") 神經(jīng)網(wǎng)絡加速器架構(gòu)的優(yōu)劣分析
神經(jīng)網(wǎng)絡加速器架構(gòu)的優(yōu)劣分析
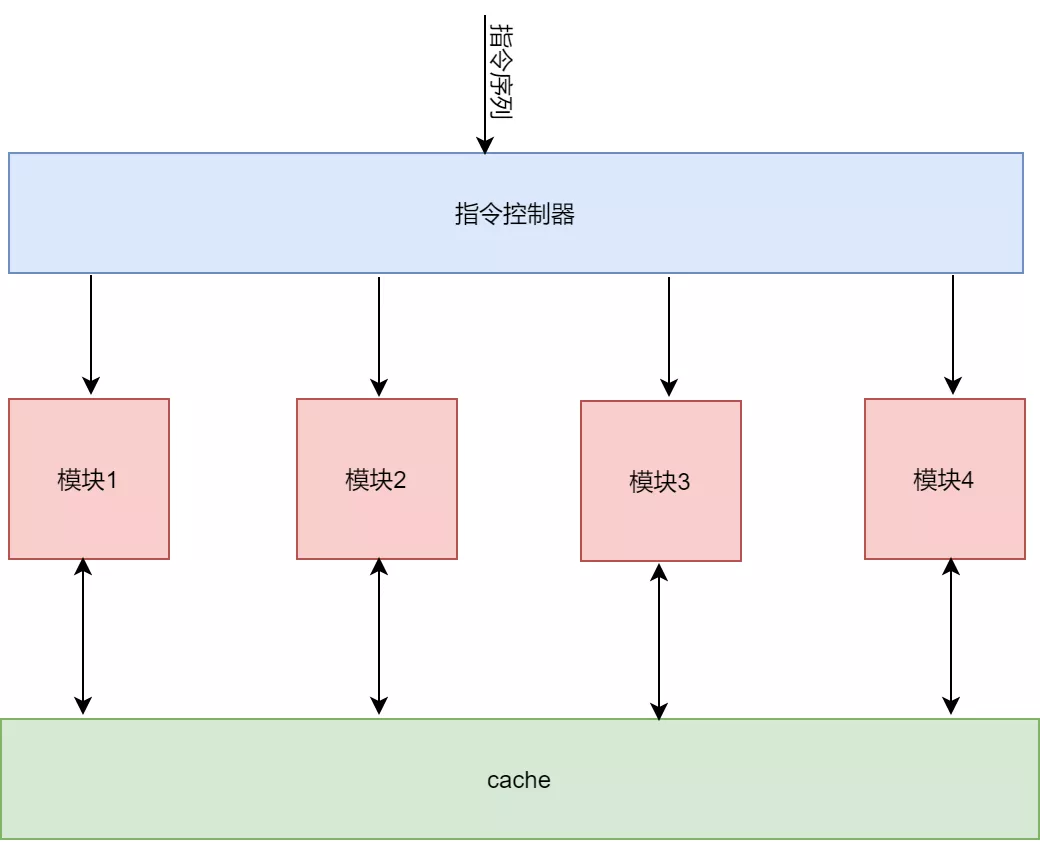
神經(jīng)網(wǎng)絡加速器基本上是一個中介拓撲架構(gòu)的神經(jīng)網(wǎng)絡加速器,其通過指令解析模塊將不同指令分發(fā)到不同的數(shù)據(jù)處理模塊。這些數(shù)據(jù)處理模塊共享片上的存儲。這種結(jié)構(gòu)的優(yōu)點有:
1) 結(jié)構(gòu)簡單,控制起來容易。對應每個數(shù)據(jù)處理模塊都對應一個復雜指令,在進行神經(jīng)網(wǎng)絡加速的時候,只需要根據(jù)神經(jīng)網(wǎng)絡的中的不同數(shù)據(jù)計算部分,提取出可在硬件上進行布置的部分,根據(jù)這部分完成指令編寫。同時一個神經(jīng)網(wǎng)絡的計算流圖決定了不同類型指令之間的依賴關(guān)系。
2) 可擴展性強。數(shù)據(jù)處理模塊可以任意進行擴展,對應著指令集也可以任意增加。每個模塊和指令的接口以及cache的接口形式是一定的,它們之間可以通過cache來進行數(shù)據(jù)交互。指令集和模塊的增加和減少都不會影響到整體架構(gòu)。我們只要開發(fā)出新的模塊IP以及指令就夠了。
我個人認為,目前的架構(gòu)還存在如下缺陷:
1) 架構(gòu)不夠靈活。相對于千變?nèi)f化的神經(jīng)網(wǎng)絡結(jié)構(gòu),其只能加速有限的的計算模塊。而且如果不同神經(jīng)網(wǎng)絡之間進行切換的時候,如果這兩種神經(jīng)網(wǎng)絡差別很大,則可能造成不太好找到一個比較匹配的XRNN結(jié)構(gòu)。比如一個神經(jīng)網(wǎng)絡要用到模塊A,但是另外一個神經(jīng)網(wǎng)絡要用到模塊B,那么我們的架構(gòu)就需要將模塊A和B都加上,這樣才能適合兩種網(wǎng)絡。當然也可以選擇不加,但是終歸是有模塊不能得到充分利用。
