 語義分割算法系統介紹
語義分割算法系統介紹
圖像語義分割是圖像處理和是機器視覺技術中關于圖像理解的重要任務。語義分割即是對圖像中每一個像素點進行分類,確定每個點的類別,從而進行區域劃分,為了能夠幫助大家更好的了解語義分割領域,我們精選知乎文章。作者Xavier CHEN針對語義分割進行系統的介紹,從原理解析到算法發展總結,文章思路清晰,總結全面,推薦大家閱讀。
本文作者為Xavier CHEN,畢業于浙江大學,在知乎持續分享前沿文章。
01
前言
之前做了一個語義分割的綜述報告,現在把報告總結成文章。這篇文章將分為三個部分:
1.語義分割基本介紹:明確語義分割解決的是什么問題。
2.從FCN到Deeplab v3+:解讀語義分割模型的發展,常用方法與技巧
3.代碼實戰中需要注意的問題。
02
語義分割基本介紹
2.1 概念
語義分割(semantic segmentation) : 就是按照“語義”給圖像上目標類別中的每一點打一個標簽,使得不同種類的東西在圖像上被區分開來。可以理解成像素級別的分類任務。
輸入:(H*W*3)就是正常的圖片
輸出:( H*W*class )可以看為圖片上每個點的one-hot表示,每一個channel對應一個class,對每一個pixel位置,都有class數目 個channel,每個channel的值對應那個像素屬于該class的預測概率。
figure1
2.2評價準則
1.像素精度(pixel accuracy ):每一類像素正確分類的個數/ 每一類像素的實際個數。
2.均像素精度(mean pixel accuracy ):每一類像素的精度的平均值。
3.平均交并比(Mean Intersection over Union):求出每一類的IOU取平均值。IOU指的是兩塊區域相交的部分/兩個部分的并集,如figure2中 綠色部分/總面積。
4.權頻交并比(Frequency Weight Intersection over Union):每一類出現的頻率作為權重
figure2
03
從FCN 到Deeplab V3+
語義分割的原理和常用技巧
3.1 FCN
FCN是語義分割的開山之作,主要特色有兩點:
1.全連接層換成卷積層
2.不同尺度的信息融合FCN-8S,16s,32s
看詳細講解 推薦:
https://zhuanlan.zhihu.com/p/30195134
3.1.1 全連接層換成卷積層
figure3
以Alexnet的拓撲結構為例
原本的結構:224大小的圖片經過一系列卷積,得到大小為1/32 = 7的feature map,經過三層全連接層,得到基于FC的分布式表示。
我們把三層全連接層全都換成卷積層,卷積核的大小和個數如下圖中間行所示,我們去掉了全連接層,但是得到了另外一種基于不同channel的分布式表示:Heatmap
舉一個例子,我們有一個大小為384的圖片,經過替換了FC的Alexnet,得到的是6*6*1000的Heatmap,相當于原來的Alexnet 以stride = 32在輸入圖片上滑動,經過上采樣之后,就可以得到粗略的分割結果。
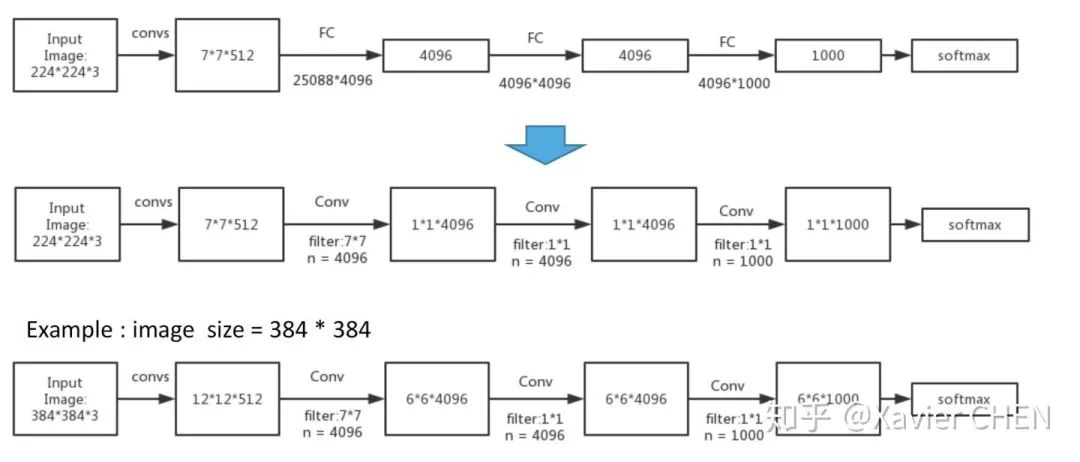
figure4
3.1.2 不同尺度的信息融合
就像剛剛舉的Alexnet的例子,對于任何的分類神經網絡我們都可以用卷積層替換FC層,只是換了一種信息的分布式表示。如果我們直接把Heatmap上采樣,就得到FCN-32s。如下圖
figure5
