 一些常見的圖像分類任務中 額外支持的8種數據增廣方法
一些常見的圖像分類任務中 額外支持的8種數據增廣方法

如果要把深度學習開發過程中幾個環節按重要程度排個序的話,相信準備訓練數據肯定能排在前幾位。要知道一個模型網絡被編寫出來后,也只是一坨代碼而已,和智能基本不沾邊,它只有通過學習大量的數據,才能學會如何作推理。因此訓練數據其實和一樣東西非常像!——武俠小說中的神功秘笈,學之前菜鳥一只,學之后一統江湖!
但很可惜的是,訓練數據和秘笈還有一個特點很相似,那就是可遇而不可求!也就是說很難獲取,除了那些公共數據集之外,如果用戶想基于自己的業務場景準備數據的話,不僅數據的生產和標注過程會比較復雜,而且一般需要的數量規模也會非常龐大,因為只有充足的數據,才能確保模型訓練的效果,這導致數據集的制作成本往往非常高。這個情況在計算機視覺領域尤甚,因為圖像要一張一張拍攝與標注,要是搞個幾十萬圖片,想想都讓人“不寒而栗”! 為了應對上述問題,在計算機視覺領域中,圖像數據增廣是一種常用的解決方法,常用于數據量不足或者模型參數較多的場景。如果用戶手中數據有限的話,則可以使用數據增廣的方法擴充數據集。一些常見的圖像分類任務中,例如ImageNet一千種物體分類,在預處理階段會使用一些標準的數據增廣方法,包括隨機裁剪和翻轉。除了這些標準的數據增廣方法之外,飛槳的圖像分類套件PaddleClas還會額外支持8種數據增廣方法,下面將為大家逐一講解。
下文所有的代碼都來自PaddleClas:
GitHub 鏈接:
https://github.com/PaddlePaddle/PaddleClas
Gitee 鏈接:
https://gitee.com/paddlepaddle/PaddleClas
8大數據增廣方法
首先咱們先來看看以ImageNet圖像分類任務為代表的標準數據增廣方法,該方法的操作過程可以分為以下幾個步驟:
圖像解碼,也就是將圖像轉為Numpy格式的數據,簡寫為 ImageDecode。
圖像隨機裁剪,隨機將圖像的長寬均裁剪為 224 大小,簡寫為 RandCrop。
水平方向隨機翻轉,簡寫為 RandFlip。
圖像數據的歸一化,簡寫為 Normalize。
圖像數據的重排。圖像的數據格式為[H, W, C](即高度、寬度和通道數),而神經網絡使用的訓練數據的格式為[C, H, W],因此需要對圖像數據重新排列,例如[224, 224, 3]變為[3, 224, 224],簡寫為 Transpose。
多幅圖像數據組成 batch 數據,如 BatchSize 個[3, 224, 224]的圖像數據拼組成[batch-size, 3, 224, 224],簡寫為 Batch。
相比于上述標準的圖像增廣方法,研究者也提出了很多改進的圖像增廣策略,這些策略均是在標準增廣方法的不同階段插入一定的操作,基于這些策略操作所處的不同階段,大概分為三類:
圖像變換類:對 RandCrop 后的 224 的圖像進行一些變換,包括AutoAugment和RandAugment。
圖像裁剪類:對Transpose 后的 224 的圖像進行一些裁剪,包括CutOut、RandErasing、HideAndSeek和GridMask。
圖像混疊:對 Batch 后的數據進行混合或疊加,包括Mixup和Cutmix。
PaddleClas中集成了上述所有的數據增廣策略,每種數據增廣策略的參考論文與參考開源代碼均在下面的介紹中列出。下文將介紹這些策略的原理與使用方法,并以下圖為例,對變換后的效果進行可視化。
圖像變換類
通過組合一些圖像增廣的子策略對圖像進行修改和跳轉,這些子策略包括亮度變換、對比度增強、銳化等。基于策略組合的規則不同,可以劃分為AutoAugment和RandAugment兩種方式。
01
AutoAugment
論文地址:
https://arxiv.org/abs/1805.09501v1
不同于常規的人工設計圖像增廣方式,AutoAugment是在一系列圖像增廣子策略的搜索空間中通過搜索算法找到并組合成適合特定數據集的圖像增廣方案。針對ImageNet數據集,最終搜索出來的數據增廣方案包含 25 個子策略組合,每個子策略中都包含兩種變換,針對每幅圖像都隨機的挑選一個子策略組合,然后以一定的概率來決定是否執行子策略中的每種變換。 PaddleClas中AutoAugment的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportImageNetPolicy
fromppcls.data.imaugimporttransform
size=224
#圖像解碼
decode_op=DecodeImage()
#圖像隨機裁剪
resize_op=ResizeImage(size=(size,size))
#使用AutoAugment圖像增廣方法
autoaugment_op=ImageNetPolicy()
ops=[decode_op,resize_op,autoaugment_op]
#圖像路徑
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops) 變換結果如下圖所示。
