 神經網絡如何識別圖片的內容?
神經網絡如何識別圖片的內容?
向神經網絡展示大量的人和車的圖片,并告知其哪一張是車,哪一張是人,最終,這個神經網絡就可以學會區分人和車。當新輸入一張車或人的圖片時,它會告訴你這是一個人還是一輛汽車。
如圖1.1所示:基本上,這個神經網絡所做的就是構建一個有意義的結構。如果讓這個神經網絡生成一張新的未曾出現過的人或車的照片,它無法做到,如圖1.2所示。
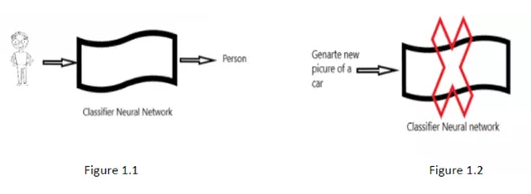
圖1:卷積神經網絡
通常需要生成呈相同輸入分布的新樣本,為此需要一個生成模型。
生成式網絡
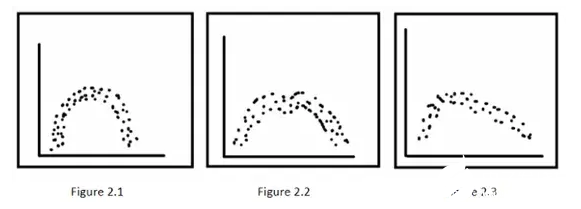
圖2:生成網絡的輸入數據
如果將這三種類型的數據(圖2)輸入到生成網絡,該網絡的學習模型將如圖3所示。當試圖通過這個訓練好的生成式神經網絡生成樣本時,它將生成圖4,因為圖4的模型與以上所有三種輸入分布模型的平均值相似。
但通過觀察,可以清晰地判斷出這個樣本不屬于任何一種已輸入的數據分布類型。該如何解決這個問題呢?答案是隨機性。也就是說,生成模型通過增加隨機性來產生相似度極高的結果。
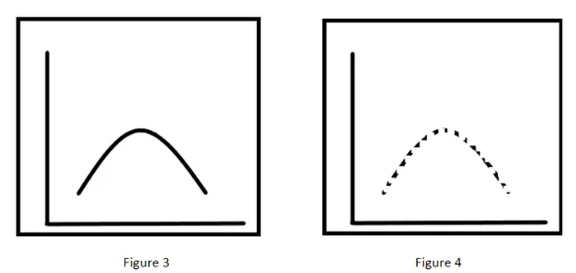
圖3:學習模型;圖4:生成式網絡的輸出結果
對抗性網絡
假設要訓練一個神經網絡來正確識別0到9之間的數字,我們先要提供大量數字的圖像。訓練時,當網絡預測正確時將會得到獎勵,預測錯誤時則會給出反饋,這樣網絡就會相應地調整其權值,并且對所有數字的所有圖像重復這個過程。
但作為人類的我們在歷經這個過程時其實并非如此。如果你是一名教師,正在教一個孩子如何識別0-9。對于數字0,2,3,4,5,6,8,9,他有70%的把握回答出正確答案。但當他得到1和7這兩個數字時,他心中只有50%的把握(他可能無法分辨)。因為對于他來講,數字1和7看起來十分相似。
你注意到了這一點,于是開始重點關注1和7,這是你學生面臨的主要問題。但如果你一直問同樣的問題,他最終會失去動力并放棄,這種平衡在人類身上是很常見的,但神經網絡不是這樣,神經網絡沒有感覺。我們可以就這些錯誤對網絡進行一次又一次的訓練,直到出錯率降到與分辨其他數字的出錯率相同為止。
現實中,有些人可能會遇到這樣的情況:老師不停問他們同樣的問題,他們不斷失敗,甚至會覺得是老師想讓他們失敗。這實際上是一種反向行為。
那么如何在神經網絡中重現類似的場景?實際上,我們可以建立一個真正的對抗性網絡。如果有程序真正使神經網絡盡可能多地犯錯,產生上述那種反應,并且它發現了任何弱點,那么這道程序就會針對性地迫使學習者學會根除這種弱點。
生成式對抗網絡
生成式對抗網絡由兩個模塊組成:一個是生成模型,另一個是判別模型。在訓練生成式對抗網絡時,這兩個網絡實際上是互相博弈的關系,都在競爭唯一的參數——判別模型的錯誤率。生成模型調整其權重以求產生更高的誤差,判別模型通過學習試圖降低誤差。
示例
有一個偽造者試圖造一幅假畫并且將其高價出售。與此同時,有一個檢查員負責檢查并判斷這些畫的真偽。
起初,偽造者只是在紙上隨意畫幾條線,檢查員此時無法確定真假。因為一開始判別模型和生成模型都還沒有進行任何學習。
后來,造假畫者學習了更多不同種類的畫法,制作出一幅看起來像原畫的畫,檢查員也學習精細的圖案來區分贗品和原畫。當檢查偽造者新生成的畫時,檢查員就會識別出畫是贗品然后拒絕它,這個過程會不斷重復。
最終,出現了這樣一種情況:偽造者制作出一張看起來很貼近原畫的圖片,而檢查員無法確定其真偽。這在神經網絡中表現為,生成模型生成一張看起來和原畫一模一樣的圖,而判別模型的輸出為0.5,表示其無法區分圖片的真假。這時可以把判別模型從神經網絡中移除,得到了一個經過充分訓練的生成模型,可以生成看起來非常真實的畫。
除此之外,如果將大量的汽車圖像導入生成式對抗網絡中,以生成一個新的汽車樣本,那么有一點是確定的,那就是生成式對抗網絡此時已了解什么是汽車。
因為網絡將在潛在空間中構造一個結構,這個結構又稱為特征向量,如果觀察這些向量,會發現其意義是完整的。這個潛在空間是輸入數據分布的映射。每一個維度都與汽車的某項特征相對應。如果潛在空間中的一個軸表示的是汽車的尺寸,那么另一個軸就表示汽車的顏色。
所以,如果移動輸入分布中的一個數據點,那么在潛在空間中也會有一個非常平滑的過渡。這樣,一個類似于輸入數據分布的新樣本就產生了。
責編AJX
-
神經網絡
+關注
關注
42文章
4811瀏覽量
103025 -
算法
+關注
關注
23文章
4702瀏覽量
94946 -
圖片
+關注
關注
0文章
203瀏覽量
16191
發布評論請先 登錄





 工商網監
工商網監
評論