") 機器學習模型:感知器的誕生及具體算法
機器學習模型:感知器的誕生及具體算法
各位小伙伴們,又到了喜聞樂見的更新時間,最近猛料不斷,先有Boston動力的“仁義”機器人反恐演習,緊接著MIT的狗狗們在實驗室的綠茵場上集體賣萌,讓我們感慨強人工智能離我們也許不遠了。
作為快要禿頭的我們,又該怎么看待這個快速變化的世界呢?在知識更新越來越快的現(xiàn)在,想要專注于當下似乎都變得艱難。其實柳貓想要告訴大家,作為一個普通人,對各種信息越是了解的多,認識的越是淺薄,為了增強自己的不可替代性,必須增加自己專業(yè)的深度,從一而終。
今天,想跟大家分享一下最早也是最簡單的一個機器學習模型:感知器~
感知器的誕生——從樣本中學習
神經(jīng)網(wǎng)絡(luò)的AI先驅(qū)們一直依靠著神經(jīng)元的繪圖以及它們相互連接的方式,進行著艱難的摸索。康奈爾大學的弗蘭克·羅森布拉特是最早模仿人體自動圖案識別視覺系統(tǒng)架構(gòu)的人之一。
他發(fā)明了一種看似簡單的網(wǎng)絡(luò)感知器(perceptron),這種學習算法可以學習如何將圖案進行分類,例如識別字母表中的不同字母。**算法是為了實現(xiàn)特定目標而按步驟執(zhí)行的過程,**就像烘焙蛋糕的食譜一樣。
如果我們了解了感知器如何學習圖案識別的基本原則,那么在理解深度學習工作原理的路上已經(jīng)成功了一半。感知器的目標是確定輸入的圖案是否屬于圖像中的某一類別(比如貓)。
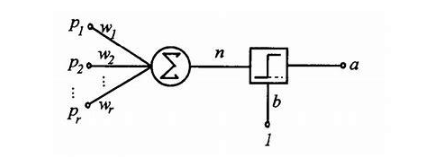
上圖解釋了感知器的輸入如何通過一組權(quán)重,來實現(xiàn)輸入單元到輸出單元的轉(zhuǎn)換。權(quán)重是對每一次輸入對輸出單元做出的最終決定所產(chǎn)生影響的度量,但是我們?nèi)绾握业揭唤M可以將輸入進行正確分類的權(quán)重呢?
解決這個問題的傳統(tǒng)方法,是根據(jù)分析或特定程序來手動設(shè)定權(quán)重。這需要耗費大量人力,而且往往依賴于直覺和工程方法。另一種方法則是使用一種從樣本中學習的自動過程,和我們認識世界上的對象的方法一樣。需要很多樣本來訓練感知器,包括不屬于該類別的反面樣本,特別是和目標特征相似的,例如,如果識別目標是貓,那么狗就是一個相似的反面樣本。這些樣本被逐個傳遞給感知器,如果出現(xiàn)分類錯誤,算法就會自動對權(quán)重進行校正。
感知器具體算法
這種感知器學習算法的美妙之處在于,如果已經(jīng)存在這樣一組權(quán)重,并且有足夠數(shù)量的樣本,那么它肯定能自動地找到一組合適的權(quán)重。在提供了訓練集中的每個樣本,并且將輸出與正確答案進行比較后,感知器會進行遞進式的學習。如果答案是正確的,那么權(quán)重就不會發(fā)生變化。但如果答案不正確(0被誤判成了1,或1被誤判成了0),權(quán)重就會被略微調(diào)整,以便下一次收到相同的輸入時,它會更接近正確答。這種漸進的變化很重要,這樣一來,權(quán)重就能接收來自所有訓練樣本的影響,而不僅僅是最后一個。
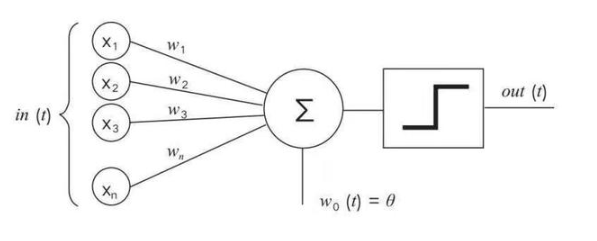