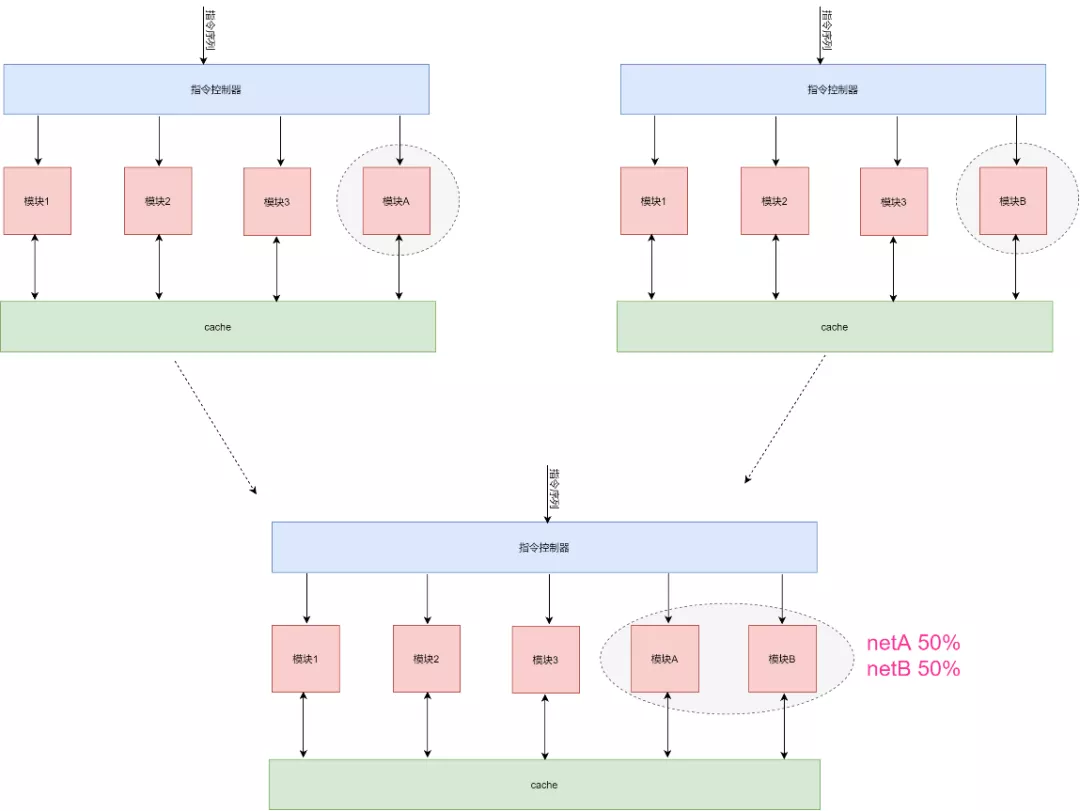
2) 不同數(shù)據(jù)處理模塊之間通過cache進行數(shù)據(jù)交互,以及指令分發(fā)造成了延時。這對于一個大的神經(jīng)網(wǎng)絡來說,這些開銷占比很小,但是當一個神經(jīng)網(wǎng)絡很小,計算復雜的時候,不同模塊之間的數(shù)據(jù)交互就會降低整體效能。

3) 介于AI芯片和GPU之間的尷尬處境。使用FPGA來進行神經(jīng)網(wǎng)絡加速器,和GPU比不過算力,同時又不能像AI芯片那樣具有高速和充足資源的特點。所以針對大計算的網(wǎng)絡,面對GPU我們的性能很難PK過。
4) FPGA的優(yōu)勢沒有顯現(xiàn)出來。可以和GPU等競爭的優(yōu)勢在于FPGA的動態(tài)可重配置以及流水線處理,這些是GPU等芯片不具備的。流水線可以容納更多的計算核,而且能夠減少計算核之間數(shù)據(jù)延時,而可重配置的特點可以更好的適配千變?nèi)f化的神經(jīng)網(wǎng)絡結(jié)構(gòu)。這兩個優(yōu)點在神經(jīng)網(wǎng)絡加速器中也得到了一定的體現(xiàn),比如矩陣乘法核的大小,cache大小都是可配置的。而且不同的計算模塊之間還可以做一定的直連,也能夠降低讀寫cache帶來的延時。但是這些特點還并沒有得到很好的利用。
圖架構(gòu)設想:
對于神經(jīng)網(wǎng)絡加速器,我們總是渴望在FPGA上構(gòu)建一個統(tǒng)一的IP核,能夠盡力去適應不同的神經(jīng)網(wǎng)絡,能夠盡力去加速每個神經(jīng)網(wǎng)絡。于是乎,我們增加了一個個模塊IP,不斷擴充指令集。但是這些都受到了兩個條件的制約:一個是FPGA資源的有限性,另外一個就是神經(jīng)網(wǎng)絡的千變?nèi)f化。如果我們換一種思路,不去追求一種統(tǒng)一的神經(jīng)網(wǎng)絡加速IP,而是基于FPGA可重配置特點構(gòu)建一種平臺,在這個平臺下,可以由用戶根據(jù)需要加速的不同神經(jīng)網(wǎng)絡來自行搭建一套加速器。而我們要做的就是,建立一個IP庫,庫里包含各種計算IP,比如矩陣乘法,向量加法,concat,embedding等等。整個平臺來根據(jù)網(wǎng)絡模型選擇不同IP來構(gòu)建一個神經(jīng)網(wǎng)絡加速器。