02
RandAugment
論文地址: https://arxiv.org/pdf/1909.13719.pdf AutoAugment 的搜索方法比較暴力,直接在數據集上搜索針對該數據集的最優策略,計算量會很大。在 RandAugment對應的論文中作者發現,針對越大的模型,越大的數據集,使用 AutoAugment 方式搜索到的增廣方式產生的收益也就越小;而且這種搜索出的最優策略是針對指定數據集的,遷移能力較差,并不太適合遷移到其他數據集上。 在 RandAugment 中,作者提出了一種隨機增廣的方式,不再像 AutoAugment 中那樣使用特定的概率確定是否使用某種子策略,而是所有的子策略都會以同樣的概率被選擇到,論文中的實驗也表明這種數據增廣方式即使在大模型的訓練中也具有很好的效果。 PaddleClas中RandAugment的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportRandAugment
fromppcls.data.imaugimporttransform
size=224
#圖像解碼
decode_op=DecodeImage()
#圖像隨機裁剪
resize_op=ResizeImage(size=(size,size))
#使用RandAugment圖像增廣方法
randaugment_op=RandAugment()
ops=[decode_op,resize_op,randaugment_op]
#圖像路徑
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops) 變換結果如下圖所示。
圖像裁剪類
圖像裁剪類主要是對Transpose 后的 224 的圖像進行一些裁剪,即裁剪掉部分圖像,或者也可以理解為對部分圖像做遮蓋,共有CutOut、RandErasing、HideAndSeek和GridMask四種方法。
03
Cutout
論文地址:
https://arxiv.org/abs/1708.04552
Cutout 可以理解為 Dropout 的一種擴展操作,不同的是 Dropout 是對圖像經過網絡后生成的特征進行遮擋,而 Cutout 是直接對輸入的圖像進行遮擋,相對于Dropout對噪聲的魯棒性更好。作者在論文中也進行了說明,這樣做法有以下兩點優勢:
通過 Cutout 可以模擬真實場景中主體被部分遮擋時的分類場景。
可以促進模型充分利用圖像中更多的內容來進行分類,防止網絡只關注顯著性的圖像區域,從而發生過擬合。
PaddleClas中Cutout的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportCutout
fromppcls.data.imaugimporttransform
size=224
#圖像解碼
decode_op=DecodeImage()
#圖像隨機裁剪
resize_op=ResizeImage(size=(size,size))
#使用Cutout圖像增廣方法
cutout_op=Cutout(n_holes=1,length=112)
ops=[decode_op,resize_op,cutout_op]
#圖像路徑
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops) 裁剪結果如下圖所示:
04
RandomErasing
論文地址:
https://arxiv.org/pdf/1708.04896.pdf
RandomErasing 與 Cutout 方法類似,同樣是為了解決訓練出的模型在有遮擋數據上泛化能力較差的問題,作者在論文中也指出,隨機裁剪的方式與隨機水平翻轉具有一定的互補性。作者也在行人再識別(REID)上驗證了該方法的有效性。與Cutout不同的是,在RandomErasing中,圖片以一定的概率接受該種預處理方法,生成掩碼的尺寸大小與長寬比也是根據預設的超參數隨機生成。 PaddleClas中RandomErasing的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportToCHWImage
fromppcls.data.imaugimportRandomErasing
fromppcls.data.imaugimporttransform
size=224
#圖像解碼
decode_op=DecodeImage()
#圖像隨機裁剪
resize_op=ResizeImage(size=(size,size))
#使用RandomErasing圖像增廣方法
randomerasing_op=RandomErasing()
ops=[decode_op,resize_op,tochw_op,randomerasing_op]
#圖像路徑
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
