 用PaddleNLP在4060單卡上實踐大模型預訓練技術
用PaddleNLP在4060單卡上實踐大模型預訓練技術
作者:算力魔方創始人/英特爾創新大使劉力
之前我們分享了《從零開始訓練一個大語言模型需要投資多少錢》,其中高昂的預訓練費用讓許多對大模型預訓練技術感興趣的朋友望而卻步。
應廣大讀者的需求,本文將手把手教您如何在單張消費級顯卡上,利用PaddleNLP實踐OpenAI的GPT-2模型的預訓練。GPT-2的預訓練關鍵技術與流程與GPT-4等大參數模型如出一轍,通過親手實踐GPT-2的預訓練過程,您就能對GPT-4的預訓練技術有更深入的了解。
視頻鏈接如下:
[零基礎]:用PaddleNLP在4060單卡上實踐大模型預訓練技術 (qq.com)
一,GPT-2模型簡介
GPT-2(Generative Pre-trained Transformer 2)是由OpenAI在2019年發布的第二代生成式預訓練語言模型,通過無監督學習的方式進行預訓練,能夠在多個自然語言處理任務上取得顯著的效果,如文本生成、閱讀理解、機器翻譯等。
GPT-2 奠定的技術基礎為 GPT-3、GPT-4 的發展提供了方向,后續版本在此基礎上不斷改進和創新。
GPT-2有4個參數版本:124M、355M、774M和1.5B。為方便大家使用單卡實踐預訓練技術,本文選用124M版本。
二,PaddleNLP簡介
PaddleNLP是一款基于飛槳的開源大語言模型(LLM)開發套件,支持在多種硬件上進行高效的大模型訓練、無損壓縮以及高性能推理。PaddleNLP具備簡單易用和性能極致的特點,致力于助力開發者實現高效的大模型產業級應用。
代碼倉:https://github.com/PaddlePaddle/PaddleNLP

