 小米在預訓練模型的探索與優化
小米在預訓練模型的探索與優化
導讀:預訓練模型在NLP大放異彩,并開啟了預訓練-微調的NLP范式時代。由于工業領域相關業務的復雜性,以及工業應用對推理性能的要求,大規模預訓練模型往往不能簡單直接地被應用于NLP業務中。本文將為大家帶來小米在預訓練模型的探索與優化。
01
預訓練簡介
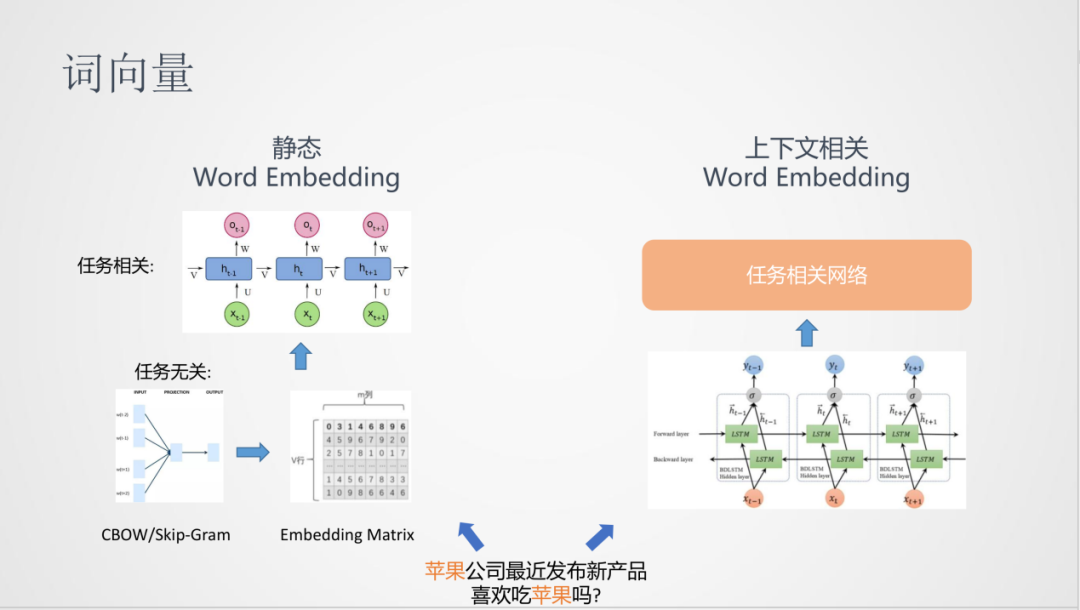
預訓練與詞向量的方法一脈相承。詞向量是從任務無關和大量的無監督語料中學習到詞的分布式表達,即文檔中詞的向量化表達。在得到詞向量之后,一般會輸入到下游任務中,進行后續的計算,從而得到任務相關的模型。
但是,詞向量的學習方法存在一個問題:不能對文檔中的上下文進行建模,對于上面的例子“蘋果”在兩個句子中的表達意思是不一樣的,而詞向量的表達卻是同一個,所以在表達能力的多樣性上會有局限,這是一種靜態的Word Embedding。
在后面的發展中,有了根據上下文建模的Word Embedding,比如,可以在學習上嘗試使用雙向LSTM模型,在非監督語料學習詞向量,這比靜態的詞向量網絡會復雜一些,最后可以通過隱層得到動態的詞向量輸入到下游任務中。
1. 序列建模方法
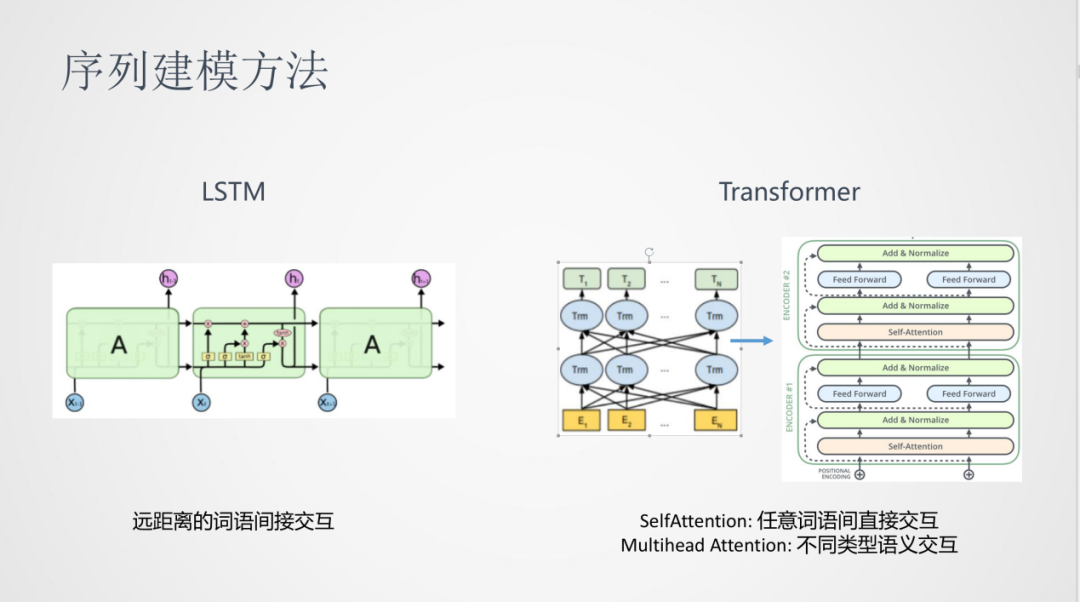
在NLP中,一般使用序列建模的方法。之前比較常用的序列建模是LSTM遞歸神經網絡,其問題是建模時,句子中兩個遠距離詞之間的交互是間接的。
17年Transformer發布之后,在NLP任務中取得了很大的提升。這里面Self-Attention可以對任意詞語間進行直接的交互,Multi-head Attention可以表達在不同類型的進行語義交互。
2. 預訓練模型
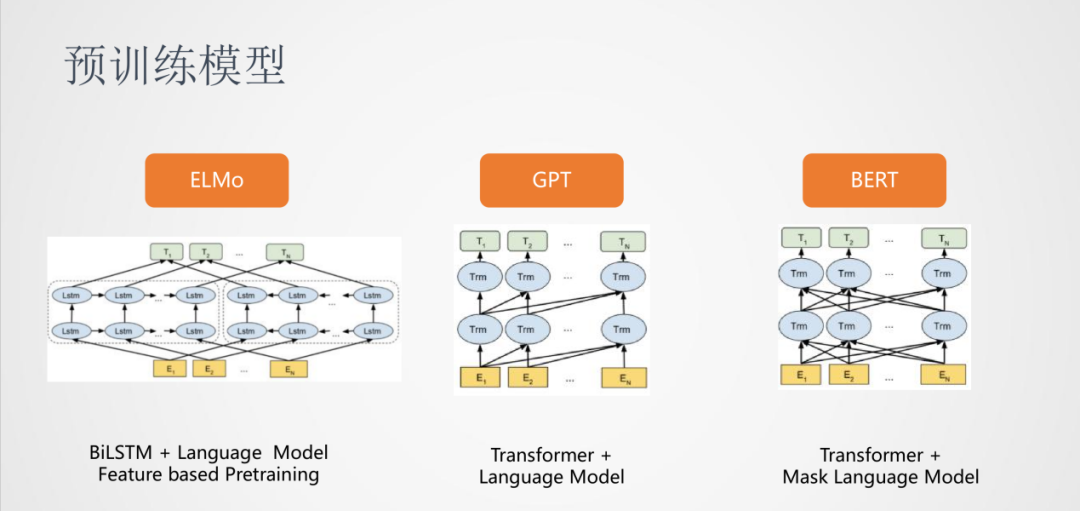
在這之后,預訓練模型開始流行起來。
