。
同時(shí)可以注意到,本模型當(dāng)中,底層特征將會(huì)融入在預(yù)訓(xùn)練模型的底層,而高層特征則會(huì)融入在預(yù)訓(xùn)練模型的高層。
實(shí)驗(yàn)及分析4.1數(shù)據(jù)集
本文在多個(gè)數(shù)據(jù)集上進(jìn)行了大量的實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果包括了 GLUE Benchmark [7], CoNLL2000 Chunking [8] 以及 Eye-tracking [9] 和模型本身的一些分析。
4.2基線方法
1. BERT 不進(jìn)行遷移,直接在目標(biāo)領(lǐng)域上進(jìn)行預(yù)測(cè)。RoBERTa 微調(diào)源領(lǐng)域模型的全部參數(shù)進(jìn)行領(lǐng)域適應(yīng);
2. fMRI-EEG-BERT 一種認(rèn)知數(shù)據(jù)增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型,利用了核磁共振與腦電磁場(chǎng)數(shù)據(jù);
3. Eye-tracking BERT 一種認(rèn)知數(shù)據(jù)增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型,利用了眼球動(dòng)作捕捉進(jìn)行微調(diào)后再在下游任務(wù)上微調(diào);
4. CogBERT (Random) 本論文所提出的模型,但是特征分?jǐn)?shù)并未經(jīng)由一階段進(jìn)行生成,而是隨機(jī)生成的。
4.3 實(shí)驗(yàn)結(jié)果與分析
如表 2 所示,本文所提出的模型能夠在所有任務(wù)上超越模型的原本基線,同時(shí)超越大多數(shù)的認(rèn)知增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型,并能夠在大多數(shù)任務(wù)上達(dá)到或者超越經(jīng)由語(yǔ)法增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型,體現(xiàn)了本文所提出模型的有效性。
