 預訓練數據大小對于預訓練模型的影響
預訓練數據大小對于預訓練模型的影響
引言:
NLP領域的研究目前由像RoBERTa等經過數十億個字符的語料經過預訓練的模型匯主導。那么對于一個預訓練模型,對于不同量級下的預訓練數據能夠提取到的知識和能力有何不同?是否可以在更少量數據上實現相似的能力與知識。本文基于不同量級預訓練數據的RoBERTa模型分析了在分類探知(Classififier Probe)、信息論探查(info-theoretic probing)、無監督相對可接受性判斷(unsupervised relative acceptability judgment,)和自然語言理解任務上的微調(Fine-tuning on NLU Tasks)等任務上的表現,用于衡量模型在語言能力上的差異。
背景介紹:
Probe
BERT類模型的工作模式簡單,但取得的效果也是極佳的,其在各項任務上的良好表現主要得益于其在大量無監督文本上學習到的文本表征能力。那么如何從語言學的特征角度來衡量一個預訓練模型的究竟學習到了什么樣的語言學文本知識呢?Probe就是為了測試模型在語言學特征角度上的各種能力而設計的任務。以下為本文涉及到的兩種Probe方式:
Edge Probing
Edge Probing(以下簡稱 E-Probe)簡單來說,就是對于一個已經預訓練好的預訓練模型,E-Probe就是一個插入在中間層的淺層神經網絡,通常為一個分類器層。示意圖如下:
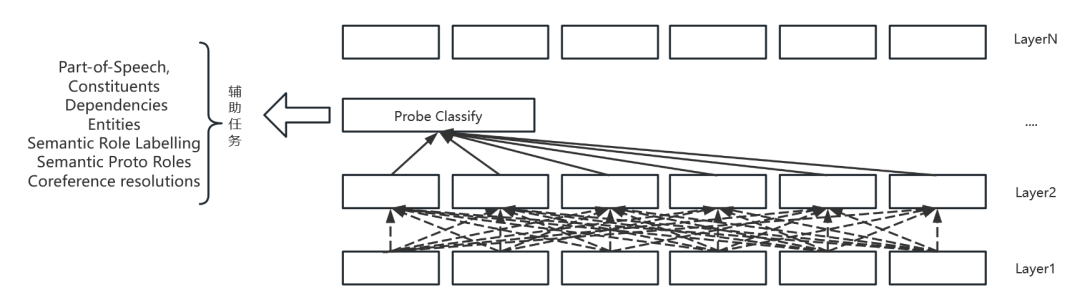