img=img.transpose((1,2,0)) 裁剪結果如下圖所示。
05
HideAndSeek
論文地址:
https://arxiv.org/pdf/1811.02545.pdf
HideAndSeek方法將圖像分為若干大小相同的區域塊(patch),對于每塊區域,都以一定的概率生成掩碼,如下圖所示,可能是完全遮擋、完全不遮擋或者遮擋部分。
PaddleClas中HideAndSeek的使用方法如下所示: fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportToCHWImage
fromppcls.data.imaugimportHideAndSeek
fromppcls.data.imaugimporttransform
size=224
#圖像解碼
decode_op=DecodeImage()
#圖像隨機裁剪
resize_op=ResizeImage(size=(size,size))
#使用HideAndSeek圖像增廣方法
hide_and_seek_op=HideAndSeek()
ops=[decode_op,resize_op,tochw_op,hide_and_seek_op]
#圖像路徑
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
img=img.transpose((1,2,0)) 裁剪結果如下圖所示。
06
GridMask
論文地址:
https://arxiv.org/abs/2001.04086
作者在論文中指出,之前的圖像裁剪方法存在兩個問題,如下圖所示:
過度刪除區域可能造成目標主體大部分甚至全部被刪除,或者導致上下文信息的丟失,導致增廣后的數據成為噪聲數據;
保留過多的區域,對目標主體及上下文基本產生不了什么影響,失去增廣的意義。
因此如何避免過度刪除或過度保留成為需要解決的核心問題。GridMask是通過生成一個與原圖分辨率相同的掩碼,并將掩碼進行隨機翻轉,與原圖相乘,從而得到增廣后的圖像,通過超參數控制生成的掩碼網格的大小。 在訓練過程中,有兩種以下使用方法:
設置一個概率p,從訓練開始就對圖片以概率p使用GridMask進行增廣。
一開始設置增廣概率為0,隨著迭代輪數增加,對訓練圖片進行GridMask增廣的概率逐漸增大,最后變為p。
論文中表示,經過驗證后,上述第二種方法的訓練效果更好一些。 PaddleClas中GridMask的使用方法如下所示。 fromdata.imaugimportDecodeImage
fromdata.imaugimportResizeImage
fromdata.imaugimportToCHWImage
fromdata.imaugimportGridMask
fromdata.imaugimporttransform
size=224
#圖像解碼
decode_op=DecodeImage()
#圖像隨機裁剪
resize_op=ResizeImage(size=(size,size))
#圖像數據的重排
tochw_op=ToCHWImage()
#使用GridMask圖像增廣方法
gridmask_op=GridMask(d1=96,d2=224,rotate=1,ratio=0.6,mode=1,prob=0.8)
ops=[decode_op,resize_op,tochw_op,gridmask_op]
#圖像路徑
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
img=img.transpose((1,2,0)) 結果如下圖所示:
圖像混疊
前文所述的圖像變換與圖像裁剪都是針對單幅圖像進行的操作,而圖像混疊是對兩幅圖像進行融合,生成一幅圖像,Mixup和Cutmix兩種方法的主要區別為混疊的方式不太一樣。
07
Mixup
論文地址: https://arxiv.org/pdf/1710.09412.pdf Mixup是最先提出的圖像混疊增廣方案,其原理就是直接對兩幅圖的像素以一個隨機的比例進行相加,不僅簡單,而且方便實現,在圖像分類和目標檢測領域上都取得了不錯的效果。為了便于實現,通常只對一個 batch 內的數據進行混疊,在Cutmix中也是如此。 如下是imaug中的實現,需要指出的是,下述實現會出現對同一幅進行相加的情況,也就是最終得到的圖和原圖一樣,隨著 batch-size 的增加這種情況出現的概率也會逐漸減小。 PaddleClas中Mixup的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportToCHWImage
fromppcls.data.imaugimporttransform
fromppcls.data.imaugimportMixupOperator
size=224
#圖像解碼
decode_op=DecodeImage()
#圖像隨機裁剪
resize_op=ResizeImage(size=(size,size))
#圖像數據的重排