但是我們知道,隨著一次次的池化,雖然感受野不斷增大,語義信息不斷增強。但是池化造成了像素位置信息的丟失:直觀舉例,1/32大小的Heatmap上采樣到原圖之后,在Heatmap上如果偏移一個像素,在原圖就偏移32個像素,這是不能容忍的。
見figure6,前面的層雖然語義信息較少,但是位置信息較多,作者就把1/8 1/16 1/32的三個層的輸出融合起來了。先把1/32的輸出上采樣到1/16,和Pool4的輸出做elementwose addition , 結果再上采樣到1/8,和Pool3的輸出各個元素相加。得到1/8的結果,上采樣8倍,求Loss。
figure6
3.2 U-net
figure7
U-net用于解決小樣本的簡單問題分割,比如醫療影片的分割。它遵循的基本原理與FCN一樣:
1.Encoder-Decoder結構:前半部分為多層卷積池化,不斷擴大感受野,用于提取特征。后半部分上采樣回復圖片尺寸。
2.更豐富的信息融合:如灰色剪頭,更多的前后層之間的信息融合。這里是把前面層的輸出和后面層concat(串聯)到一起,區別于FCN的逐元素加和。不同Feature map串聯到一起后,后面接卷積層,可以讓卷積核在channel上自己做出選擇。注意的是,在串聯之前,需要把前層的feature map crop到和后層一樣的大小。
3.3 SegNet
figure 8
在結構上看,SegNet和U-net其實大同小異,都是編碼-解碼結果。區別在意,SegNet沒有直接融合不同尺度的層的信息,為了解決為止信息丟失的問題,SegNet使用了帶有坐標(index)的池化。如下圖所示,在Max pooling時,選擇最大像素的同時,記錄下該像素在Feature map的位置(左圖)。在反池化的時候,根據記錄的坐標,把最大值復原到原來對應的位置,其他的位置補零(右圖)。后面的卷積可以把0的元素給填上。這樣一來,就解決了由于多次池化造成的位置信息的丟失。
figure 9
3.4 Deeplab V1
figure10
這篇論文不同于之前的思路,他的特色有兩點:
1.由于Pooling-Upsample會丟失位置信息而且多層上下采樣開銷較大,把控制感受野大小的方法化成:帶孔卷積(Atrous conv)
2.加入CRF(條件隨機場),利用像素之間的關連信息:相鄰的像素,或者顏色相近的像素有更大的可能屬于同一個class。
3.4.1 Atrous Conv
如右下圖片所示,一個擴張率為2的帶孔卷積接在一個擴張率為1的正常卷積后面,可以達到大小為7的感受野,但是輸出的大小并沒有減小,參數量也沒有增大。
figure 11
3.4.2 條件隨機場CRF
figure 12
3.5 PSPnet
figure13
原理都大同小異,前面的不同level的信息融合都是融合淺層和后層的Feature Map,因為后層的感受野大,語義特征強,淺層的感受野小,局部特征明顯且位置信息豐富。
PSPnet則使用了空間金字塔池化,得到一組感受野大小不同的feature map,將這些感受野不同的map concat到一起,完成多層次的語義特征融合。
3.6 Deeplab V2
figure 14
Deeplab v2在v1的基礎上做出了改進,引入了ASPP(Atrous Spatial Pyramid Pooling)的結構,如上圖所示。我們注意到,Deeplab v1使用帶孔卷積擴大感受野之后,沒有融合不同層之間的信息。
ASPP層就是為了融合不同級別的語義信息:選擇不同擴張率的帶孔卷積去處理Feature Map,由于感受野不同,得到的信息的Level也就不同,ASPP層把這些不同層級的feature map concat到一起,進行信息融合。
