") 一文理解多模態(tài)大語言模型——上
一文理解多模態(tài)大語言模型——上
作者:Sebastian Raschka 博士,
翻譯:張晶,Linux Fundation APAC Open Source Evangelist
編者按:本文并不是逐字逐句翻譯,而是以更有利于中文讀者理解的目標(biāo),做了刪減、重構(gòu)和意譯,并替換了多張不適合中文讀者的示意圖。
原文地址:https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
在過去幾個(gè)月中,OpenVINO?架構(gòu)師 Yury閱讀了眾多有關(guān)多模態(tài)大語言模型的論文和博客,在此基礎(chǔ)上,推薦了一篇解讀多模態(tài)大語言模型的最佳文章《Understand Multimodal LLMs》--- 能讓讀者很好的理解大語言模型(LLMs)是如何演進(jìn)為視覺語言模型(VLMs)的。

閱讀本文之前,可以先在自己的電腦上運(yùn)行當(dāng)前最新的視覺大語言模型Llama 3.2 Vision模型,感受一下視覺語言模型能干什么!
一,什么是多模態(tài)大語言模型
多模態(tài)大語言模型是能夠處理多種“模態(tài)”類型輸入的大語言模型,其中每個(gè)“模態(tài)”指的是特定類型的數(shù)據(jù),例如:文本、聲音、圖像、視頻等,處理結(jié)果以文本類型輸出。
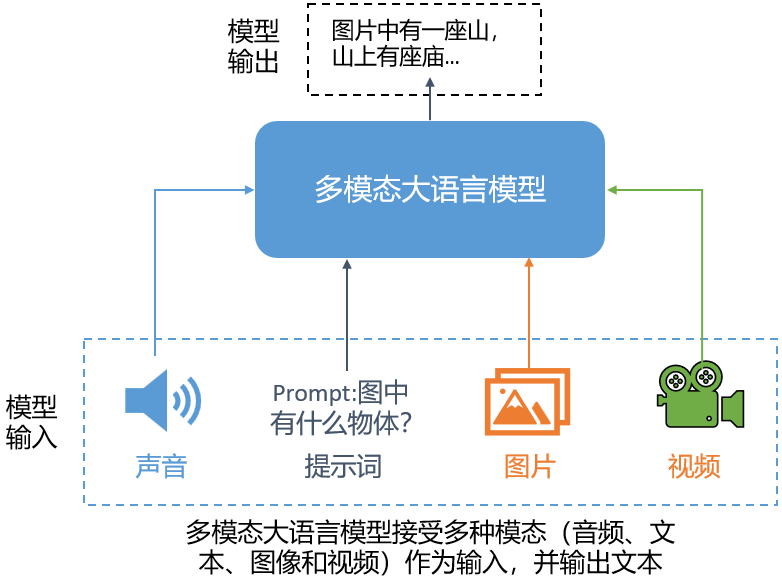
多模態(tài)大語言模型的一個(gè)經(jīng)典而直觀的應(yīng)用是解讀圖片:輸入圖像和提示詞,模型生成該圖像的描述(文本),如下圖所示。