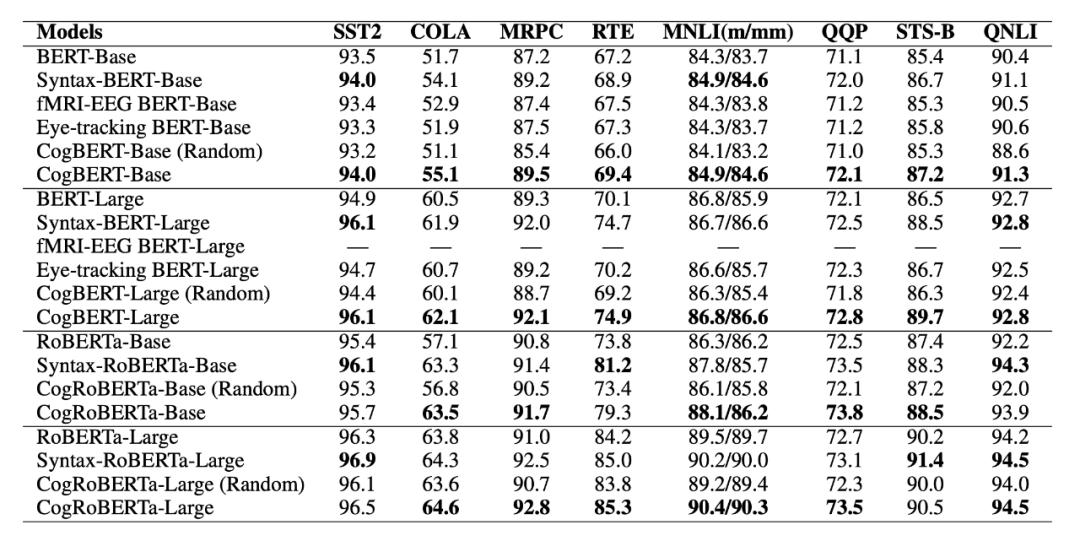
▲表2. GLUE Benchmark實(shí)驗(yàn)結(jié)果
在 CoNLL 2000 Chunking 的數(shù)據(jù)集上,本文提出的模型可以超越 BERT 基線模型,同時(shí)本文提出的模型還可以超越先前專門用于序列標(biāo)注而設(shè)計(jì)的模型。體現(xiàn)了認(rèn)知增強(qiáng)的模型可以被用在廣泛的自然語(yǔ)言處理任務(wù)上。
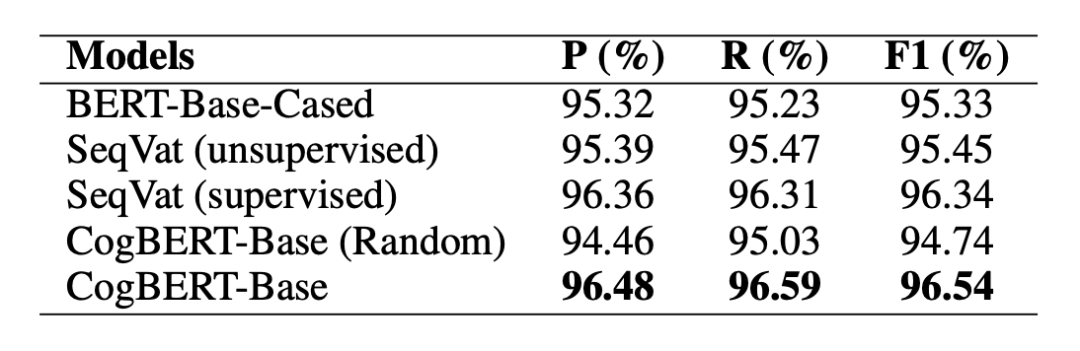
▲表3. CoNLL2000 Chunking實(shí)驗(yàn)結(jié)果 同時(shí),本文也在認(rèn)知相關(guān)任務(wù)上進(jìn)行了測(cè)試。在眼動(dòng)數(shù)據(jù)預(yù)測(cè)的任務(wù)當(dāng)中,本文所提出的模型可以在英語(yǔ)和荷蘭語(yǔ)的數(shù)據(jù)上超越相應(yīng)的基線模型。同時(shí)由于本文模型是基于 BERT 單語(yǔ)言版本,實(shí)驗(yàn)證明我們的模型也能夠超越 BERT 多語(yǔ)言版本,同時(shí)能夠超越 XLM-17 這一在 17 種語(yǔ)言上預(yù)訓(xùn)練的模型,最終能以僅單語(yǔ)言的模型版本達(dá)到可比或者超越 XLM-100 這一在 100 種語(yǔ)言上預(yù)訓(xùn)練的模型。證明了融入認(rèn)知數(shù)據(jù)對(duì)于認(rèn)知任務(wù)具有強(qiáng)力的增益。
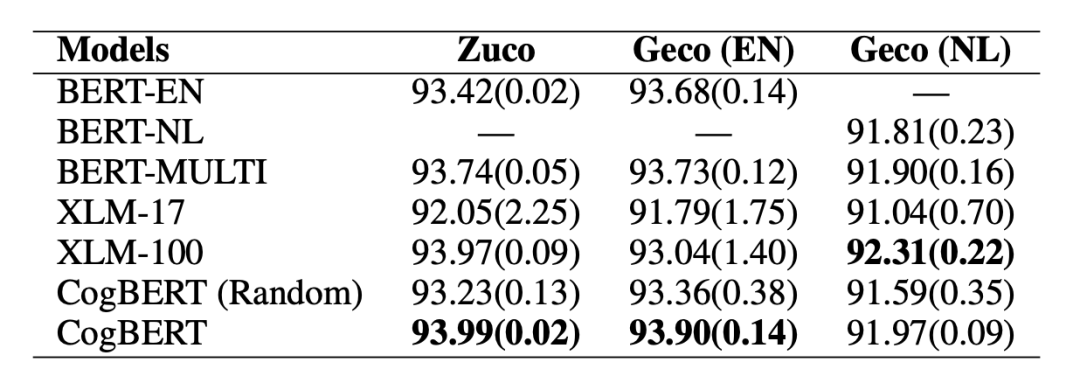
▲表4. Eye-tracking Prediction實(shí)驗(yàn)結(jié)果
在對(duì)于模型本身的分析方面,首先展示在模型學(xué)習(xí)中不同任務(wù)里,不同特征所得到的權(quán)重。在 COLA(語(yǔ)法可接受性)上,本文的模型對(duì)語(yǔ)法相關(guān)特征給出了高權(quán)值。在 MRPC(轉(zhuǎn)述句識(shí)別)上,模型認(rèn)為命名實(shí)體是最為重要的特征,即可能如果兩個(gè)句子并不在描述同一個(gè)實(shí)體,那么兩個(gè)句子大概率不是轉(zhuǎn)述句。