對于每一個輔助任務,分類器的輸入可能都不一樣。比如在實體標注輔助任務中,輸入可能為該層某個區間的輸出,對于詞性標注輔助任務,輸入即為該層中的單個輸出。在具體的輔助任務訓練中,原預訓練模型的參數是不參與更新的,只更新該分類頭的參數。同時由于各個層均可以用于輔助任務的訓練,因此使用到了一個可學習的權重向量來對于某個token在所有層對應的輸出向量來作為最終的表示。最終得到的這個權重也可以用于衡量該輔助任務所需要的信息各個層之間的占比情況。E-Probe提供了一種更為直觀的方式衡量模型對于語言學特征的表征能力。
Probing with MDL
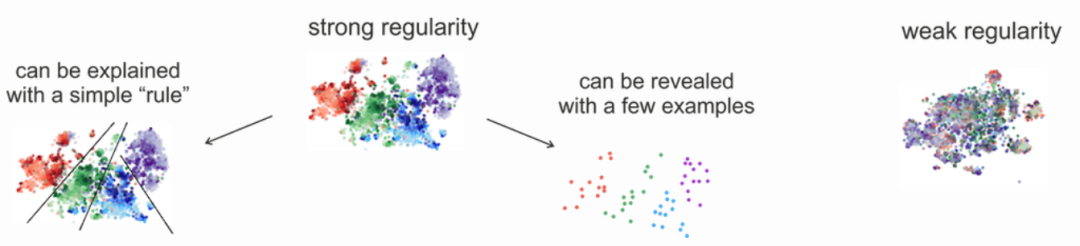
Probing with MDL(以下簡稱 M-Probe)。M-Probe主要就E-Probe中存在的各項問題進行了討論,并提出了基于了最小描述長度(minimum description length,MDL)的Probe方法。相較于E-Probe,M-Probe的方法就沒有那么直觀。M-Probe使用了數據編碼這一概念,替換了以往E-Probe中預測這一個行為。對應在模型上的改變即為將分類頭轉化為了一個概率模型,然后根據香農編碼,即可得到無損轉換編碼時的最小編碼長度。當下對于輔助任務上的表現不再是根據最終輔助任務上的Accuracy等指標來實現的,而是根據對于數據編碼后的編碼長度來進行比較實現的。本質原理為,對于輔助任務所需要的特征能夠更好表達的模型,具有對于數據分布上更好的規律分布,那么對于編碼來說則可以使用更短的編碼長度來實現對于數據的編碼。可以通過下圖釋義來表示:
接下來將會介紹關于本文使用到的M-Probe的線上編碼版本,E-Probe存在的一個問題就是只有在減少分類器訓練數據量時,他們才能看到指標的合理差異。即對于數據量上的差距也會導致最終效果的不同,因此采用了一個線上編碼版本的M-Probe。流程如下圖所示:
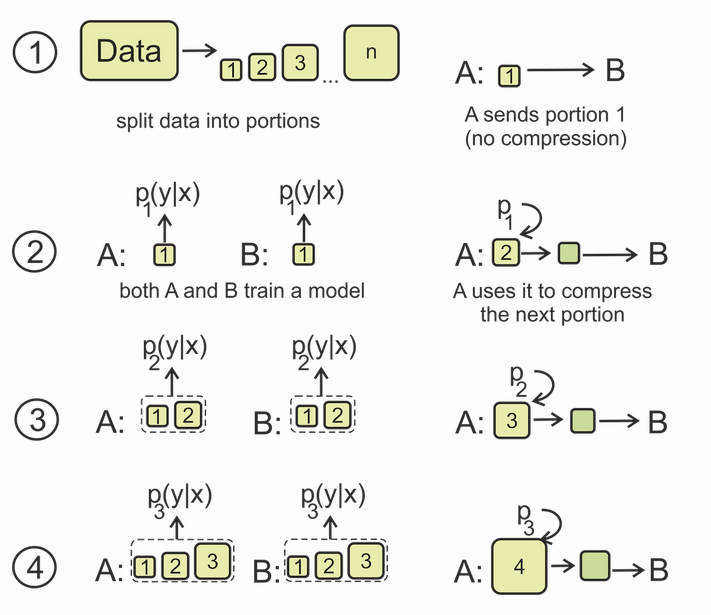
首先將數據分割為不同大小的部分,對于第一次兩個模型訓練的輸入均為未壓縮的版本,在后續的學習中B的標簽概率分布均為A模型編碼后的結果。最終直到整個數據集都被傳遞后,得到的編碼長度可以被下式衡量
上式的前半部分為數據中第一部分對于共K個類別進行編碼所需要的編碼長度,后面的部分為各個數據團根據香農編碼得到的對于數據進行編碼所需要的編碼長度。
綜上M-Probe實現了一個基于MDL的Probe方式,最終能夠通過編碼長度來衡量預訓練模型對于各個語言學特征的提取能力。
實驗設計
本文主要使用以上的對于模型表征能力測評的方法,對于分別在1M、10M、100M、1B和30B字符量的預訓練數據集上得到的RoBERTa模型進行測試。并對于結果進行了分析。
Classififier Probing
本實驗主要基于E-Probe的方法,分別對于詞性標注(Part-of-Speech),依存句法分析(Dependencies),成分句法分析(Constituents),關系抽取(Relations),語義角色標注(SRL對應下圖中的SRL、Sem. Proto Role 1 、Sem. Proto Role 2),共指消解(coreference resolution,對應下表中的OntoNotes coref. )命名實體識別(Entities)和常識推斷(Winograd coref.)等輔助任務進行了測評。結果如下:
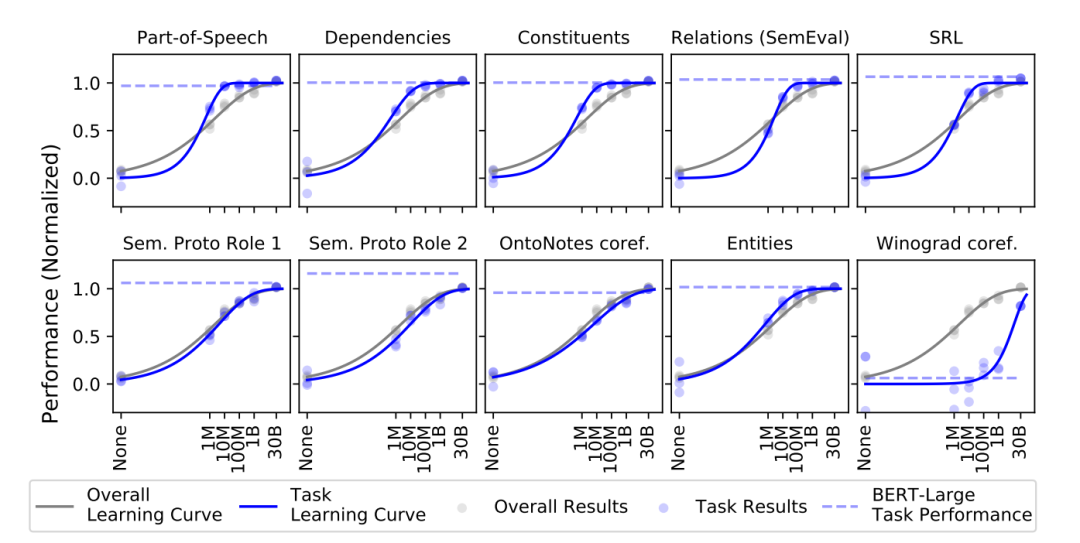
其中所有的數據結果均使用了Min-max歸一化,其中None對應的為隨機初始化的RoBERTa模型。并根據以上的結果進行了匯總,分別從句法、語義和常識推斷三個方面來具體衡量各個體量數據預訓練下的效果。