當(dāng)然,還有許多其他應(yīng)用,例如:從圖片中提取信息并將其轉(zhuǎn)換為 LaTeX 或 Markdown。
二,構(gòu)建多模態(tài)大語言模型的常見方式
構(gòu)建多模態(tài) LLM 有兩種主要方式:
方法 A:統(tǒng)一嵌入解碼器架構(gòu)(Unified Embedding Decoder Architecture);
方法 B:跨模態(tài)注意架構(gòu)(Cross-modality Attention Architecture approach)。
(順便說一句,Sebastian認(rèn)為這些技術(shù)目前還沒有正式的術(shù)語,但如果您遇到過,請告訴他。例如,更簡短的描述可能是“僅解碼器(Decoder-Only)”和“基于交叉注意(Cross-Attention-Based)”)
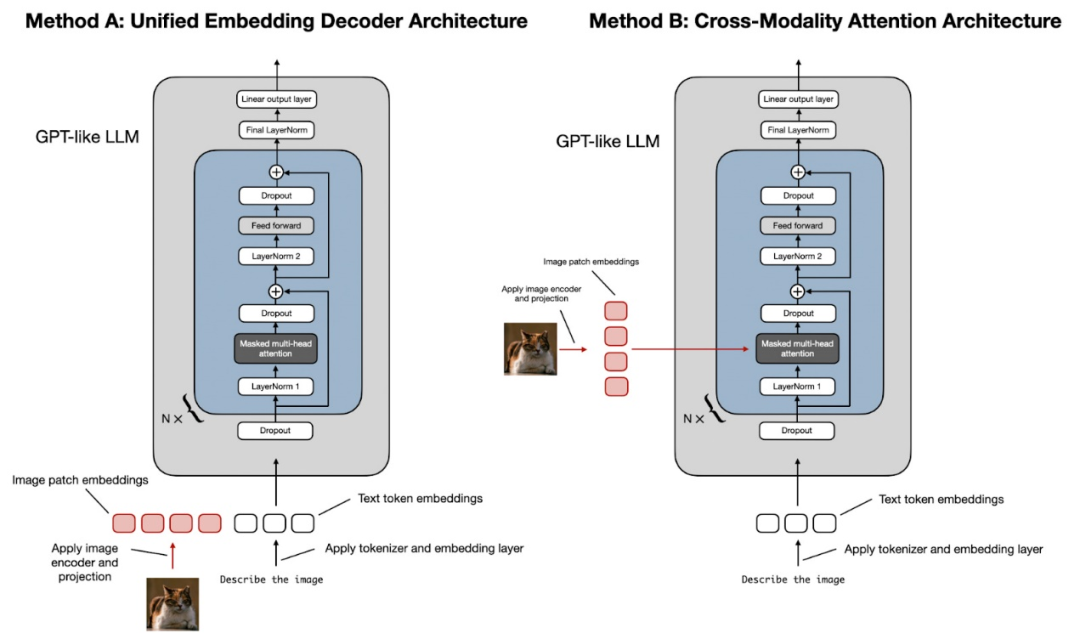
如上圖所示,統(tǒng)一嵌入解碼器架構(gòu)使用單個(gè)解碼器模型,與僅解碼器(Decoder-Only)的 LLM 架構(gòu)(如 GPT-2 或 Llama 3.2)非常相似。在這種方法中,圖像被轉(zhuǎn)換為與原始文本分詞(本文將大語言模型語境下的Token,統(tǒng)一翻譯為分詞)具有相同嵌入大小的分詞,從而允許 LLM 在連接后同時(shí)處理文本和圖像輸入分詞。
跨模態(tài)注意架構(gòu)采用交叉注意機(jī)制,將圖像和文本嵌入直接集成到注意層中。
三,統(tǒng)一嵌入解碼器架構(gòu)
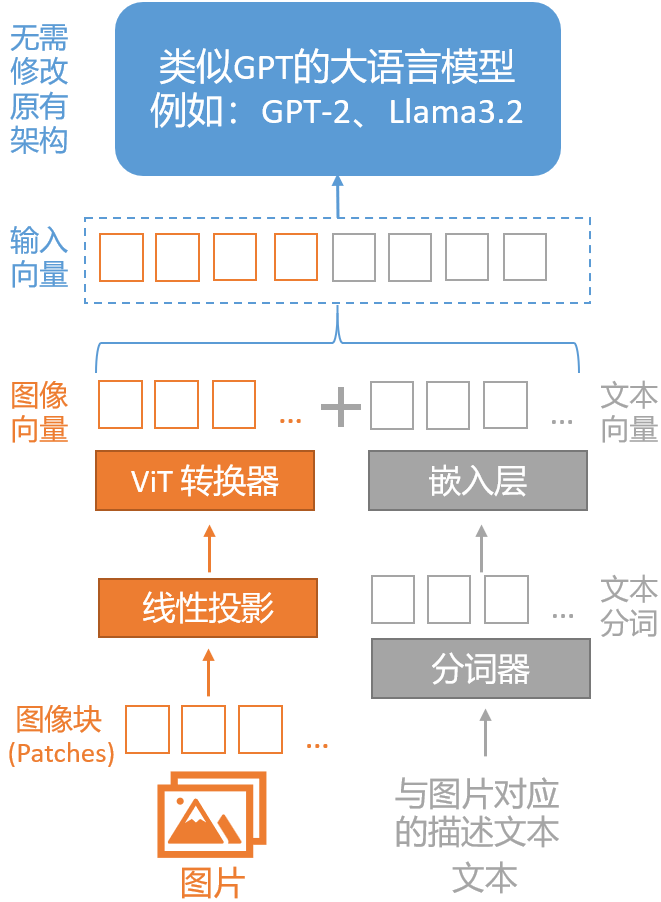
統(tǒng)一嵌入解碼器架構(gòu)是一種將圖像向量和文本向量組合成嵌入向量后輸入給大語言模型的架構(gòu),其優(yōu)點(diǎn)是:無需修改原有的大語言模型架構(gòu)。
在統(tǒng)一嵌入解碼器架構(gòu)中,圖像跟文本一樣,先被轉(zhuǎn)換為分詞(Token),然后被轉(zhuǎn)換為嵌入向量,最后跟文本嵌入向量一起,送入原來的大語言模型進(jìn)行訓(xùn)練或推理。
1,文本向量化
自然語言本文在輸入大語言模型前,會先經(jīng)過分詞器(Tokenizer)變成分詞,然后經(jīng)過嵌入層變成向量。