在 RTE(文本蘊(yùn)含)中,模型認(rèn)為名詞短語(yǔ)是最為重要的特征,這可能意味著如果兩個(gè)句子具有類似的名詞短語(yǔ)結(jié)構(gòu),那么兩個(gè)句子具有較大的概率是蘊(yùn)含關(guān)系。在 CoNLL 2000 Chunking 和 CoNLL 2003 NER 任務(wù)當(dāng)中,模型可以很直觀的給出名詞短語(yǔ)和實(shí)體詞為最重要特征,符合了任務(wù)的設(shè)計(jì)。

▲表5. 特征權(quán)重分析實(shí)驗(yàn)結(jié)果
我們觀察到,替換下層或上層的認(rèn)知特征會(huì)降低模型的性能,而去除所有層的認(rèn)知特征會(huì)進(jìn)一步影響模型的性能。我們還注意到,盡管可讀性對(duì)于我們的模型來(lái)說(shuō)沒有認(rèn)知特征那么重要,但去除它也會(huì)損害模型的性能。不分層的融入特征意味著我們將所有的特征整合到 BERT 的每一層,不分層的糟糕表現(xiàn)表明,以分層的方式整合特征是認(rèn)知引導(dǎo)的 NLP 的一個(gè)有效方法。
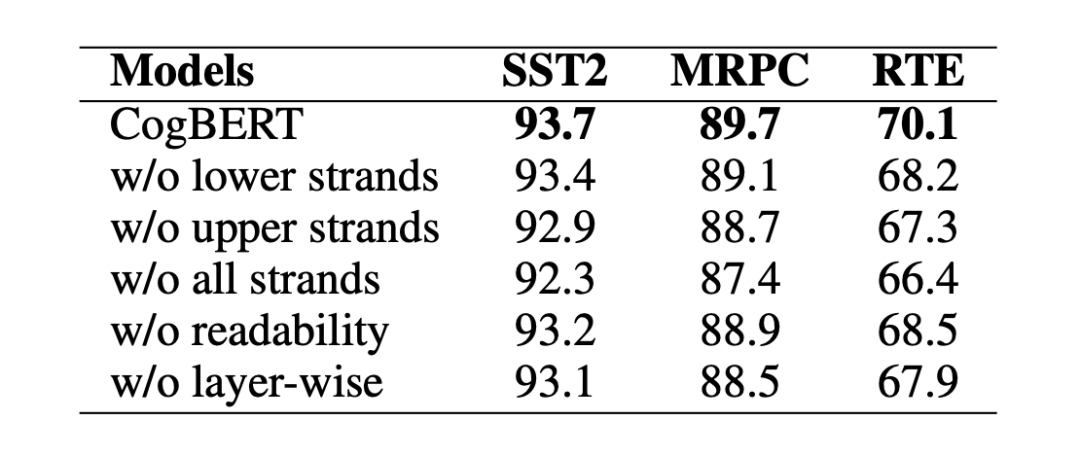
▲表6. 消融實(shí)驗(yàn)結(jié)果
在本文中,由于下層特征融入到預(yù)訓(xùn)練模型的底層,而上層特征融入到高層當(dāng)中,因此有必要去尋找合適的分層邊界。本文量化地討論了 BERT 的哪一層應(yīng)該是下層和上層認(rèn)知特征的邊界,并對(duì) SST2、MRPC、QNLI 和 STS-B 任務(wù)的開發(fā)集進(jìn)行了比較實(shí)驗(yàn),并在圖中說(shuō)明了結(jié)果。Y 軸是不同 NLP 任務(wù)的性能。X 軸是層數(shù)。例如,如果層數(shù)為 6,我們將下層的認(rèn)知特征納入 BERT 的 1-6 層,將上層的認(rèn)知特征納入其余層。