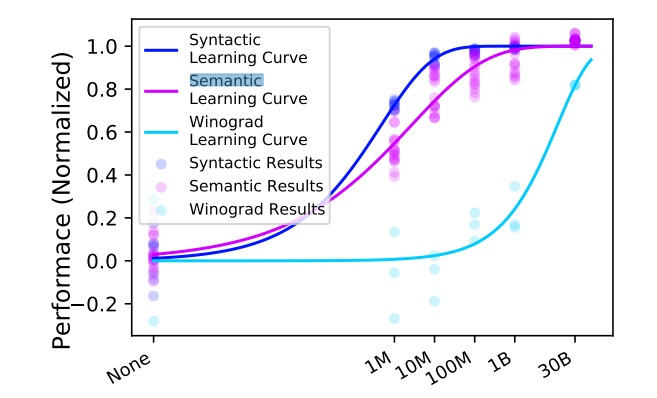
由以上的實驗可以得出結論:大多數的句法與語法特征的學習在1B以下的字符數量訓練集完成,大部分任務的表征能力在1M附近達到最快的學習速度,而其中較為不同的是知識推斷任務,本文認為是由于關于知識內容的學習需要更為龐大的訓練數據。同時,在100M量級上的RoBERTa模型的關于語義與句法表征能力已經非常接近30B量級下的模型了。
Minimum Description Length Probing
本實驗是基于M-Probe的方法,在同樣的數據集上進行的實驗。
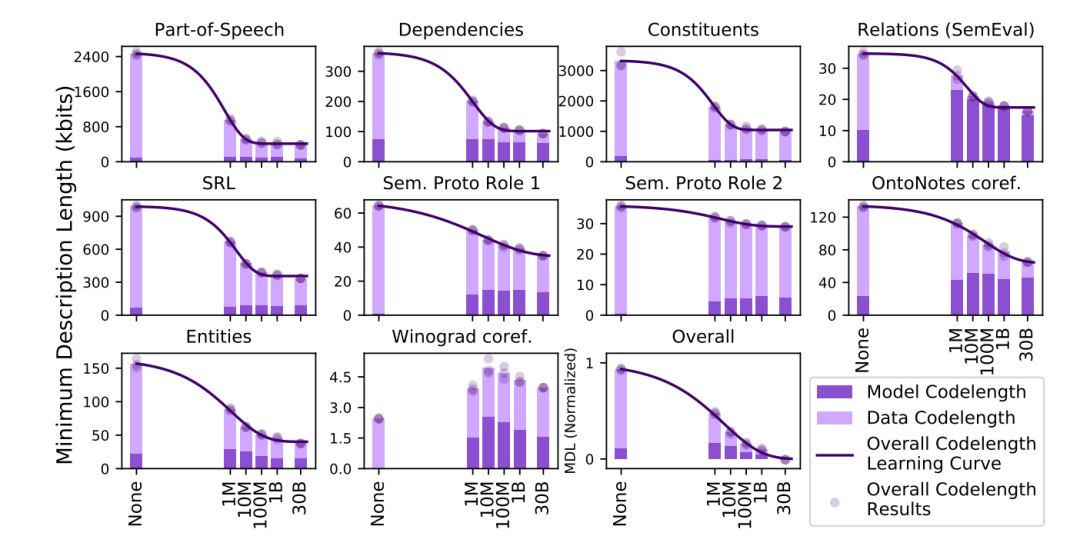
上圖中Winograd的效果差距可能是由于在實驗中基于M-Probe的方法沒辦法很好收斂。同樣的根據實驗結果,整體長度的下降也符合M-Probe的思想,包含更多知識的嵌入會使得任務具有更強的規律性更容易被編碼。在該試驗中,大部分的任務在100M上的效果也已經很接近30B的效果了。
Unsupervised Grammaticality Judgement
該任務主要是基于BLiMP基準集來測試模型,BLiMP主要包含了67個子數據集,每一種數據集中包含了1000個句子對,每個句子對之間的差距只有一個編輯距離,但這些句子在語法是否正確上缺失截然相反的,需要模型來識別。這67個子數據集分別對應了英語語法中的一種特定的表述、句法或者語義現象。對對于該任務,使用的方法為,使用MLM的方法,對于該不同位置上的字符對應在兩個不同詞上的概率來衡量整體模型對于該自然語言現象的理解能力。結果如下:
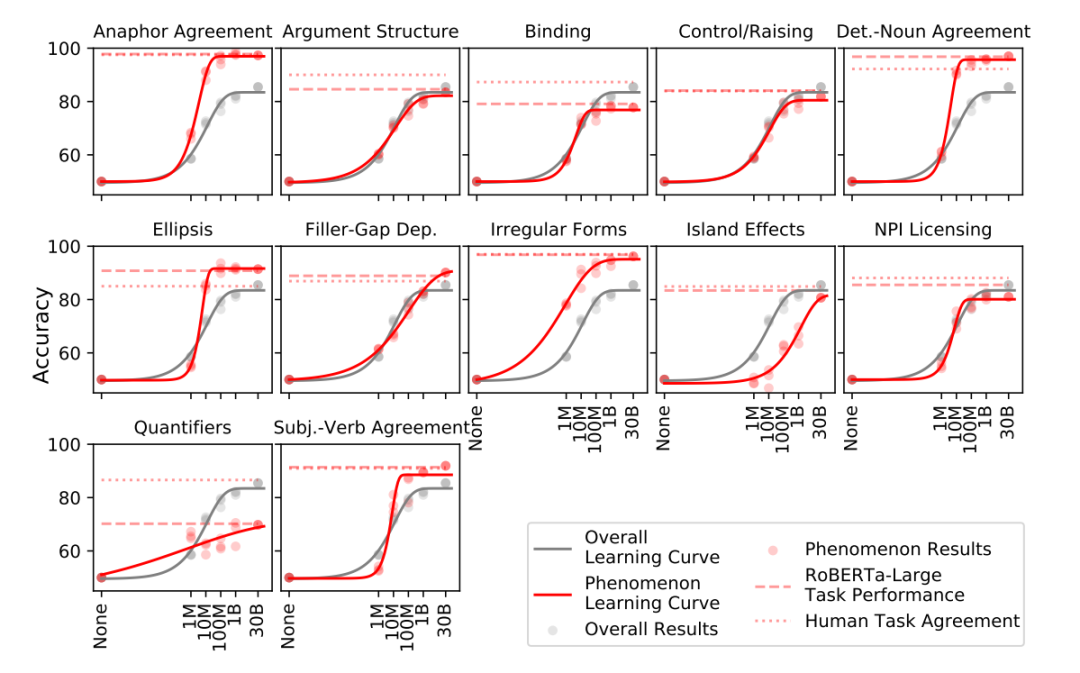
和上述兩個任務中表現的一致的是,模型基本上在1M與100M的量級間上的表現快速增長。對于大部分的句子對任務,100M量級下的模型基本上與人類表現只相差9個百分點,而額外的大量數據只能提高6個百分點,對于一些潛在的語法現象可能需要更大量級的數據。同時對于不同任務之間也進行比較,對于一些頻率高的現象往往在1M到10M就能達到一個很好的效果,而對于頻率較低的現象,往往需要更大量級的模型才能學習到很好的表征。
Unsupervised Language Model Knowledge Probe
本實驗主要基于LAMA數據集上的實驗表現,該數據集主要由五萬個完型填空句子得到,這些語句主要為針對于事實知識問題的填空問題。
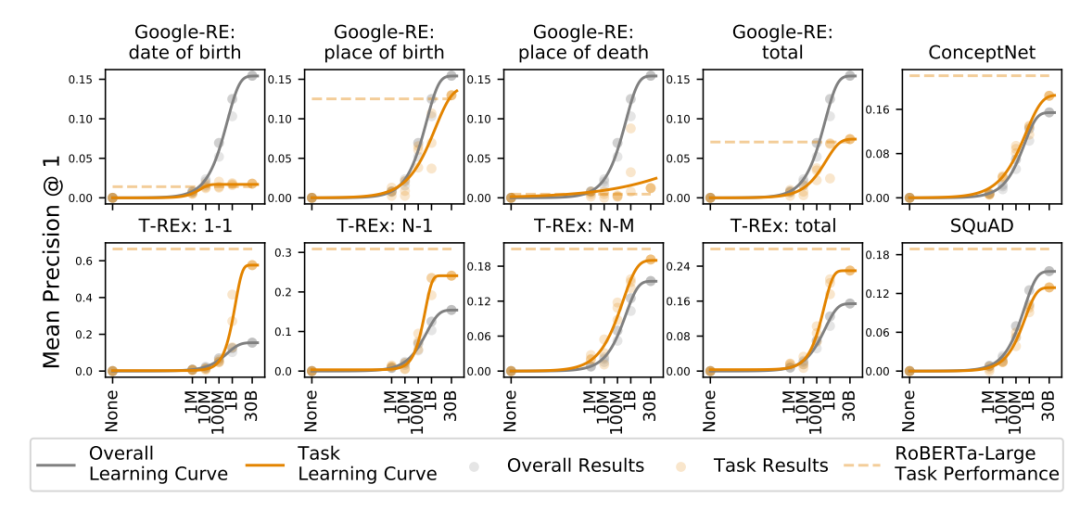
可以看到針對于事實知識性的測試實驗中,并沒有一個很好的可以總結的瓶頸規律。其中在ConceptNet任務中這一個概念性的填空中的表現可以很好的解釋Winograd coref.中1B到30B的大幅度提升。對于知識類別的表征與學習能力可能需要更多的數據或者預訓練任務來進行提升。
Fine-tuning on NLU Tasks
本實驗主要基于SuperGLUE這一分類基準數據集來測試在真正的下游任務上,不同量級模型的表現到底有什么區別。
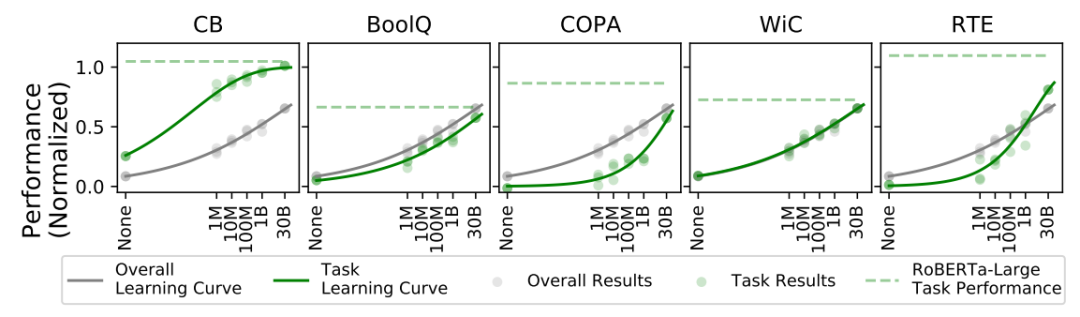
可以看到在下游NLU任務上,即是在30B的量級上也并沒有出現非常顯著的飽和現象,在一些關鍵的NLU任務上提供更多的預訓練數據可能會帶來更大的提升。
總結與討論
