") 人工智能引發(fā)的圖像分類算法
人工智能引發(fā)的圖像分類算法
作者:Quenton Hall,賽靈思公司工業(yè)、視覺、醫(yī)療及科學市場的 AI 系統(tǒng)架構(gòu)師
在上一篇文章中,我們簡要介紹了更高層次的問題,這些問題為優(yōu)化加速器的需求奠定了基礎(chǔ)。作為一個尖銳的問題提醒,現(xiàn)在讓我們通過一個非常簡單的圖像分類算法,來看一看與之相關(guān)聯(lián)的計算成本與功耗。
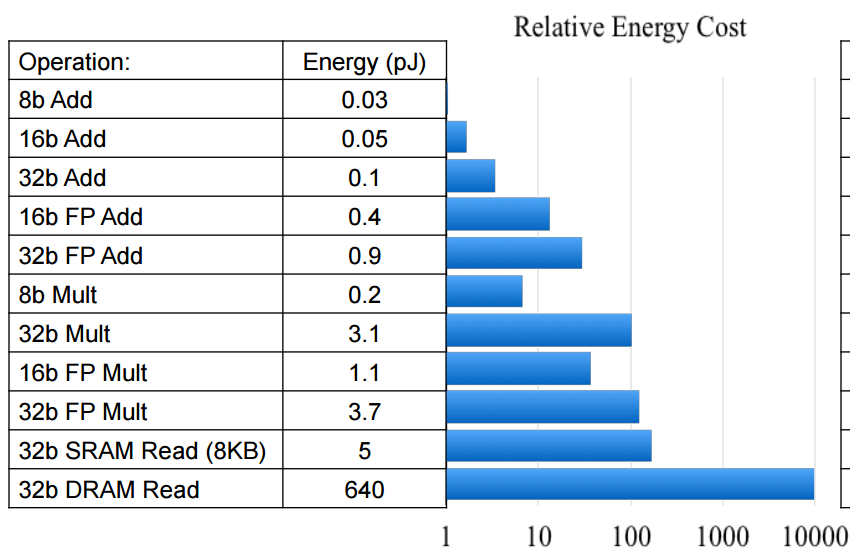
利用 Mark Horowitz 提供的數(shù)據(jù)點,我們可以考慮圖像分類器在不同空間限制下的相對功耗。雖然您會注意到 Mark 的能耗估計是針對 45nm 節(jié)點的,但業(yè)界專家建議,這些數(shù)據(jù)點將繼續(xù)按當前的半導體工藝尺寸進行調(diào)整。也就是說,無論工藝尺寸是 45nm 還是 16nm,與 FP32 運算相比,INT8 運算的能量成本仍然低一個數(shù)量級。
功耗可按以下方式進行計算:
| 功耗 = 能量(J)/運算*運算/s |
從這個等式中我們可以看出,只有兩種方法能夠降低功耗:要么減少執(zhí)行特定運算所需的功耗,要么減少運算的次數(shù),或者一起減少。
對于我們的圖像分類器,我們將選擇ResNet50作為一個目標。ResNet 提供了近乎最先進的圖像分類性能,同時與眾多具有類似性能的可比網(wǎng)絡(luò)相比,它所需的參數(shù)(權(quán)重)更少,這便是它的另一大優(yōu)勢。
為了部署 ResNet50,我們每次推斷必須大約 77 億運算的算力。這意味著,對于每一幅我們想要分類的圖像,我們將產(chǎn)生 7.7 * 10E9 的“計算成本”。
現(xiàn)在,讓我們考慮一個相對高容量的推斷應(yīng)用,在該應(yīng)用中,我們可能希望每秒對 1000 幅圖像進行分類。堅持沿用 Mark 的 45nm 能量估算,我們得出以下結(jié)論:
|
功耗 = 4pJ + 0.4pJ/運算*7.7B運算/圖像 * 1000圖像/s
= 33.88W |
作為創(chuàng)新的第一維度,我們可以將網(wǎng)絡(luò)從 FP32 量化到 8 位整數(shù)運算。這將功耗降低了一個數(shù)量級以上。雖然在訓練期間 FP32 的精度有利于反向傳輸,但它在像素數(shù)據(jù)的推斷時間幾乎沒有創(chuàng)造價值。大量研究和論文已經(jīng)表明,在眾多應(yīng)用中,可以分析每一層的權(quán)重分布并對該分布進行量化,同時將預量化的預測精度保持在非常合理的范圍內(nèi)。
此外,量化研究還表明,8 位整數(shù)值對于像素數(shù)據(jù)來說是很好的“通用”解決方案,并且對于典型網(wǎng)絡(luò)的許多內(nèi)層,可以將其量化到 3-4 位,而在預測精度上損失最小。由 Michaela Blott 領(lǐng)導的賽靈思研究實驗室團隊多年來一直致力于二進制神經(jīng)網(wǎng)絡(luò) (BNN) 的研究與部署,并取得了一些令人矚目的成果。(如需了解更多信息,請查看 FINN 和 PYNQ)
如今,我們與DNNDK的重點是將網(wǎng)絡(luò)推斷量化至 INT8。現(xiàn)代賽靈思 FPGA 中的單個 DSP 片可以在單個時鐘周期內(nèi)計算兩個 8 位乘法運算,這并非巧合。在 16nm UltraScale+ MPSoC 器件系列中,我們擁有超過 15 種不同的器件變型,從數(shù)百個 DSP 片擴展到數(shù)千個 DSP 片,同時保持應(yīng)用和/OS 兼容性。16nm DSP 片的最大 fCLK 峰值為 891MHz。因此,中型 MPSoC 器件是功能強大的計算加速器。
現(xiàn)在,讓我們考慮一下從 FP32 遷移到 INT8 的數(shù)學含義:
|
功耗 = 0.2pJ+0.03pJ/運算*7.7B運算/圖像*1000圖像/s
= 1.771W |
Mark 在演講中,提出了一個解決計算效率問題的方法,那就是使用專門構(gòu)建的專用加速器。他的觀點適用于機器學習推斷。
上述分析沒有考慮到的是,我們還將看到 FP32 的外部 DDR 流量至少減少四倍。正如您可能預料到的那樣,與外部存儲器訪問相關(guān)的功耗成本比內(nèi)部存儲器高得多,這也是事實。如果我們簡單地利用 Mark 的數(shù)據(jù)點,我們會發(fā)現(xiàn)訪問 DRAM 的能量成本大約是 1.3-2.6nJ,而訪問 L1 存儲器的能量成本可能是 10-100pJ。看起來,與訪問內(nèi)部存儲器(如賽靈思 SoC 中發(fā)現(xiàn)的 BlockRAM 和 UltraRAM)的能量成本相比,外部 DRAM 訪問的能量成本至少高出一個數(shù)量級。
除了量化所提供的優(yōu)勢以外,我們還可以使用網(wǎng)絡(luò)剪枝技術(shù)來減少推斷所需的計算工作負載。使用賽靈思Vitis AI 優(yōu)化器工具,可以將在 ILSCVR2012(ImageNet 1000 類)上訓練的圖像分類模型的計算工作負載減少 30-40%,精度損失不到 1%。再者,如果我們減少預測類的數(shù)量,我們可以進一步增加這些性能提升。現(xiàn)實情況是,大多數(shù)現(xiàn)實中的圖像分類網(wǎng)絡(luò)都是在有限數(shù)量的類別上進行訓練的,這使得超出這種水印的剪枝成為可能。作為參考,我們其中一個經(jīng)過剪枝的 VGG-SSD 實現(xiàn)方案在四個類別上進行訓練,需要 17 個 GOP(與原始網(wǎng)絡(luò)需要 117 個 GOP 相比),在精度上沒有損失!誰說 VGG 沒有內(nèi)存效率?
然而,如果我們簡單地假設(shè)我們在 ILSCVR2012 上訓練我們的分類器,我們發(fā)現(xiàn)我們通常可以通過剪枝減少大約 30% 的計算工作負載。考慮到這一點,我們得出以下結(jié)論:
|
功耗 = 0.2pJ+0.03pJ/運算*7.7B運算/圖像0.7*1000圖像/s
= 1.2397W |
將此值與 FP32 推斷的原始估計值 33.88W 進行比較。
雖然這種分析沒有考慮到多種變量(混合因素),但顯然存在一個重要的優(yōu)化機會。因此,當我們繼續(xù)尋找遙遙無期的“解決計算飽和的靈丹妙藥”時,考慮一下吳恩達斷言“AI 是新電能”的背景。我認為他并不是在建議 AI 需要更多的電能,只是想表明 AI 具有極高的價值和巨大的影響力。所以,讓我們對 ML 推斷保持冷靜的頭腦。對待機器學習推斷應(yīng)保持冷靜思考,既不必貿(mào)然跟風,也無需針對高性能推斷設(shè)計采用液態(tài)冷卻散熱。
在本文的第三篇中我們還將就專門構(gòu)建的“高效”神經(jīng)網(wǎng)絡(luò)模型的使用以及如何在賽靈思應(yīng)用中利用它們來實現(xiàn)更大的效率增益進行討論。
-
dsp
+關(guān)注
關(guān)注
555文章
8148瀏覽量
355468 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102901 -
AI
+關(guān)注
關(guān)注
88文章
34391瀏覽量
275634 -
半導體工藝
+關(guān)注
關(guān)注
19文章
107瀏覽量
26599 -
MPSoC
+關(guān)注
關(guān)注
0文章
200瀏覽量
24633
發(fā)布評論請先 登錄
【每天學點AI】實戰(zhàn)圖像增強技術(shù)在人工智能圖像處理中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論