") VisCPM:邁向多語言多模態(tài)大模型時代
VisCPM:邁向多語言多模態(tài)大模型時代
隨著 GPT-4 和 Stable Diffusion 等模型多模態(tài)能力的突飛猛進,多模態(tài)大模型已經(jīng)成為大模型邁向通用人工智能(AGI)目標(biāo)的下一個前沿焦點。總體而言,面向圖像和文本的多模態(tài)生成能力可以大致分為兩類:
1. 在圖生文(image-to-text generation)方面,以 GPT-4 為代表的多模態(tài)大模型,可以面向圖像進行開放域?qū)υ捄蜕疃韧评恚?/span>
2. 在文生圖(text-to-image generation)方面,以 Stable Diffusion 為代表的多模態(tài)模型,可以根據(jù)文本生成圖像內(nèi)容。由這些多模態(tài)模型掀起的 AIGC 浪潮,廣泛而深刻地改變著學(xué)術(shù)界和工業(yè)界的思想實踐。
然而,目前多模態(tài)大模型的成功很大程度上局限于英文世界,而中文等其他非英語語言的多模態(tài)能力明顯落后。這是因為相比于英文世界,中文等其他非英語語言的多模態(tài)數(shù)據(jù)嚴重稀缺,難以滿足多模態(tài)大模型對大規(guī)模高質(zhì)量圖文對數(shù)據(jù)的需求。這些問題使得多語言多模態(tài)大模型的構(gòu)建極具挑戰(zhàn)性。
為了解決上述挑戰(zhàn),我們提出使用高資源語言(如英語)作為橋接圖像信號和低資源語言(如中文)的橋梁,實現(xiàn)多語言多模態(tài)大模型能力的快速泛化,從而緩解對低資源語言下模態(tài)對齊數(shù)據(jù)(圖文對數(shù)據(jù))的依賴。
通過類比人類的學(xué)習(xí)過程,我們可以直觀地理解該方法:人類學(xué)習(xí)者可以僅通過母語與視覺信號的對應(yīng)關(guān)系,以及母語與不同語言之間的對應(yīng)關(guān)系,自然地建立起不同語言下對視覺信號的統(tǒng)一認知。這是由于不同的自然語言符號系統(tǒng),很大程度上都是以描述相同的客觀世界為驅(qū)動力演化發(fā)展而來的,這為多語言多模態(tài)能力的快速泛化提供了基礎(chǔ)。
為了驗證上述方法,我們以中英雙語的多模態(tài)大模型為例,構(gòu)建了 VisCPM 系列模型,建立中英雙語的多模態(tài)對話能力(VisCPM-Chat 模型)和文到圖生成能力(VisCPM-Paint 模型)。
在多語言對齊方面,我們選用百億參數(shù)量的 CPM-Bee 10B 作為基底語言模型。該模型優(yōu)秀的中英雙語能力,提供了多語言對齊的基礎(chǔ)。在多模態(tài)對齊方面,我們?yōu)镃PM-Bee分別融合視覺編碼器(Q-Former)和視覺解碼器(Diffusion-UNet)以支持視覺信號的輸入和輸出。得益于 CPM-Bee 基座優(yōu)秀的雙語能力,VisCPM 可以僅通過英文多模態(tài)數(shù)據(jù)預(yù)訓(xùn)練,泛化實現(xiàn)優(yōu)秀的中文多模態(tài)能力。