首先是ELMO,依然使用的是雙向LSTM,它將模型做的更深,并且在大規模的無監督語料中進行訓練,使用的訓練任務是語言模型。對于具體的任務,將從ELMO得到的詞向量作為特征輸入到下游任務中,ELMO這種的預訓練屬于Feature based Pretraining。
其次是GPT,它使用的是Transformer結構,訓練任務是從左到右的語言模型,比較適合生成類的任務。
最后是BERT,依然使用的Transformer結構,訓練任務換成了Mask Language Model,可以對詞語的上下文進行建模。
3. BERT模型
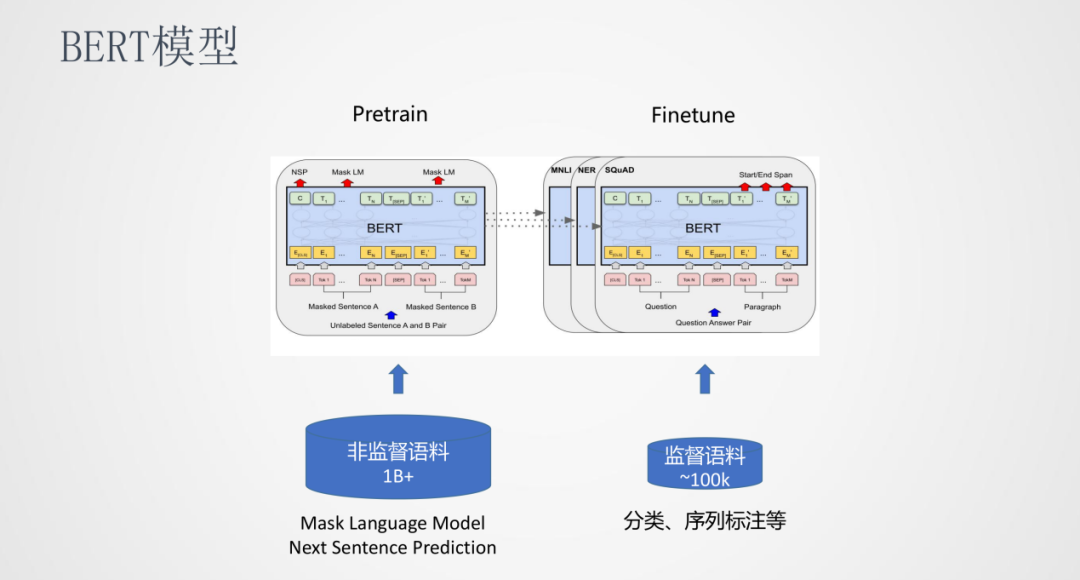
BERT是一種Pretrain和Finetune的訓練方式,在Pretrain階段使用海量的非監督語料訓練出一個與任務無關的公共模型,在Finetune階段可以使用少量的監督語料訓練一個任務相關且效果更優的模型。
4. BERT效果
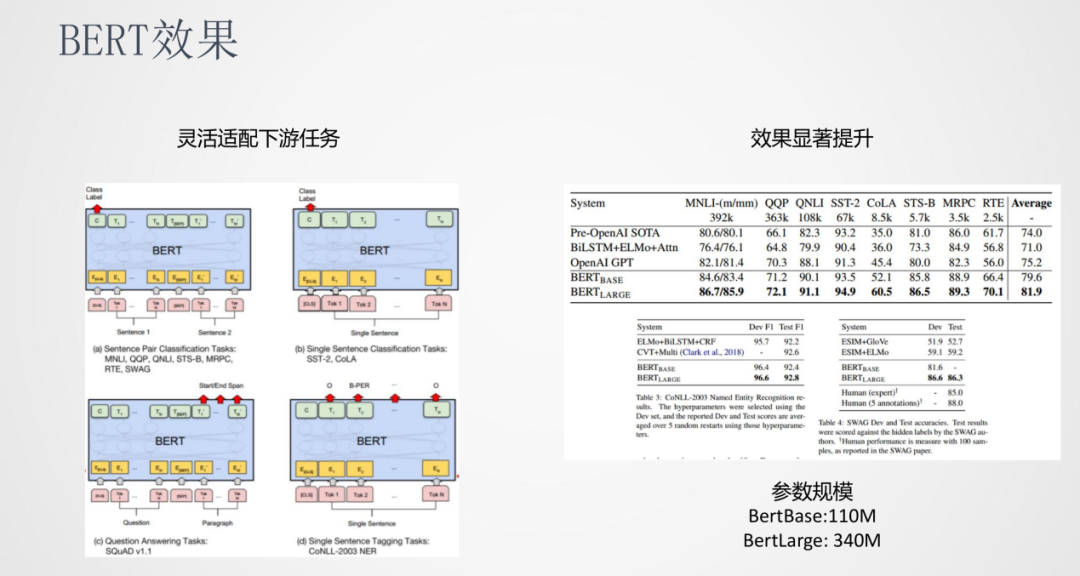
BERT可以靈活的適配下游任務,比如句對分類、文本分類、序列標注、QA等等。另一方面BERT的參數規模也是非常大的,BertBase有110M的參數,BertLarge有340M參數。
5. 預訓練模型發展
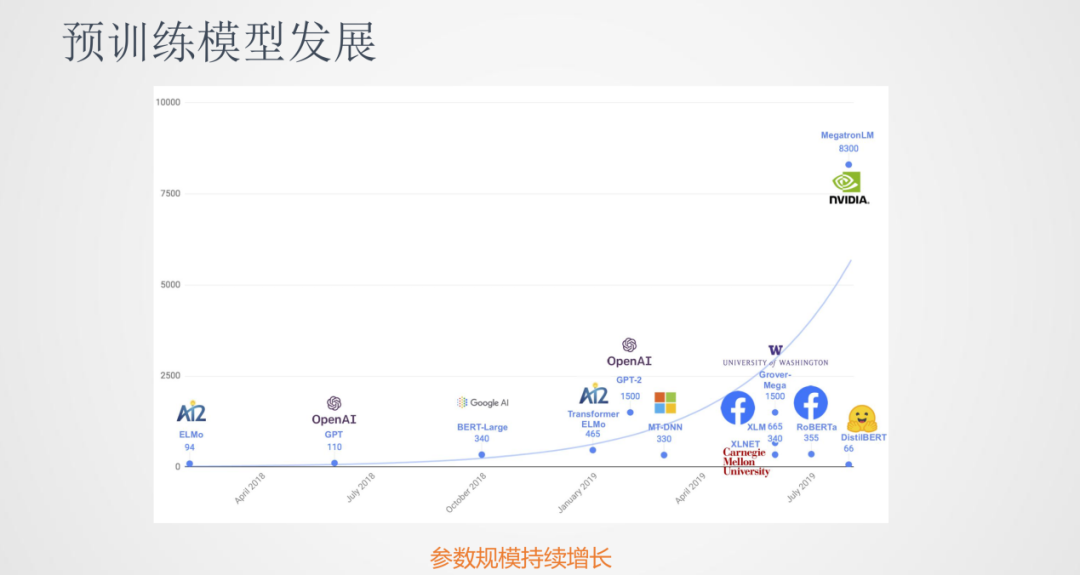
在BERT之后,預訓練模型的發展非常迅速,出現了很多新的預訓練模型。這些模型的趨勢是模型參數在不斷的增大。
02
預訓練落地挑戰
我們以對話系統來介紹下預訓練落地的一些挑戰。對話系統的流程是將輸入的語音通過ASR識別成文本Query,然后進行分詞。由于語音的輸入一般是連續的,所以需要進行語義的斷句。接下來,進行意圖分類將Query分類到天氣/音樂/聊天……這些類別中,再根據Query來匹配到答案,其中匹配的方法可以是檢索式也可以是生成式。
在整個對話系統中,預訓練模型可以應用到很多任務中,遇到的挑戰主要有以下幾個方面:
挑戰一:推理延時高、成本高
