") SparseViT:以非語義為中心、參數(shù)高效的稀疏化視覺Transformer
SparseViT:以非語義為中心、參數(shù)高效的稀疏化視覺Transformer

背景簡介
隨著圖像編輯工具和圖像生成技術(shù)的快速發(fā)展,圖像處理變得非常方便。然而圖像在經(jīng)過處理后不可避免的會留下偽影(操作痕跡),這些偽影可分為語義和非語義特征。因此目前幾乎所有的圖像篡改檢測模型(IML)都遵循“語義分割主干網(wǎng)絡(luò)”與“精心制作的手工制作非語義特征提取”相結(jié)合的設(shè)計,這種方法嚴重限制了模型在未知場景的偽影提取能力。

論文標題: Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization through Spare-Coding Transformer
作者單位:
四川大學(呂建成團隊),澳門大學
論文鏈接:
https://arxiv.org/abs/2412.14598
代碼鏈接:
https://github.com/scu-zjz/SparseViT
研究內(nèi)容
利用非語義信息往往在局部和全局之間保持一致性,同時相較于語義信息在圖像不同區(qū)域表現(xiàn)出更大的獨立性,SparseViT 提出了以稀疏自注意力為核心的架構(gòu),取代傳統(tǒng) Vision Transformer(ViT)的全局自注意力機制,通過稀疏計算模式,使得模型自適應(yīng)提取圖像篡改檢測中的非語義特征。
研究團隊在統(tǒng)一的評估協(xié)議下復現(xiàn)并對比多個現(xiàn)有的最先進方法,系統(tǒng)驗證了 SparseViT 的優(yōu)越性。同時,框架采用模塊化設(shè)計,用戶可以靈活定制或擴展模型的核心模塊,并通過可學習的多尺度監(jiān)督機制增強模型對多種場景的泛化能力。
此外,SparseViT 極大地降低了計算量(最高減少 80% 的 FLOPs),實現(xiàn)了參數(shù)效率與性能的兼顧,展現(xiàn)了其在多基準數(shù)據(jù)集上的卓越表現(xiàn)。SparseViT 有望為圖像篡改檢測領(lǐng)域的理論與應(yīng)用研究提供新視角,為后續(xù)研究奠定基礎(chǔ)。
SparseViT 總體架構(gòu)的設(shè)計概覽圖如下所示:
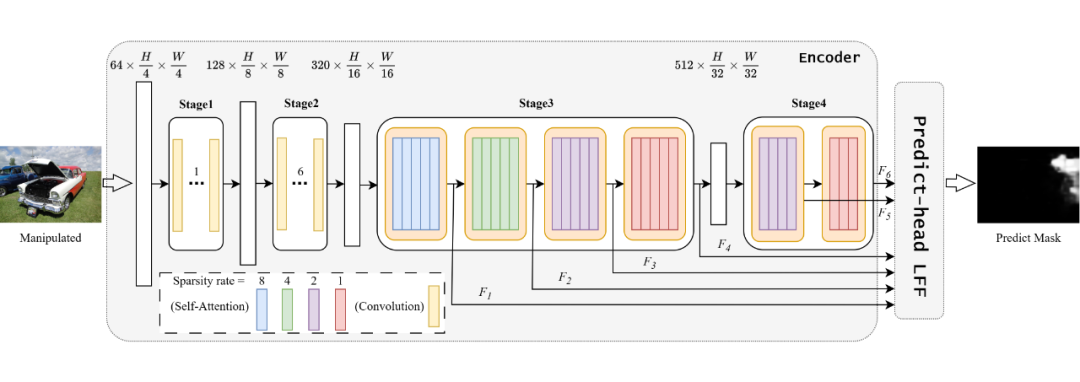
▲ 圖1:SparseViT 總體架構(gòu)
主要的組件包含:
1. 負責高效特征捕獲的 Sparse Self-Attention