中英雙語多模態(tài)對話模型VisCPM-Chat
VisCPM-Chat 模型使用 Q-Former 作為視覺編碼器,使用 CPM-Bee(10B)作為語言基座模型,并通過語言建模訓(xùn)練目標(biāo)融合視覺和語言模型。模型訓(xùn)練包括預(yù)訓(xùn)練和指令精調(diào)兩階段:
-
預(yù)訓(xùn)練:我們使用約 100M 高質(zhì)量英文圖文對數(shù)據(jù)對 VisCPM-Chat 進行了預(yù)訓(xùn)練,數(shù)據(jù)包括 CC3M、CC12M、COCO、Visual Genome、LAION 等。在預(yù)訓(xùn)練階段,語言模型參數(shù)保持固定,僅更新Q-Former部分參數(shù),以支持大規(guī)模視覺-語言表示的高效對齊。
- 指令精調(diào):我們采用 LLaVA-150K 英文指令精調(diào)數(shù)據(jù),并混合相應(yīng)翻譯后的中文數(shù)據(jù)對模型進行指令精調(diào),以對齊模型多模態(tài)基礎(chǔ)能力和用戶使用意圖。在指令精調(diào)階段,我們更新全部模型參數(shù),以提升指令精調(diào)數(shù)據(jù)的利用效率。有趣的是,我們發(fā)現(xiàn)即使僅采用英文指令數(shù)據(jù)進行指令精調(diào),模型也可以理解中文問題,但僅能用英文回答。這表明模型的多語言多模態(tài)能力已經(jīng)得到良好的泛化。在指令精調(diào)階段進一步加入少量中文翻譯數(shù)據(jù),可以將模型回復(fù)語言和用戶問題語言對齊。
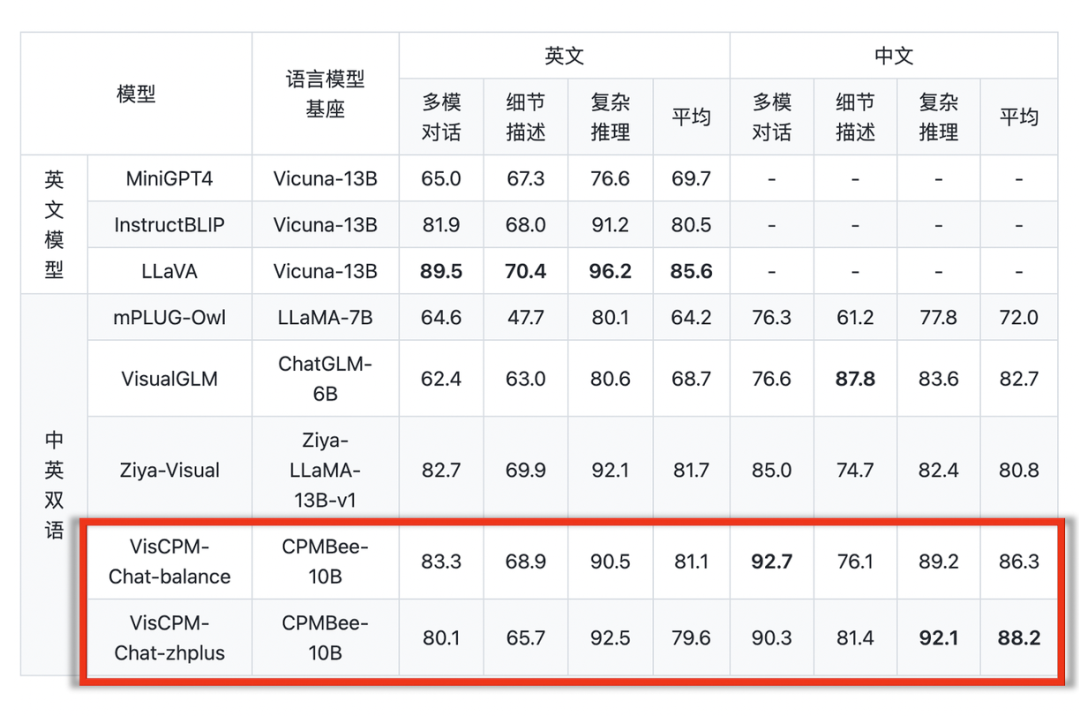
我們在 LLaVA 標(biāo)準(zhǔn)英文測試集和翻譯的中文測試集對模型進行了評測,該評測基準(zhǔn)考察模型在開放域?qū)υ挕D像細節(jié)描述、復(fù)雜推理方面的表現(xiàn),并使用 GPT-4 進行打分。可以觀察到,在不使用任何中文圖文對預(yù)訓(xùn)練數(shù)據(jù)的情況下,VisCPM-Chat 在中文多模態(tài)能力方面取得了最佳的平均性能,在通用域?qū)υ捄蛷?fù)雜推理表現(xiàn)出色,同時也表現(xiàn)出了不錯的英文多模態(tài)能力。
在上述平衡的中英雙語能力(VisCPM-Chat-balance)基礎(chǔ)上,我們在預(yù)訓(xùn)練階段額外加入 20M 清洗后的原生中文圖文對數(shù)據(jù)和 120M 翻譯到中文的圖文對數(shù)據(jù),可以實現(xiàn)中文多模態(tài)能力的進一步強化(VisCPM-Chat-zhplus)。
VisCPM-Chat 表現(xiàn)出令人印象深刻的圖像理解能力,并能夠在對話中運用世界知識和常識知識。例如在下圖中,VisCPM 能夠識別染色的地圖和人像,并正確理解出染色代表的不同含義。除此之外,VisCPM-Chat 還具有不錯的中文特色能力,比如能用李白的詩描繪黃河的景象并作解讀,在面對中秋月夜時還能用蘇軾的《水調(diào)歌頭》借景抒情。