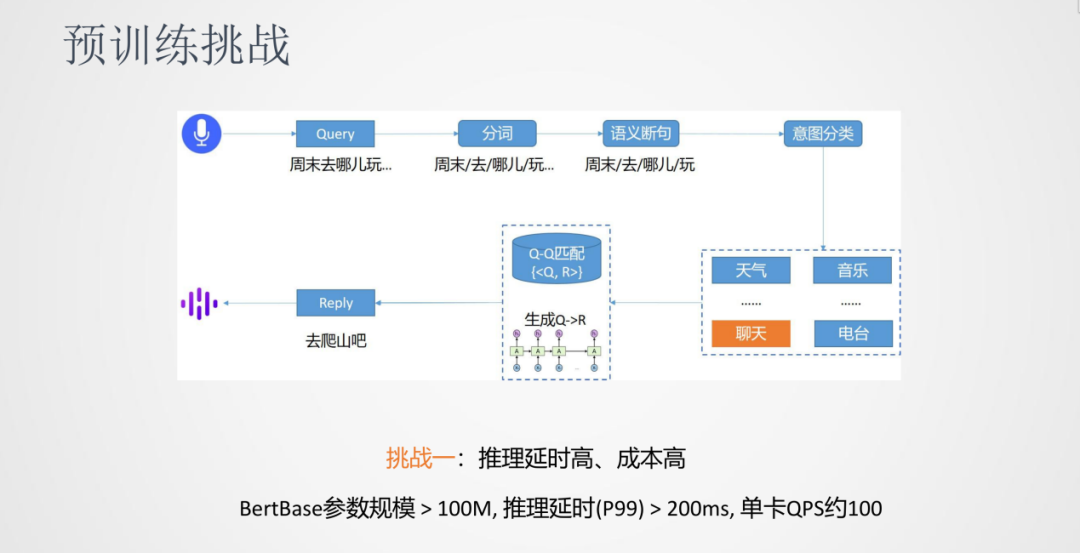
第一個挑戰是由于預訓練模型的參數比較大,會引起推理的延時比較高以及單卡的吞吐比較低,所以推理延時高和成本高是一個通用的挑戰。
挑戰二:知識融入
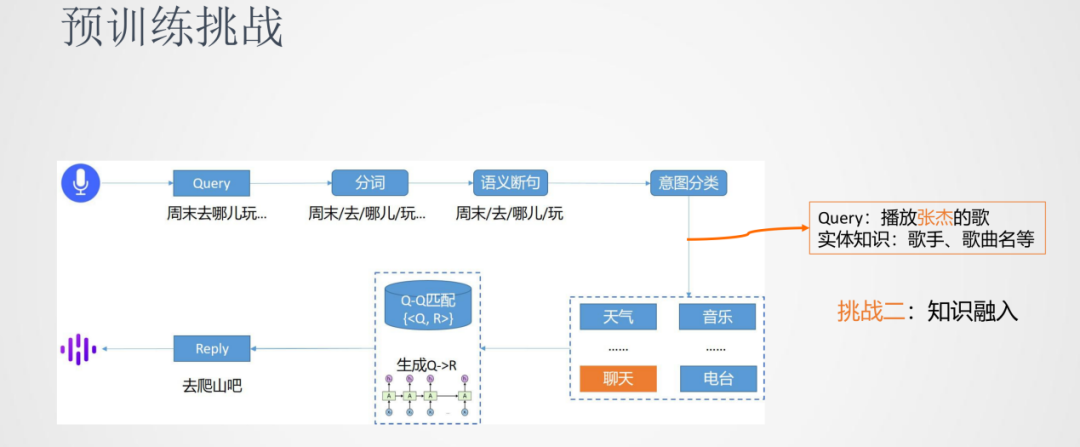
第二個挑戰是一些任務除了使用原生的BERT模型之外,還需要融入一些外部的知識。比如意圖分類的任務,Query中的歌手、歌曲名實體的融入可以幫助模型將Query更準確的分類到音樂類中。
挑戰三:如何根據任務調整模型和訓練
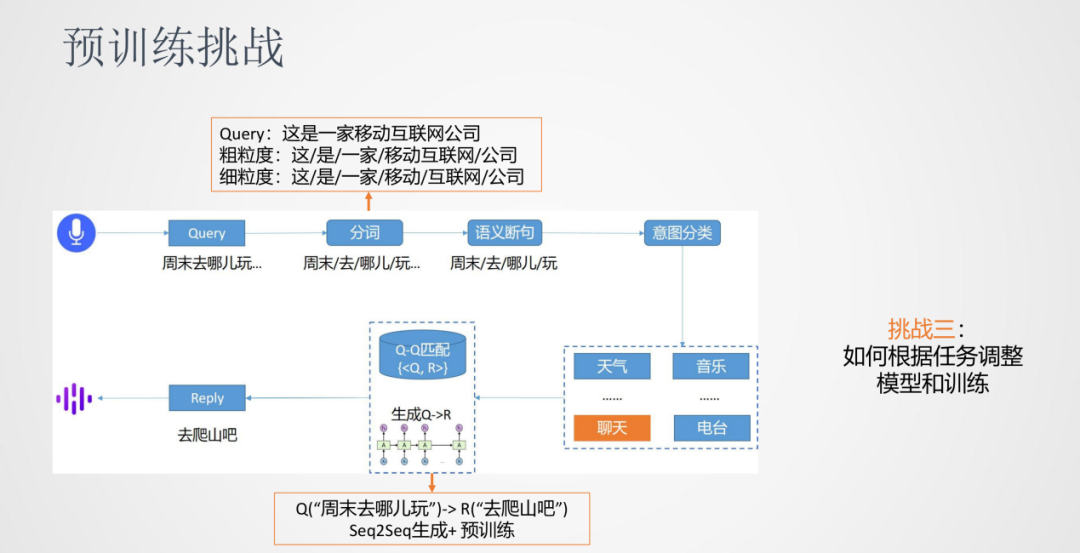
第三個挑戰是我們發現一些任務需要在預訓練模型的基礎上進行調整——模型結構上或者訓練方法上。比如分詞任務,同樣一句話我們可能同時需要粗粒度的分詞或者細粒度的分詞結果,對于原生BERT的序列標注任務需要一些適配。另外,像是對話生成類的任務,傳統上使用Encoder和Decoder的模式,在原生BERT需要進行訓練方法的改進。
03
預訓練實踐探索
1. 推理效率
前面我們已經提到,對于BERT的一個挑戰是模型參數很大,針對這個問題我們很容易想到是不是可以對模型進行壓縮,而知識蒸餾是一種常用的模型壓縮方法。
①知識蒸餾
知識蒸餾是由一個大模型(teacher模型)通過蒸餾數據來生成一個小模型(student模型)。針對分類任務,蒸餾數據相對原始數據會變成soft label的形式,更利于小模型學習到模型中的知識。
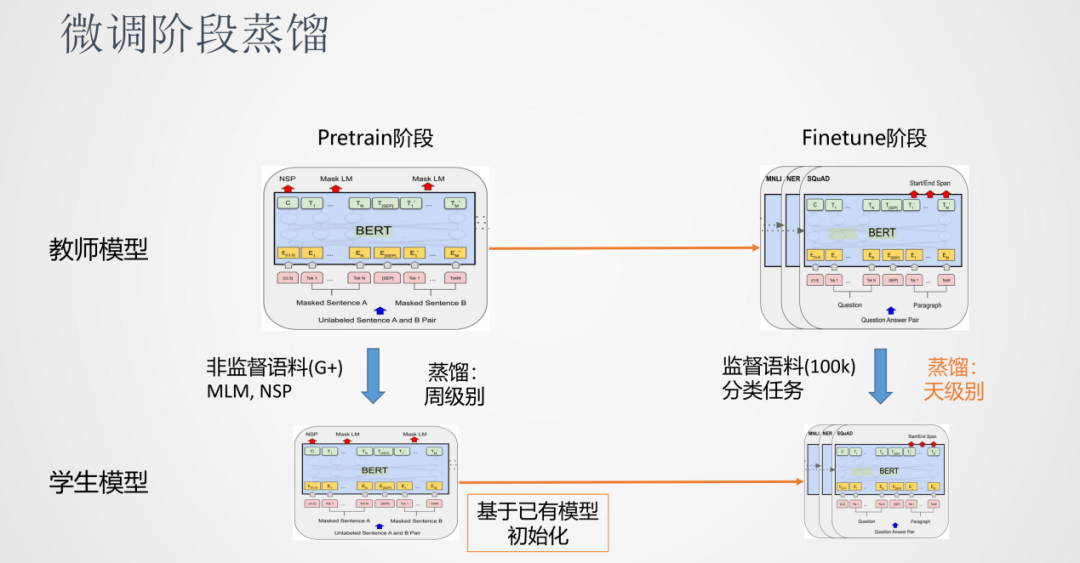
前面說到預訓練模型可以分為Pretrain階段和Finetune階段,對于知識蒸餾來說,也可以分別對Pretrain階段和Finetune階段進行蒸餾。其中,因為Pretrain階段時間會很慢,蒸餾Pretrain也很慢,一般時間是周級別的。另一種方法是跳過Pretrain的階段,使用小模型作為學生的初始模型,直接進行Finetune的蒸餾階段。在實踐中我們發現,這種方式可以得到一個效果不錯的模型。好處是Finetune階段比較快,天級別就可以完成一個蒸餾任務。