研究發(fā)現(xiàn),當(dāng)層數(shù)邊界在 4 左右時(shí),所有任務(wù)都達(dá)到了最佳性能,這意味著 BERT 的低層更適合納入下層認(rèn)知特征,而當(dāng)我們將上層認(rèn)知特征納入更高的層數(shù)時(shí),它們更有用。這些結(jié)果可以有效地指導(dǎo)未來(lái)認(rèn)知強(qiáng)化預(yù)訓(xùn)練模型的研究,同時(shí)也進(jìn)一步驗(yàn)證了前人關(guān)于預(yù)訓(xùn)練模型的相關(guān)研究 [10]。
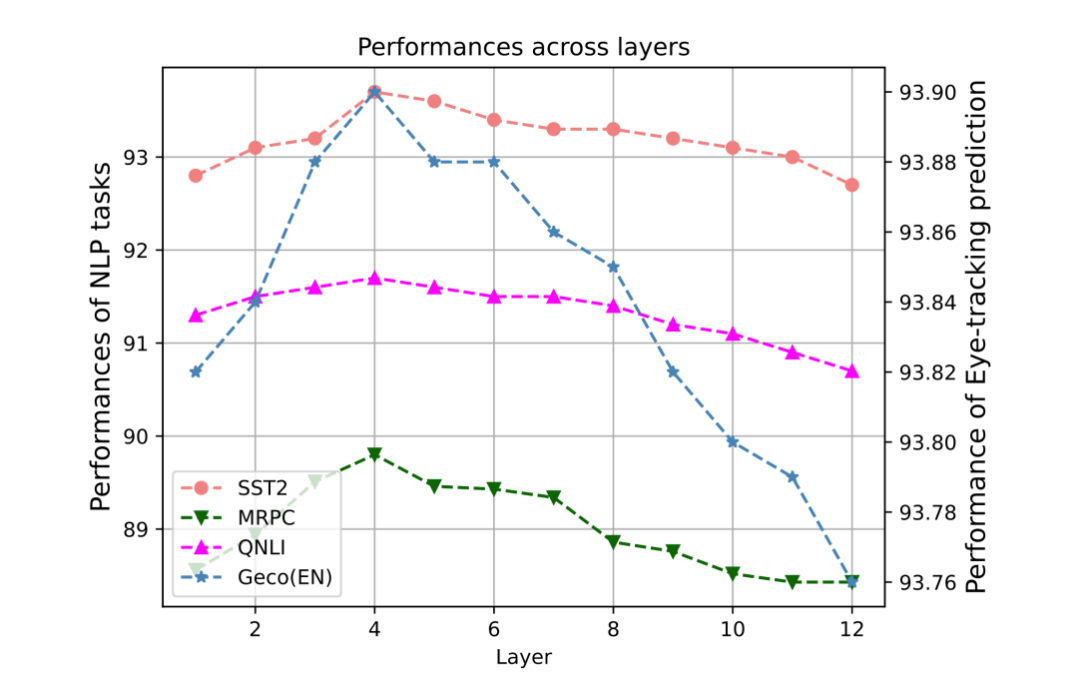
▲圖4. 任務(wù)表現(xiàn)與特征層數(shù)分析圖
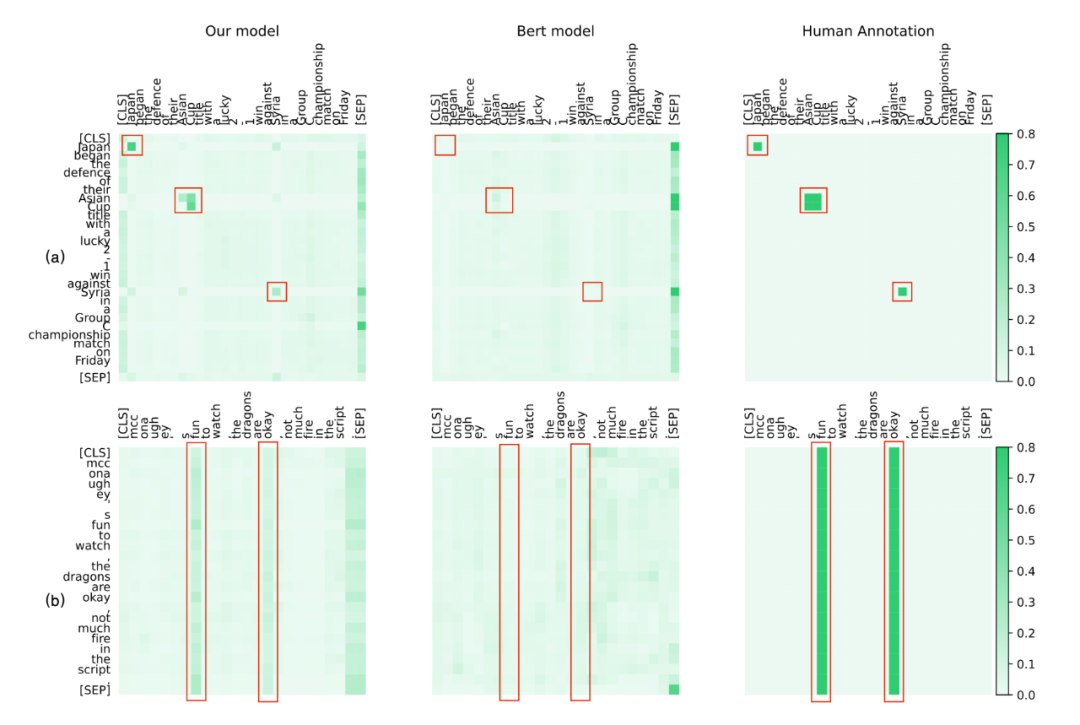
為了定性地分析我們方法的有效性,我們將 CogBERT 的注意力可視化,并與 BERT 和人類進(jìn)行比較。我們從 SST2、NER 和 MRPC 任務(wù)中選擇案例。為了與人類的認(rèn)知進(jìn)行比較,給定一個(gè)特定的 NLP 任務(wù),我們要求四個(gè)注釋者在閱讀句子時(shí)突出他們的注意詞。對(duì)于 BERT 和 CogBERT,我們從預(yù)訓(xùn)練模型的較高層次中選擇注意力得分,這可以捕捉到任務(wù)的特定特征。SST2 和 NER 的注意力可視化圖。
圖 (a) 展示了 CoNLL-2003 NER 任務(wù)的注意力可視化,說(shuō)明 CogBERT 像人類一樣對(duì) NER 詞 "Asian Cup"、"Japan"和 "Syria"給予了更多的關(guān)注,而 BERT 對(duì)這些詞的關(guān)注很少。圖 (b) 說(shuō)明了 SST2 任務(wù)的注意力可視化,顯示 CogBERT 捕獲了關(guān)鍵的情感詞`fun'和`okay',而這兩個(gè)詞從人類的判別行為來(lái)說(shuō)對(duì)人類的判斷也很重要。
相比之下,BERT 未能關(guān)注這些詞。這些實(shí)驗(yàn)結(jié)果表明,盡管預(yù)訓(xùn)練模型在眾多 NLP 任務(wù)中取得了可喜的改進(jìn),但它們離人類智能的水平還很遠(yuǎn)。通過學(xué)習(xí)人類閱讀中的注意力機(jī)制,認(rèn)知引導(dǎo)的預(yù)訓(xùn)練模型可以提供一種接近人類認(rèn)知的有效方法。
▲圖5. 注意力可視化
結(jié)論