本文主要使用了基于Probe的方法來對模型在不同量級數據下的表征能力進行測試。得出了在10M到100M量級的數據中會達到對于語法和語義表征能力的飽和并和人類的能力想當,但對于事實類的知識需要更多的預訓練數據才能達到。對于下游的NLU任務,預訓練數據量的提升往往會帶來較好的性能提升,同時在目前的30B的情況下仍未達到飽和。
對于本文中NLU仍未達到飽和的原因,文中的解決方案是提供更多的預訓練數據這樣的方式,但這樣的方式往往是沒有目的性的,本文后續對于該點的討論也集中于無法將對應的語法或者語義性的表征能力與對應的NLU任務聯系上去,對于推動NLU任務的提升的是什么仍然是一個未解決的問題。但對于此現象,個人覺得可能和Unsupervised Grammaticality Judgement這一節中的類似,因為長尾效應的存在,通過堆疊大量的預訓練數據確實會引入更多的長尾效應中20%尾巴的部分,即能夠提高NLU任務中未被覆蓋到的部分,但這樣的方式確實低效的,那么是否能夠找到一個更高效針對NLU任務的方法從龐大的預訓練語料庫中找到這一和20%尾巴更相似的數據來構建新的預訓練語料庫呢?
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4808瀏覽量
102822 -
編碼
+關注
關注
6文章
967瀏覽量
55507 -
模型
+關注
關注
1文章
3488瀏覽量
50011
發布評論請先 登錄
基于不同量級預訓練數據的RoBERTa模型分析
【大語言模型:原理與工程實踐】大語言模型的預訓練
為什么要使用預訓練模型?8種優秀預訓練模型大盤點
小米在預訓練模型的探索與優化

2021 OPPO開發者大會:NLP預訓練大模型





 工商網監
工商網監
評論