 一種基于亂序語言模型的預訓練模型-PERT
一種基于亂序語言模型的預訓練模型-PERT
寫在前面
今天分享給大家一篇哈工大訊飛聯合實驗室的論文,一種基于亂序語言模型的預訓練模型-PERT,全名《PERT: PRE-TRAINING BERT WITH PERMUTED LANGUAGE MODEL》。該篇論文的核心是,將MLM語言模型的掩碼詞預測任務,替換成詞序預測任務,也就是在不引入掩碼標記[MASK]的情況下自監督地學習文本語義信息,隨機將一段文本的部分詞序打亂,然后預測被打亂詞語的原始位置。
PERT模型的Github以及對應的開源模型其實年前就出來了,只是論文沒有放出。今天一瞬間想起來去看一眼,這不,論文在3月14號的時候掛到了axirv上,今天分享給大家。
paper:https://arxiv.org/pdf/2203.06906.pdf
github:https://github.com/ymcui/PERT
介紹
預訓練語言模型(PLMs)目前在各種自然語言處理任務中均取得了優異的效果。預訓練語言模型主要分為自編碼和自回歸兩種。自編碼PLMs的預訓練任務通常是掩碼語言模型任務,即在預訓練階段,使用[MASK]標記替換原始輸入文本中的一些token,并在詞匯表中恢復這些被[MASK]的token。
常用預訓練語言模型總結:https://zhuanlan.zhihu.com/p/406512290
那么,自編碼PLMs只能使用掩碼語言模型任務作為預訓練任務嗎?我們發現一個有趣的現象“在一段文本中隨機打亂幾個字并不會影響我們對這一段文本的理解”,如下圖所示,乍一看,可能沒有注意到句子中存在一些亂序詞語,并且可以抓住句子的中心意思。該論文探究了是否可以通過打亂句子中的字詞來學習上下文的文本表征,并提出了一個新的預訓練任務,即亂序語言模型(PerLM)。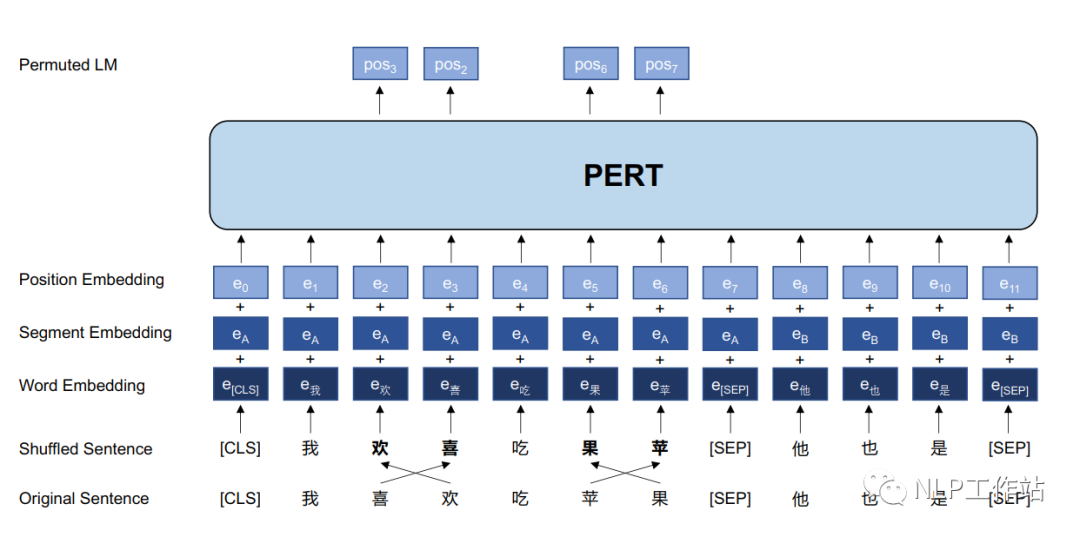
模型
PERT模型結構如上圖所示。PERT模型結構與BERT模型結構相同,僅在模型輸入以及預訓練目標上略有不同。
PERT模型的細節如下:
- 采用亂序語言模型作為預訓練任務,預測目標為原始字詞的位置;
- 預測空間大小取決于輸入序列長度,而不是整個詞表的大小(掩碼語言模型預測空間為詞表);
- 不采用NSP任務;
- 通過全詞屏蔽和N-gram屏蔽策略來選擇亂序的候選標記;
- 亂序的候選標記的概率為15%,并且真正打亂順序僅占90%,剩余10%保持不變。