中英雙語文生圖模型VisCPM-Paint
VisCPM-Paint 使用 CPM-Bee(10B)作為文本編碼器,使用 UNet 作為圖像解碼器,并通過擴散模型訓(xùn)練目標(biāo)融合語言和視覺模型。在訓(xùn)練過程中,語言模型參數(shù)始終保持固定。我們使用 Stable Diffusion 2.1 的 UNet 參數(shù)初始化視覺解碼器,并通過逐步解凍其中關(guān)鍵的橋接參數(shù)將其與語言模型融合。該模型在 LAION 2B 英文圖文對數(shù)據(jù)上進行了訓(xùn)練。
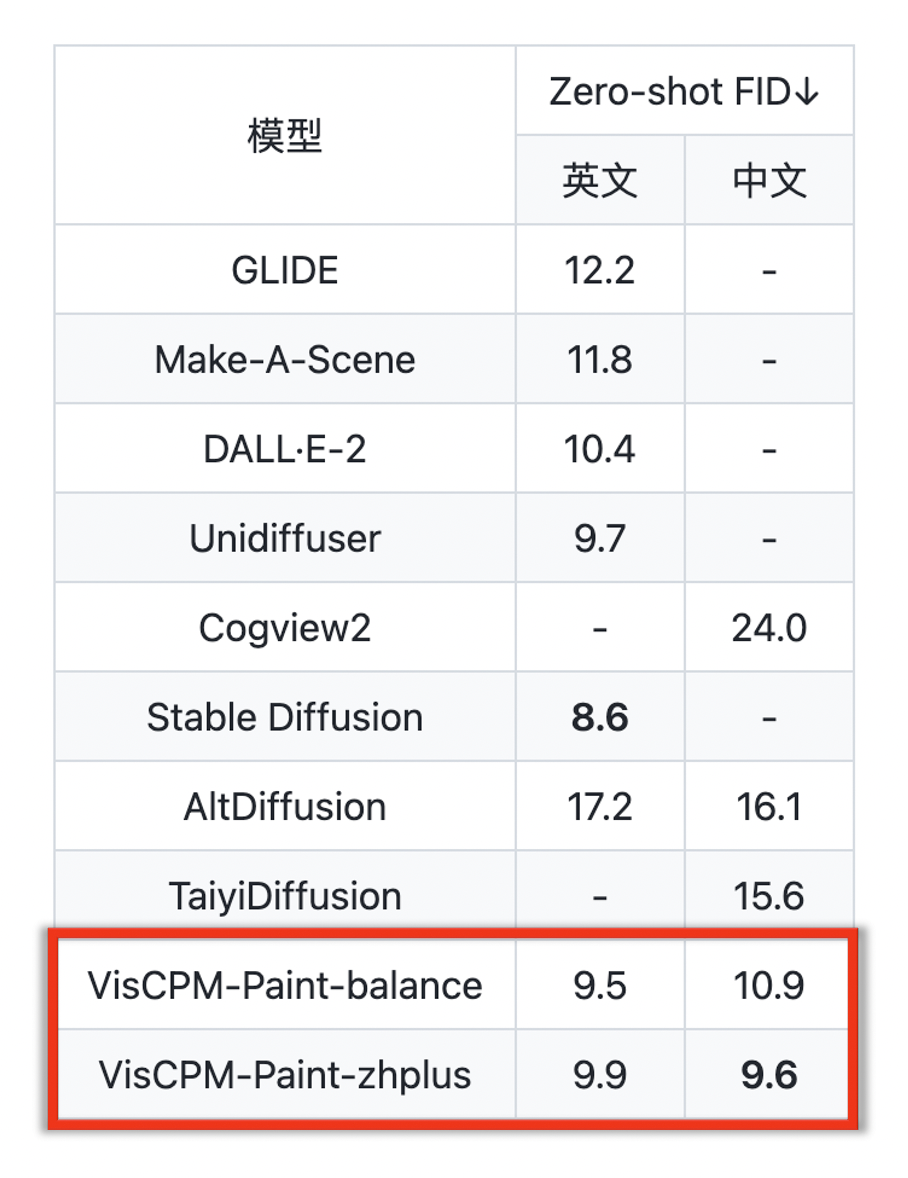
我們在標(biāo)準(zhǔn)圖像生成測試集 MSCOCO 上采樣了 3 萬張圖片,計算了常用評估圖像生成指標(biāo) FID(Fréchet Inception Distance)評估生成圖片的質(zhì)量。與 VisCPM 類似,我們發(fā)現(xiàn)得益于 CPM-Bee 的雙語能力,VisCPM-Paint 可以僅通過英文圖文對訓(xùn)練,泛化實現(xiàn)良好的中文文到圖生成能力,達到中文開源模型的最佳效果。在中英平衡能力(VisCPM-Paint-balance)的基礎(chǔ)上,通過進一步加入 20M 清洗后的原生中文圖文對數(shù)據(jù),以及 120M 翻譯到中文的圖文對數(shù)據(jù),模型的中文文到圖生成能力可以獲得進一步提升(VisCPM-Paint-zhplus)。
VisCPM-Paint 模型中分別輸入“海上生明月,天涯共此時,唯美風(fēng)格,抽象風(fēng)格”和“人閑桂花落,月靜春山空”兩條 prompts,生成了以下兩張圖片。可以看出,VisCPM-Paint 對中國特色意向也有較好的把握能力。