tochw_op=ToCHWImage()
#使用HideAndSeek圖像增廣方法
hide_and_seek_op=HideAndSeek()
#使用Mixup圖像增廣方法
mixup_op=MixupOperator()
ops=[decode_op,resize_op,tochw_op]
imgs_dir=“/imgdir/xxx.jpg”#圖像路徑
batch=[]
fnames=os.listdir(imgs_dir)
foridx,finenumerate(fnames):
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
batch.append((img,idx))#fakelabel
new_batch=mixup_op(batch) 混疊結果如下圖所示。
08
Cutmix
論文地址:
https://arxiv.org/pdf/1905.04899v2.pdf
與 Mixup 直接對兩幅圖進行相加不一樣,Cutmix 是從另一幅圖中隨機裁剪出一個 ROI(region of interest, 感興趣區域),然后覆蓋當前圖像中對應的區域,代碼實現如下所示: fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportToCHWImage
fromppcls.data.imaugimporttransform
fromppcls.data.imaugimportCutmixOperator
size=224
#圖像解碼
decode_op=DecodeImage()
#圖像隨機裁剪
resize_op=ResizeImage(size=(size,size))
#圖像數據的重排
tochw_op=ToCHWImage()
#使用HideAndSeek圖像增廣方法
hide_and_seek_op=HideAndSeek()
#使用Cutmix圖像增廣方法
cutmix_op=CutmixOperator()
ops=[decode_op,resize_op,tochw_op]
imgs_dir=“/imgdir/xxx.jpg”#圖像路徑
batch=[]
fnames=os.listdir(imgs_dir)
foridx,finenumerate(fnames):
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
batch.append((img,idx))#fakelabel
new_batch=cutmix_op(batch) 混疊結果如下圖所示:
實驗
經過實驗驗證,在ImageNet1k數據集上基于PaddleClas使用不同數據增廣方式的分類精度如下所示,可見通過數據增廣方式可以有效提升模型的準確率。
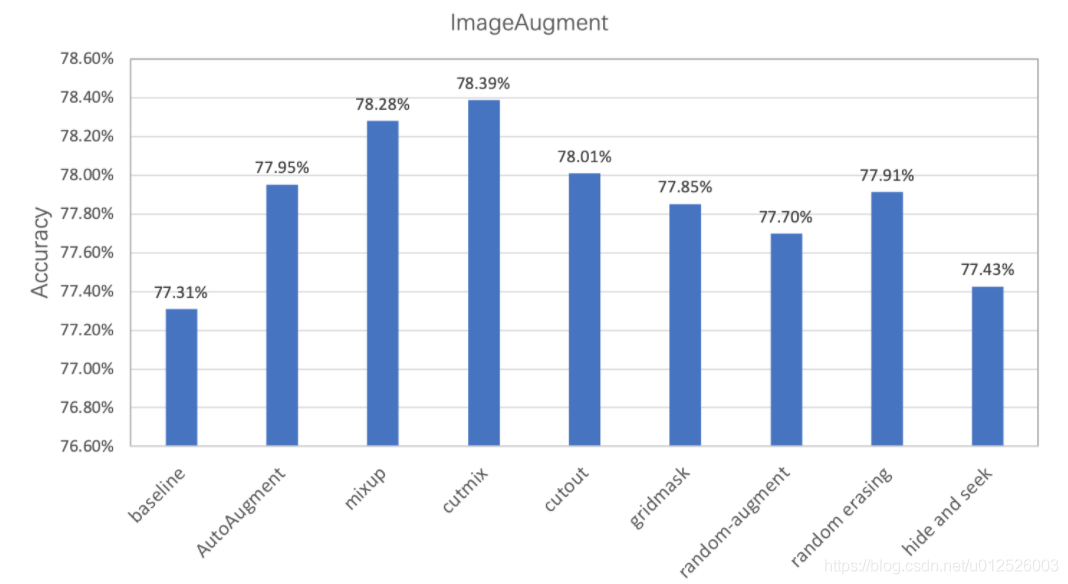
注意: 在這里的實驗中,為了便于對比,將l2 decay固定設置為1e-4,在實際使用中,更小的l2 decay一般效果會更好。結合數據增廣,將l2 decay由1e-4減小為7e-5均能帶來至少0.3~0.5%的精度提升。
PaddleClas數據增廣避坑
指南以及部分注意事項
最后再為大家介紹幾個PaddleClas數據增廣使用方面的小Trick。
在使用圖像混疊類的數據處理時,需要將配置文件中的use_mix設置為True,另外由于圖像混疊時需對label進行混疊,無法計算訓練數據的準確率,所以在訓練過程中沒有打印訓練準確率。
在使用數據增廣后,由于訓練數據更難,所以訓練損失函數可能較大,訓練集的準確率相對較低,但其擁有更好的泛化能力,所以驗證集的準確率相對較高。
在使用數據增廣后,模型可能會趨于欠擬合狀態,建議可以適當的調小l2_decay的值來獲得更高的驗證集準確率。
幾乎每一類圖像增廣均含有超參數,PaddleClas在這里只提供了基于ImageNet-1k的超參數,其他數據集需要用戶自己調試超參數,當然如果對于超參數的含義不太清楚的話,可以閱讀相關的論文,調試方法也可以參考訓練技巧的章節
原文標題:干貨 | 計算機視覺的數據增廣技術大盤點!附漲點神器,已開源!
文章出處:【微信公眾號:機器人創新生態】歡迎添加關注!文章轉載請注明出處。
-
數據
+關注
關注
8文章
7256瀏覽量
91867 -
計算機視覺
+關注
關注
9文章
1709瀏覽量
46778
原文標題:干貨 | 計算機視覺的數據增廣技術大盤點!附漲點神器,已開源!
文章出處:【微信號:robotplaces,微信公眾號:機器人創新生態】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
常見xgboost錯誤及解決方案
xgboost在圖像分類中的應用
傅立葉變換在機器學習中的應用 常見傅立葉變換的誤區解析
Python中dict支持多個key的方法
一些常見的動態電路

主動學習在圖像分類技術中的應用:當前狀態與未來展望

LSTM神經網絡在圖像處理中的應用
分享一些常見的電路





 工商網監
工商網監
評論