由于亂序語言模型不使用[MASK]標記,減輕了預訓練任務與微調任務之間的gap,并由于預測空間大小為輸入序列長度,使得計算效率高于掩碼語言模型。PERT模型結構與BERT模型一致,因此在下游預訓練時,不需要修改原始BERT模型的任何代碼與腳本。注意,與預訓練階段不同,在微調階段使用正常的輸入序列,而不是打亂順序的序列。
中文實驗結果與分析
預訓練參數
- 數據:由中文維基百科、百科全書、社區問答、新聞文章等組成,共5.4B字,大約20G。
- 訓練參數:詞表大小為21128,最大序列長度為512,batch大小為416(base版模型)和128(large版模型),初始學習率為1e-4,使用 warmup動態調節學習率,總訓練步數為2M,采用ADAM優化器。
- 訓練設備:一臺TPU,128G。
機器閱讀理解MRC任務
在CMRC2018和DRCD兩個數據集上對機器閱讀理解任務進行評測,結果如下表所示。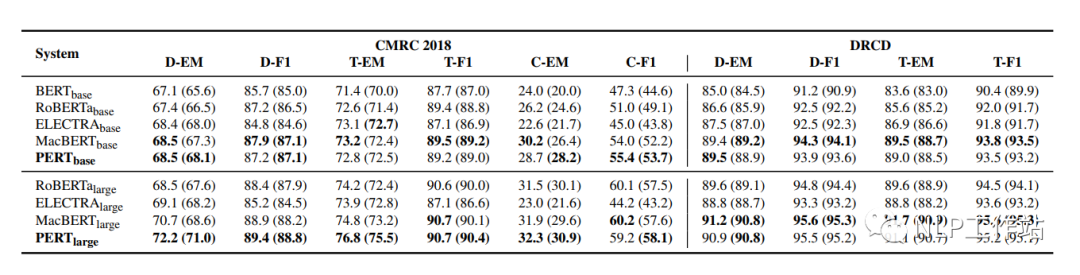
PERT模型相比于MacBERT模型有部分的提高,并且始終優于其他模型。
文本分類TC任務
在XNLI、LCQMC、BQ Corpus、ChnSentiCorp、TNEWS和OCNLI 6個數據集上對文本分類任務進行評測,結果如下表所示。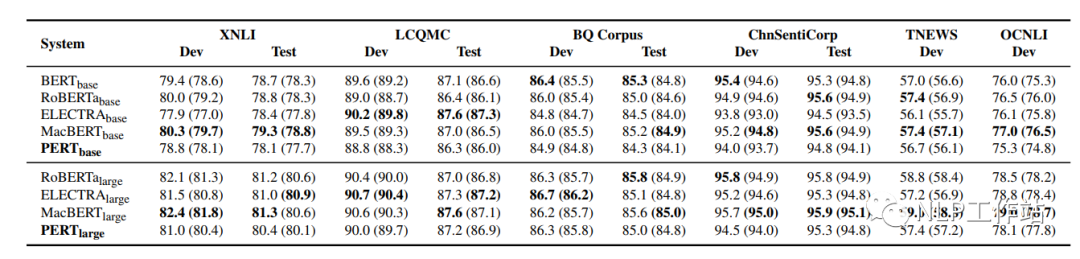
在文本分類任務上,PERT模型表現不佳。推測與MRC任務相比,預訓練中的亂序文本給理解短文本帶來了困難。
命名實體識別NER任務
在MSRA-NER和People’s Daily兩個數據集上對命名實體識別任務進行評測,結果如下表所示。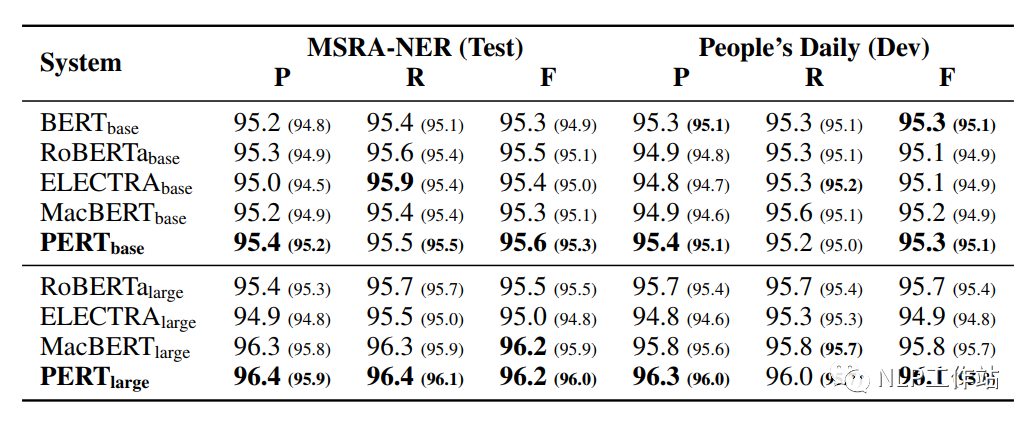
PERT模型相比于其他模型均取得最優的效果,表明預訓練中的亂序文在序列標記任務中的良好能力。
對比機器閱讀理解、文本分類和命名實體識別三個任務,可以發現,PERT模型在MRC和NER任務上表現較好,但在TC任務上表現不佳,這意味著TC任務對詞語順序更加敏感,由于TC任務的輸入文本相對較短,有些詞語順序的改變會給輸入文本帶來完全的意義變化。然而,MRC任務的輸入文本通常很長,幾個單詞的排列可能不會改變整個文章的敘述流程;并且對于NER任務,由于命名實體在整個輸入文本中只占很小的比例,因此詞語順序改變可能不會影響NER進程。
語法檢查任務
在Wikipedia、Formal Doc、Customs和Legal 4個數據集上對文本分類任務進行評測語法檢查任務進行評測,結果如下表所示。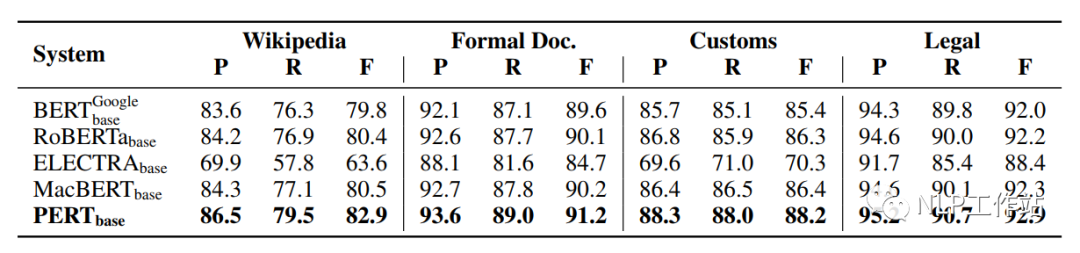
PERT模型相比于其他模型均取得最優的效果,這是由于下游任務與預訓練任務非常相似導致的。