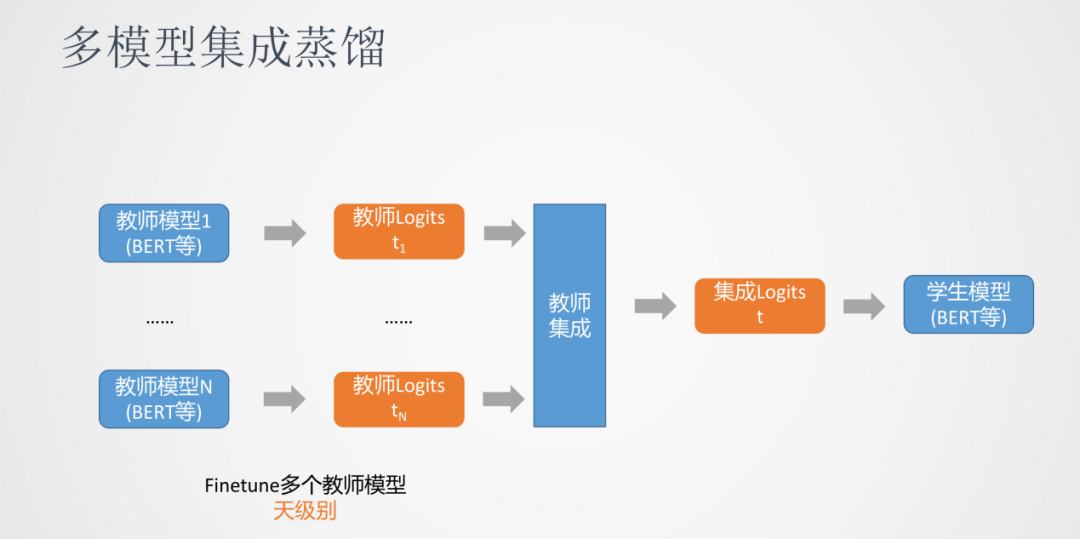
我們發現多模型集成蒸餾對模型效果有一定的提升。多模型集成蒸餾是我們同時訓練多個教師模型,每個教師模型會對數據生成一份蒸餾后的數據。比如分類任務,會生成多個logits這樣概率的分布,然后通過教師集成為一個logits,最后用這個融合后的logits去優化最終的學生模型。
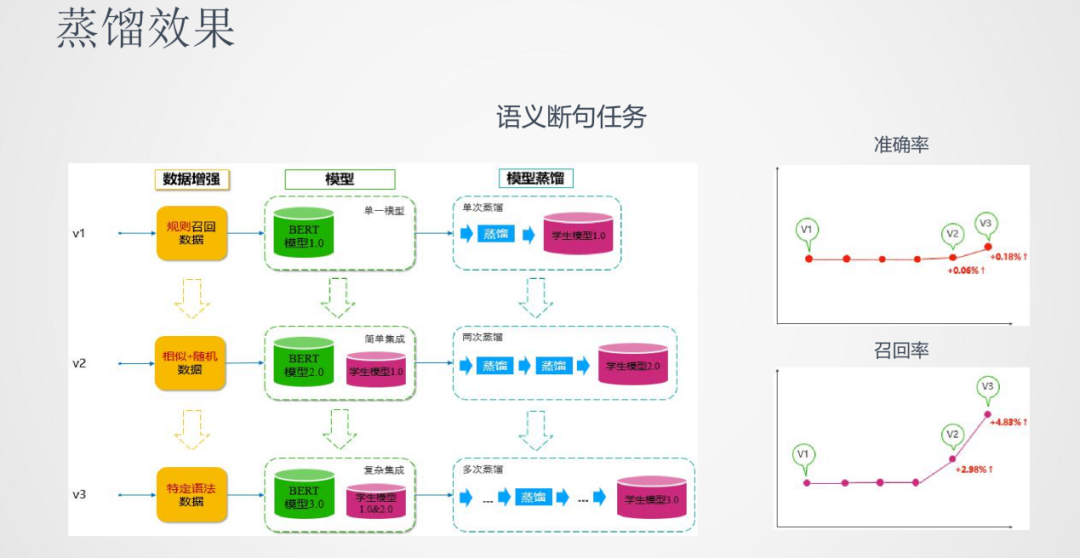
在蒸餾的效果上,以語義斷句任務為例,我們做了三版的模型:
第一版使用單模型的BERT去蒸餾學生模型
第二版使用多模型進行蒸餾,這里面使用的集成策略也相對簡單
第三版使用更多的教師模型且更復雜的集成策略來蒸餾學生模型
從效果上面看,準確率和召回率三版模型都有逐步的提升,尤其集成教師蒸餾的方法在召回率上的效果有了較大的提升。
②低精度推理
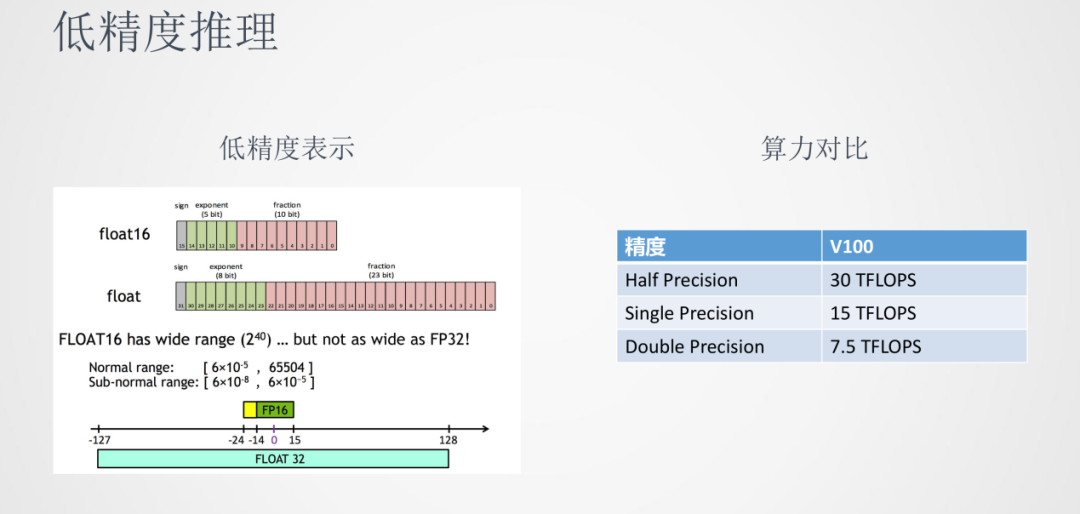
我們都知道在模型訓練時,參數一般都是以float32存儲的。由于神經網絡計算有一定的魯棒性,使用float16半精度的表示也可以達到接近float32的效果。我們可以看到在GPU V100上,半精度算力可以達到單精度的兩倍,在推理延時和吞吐上都具有優勢。
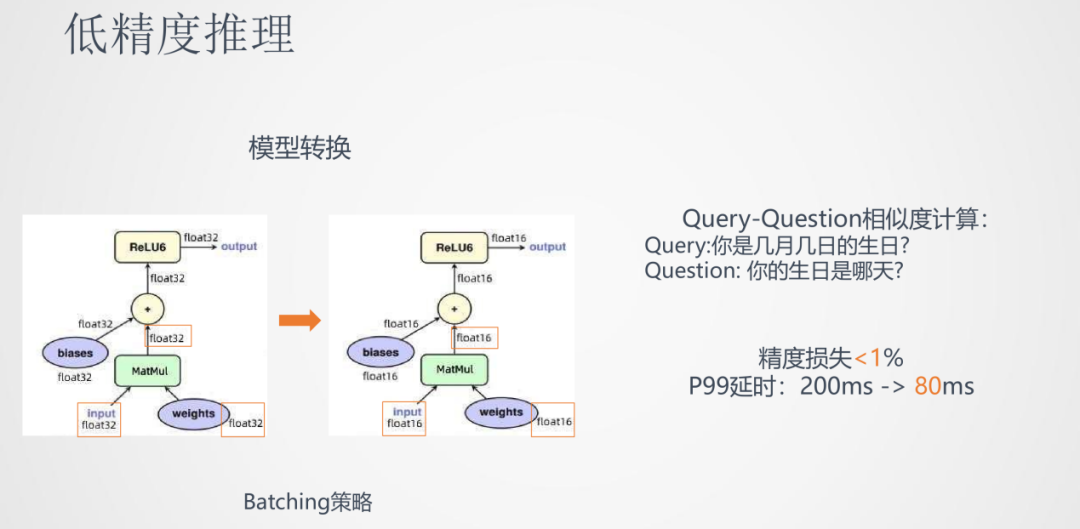
具體的操作是將各個float32位的參數矩陣都轉換成float16位的格式。在實際應用,如Query-Question相似度計算任務中,低精度推理的精度損失小于1%,而P99的延時從200ms降到了80ms,有一倍以上的推理速度降低。
③算子融合
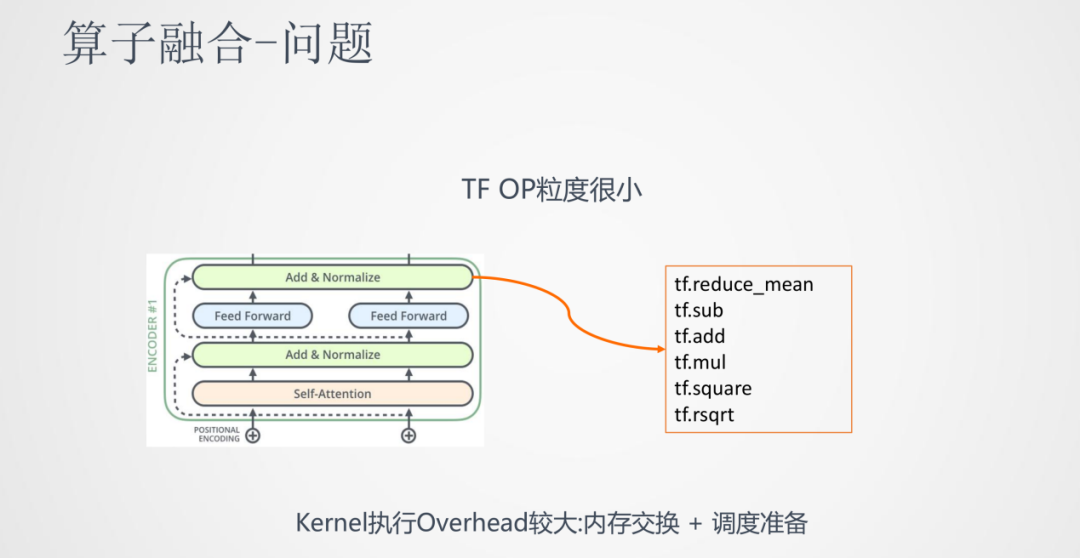