我們提出了 CogBERT,一個(gè)能夠有效地將認(rèn)知信號(hào)納入預(yù)訓(xùn)練模型的框架。實(shí)驗(yàn)結(jié)果表明,CogBERT 在多個(gè) NLP 基準(zhǔn)數(shù)據(jù)集上取得了超越基線的結(jié)果,同時(shí)模型表明證明對(duì)認(rèn)知任務(wù)同樣有用。分析表明,CogBERT 可以自適應(yīng)地學(xué)習(xí)特定任務(wù)的認(rèn)知特征權(quán)重,從而對(duì)認(rèn)知數(shù)據(jù)在 NLP 任務(wù)中的工作方式做出精細(xì)的解釋。這項(xiàng)工作為學(xué)習(xí)認(rèn)知增強(qiáng)的預(yù)訓(xùn)練模型提供了一個(gè)新的方法,廣泛闡述的實(shí)驗(yàn)可以指導(dǎo)未來(lái)的研究。
審核編輯 :李倩 ·
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
560瀏覽量
10696 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25305
原文標(biāo)題:COLING'22 | CogBERT:腦認(rèn)知指導(dǎo)的預(yù)訓(xùn)練語(yǔ)言模型
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

從Open Model Zoo下載的FastSeg大型公共預(yù)訓(xùn)練模型,無(wú)法導(dǎo)入名稱是怎么回事?
小白學(xué)大模型:訓(xùn)練大語(yǔ)言模型的深度指南

用PaddleNLP在4060單卡上實(shí)踐大模型預(yù)訓(xùn)練技術(shù)

騰訊公布大語(yǔ)言模型訓(xùn)練新專利
KerasHub統(tǒng)一、全面的預(yù)訓(xùn)練模型庫(kù)
大語(yǔ)言模型開發(fā)框架是什么
什么是大模型、大模型是怎么訓(xùn)練出來(lái)的及大模型作用

寫給小白的大模型入門科普
從零開始訓(xùn)練一個(gè)大語(yǔ)言模型需要投資多少錢?

直播預(yù)約 |數(shù)據(jù)智能系列講座第4期:預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論