預訓練的訓練步數對PERT模型的影響
不同的下游任務的最佳效果可能出現在不同的預訓練步驟上,如下圖所示。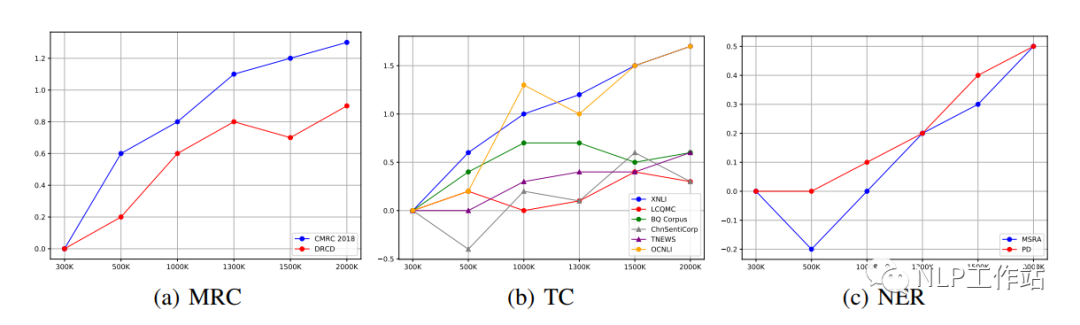
我們發現對于MRC和NER任務,隨著預訓練步數的增加,下游任務也會隨之提高。然而,對于TC任務,不同數據的指標在不同的步數上取得最優。如果考慮到特定任務的效果,有必要在早期訓練中保存部分模型。
不同的打亂粒度對PERT模型的影響
不同粒度間的打亂,可以使使輸入文本更具可讀性。通過在不同粒度內亂序輸入文本來比較性能,如下表所示。
我們發現,在各種打亂粒度中,無限制亂序的PERT模型在所有任務中都取得了最優的效果;而選擇最小粒度(詞語之間)的模型,效果最差。可能原因是,雖然使用更小的粒度的亂序可以使輸入文本更具可讀性,但是對預訓練任務的挑戰性較小,使模型不能學習到更好地語義信息。
不同預測空間對PERT模型的影響
將PERT模型使用詞表空間作為預測目標是否有效?如下表所示。
實驗結果表明,PERT模型不需要在詞表空間中進行預測,其表現明顯差于在輸入序列上的預測;并且將兩者結合的效果也不盡如人意。
預測部分序列和預測全部序列對PERT模型的影響
ELECTRA模型的實驗發現預測完全序列的效果比部分序列的更好,因此ELECTRA模型采用RTD任務對判別器采用完全序列預測。但通過本論文實驗發現,預測完全序列在PERT模型中并沒有產生更好的效果。表明在預訓練任務中使用預測全部序列并不總是有效的,需要根據所設計的預訓練任務進行調整。
總結
PERT模型的預訓練思路還是挺有意思的,并在MRC、NER和WOR任務上均取得了不錯的效果。并且由于結構與BERT模型一致,因此在下游任務使用時,僅修改預訓練模型加載路徑就實現了模型替換,也比較方便。當打比賽或者做業務時候,可以不妨試一試,說不定有奇效。(ps:我在我們自己的MRC數據集上做過實驗,效果不錯呦!!)
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
561瀏覽量
10710 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14058
原文標題:PERT:一種基于亂序語言模型的預訓練模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

小白學大模型:訓練大語言模型的深度指南

用PaddleNLP在4060單卡上實踐大模型預訓練技術








 工商網監
工商網監
評論