在推理速率上的提升,我們還嘗試了另一種方法:算子融合。
它的初衷是,Transformer從結構上看每一層都有self-attention,add,layer-normalize,feed forward,sublayer等步驟。實際上,中間的每一步轉化到具體的深度學習框架中都是非常長的算子步驟。比如像layer-normalize這一步需要tensorflow中6-7個甚至更多的算子計算序列來完成。這樣在計算框架中OP粒度很小,而CPU在很多時間都是在等待OP的內存交換和調度,導致CPU大部分時間都是在空轉,使得計算效率較低。
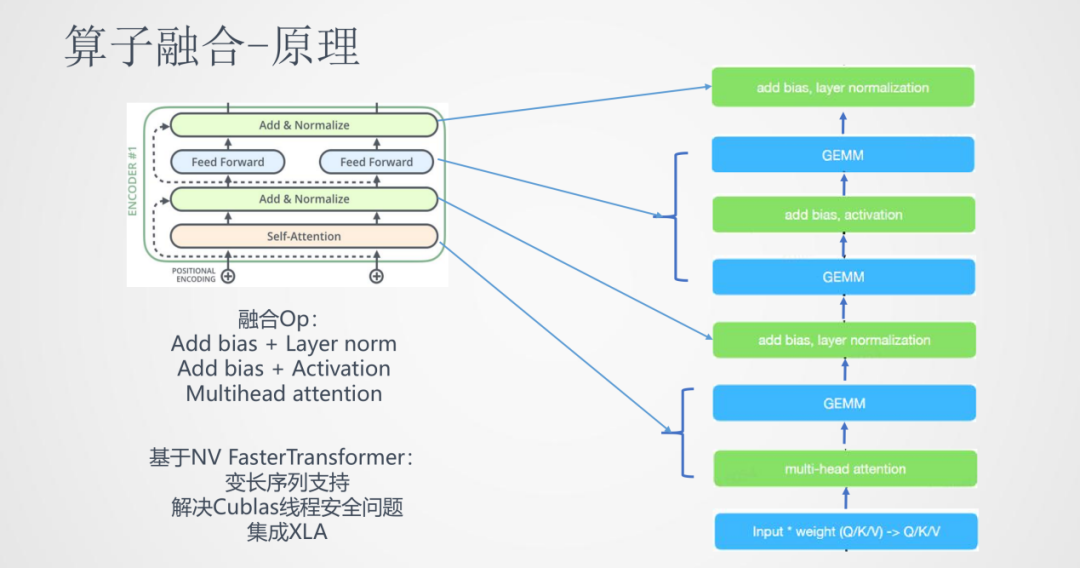
算子融合的思路就是將這些相鄰的算子盡可能融合成一個算子,這樣就能讓CPU最大限度的連續運行。上圖就是將Transformer中的一個block進行了算子融合,將多個小的算子融合成大的算子。
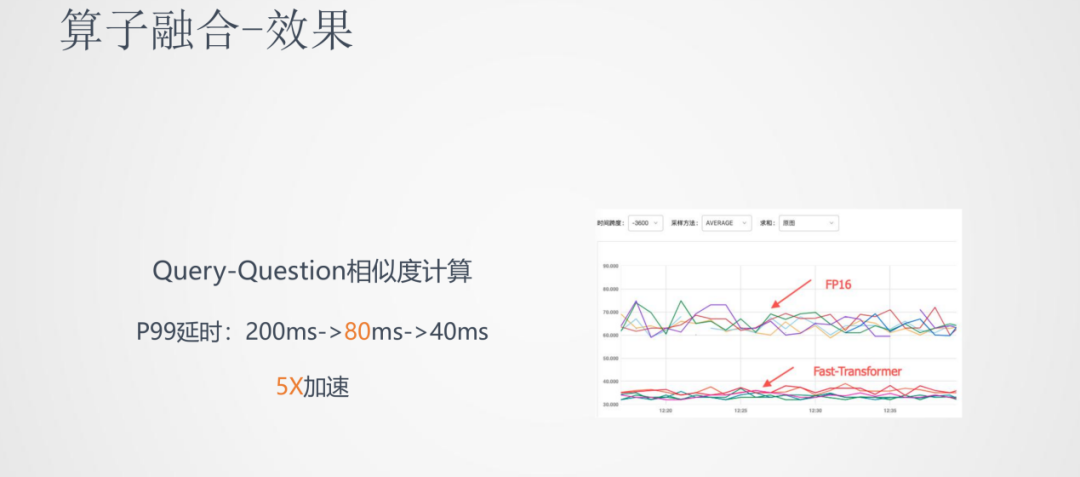
我們可以看到通過加入算子融合,在低精度推理上,推理速度又降低了一倍。這樣就可以將BERT這種大的模型推到線上落地。
2. 知識融合
①問題
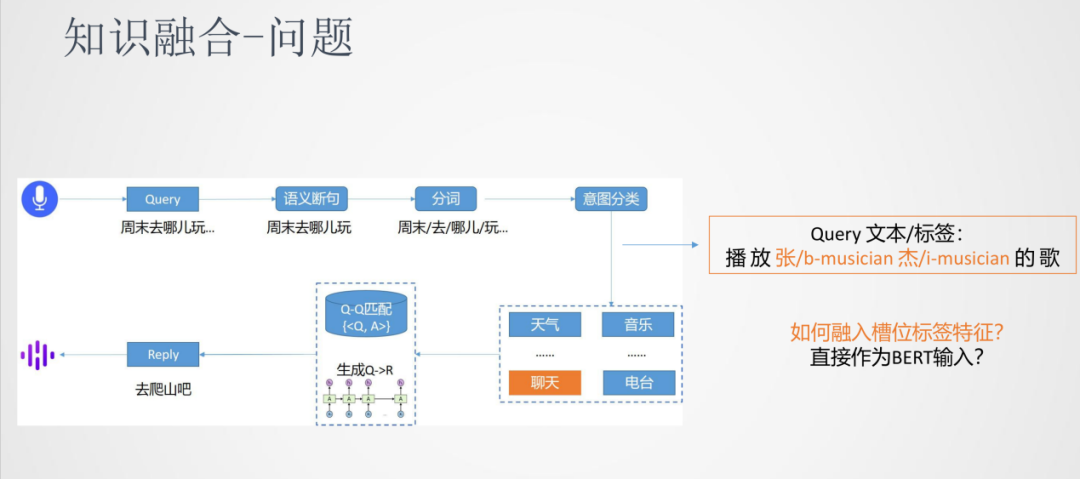
回顧一下之前的對話系統場景,在落地意圖分類任務時,有一些類別包含領域相關的外部信息。比如音樂包含歌手名、歌曲名這樣的信息,我們利用這些信息可以更容易地將query分到對應的類別上。
這樣問題就可以抽象表達為如何將輸入的原始序列和槽位的標簽序列融合在一起用來做分類模型。一個簡單的方法就是將標簽序列也作為輸入,輸入到BERT中,但是BERT在訓練中沒有見到過這樣的輸入,這樣分類的效果會差一些。
②方案
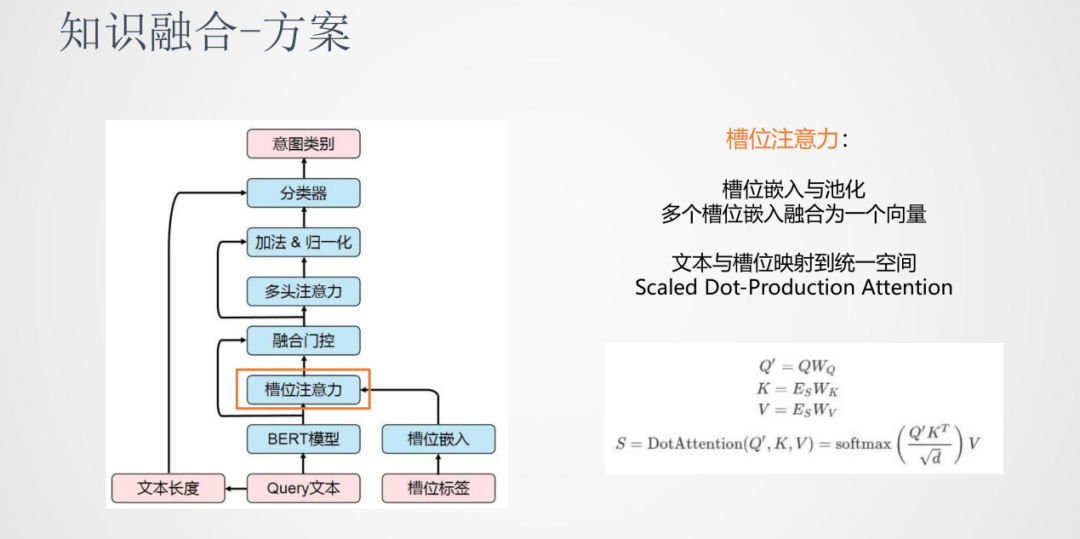
介紹下我們的知識融合方案:
首先引入槽位注意力機制,原始輸入的Query會經過BERT計算輸出一個隱層的表達,槽位的標簽也會做一個嵌入的表達。考慮到同一個詞語位置的地方會有多個槽位信息,我們對于這個多標簽的情況可以做一個池化操作,融合為一個向量。之后做一個線性變換,將文本序列和標簽序列映射到同一個空間,在同一個空間進行attention操作使兩個序列進行交互,這樣就可以得到原始特征和標簽特征的融合特征表示。
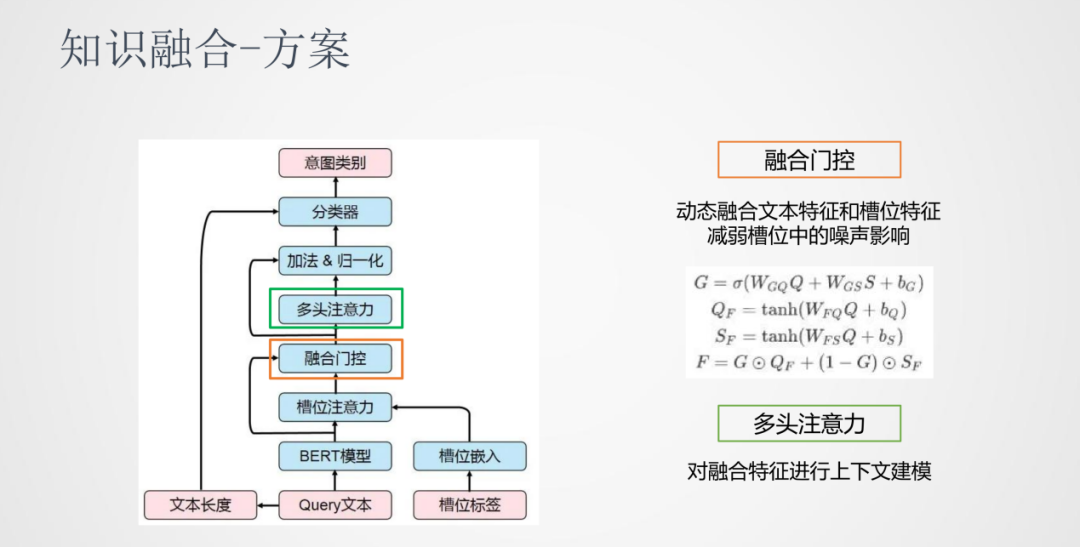
在這之后,我們加入了一個融合門控機制。一般提取出來的標簽都會有一些噪聲,我們通過外部知識獲取的標簽會有一些不準確的可能,所以我們需要確定有多少程度的標簽信息可以加入到原始序列中。我們加入的是一個動態門控的機制,將文本特征和槽位特征進行一個動態的加權。在融合門控之后加入了一個多頭注意力機制,它的作用是在融合之后的特征進行上下文交互來建模。
③效果對比
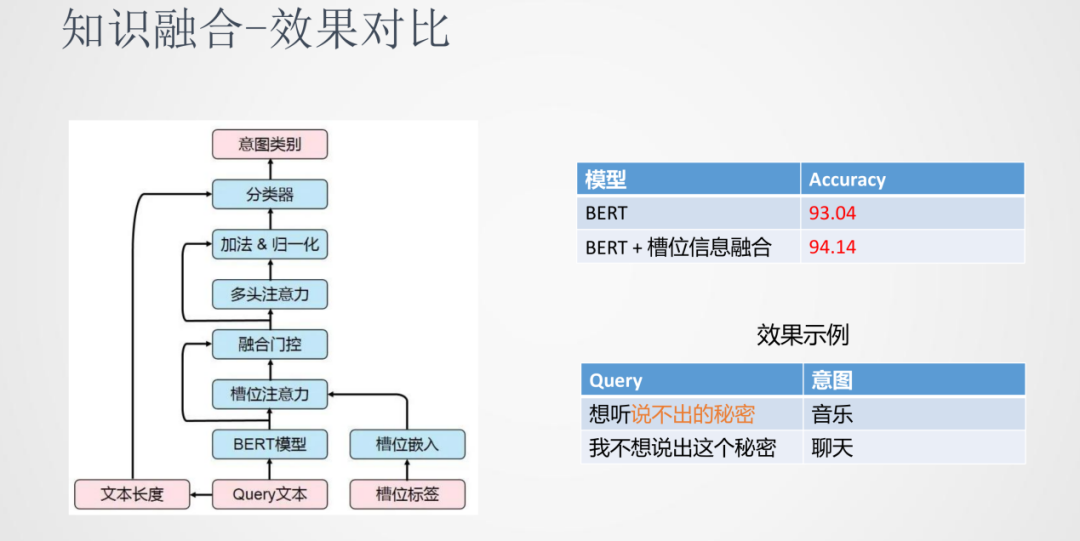
綜合上面這些方法的融合,在意圖分類這個任務上對比單獨使用BERT和融入槽位信息的BERT,融入了槽位信息之后準確率上會有一定量的提升。在上面的例子中,“想聽說不出的秘密”和“我不想說出這個秘密”由于加入的外部知識能夠很好的分類到相應的類別當中。
3. 任務適配
任務一:多粒度分詞
①問題
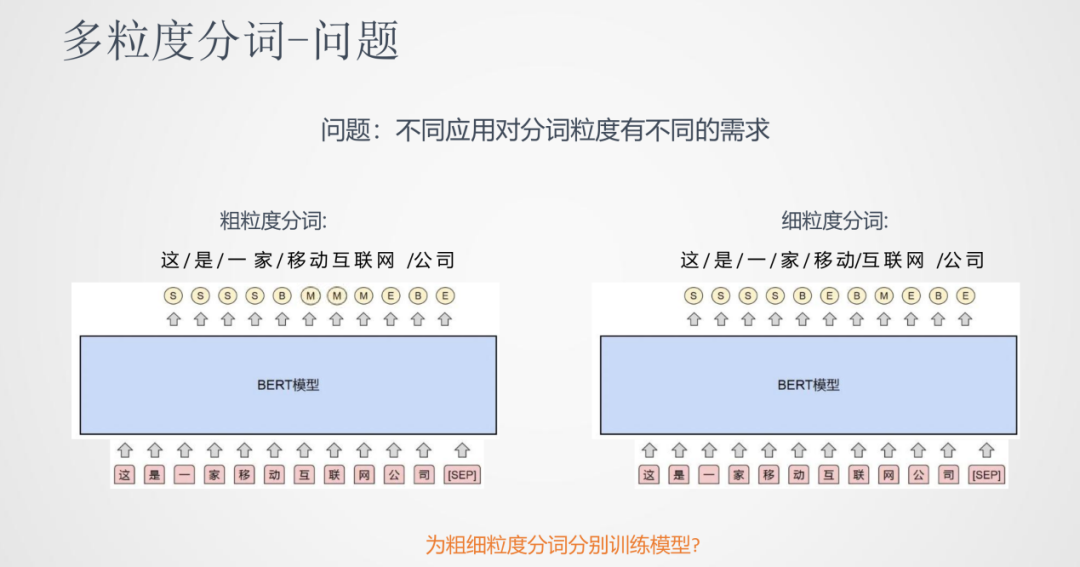
針對同一句話,我們會有粗細粒度不同的分詞需求。比如:這是一家移動互聯網公司,粗粒度:這/是/一家/移動互聯網/公司,細粒度:這/是/一家/移動/互聯網/公司,所以我們需要模型的調整來完成這樣的需求。
分詞任務可以看成是序列標注的任務,輸入的是文本,輸出是每個文字上各個標簽的開始或者結束。一種簡單的一種做法就是為粗/細粒度分別訓練兩版不同的模型,但是模型的維護成本和運行成本都比較高。
②方案
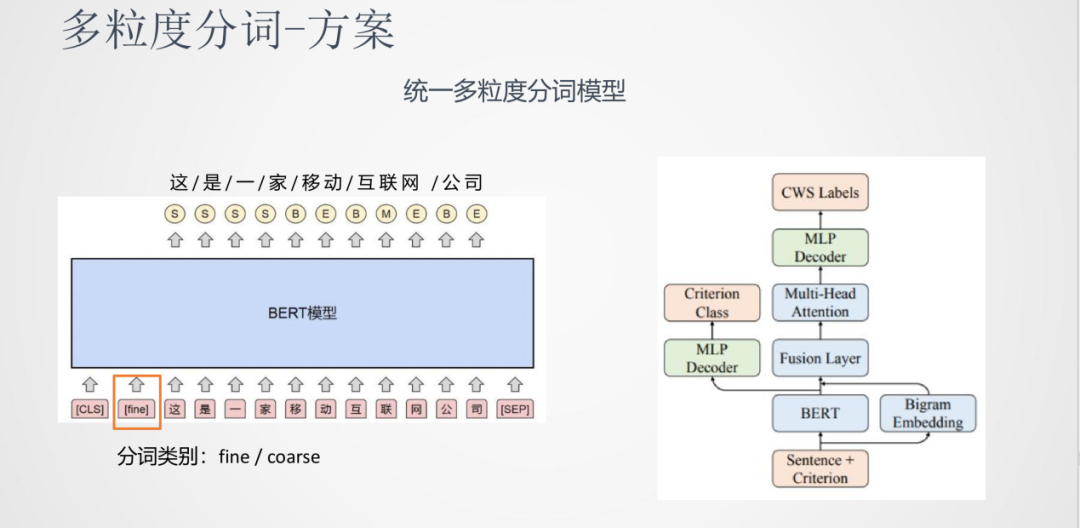
