 預訓練語言模型的字典描述
預訓練語言模型的字典描述
今天給大家帶來一篇IJCAI2022浙大和阿里聯合出品的采用對比學習的字典描述知識增強的預訓練語言模型-DictBERT,全名為《Dictionary Description Knowledge Enhanced Language Model Pre-training via Contrastive Learning》
又鴿了許久,其實最近看到一些有趣的論文,大多以知乎想法的形式發了,感興趣可以去看看,其實碼字還是很不易的~
介紹
預訓練語言模型(PLMs)目前在各種自然語言處理任務中均取得了優異的效果,并且部分研究學者將外部知識(知識圖譜)融入預訓練語言模型中后獲取了更加優異的效果,但具體場景下的知識圖譜信息往往是不容易獲取的,因此,我們提出一種新方法DictBert,將字典描述信息作為外部知識增強預訓練語言模型,相較于知識圖譜的信息增強,字典描述更容易獲取。
在預訓練階段,提出來兩種新的預訓練任務來訓練DictBert模型,通過掩碼語言模型任務和對比學習任務將字典知識注入到DictBert模型中,其中,掩碼語言模型任務為字典中詞條預測任務(Dictionary Entry Prediction);對比學習任務為字典中詞條描述判斷任務(Entry Description Discrimination)。
在微調階段,我們將DictBert模型作為可插拔的外部知識庫,對輸入序列中所包含字典中的詞條信息作為外部隱含知識內容,注入到輸入中,并通過注意機制來增強輸入的表示,最終提升模型表征效果。
模型
字典描述知識
字典是一種常見的資源,它列出了某一種語言所包含的字/詞,并通過解釋性描述對其進行含義的闡述,常常也會指定它們的發音、來源、用法、同義詞、反義詞等,如下表所示,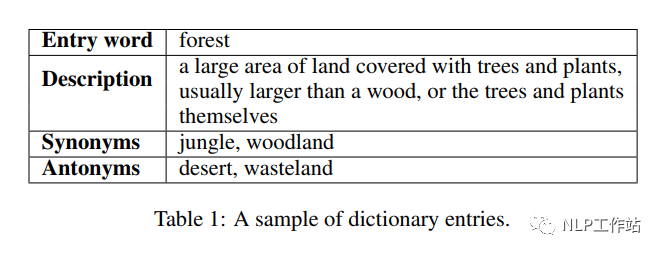 我們主要利用四種信息進行模型的預訓練,包括:詞條、描述、同義詞和反義詞。在詞條預測任務中,利用字典的詞條及其描述進行知識學習;在詞條描述判斷任務中,利用同義詞和反義詞來進行對比學習,從而學習到知識表征。