三,預訓練環境準備
本文的軟硬件環境如下:
操作系統:Ubuntu 24.04 LTS
GPU:NVIDIA RTX-4060
代碼編輯器:VS Code
Python虛擬環境管理器:Anaconda
大語言模型訓練工具:PaddleNLP
大語言模型:GPT-2
在Ubuntu 24.04上安裝RTX-4060驅動和Anaconda請參見這里;若您習慣在Windows上從事日常工作,請先配置《在Windows用遠程桌面訪問Ubuntu 24.04.1 LTS》。
四,安裝PaddleNLP
首先,請用Anaconda創建虛擬環境“gpt2”:
# 創建名為my_paddlenlp的環境,指定Python版本為3.9或3.10 conda create -n gpt2 python=3.10 # 激活環境 conda activate gpt2
然后,克隆PaddleNLP代碼倉到本地,切換到“develop”分支后安裝PaddleNLP。
# 克隆PaddleNLP代碼倉到本地 git clone https://github.com/PaddlePaddle/PaddleNLP.git cd PaddleNLP # 切換到”develop”分支 git checkout develop # 安裝飛槳框架 pip install paddlepaddle-gpu # 安裝PaddleNLP pip setup.py install
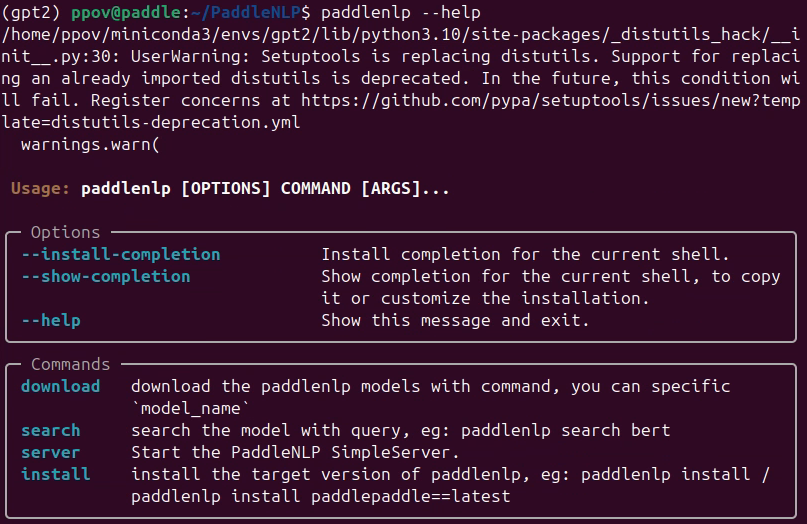
輸入命令:“paddlenlp --help”,出現下圖,說明PaddleNLP安裝成功!
五,下載預訓練數據集
為了方便讀者運行快速體驗預訓練過程,PaddleNLP提供了處理好的100K條openweb數據集的訓練樣本。該訓練數據集雖然不夠預訓練的數據量要求(模型參數量的十倍以上),但足夠讓讀者觀察到啟動預訓練后,隨機初始化權重的GPT-2模型的Loss值從11.x左右下降到5.x左右。
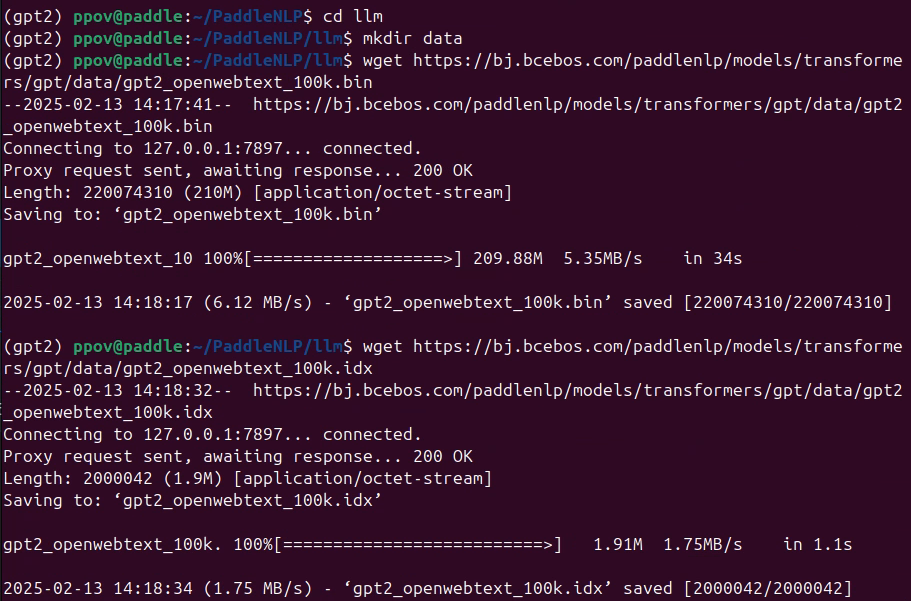
用命令將100K條openweb數據集的訓練樣本下載到PaddleNLP/llm/data文件夾:???????
cd PaddleNLP/llm mkdir data wget https://bj.bcebos.com/paddlenlp/models/transformers/gpt/data/gpt2_openwebtext_100k.bin wget https://bj.bcebos.com/paddlenlp/models/transformers/gpt/data/gpt2_openwebtext_100k.idx mv gpt2_openwebtext_100k.bin ./data mv gpt2_openwebtext_100k.idx ./data
六,下載GPT-2模型和分詞器到本地
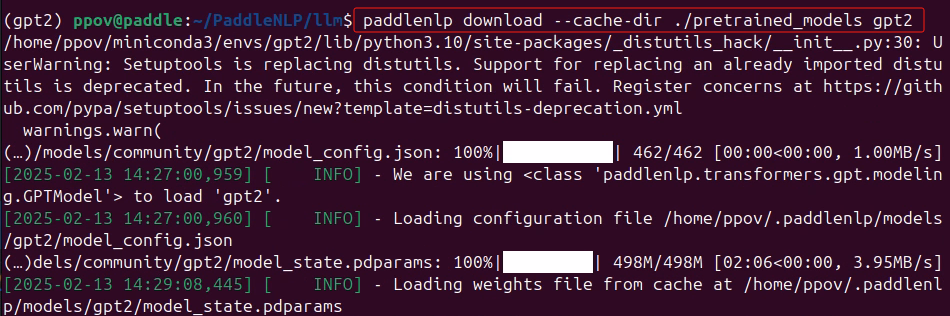
在/llm路徑下,輸入命令下載GPT-2模型和分詞器到本地:
paddlenlp download --cache-dir ./pretrained_models gpt2
然后,打開llm/config/gpt3/pretrain_argument.json文件,按照下圖修改:
"model_name_or_path": "./pretrained_models/gpt2"
"tokenizer_name_or_path": "./pretrained_models/gpt2"
七,啟動GPT-2模型的預訓練
在/llm路徑下,輸入命令:???????
python -u -m paddle.distributed.launch --gpus "0" run_pretrain.py
./config/gpt-3/pretrain_argument.json
--use_flash_attention False
--continue_training 0
訓練結果如下圖所示:
八,總結
使用PaddleNLP,可以在單張4060顯卡上實踐OpenAI的GPT-2模型的預訓練,讓自己對GPT-4的預訓練技術有更深入的了解!
更多大模型訓練技術,
請參看:https://paddlenlp.readthedocs.io/
如果你有更好的文章,歡迎投稿!
稿件接收郵箱:nami.liu@pasuntech.com
更多精彩內容請關注“算力魔方?”!
審核編輯 黃宇
-
數據集
+關注
關注
4文章
1223瀏覽量
25321 -
大模型
+關注
關注
2文章
3062瀏覽量
3908 -
LLM
+關注
關注
1文章
322瀏覽量
727
發布評論請先 登錄
【大語言模型:原理與工程實踐】核心技術綜述
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的預訓練
為什么要使用預訓練模型?8種優秀預訓練模型大盤點

Multilingual多語言預訓練語言模型的套路
如何更高效地使用預訓練語言模型
利用視覺語言模型對檢測器進行預訓練
預訓練數據大小對于預訓練模型的影響
預訓練模型的基本原理和應用
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集






 工商網監
工商網監
評論