為了推動多模態(tài)大模型開源社區(qū)和相關(guān)研究領(lǐng)域的發(fā)展,我們將 VisCPM 系列的所有模型免費開源(https://github.com/OpenBMB/VisCPM),歡迎個人和研究用途自由使用。未來我們也會將 VisCPM 整合到 huggingface代碼框架中,以及陸續(xù)完善安全模型、 支持快速網(wǎng)頁部署、 支持模型量化功能、支持模型微調(diào)等功能,歡迎持續(xù)關(guān)注。
· ·
原文標(biāo)題:VisCPM:邁向多語言多模態(tài)大模型時代
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2928文章
46016瀏覽量
389383
原文標(biāo)題:VisCPM:邁向多語言多模態(tài)大模型時代
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

基于MindSpeed MM玩轉(zhuǎn)Qwen2.5VL多模態(tài)理解模型

移遠通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗

移遠通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗

商湯“日日新”融合大模型登頂大語言與多模態(tài)雙榜單
?VLM(視覺語言模型)?詳細解析

海康威視發(fā)布多模態(tài)大模型文搜存儲系列產(chǎn)品

商湯日日新多模態(tài)大模型權(quán)威評測第一
一文理解多模態(tài)大語言模型——下

一文理解多模態(tài)大語言模型——上






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論