我們主要利用四種信息進行模型的預訓練,包括:詞條、描述、同義詞和反義詞。在詞條預測任務中,利用字典的詞條及其描述進行知識學習;在詞條描述判斷任務中,利用同義詞和反義詞來進行對比學習,從而學習到知識表征。
預訓練任務
預訓練任務主要包含字典中詞條預測任務和字典中詞條描述判斷任務,如下圖所示。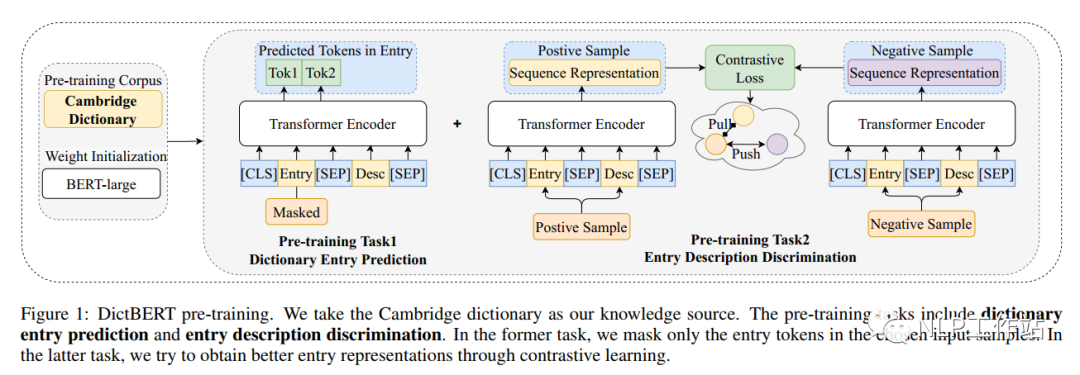 詞條預測任務,實際上是一個掩碼語言模型任務,給定詞條和它對于的描述,然后將詞條的內容使用特殊字符[MASK]進行替換,最終將其[MASK]內容進行還原。注意,當詞條包含多個token時,需要將其全部掩掉。
詞條預測任務,實際上是一個掩碼語言模型任務,給定詞條和它對于的描述,然后將詞條的內容使用特殊字符[MASK]進行替換,最終將其[MASK]內容進行還原。注意,當詞條包含多個token時,需要將其全部掩掉。
詞條描述判斷任務,實際上是一個對比學習任務,而對比學習就是以拉近相似數據,推開不相似數據為目標,有效地學習數據表征。如下表所示, 對于詞條“forest”,正例樣本為同義詞“woodland”,負例樣本為反義詞“desert”。對比學習中,分別對原始詞條+描述、正例樣本+描述和負例樣本+描述進行模型編碼,獲取、和,獲取對比學習損失,
對于詞條“forest”,正例樣本為同義詞“woodland”,負例樣本為反義詞“desert”。對比學習中,分別對原始詞條+描述、正例樣本+描述和負例樣本+描述進行模型編碼,獲取、和,獲取對比學習損失,
最終,模型預訓練的損失為
其中,為0.4,為0.6。
微調任務
在微調過程中,將DictBert模型作為可插拔的外部知識庫,如下圖所示,首先識別出輸入序列中所包含字典中的詞條信息,然后通過DictBert模型獲取外部信息表征,再通過三種不同的方式進行外部知識的注入,最終將其綜合表征進行下游具體的任務。并且由于可以事先離線對一個字典中所有詞條進行外部信息表征獲取,因此,在真實落地場景時并不會增加太多的額外耗時。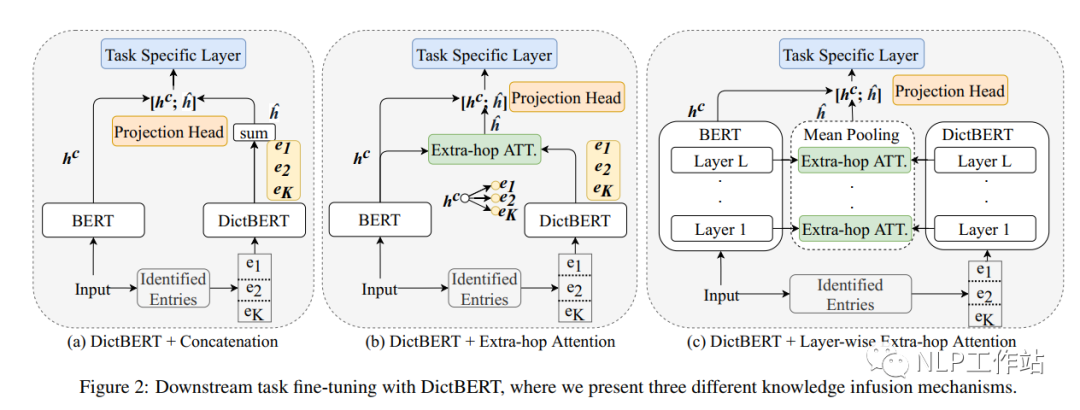 知識注入的方式包含三種:
知識注入的方式包含三種:
Pooled Output Concatenation,即將所有詞條的信息表征進行求和,然后與原始模型的進行拼接,最終進行下游任務;
Extra-hop Attention,即將所有詞條的信息表征對進行attition操作,獲取分布注意力后加權求和的外部信息表征,然后與原始模型的進行拼接,最終進行下游任務;
Layer-wise Extra-hop Attention,即將所有詞條的信息表征對每一層的進行attition操作,獲取每一層分布注意力后加權求和的外部信息表征,然后對其所有層進行mean-pooling操作,然后與原始模型的進行拼接,最終進行下游任務;
結果
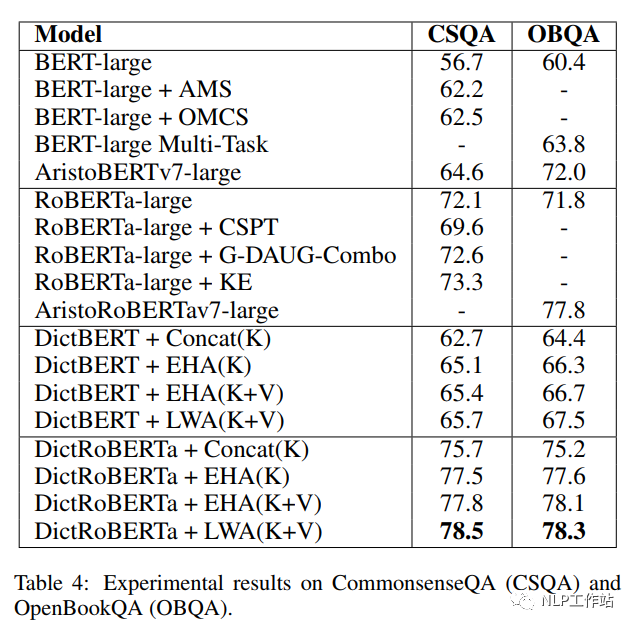
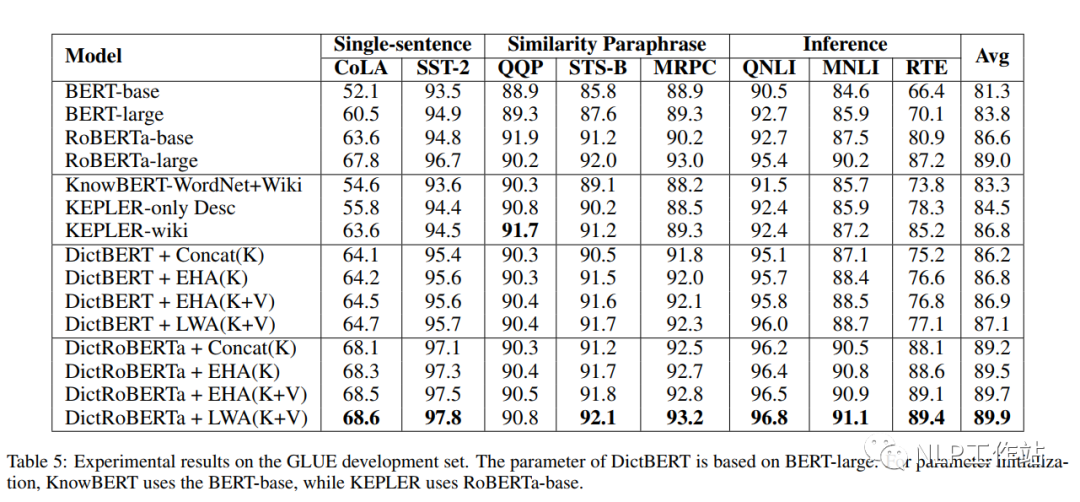
如下表所示,采用劍橋字典進行預訓練后的DictBert模型,在CoNLL2003、TACRED、CommonsenseQA、OpenBookQA和GLUE上均有提高。其中,Concat表示Pooled Output Concatenation方式,EHA表示Extra-hop Attention,LWA表示Layer-wise Extra-hop Attention,K表示僅采用詞條進行信息表征,K+V表示采用詞條和描述進行信息表征。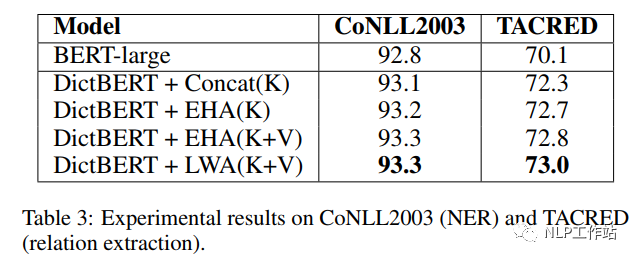
總結
挺有意思的一篇論文吧,相較于知識圖譜來說,字典確實較容易獲取,并在不同領域中,也比較好通過爬蟲的形式進行詞條和描述的獲取;并且由于字典的表征可以進行離線生成,所以對線上模型的耗時并不明顯,主要在attention上。
-
編碼
+關注
關注
6文章
963瀏覽量
55310 -
字典
+關注
關注
0文章
13瀏覽量
7756 -
語言模型
+關注
關注
0文章
556瀏覽量
10578
原文標題:IJCAI2022 | DictBert:采用對比學習的字典描述知識增強的預訓練語言模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論