自然語言是非常高維的數(shù)據(jù),因?yàn)槊總€(gè)可能的單詞都被視為一個(gè)特征。通過分詞化,可以將文本映射到一個(gè)固定大小的向量空間中(例如,GPT2模型用的分詞器算法是BPE,詞匯表大小是50,257),這有助于減少數(shù)據(jù)的維度,使得模型訓(xùn)練更加高效。
分詞數(shù)據(jù)經(jīng)過嵌入層(Embedding Layer)轉(zhuǎn)換成向量數(shù)據(jù)后,方便模型進(jìn)行特征提取、捕捉豐富的語義信息和上下文關(guān)系,并提高模型的性能和計(jì)算效率。
將自然語言文本分詞化和向量化已經(jīng)成為Transformer架構(gòu)模型的標(biāo)準(zhǔn)數(shù)據(jù)預(yù)處理步驟。
2,圖像向量化
類似于文本的分詞化和向量化,圖像的向量化是通過圖像編碼器模塊(而不是分詞器)實(shí)現(xiàn)的。原始圖像首先會被分割成更小的塊(patches),這與分詞器(Tokenizer)將自然語言的單詞(Word)拆成分詞(Token)類似。
隨后,圖像編碼器會把這些塊由線性投影(Linear Projection)模塊和預(yù)訓(xùn)練視覺轉(zhuǎn)換器(Vision Transformer)進(jìn)行編碼,最終轉(zhuǎn)換成向量,其大小與文本向量相同。
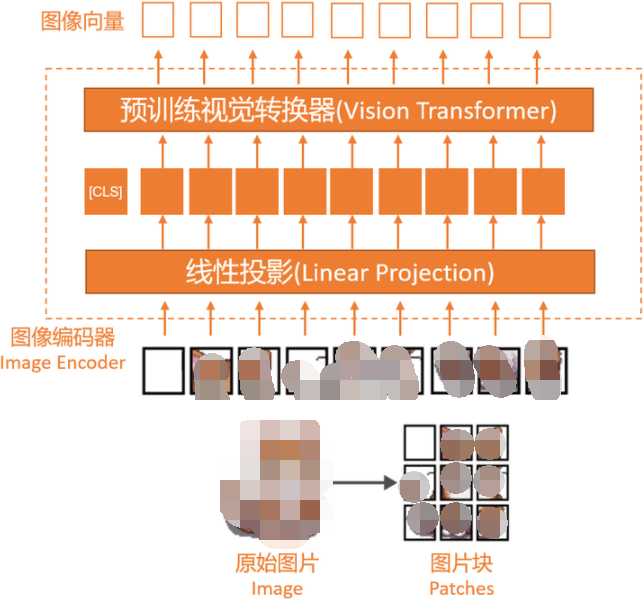
上圖中的“線性投影”由一個(gè)單一的線性層(即全連接層)組成,這個(gè)層的目的是將被展平為向量的圖像塊投影到與變換器編碼器兼容的嵌入尺寸。
當(dāng)前普遍使用的視覺變換器是CLIP或OpenCLIP等,負(fù)責(zé)把展平的圖像塊變換為圖像向量。由于圖像塊向量具有與文本分詞向量相同的向量維度,我們可以簡單地將它們串聯(lián)起來作為大語言模型的輸入,如本節(jié)開頭的圖片所示。
到此,統(tǒng)一嵌入解碼器架構(gòu)(Unified Embedding Decoder Architecture)介紹完畢。
下一篇文章,我們將繼續(xù)介紹:跨模態(tài)注意架構(gòu)(Cross-modality Attention Architecture approach)。
如果你有更好的文章,歡迎投稿!
稿件接收郵箱:nami.liu@pasuntech.com
更多精彩內(nèi)容請關(guān)注“算力魔方?”!
審核編輯 黃宇
-
語言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10710
發(fā)布評論請先 登錄
如何利用LLM做多模態(tài)任務(wù)?
VisCPM:邁向多語言多模態(tài)大模型時(shí)代

更強(qiáng)更通用:智源「悟道3.0」Emu多模態(tài)大模型開源,在多模態(tài)序列中「補(bǔ)全一切」

中科大&字節(jié)提出UniDoc:統(tǒng)一的面向文字場景的多模態(tài)大模型
DreamLLM:多功能多模態(tài)大型語言模型,你的DreamLLM~

探究編輯多模態(tài)大語言模型的可行性
機(jī)器人基于開源的多模態(tài)語言視覺大模型

韓國Kakao宣布開發(fā)多模態(tài)大語言模型“蜜蜂”
利用OpenVINO部署Qwen2多模態(tài)模型
一文理解多模態(tài)大語言模型——下


海康威視發(fā)布多模態(tài)大模型文搜存儲系列產(chǎn)品
商湯“日日新”融合大模型登頂大語言與多模態(tài)雙榜單
百度發(fā)布文心大模型4.5和文心大模型X1
基于MindSpeed MM玩轉(zhuǎn)Qwen2.5VL多模態(tài)理解模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論