") 一文理解多模態(tài)大語言模型——下
一文理解多模態(tài)大語言模型——下

?
作者:Sebastian Raschka 博士,
翻譯:張晶,Linux Fundation APAC Open Source Evangelist
編者按:本文并不是逐字逐句翻譯,而是以更有利于中文讀者理解的目標(biāo),做了刪減、重構(gòu)和意譯,并替換了多張不適合中文讀者的示意圖。
原文地址:https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
《一文理解多模態(tài)大語言模型 - 上》介紹了什么是多模態(tài)大語言模型,以及構(gòu)建多模態(tài) LLM 有兩種主要方式之一:統(tǒng)一嵌入解碼器架構(gòu)(Unified Embedding Decoder Architecture)。本文將接著介紹第二種構(gòu)建多模態(tài) LLM 的方式:跨模態(tài)注意架構(gòu)(Cross-modality Attention Architecture approach)。
一,跨模態(tài)注意架構(gòu)
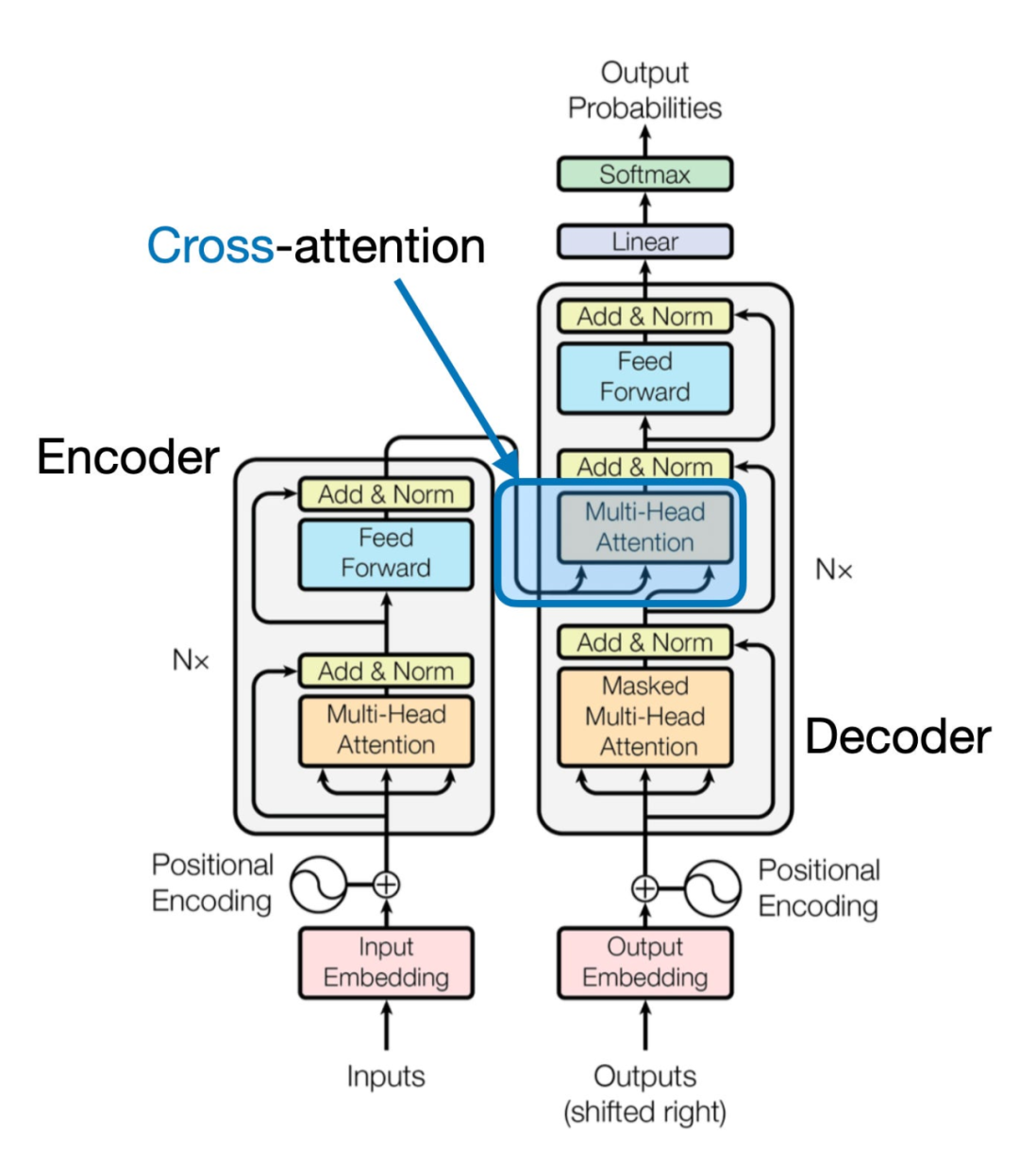
《一文理解多模態(tài)大語言模型 - 上》討論了通過統(tǒng)一嵌入解碼器架構(gòu)來構(gòu)建多模態(tài)大語言模型(LLM)的方法,并且理解了圖像編碼背后的基本概念,下面介紹另一種通過交叉注意力機(jī)制實(shí)現(xiàn)多模態(tài)LLM的方式,如下圖所示:

在上圖所示的跨模態(tài)注意力架構(gòu)方法中,我們?nèi)匀皇褂弥敖榻B的圖像向量化方式。然而,與直接將圖像向量作為L(zhǎng)LM的輸入不同,我們通過交叉注意力機(jī)制在多頭注意力層中連接輸入的圖像向量。
這個(gè)想法與2017年《Attention Is All You Need》論文中提出的原始Transformer架構(gòu)相似,在原始《Attention Is All You Need》論文中的Transformer最初是為語言翻譯開發(fā)的。因此,它由一個(gè)文本編碼器(下圖的左部分)組成,該編碼器接收要翻譯的句子,并通過一個(gè)文本解碼器(圖的右部分)生成翻譯結(jié)果。在多模態(tài)大語言模型的背景下,圖的右部分的編碼器由之前的文本編碼器,更換為圖像編碼器(圖像編碼后的向量)。
文本和圖像在進(jìn)入大語言模型前都編碼為嵌入維度和尺寸(embedding dimensions and size)一致的向量。
“我們可以把多模態(tài)大語言模型看成“翻譯”文本和圖像,或文本和其它模態(tài)數(shù)據(jù) --- 譯者。”
二,統(tǒng)一解碼器和交叉注意力模型訓(xùn)練
與傳統(tǒng)僅文本的大語言模型(LLM)的開發(fā)類似,多模態(tài)大語言模型的訓(xùn)練也包含兩個(gè)階段:預(yù)訓(xùn)練和指令微調(diào)。然而,與從零開始不同,多模態(tài)大語言模型的訓(xùn)練通常以一個(gè)預(yù)訓(xùn)練過且已經(jīng)過指令微調(diào)的大語言模型作為基礎(chǔ)模型。
對(duì)于圖像編碼器,通常使用CLIP,并且在整個(gè)訓(xùn)練過程中往往保持不變,盡管也存在例外,我們稍后會(huì)探討這一點(diǎn)。在預(yù)訓(xùn)練階段,保持大語言模型部分凍結(jié)也是常見的做法,只專注于訓(xùn)練投影器(Projector)——一個(gè)線性層或小型多層感知器。鑒于投影器的學(xué)習(xí)能力有限,通常只包含一兩層,因此在多模態(tài)指令微調(diào)(第二階段)期間,大語言模型通常會(huì)被解凍,以允許進(jìn)行更全面的更新。然而,需要注意的是,在基于交叉注意力機(jī)制的模型(方法B)中,交叉注意力層在整個(gè)訓(xùn)練過程中都是解凍的。
在介紹了兩種主要方法(方法A:統(tǒng)一嵌入解碼器架構(gòu)和方法B:跨模態(tài)注意力架構(gòu))之后,你可能會(huì)好奇哪種方法更有效。答案取決于具體的權(quán)衡:
統(tǒng)一嵌入解碼器架構(gòu)(方法A)通常更容易實(shí)現(xiàn),因?yàn)樗恍枰獙?duì)LLM架構(gòu)本身進(jìn)行任何修改。