感知器是具有單一人造shen經(jīng)元的神經(jīng)網(wǎng)絡(luò),它有一個輸入層,和將輸入單元和輸出單元相連的一組連接。感知器的目標是對提供給輸入單元的圖案進行分類。輸出單元執(zhí)行的基本操作是,把每個輸入(xn)與其連接強度或權(quán)重(wn)相乘,并將乘積的總和傳遞給輸出單元。上圖中,輸入的加權(quán)和(∑i=1,…,n wi xi)與閾值θ進行比較后的結(jié)果被傳遞給階躍函數(shù)。如果總和超過閾值,則階躍函數(shù)輸出“1”,否則輸出“0”。例如,輸入可以是圖像中像素的強度,或者更常見的情況是,從原始圖像中提取的特征,例如圖像中對象的輪廓。每次輸入一個圖像,感知器會判定該圖像是否為某類別的成員,例如貓類。輸出只能是兩種狀態(tài)之一,如果圖像處于類別中,則為“開”,否則為“關(guān)”。“開”和“關(guān)”分別對應(yīng)二進制值中的1和0。
感知器學習算法可以表達為:
感知器如何區(qū)分兩個對象類別的幾何解釋
如果對感知器學習的這種解釋還不夠清楚,我們還可以通過另一種更簡潔的幾何方法,來理解感知器如何學習對輸入進行分類。對于只有兩個輸入單元的特殊情況,可以在二維圖上用點來表示輸入樣本。每個輸入都是圖中的一個點,而網(wǎng)絡(luò)中的兩個權(quán)重則確定了一條直線。感知器學習的目標是移動這條線,以便清楚地區(qū)分正負樣本。對于有三個輸入單元的情況,輸入空間是三維的,感知器會指定一個平面來分隔正負訓練樣本。在一般的情況下,即使輸入空間的維度可能相當高且無法可視化,同樣的原則依然成立。
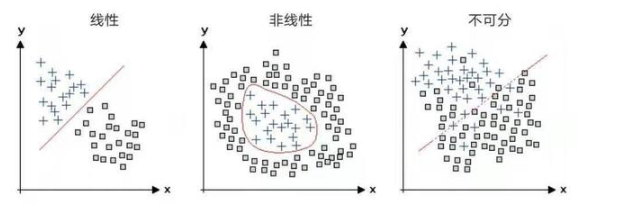
這些對象有兩個特征,例如尺寸和亮度,它們依據(jù)各自的坐標值(x,y)被繪制在每張圖上。左邊圖中的兩種對象(加號和正方形)可以通過它們之間的直線分隔開;感知器能夠?qū)W習如何進行這種區(qū)分。其他兩個圖中的兩種對象不能用直線隔開,但在中間的圖中,兩種對象可以用曲線分開。而右側(cè)圖中的對象必須舍棄一些樣本才能分隔成兩種類型。如果有足夠的訓練數(shù)據(jù),深度學習網(wǎng)絡(luò)就能夠?qū)W習如何對這三個圖中的類型進行區(qū)分。
最終,如果解決方案是可行的,權(quán)重將不再變化,這意味著感知器已經(jīng)正確地將訓練集中的所有樣本進行了分類。
但是,在所謂的“過度擬合”(overfitting)中,也可能沒有足夠的樣本,網(wǎng)絡(luò)僅僅記住了特定的樣本,而不能將結(jié)論推廣到新的樣本。為了避免過度擬合,關(guān)鍵是要有另一套樣本,稱為“測試集”(test set),它沒有被用于訓練網(wǎng)絡(luò)。訓練結(jié)束時,在測試集上的分類表現(xiàn),就是對感知器是否能夠推廣到類別未知的新樣本的真實度量。泛化(generalization)是這里的關(guān)鍵概念。在現(xiàn)實生活中,我們幾乎不會在同樣的視角看到同一個對象,或者反復遇到同樣的場景,但如果我們能夠?qū)⒁郧暗慕?jīng)驗泛化到新的視角或場景中,我們就可以處理更多現(xiàn)實世界的問題。
利用感知器區(qū)分性別
舉一個用感知器解決現(xiàn)實世界問題的例子。想想如果去掉頭發(fā)、首飾和第二性征,比如男性比女性更為突起的喉結(jié),該如何區(qū)分男性和女性的面部。
這張臉屬于男性還是女性?人們通過訓練感知器來辨別男性和女性的面孔。來自面部圖像(上圖)的像素乘以相應(yīng)的權(quán)重(下圖),并將該乘積的總和與閾值進行比較。每個權(quán)重的大小被描繪為不同顏色像素的面積。正值的權(quán)重(白色)表現(xiàn)為男性,負值的權(quán)重(黑色)傾向于女性。鼻子寬度,鼻子和嘴之間區(qū)域的大小,以及眼睛區(qū)域周圍的圖像強度對于區(qū)分男性很重要,而嘴和顴骨周圍的圖像強度對于區(qū)分女性更重要。