我們的方法是構建一個統一的多粒度分詞模型。它的思想是輸入時將分詞粒度的標簽也加入到輸入序列中,指導分詞粒度的結果。比如上圖中使用fine/coarse來分別代表細/粗粒度標簽,模型的結果就根據這個標簽來適配。
我們除了使用BERT模型網絡外也加入了Bigram的向量特征進行融合,之后使用多頭注意力機制對融合特征的上下文進行建模,最后進行MLP Decoder。除了分詞本身的學習以外,分詞類型也可以作為一個學習任務,兩個任務共同訓練這樣一個網絡。
③效果
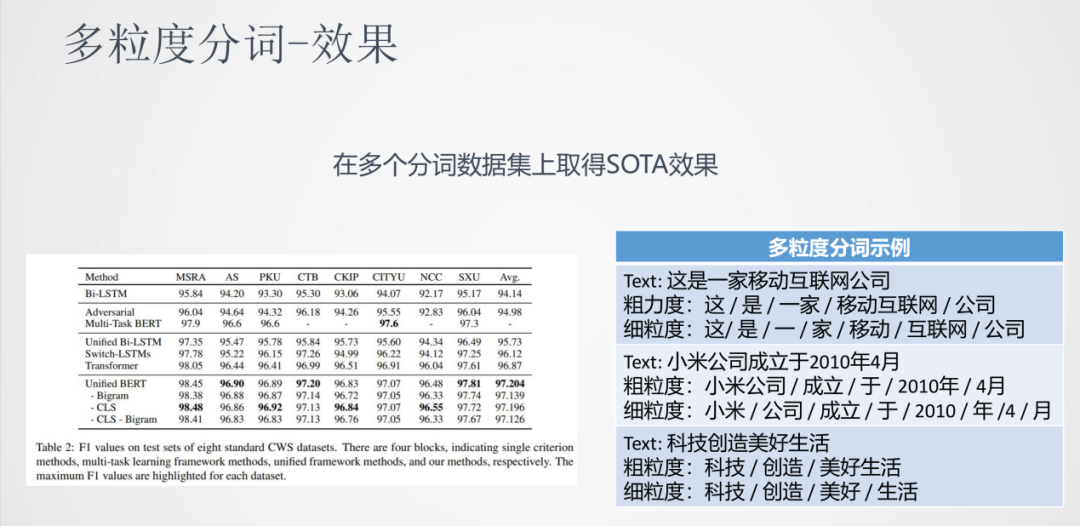
如圖中表格所示,我們使用的多粒度分詞模型在很多任務上都有不錯的效果。通過上面展示的示例可以看到,這種多粒度分詞方法也是一種靈活的分詞方式。
任務二:生成式對話
①問題
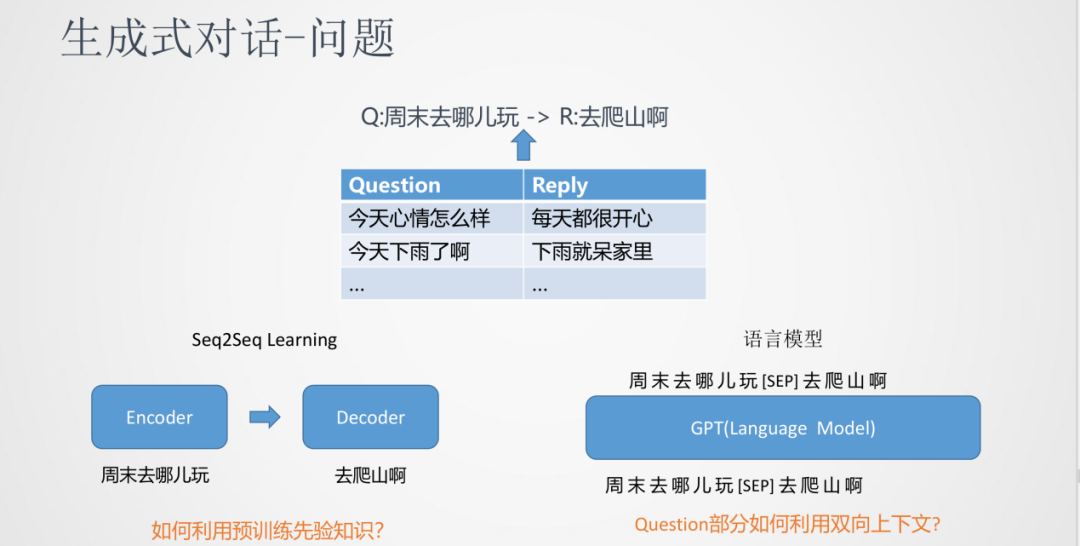
針對生成式對話這樣的場景,一般輸入一個Question,輸出為一個Reply。通常我們會在互聯網社區獲取大量Q/R的數據作為訓練語料來訓練模型。傳統來說,這是一個序列到序列的生成任務,跟翻譯模型的訓練過程比較相近。
傳統的seq2seq模型使用Encoder和Decoder進行建模,問題是沒有預訓練的過程。
另一種方法是使用類似GPT的預訓練方式,將Q和R在一起建模,中間使用[SEP]進行分割,局限是在學習的過程中只能看到文本左邊的內容,而不能對整個文本上下文進行建模。
②方案
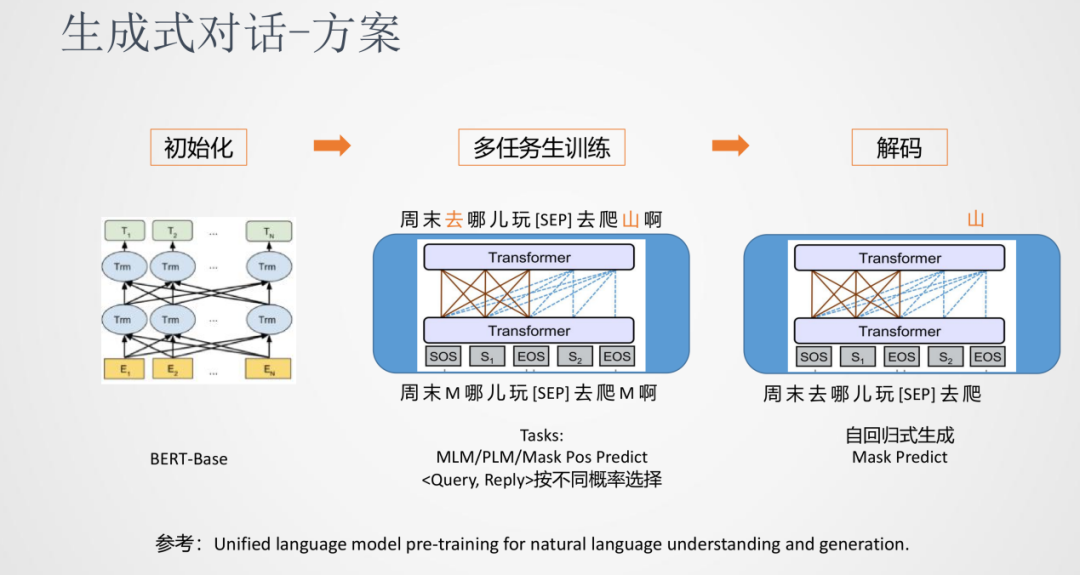
我們采用的是一種多任務的訓練方法。先使用一個基礎的預訓練模型(BERT-Base)來初始化生成式模型的參數,接下來就對話任務進行多任務的訓練,比如MLM、PLM、Mask Pos Predict等語言模型訓練任務,最終在解碼階端可以采用通用的自回歸方式生成。
③效果
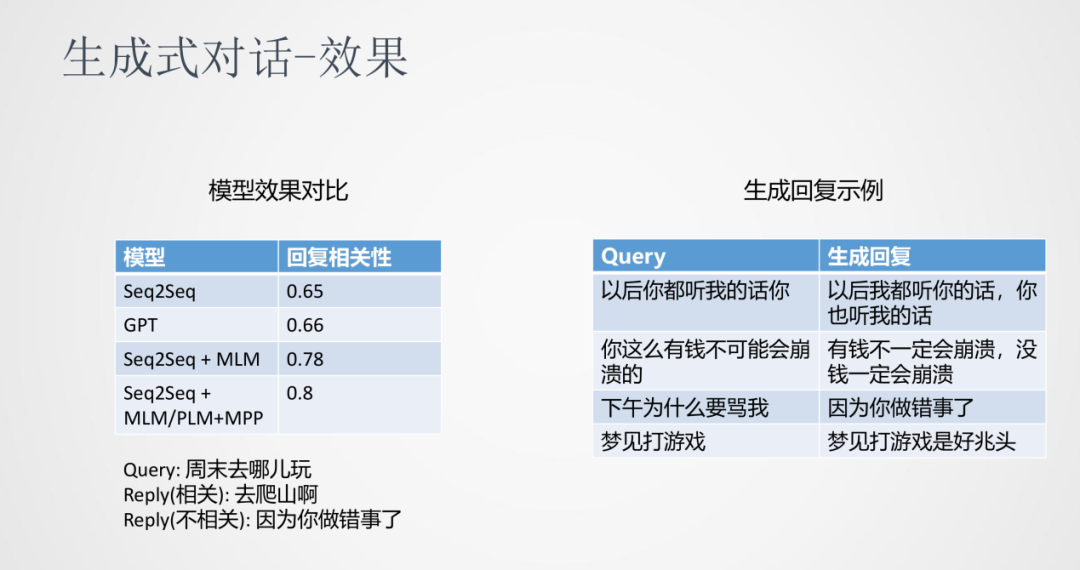
