 如何訓練和優化神經網絡
如何訓練和優化神經網絡
一、引言
神經網絡是人工智能領域的重要分支,廣泛應用于圖像識別、自然語言處理、語音識別等多個領域。然而,要使神經網絡在實際應用中取得良好效果,必須進行有效的訓練和優化。本文將從神經網絡的訓練過程、常用優化算法、超參數調整以及防止過擬合等方面,詳細闡述如何訓練和優化神經網絡。
二、神經網絡的訓練過程
數據預處理
在訓練神經網絡之前,首先需要對數據進行預處理。數據預處理包括數據清洗、數據增強、數據歸一化等操作。數據清洗旨在去除數據中的噪聲和異常值;數據增強可以通過對原始數據進行變換(如旋轉、縮放、翻轉等)來增加數據的多樣性;數據歸一化則可以將數據縮放到同一尺度上,便于神經網絡的學習。
前向傳播
前向傳播是神經網絡訓練的基礎。在前向傳播過程中,輸入數據經過神經網絡的各個層(包括輸入層、隱藏層和輸出層),逐層計算得到最終的輸出。在前向傳播過程中,每一層的輸出都作為下一層的輸入。通過前向傳播,我們可以得到神經網絡在給定輸入下的預測輸出。
計算損失函數
損失函數用于衡量神經網絡的預測輸出與真實輸出之間的差異。常用的損失函數包括均方誤差(MSE)、交叉熵損失(Cross-Entropy Loss)等。根據具體的任務和數據特點選擇合適的損失函數是訓練神經網絡的關鍵之一。
反向傳播
反向傳播是神經網絡訓練的核心。在反向傳播過程中,我們根據損失函數計算得到的梯度信息,從輸出層開始逐層向前傳播,更新神經網絡中的權重和偏置參數。通過反向傳播,我們可以不斷優化神經網絡的參數,使其更好地擬合訓練數據。
三、常用優化算法
隨機梯度下降(SGD)
隨機梯度下降是最常用的優化算法之一。在SGD中,我們每次從訓練數據中隨機選取一個樣本或一小批樣本,計算其梯度并更新神經網絡參數。SGD具有簡單、高效的特點,但在實際應用中可能面臨收斂速度慢、容易陷入局部最優解等問題。
動量(Momentum)
動量算法在SGD的基礎上引入了動量項,使得參數更新具有一定的慣性。動量算法可以加速SGD的收斂速度,并在一定程度上緩解陷入局部最優解的問題。
Adam優化器
Adam優化器結合了Momentum和RMSprop的思想,通過計算梯度的一階矩估計和二階矩估計來動態調整學習率。Adam優化器具有自適應學習率、收斂速度快等特點,在實際應用中表現出較好的性能。
四、超參數調整
超參數是神經網絡訓練過程中需要手動設置的參數,如學習率、批次大小、迭代次數等。超參數的選擇對神經網絡的性能有著重要影響。常用的超參數調整方法包括網格搜索、隨機搜索和貝葉斯優化等。在調整超參數時,需要根據具體任務和數據特點進行權衡和選擇。
五、防止過擬合
過擬合是神經網絡訓練中常見的問題之一,表現為模型在訓練數據上表現良好,但在測試數據上性能較差。為了防止過擬合,我們可以采取以下措施:
增加訓練數據量:通過增加訓練數據量可以提高模型的泛化能力,減少過擬合現象。
正則化:正則化是一種通過向損失函數中添加懲罰項來限制模型復雜度的方法。常用的正則化方法包括L1正則化、L2正則化和Dropout等。
提前停止:在訓練過程中,當模型在驗證集上的性能開始下降時,提前停止訓練可以防止模型過擬合。
集成學習:集成學習通過將多個模型的預測結果進行組合來降低過擬合風險。常用的集成學習方法包括Bagging和Boosting等。
六、總結與展望
訓練和優化神經網絡是一個復雜而有趣的過程。通過合理的數據預處理、選擇合適的優化算法、調整超參數以及采取防止過擬合的措施,我們可以使神經網絡在實際應用中取得更好的性能。未來,隨著深度學習技術的不斷發展,我們有理由相信神經網絡將在更多領域展現出其強大的潛力。同時,我們也需要關注神經網絡訓練過程中的一些挑戰和問題,如計算資源消耗、模型可解釋性等,為神經網絡的進一步發展提供有力支持。
-
神經網絡
+關注
關注
42文章
4810瀏覽量
102930 -
算法
+關注
關注
23文章
4701瀏覽量
94853 -
人工智能
+關注
關注
1804文章
48788瀏覽量
246957
發布評論請先 登錄
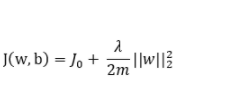
粒子群優化模糊神經網絡在語音識別中的應用
當訓練好的神經網絡用于應用的時候,權值是不是不能變了?
【PYNQ-Z2申請】基于PYNQ的卷積神經網絡加速
【案例分享】ART神經網絡與SOM神經網絡
如何構建神經網絡?
matlab實現神經網絡 精選資料分享
如何進行高效的時序圖神經網絡的訓練
基于粒子群優化的條件概率神經網絡的訓練方法
Kaggle知識點:訓練神經網絡的7個技巧






 工商網監
工商網監
評論