區(qū)分男性與女性面部的工作有趣的一點是,雖然我們很擅長做這種區(qū)分,卻無法確切地表述男女面部之間的差異。由于沒有單一特征是決定性的,因此這種模式識別問題要依賴于將大量低級特征的證據(jù)結(jié)合起來。感知器的優(yōu)點在于,權(quán)重提供了對性別區(qū)分最有幫助的面部的線索。令人驚訝的是,人中(即鼻子和嘴唇之間的部分)是最顯著的特征,大多數(shù)男性人中的面積更大。眼睛周圍的區(qū)域(男性較大)和上頰(女性較大)對于性別分類也有著很高的信息價值。感知器會權(quán)衡來自所有這些位置的證據(jù)來做出決定,我們也是這樣來做判定的,盡管我們可能無法描述出到底是怎么做到的。
感知器的擴展
感知器激發(fā)了對高維空間中模式分離的美妙的數(shù)學分析。當那些點存在于有數(shù)千個維度的空間中時,我們就無法依賴在生活的三維空間里對點和點之間距離的直覺。俄羅斯數(shù)學家弗拉基米爾·瓦普尼克(Vladimir Vapnik)在這種分析的基礎(chǔ)上引入了一個分類器,稱為“支持向量機”(Support Vector Machine)。
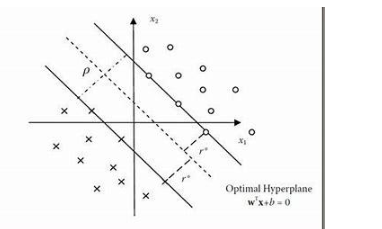
它將感知器泛化,并被大量用于機器學習。他找到了一種自動尋找平面的方法,能夠最大限度地將兩個類別的點分開(線性)。這讓泛化對空間中數(shù)據(jù)點的測量誤差容忍度更大,再結(jié)合作為非線性擴充的“內(nèi)核技巧”(kernel trick),支持向量機算法就成了機器學習中的重要支柱。
總結(jié)——并非萬能的感知器
在感知器中,每個輸入都獨立地向輸出單元提供證據(jù)。但是,如果需要依靠多個輸入的組合來做決定,那會怎樣呢?這就是感知器無法區(qū)分螺旋結(jié)構(gòu)是否相連的原因:單個像素并不能提供它是在內(nèi)部還是外部的位置信息。盡管在多層前饋神經(jīng)網(wǎng)絡(luò)中,可以在輸入和輸出單元之間的中間層中形成多個輸入的組合,但是在20世紀60年代,還沒有人知道如何訓練簡單到中間只有一層“隱藏單元”(hiddenunits)的神經(jīng)網(wǎng)絡(luò)。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102932 -
機器學習
+關(guān)注
關(guān)注
66文章
8493瀏覽量
134174 -
感知器
+關(guān)注
關(guān)注
0文章
34瀏覽量
11972
發(fā)布評論請先 登錄
【「# ROS 2智能機器人開發(fā)實踐」閱讀體驗】視覺實現(xiàn)的基礎(chǔ)算法的應(yīng)用
機器學習模型市場前景如何
【「具身智能機器人系統(tǒng)」閱讀體驗】1.全書概覽與第一章學習
《具身智能機器人系統(tǒng)》第7-9章閱讀心得之具身智能機器人與大模型
NPU與機器學習算法的關(guān)系
AI大模型與深度學習的關(guān)系
AI大模型與傳統(tǒng)機器學習的區(qū)別
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)知識學習
多層感知器的基本原理
多層感知器、全連接網(wǎng)絡(luò)和深度神經(jīng)網(wǎng)絡(luò)介紹
神經(jīng)網(wǎng)絡(luò)算法的結(jié)構(gòu)有哪些類型
機器學習算法原理詳解
機器學習在數(shù)據(jù)分析中的應(yīng)用
深度神經(jīng)網(wǎng)絡(luò)模型有哪些
機器學習的經(jīng)典算法與應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論