跨模態(tài)注意力架構(gòu)(方法B)通常被認(rèn)為在計(jì)算上更高效,因?yàn)樗粫?huì)通過額外的圖像分詞(Token)來過載輸入上下文,而是在后續(xù)的交叉注意力層中引入這些標(biāo)記。此外,如果在訓(xùn)練過程中保持大語言模型參數(shù)凍結(jié),這種方法還能保持原始大語言模型的僅文本性能。
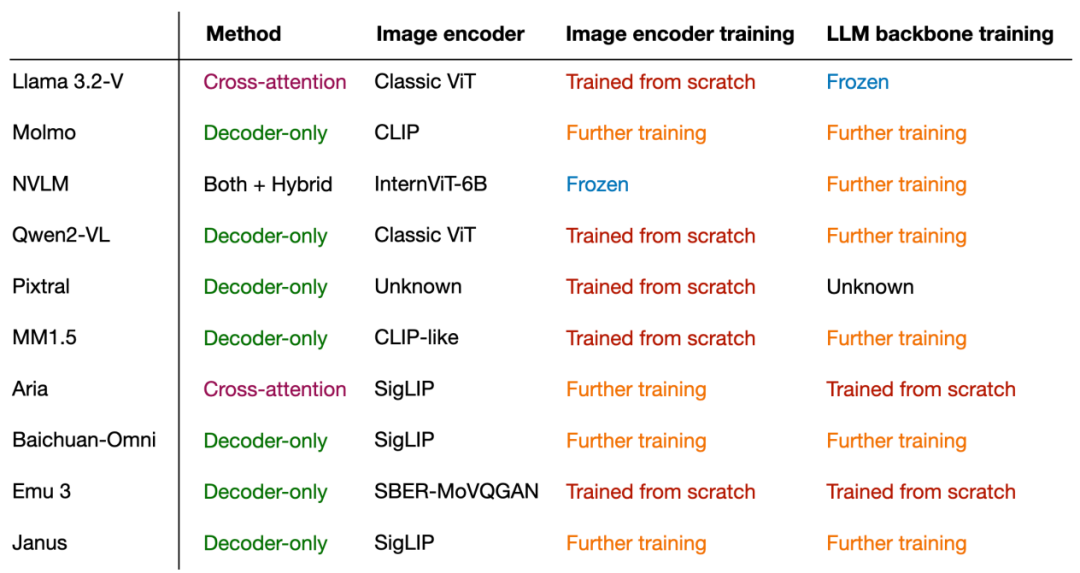
下圖總結(jié)了常見多模態(tài)大語言模型使用的組件和技術(shù):
三,總結(jié)
“多模態(tài)LLM可以通過多種不同的方式成功構(gòu)建,核心思路在于把多模態(tài)數(shù)據(jù)編碼為嵌入維度和尺寸一致的向量,使得原始大語言模型可以對(duì)多模態(tài)數(shù)據(jù)“理解并翻譯”。--- 譯者”。
如果你有更好的文章,歡迎投稿!
稿件接收郵箱:nami.liu@pasuntech.com
更多精彩內(nèi)容請(qǐng)關(guān)注“算力魔方?”!
?審核編輯 黃宇
-
語言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10799 -
LLM
+關(guān)注
關(guān)注
1文章
325瀏覽量
850
發(fā)布評(píng)論請(qǐng)先 登錄
一文理解多模態(tài)大語言模型——上

VisCPM:邁向多語言多模態(tài)大模型時(shí)代

更強(qiáng)更通用:智源「悟道3.0」Emu多模態(tài)大模型開源,在多模態(tài)序列中「補(bǔ)全一切」

中科大&字節(jié)提出UniDoc:統(tǒng)一的面向文字場(chǎng)景的多模態(tài)大模型
DreamLLM:多功能多模態(tài)大型語言模型,你的DreamLLM~

探究編輯多模態(tài)大語言模型的可行性
機(jī)器人基于開源的多模態(tài)語言視覺大模型

韓國(guó)Kakao宣布開發(fā)多模態(tài)大語言模型“蜜蜂”
李未可科技正式推出WAKE-AI多模態(tài)AI大模型

利用OpenVINO部署Qwen2多模態(tài)模型

海康威視發(fā)布多模態(tài)大模型文搜存儲(chǔ)系列產(chǎn)品
商湯“日日新”融合大模型登頂大語言與多模態(tài)雙榜單
百度發(fā)布文心大模型4.5和文心大模型X1
基于MindSpeed MM玩轉(zhuǎn)Qwen2.5VL多模態(tài)理解模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論