從實驗對比來看,跟傳統的seq2seq、GPT相比,加入多任務訓練的方式在針對回復相關性上有很明顯的提升。從上圖右邊示例中可以看到,隨著語料數據不斷的增大和模型多任務的學習,生成的回復有很好的連貫性和相關性。
04
總結與展望1. 總結
本文主要介紹了推理效率、知識融入和任務適配。
推理效率:在知識蒸餾方面使用多教師模型集成蒸餾是一種可以將模型壓縮更小,保證模型效果的方法;而推理加速方面使用低精度推理和算子融合的方法可以幫助推理速度有幾倍的提升。
知識融入:在對話系統意圖識別任務中,通過在原始序列中加入槽位信息序列,使用attention的方法將兩個特征序列融合成一個序列。
任務適配:多粒度分詞任務是在輸入上加入適配的標簽來指導輸出的一種自適應的改變。生成式對話采用聯合多任務訓練的方式能夠集成預訓練和序列到序列的生成模型。
2. 展望
輕量級模型
知識融入
預訓練平臺
原文標題:小米在預訓練模型的探索與優化
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
模型
+關注
關注
1文章
3449瀏覽量
49712 -
小米
+關注
關注
70文章
14417瀏覽量
145960 -
nlp
+關注
關注
1文章
490瀏覽量
22382
原文標題:小米在預訓練模型的探索與優化
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

從Open Model Zoo下載的FastSeg大型公共預訓練模型,無法導入名稱是怎么回事?
用PaddleNLP在4060單卡上實踐大模型預訓練技術

【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
KerasHub統一、全面的預訓練模型庫

直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論