基本設想的結(jié)構(gòu)是這樣的:

硬核IP不僅僅包括在FPGA上開發(fā)出的各種計算核,還包含有CPU,因為FPGA資源限制以及計算的復雜性,并不是所有的神經(jīng)網(wǎng)絡計算都可以在FPGA上實現(xiàn)。
軟件根據(jù)網(wǎng)絡模型,分析哪些計算可以用FPGA實現(xiàn),評估其實現(xiàn)性能,選擇最適合在FPGA上進行加速的計算。同時需要評估FPGA資源情況,配置每個核的大小,使用資源等。然后根據(jù)神經(jīng)網(wǎng)絡計算流圖,確定不同IP核的連接關(guān)系,構(gòu)建圖。
圖結(jié)構(gòu)大致設想如下:
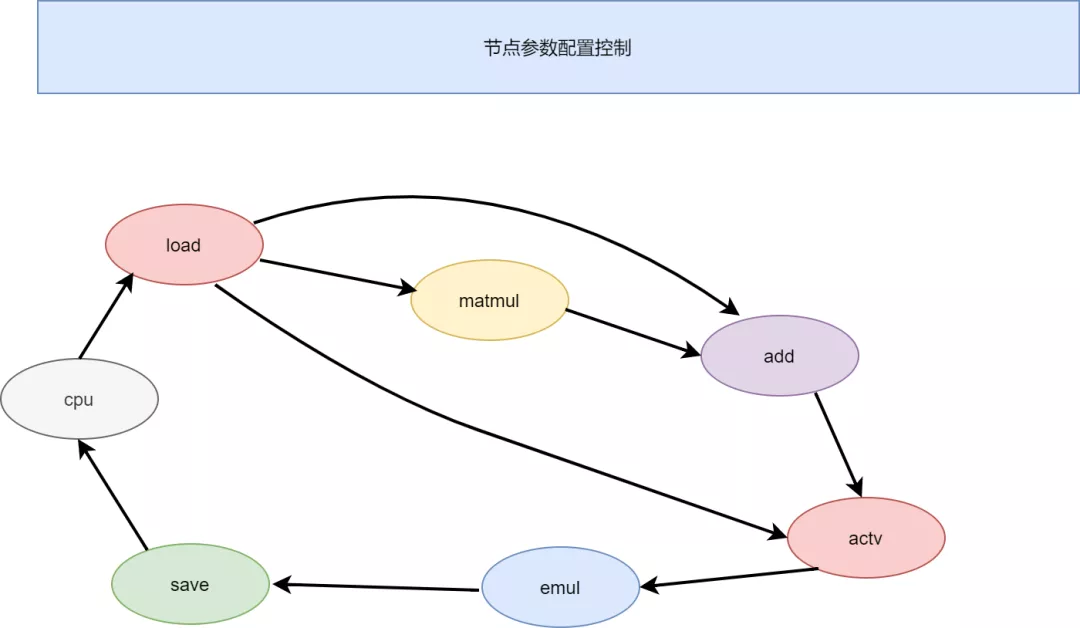
不同節(jié)點代表一個計算模塊,這些模塊之間直接通過數(shù)據(jù)流交互,不經(jīng)過共享內(nèi)存的方式,計算可以實現(xiàn)流水。節(jié)點控制器對每個節(jié)點實現(xiàn)參數(shù)配置,和數(shù)據(jù)流控制,數(shù)據(jù)流控制也很簡單,只需要控制數(shù)據(jù)閘門的開關(guān),以及數(shù)據(jù)量流通的多少就行了。
-
FPGA
+關(guān)注
關(guān)注
1644文章
21989瀏覽量
615234 -
加速器
+關(guān)注
關(guān)注
2文章
825瀏覽量
38981 -
神經(jīng)網(wǎng)絡
+關(guān)注
關(guān)注
42文章
4811瀏覽量
103018
發(fā)布評論請先 登錄
PowerVR Series2NX神經(jīng)網(wǎng)絡加速器設計
張量計算在神經(jīng)網(wǎng)絡加速器中的實現(xiàn)形式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論