3.7 Deeplab v3
Deeplab v3在原有基礎上的改動是:
1.改進了ASPP模塊
2.引入Resnet Block
3.丟棄CRF
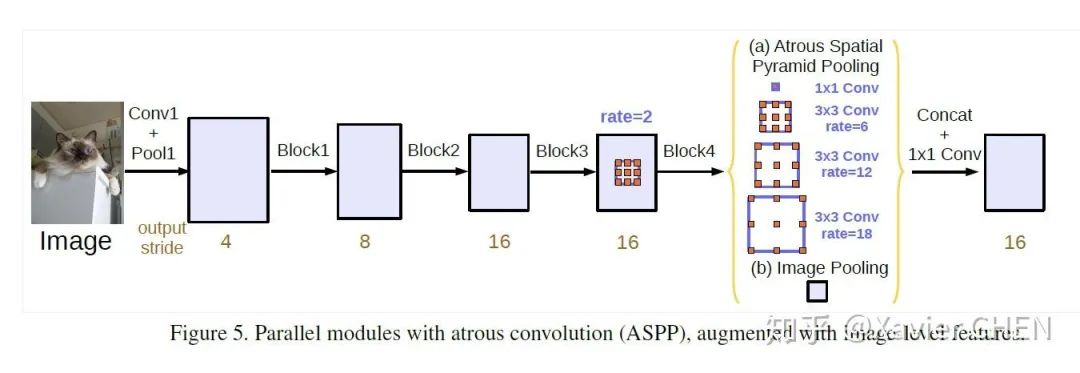
figure15
新的ASPP模塊:
1.加入了Batch Norm
2.加入特征的全局平均池化(在擴張率很大的情況下,有效權重會變小)。如圖14中的(b)Image Pooling就是全局平均池化,它的加入是對全局特征的強調、加強。
在舊的ASPP模塊中:我們以為在擴張率足夠大的時候,感受野足夠大,所以獲得的特征傾向于全局特征。但實際上,擴張率過大的情況下,Atrous conv出現了“權值退化”的問題,感受野過大,都已近擴展到了圖像外面,大多數的權重都和圖像外圍的zero padding進行了點乘,這樣并沒有獲取圖像中的信息。有效的權值個數很少,往往就是1。于是我們加了全局平均池化,強行利用全局信息。
3.8 Deeplab v3+
figure16
可以看成是把Deeplab v3作為編碼器(上半部分)。后面再進行解碼,并且在解碼的過程中在此運用了不同層級特征的融合。
此外,在encoder部分加入了Xception的結構減少了參數量,提高運行速遞。關于Xception如何減少參數量,提高速度。建議閱讀論文 : Mobilenet
https://arxiv.org/pdf/1704.04861.pdf
3.9 套路總結
看完這么多論文,會發現他們的方法都差不多,總結為一下幾點。在自己設計語義分割模型的時候,遵循一下規則,都是可以漲點的。但是要結合自己的項目要求,選擇合適的方法。
1.全卷積網絡,滑窗的形式
2.感受野的控制:Pooling+Upsample => Atrous convolution
3.不同Level的特征融合:統一尺寸之后Add / Concat+Conv, SPP, ASPP…
4.考慮相鄰像素之間的關系:CRF
5.在條件允許的情況下,圖像越大越好。
6.分割某一個特定的類別,可以考慮使用先驗知識+ 對結果進行圖像形態學處理
7.此外還有一些其他的研究思路:實時語義分割,視頻語義分割
責任編輯:xj
原文標題:一文速覽!語義分割算法盤點
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
-
算法
+關注
關注
23文章
4702瀏覽量
94950 -
FC
+關注
關注
1文章
81瀏覽量
42315 -
卷積
+關注
關注
0文章
95瀏覽量
18719
原文標題:一文速覽!語義分割算法盤點
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
SparseViT:以非語義為中心、參數高效的稀疏化視覺Transformer

【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊
利用VLM和MLLMs實現SLAM語義增強

【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+介紹基礎硬件算法模塊
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+一本介紹基礎硬件算法模塊實現的好書
手冊上新 |迅為RK3568開發板NPU例程測試
語義分割25種損失函數綜述和展望






 工商網監
工商網監
評論