Sparse Self-Attention 是 SparseViT 框架的核心組件,專注于在減少計算復雜度的同時高效捕獲篡改圖像中的關(guān)鍵特征即非語義特征。傳統(tǒng)的自注意力機制由于 patch 進行 token-to-token 的注意力計算,導致模型對語義信息過度擬合,使得非語義信息在受到篡改后表現(xiàn)出的局部不一致性被忽視。 為此,Sparse Self-Attention 提出了基于稀疏編碼的自注意力機制,如圖 2 所示,通過對輸入特征圖施加稀疏性約束,設(shè)輸入的特征圖 ,我們不是對 的整個特征上應(yīng)用注意力,而是將特征分成形狀為的張量塊,表示將特征圖分解為 個大小為的不重疊的張量塊,分別在這些張量塊上進行自注意力計算。
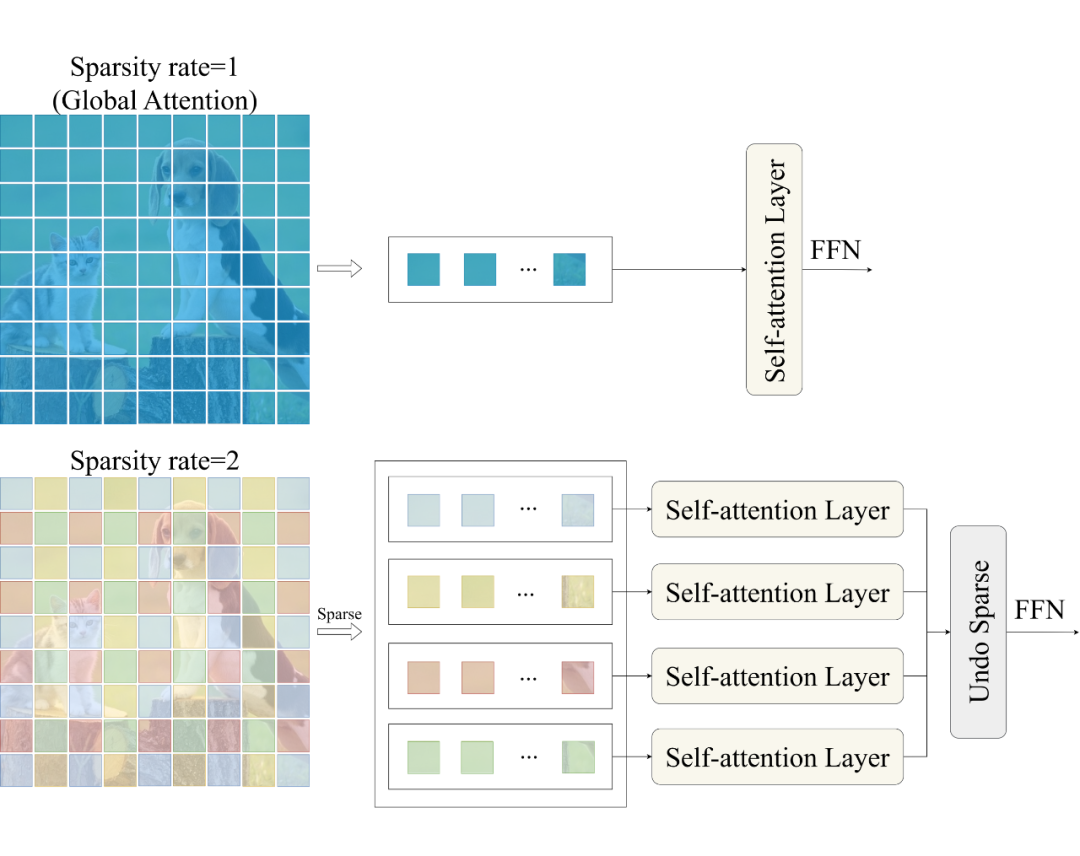
▲ 圖2:稀疏自注意力
這一機制通過對特征圖進行區(qū)域劃分,使模型在訓練中專注于非語義特征的提取,提升了對圖像篡改偽影的捕捉能力。相比傳統(tǒng)自注意力,Sparse Self-Attention 減少了約 80% 的 FLOPs,同時保留了高效的特征捕獲能力,特別是在復雜場景中表現(xiàn)卓越。模塊化的實現(xiàn)方式還允許用戶根據(jù)需求對稀疏策略進行調(diào)整,從而滿足不同任務(wù)的需求。
2. 負責多尺度特征融合的 Learnable Feature Fusion(LFF)
Learnable Feature Fusion(LFF)是 SparseViT 中的重要模塊,旨在通過多尺度特征融合機制提高模型的泛化能力和對復雜場景的適應(yīng)性。不同于傳統(tǒng)的固定規(guī)則特征融合方法,LFF 模塊通過引入可學習參數(shù),動態(tài)調(diào)整不同尺度特征的重要性,從而增強了模型對圖像篡改偽影的敏感度。
LFF 通過從稀疏自注意力模塊輸出的多尺度特征中學習特定的融合權(quán)重,優(yōu)先強化與篡改相關(guān)的低頻特征,同時保留語義信息較強的高頻特征。模塊設(shè)計充分考慮了 IML 任務(wù)的多樣化需求,既能針對微弱的非語義偽影進行細粒度處理,又能適應(yīng)大尺度的全局特征提取。
LFF 的引入顯著提升了 SparseViT 在跨場景、多樣化數(shù)據(jù)集上的性能,同時減少了無關(guān)特征對模型的干擾,為進一步優(yōu)化 IML 模型性能提供了靈活的解決方案。
研究總結(jié)
簡而言之,SparseViT 具有以下四個貢獻:
1. 我們揭示了篡改圖像的語義特征需要連續(xù)的局部交互來構(gòu)建全局語義,而非語義特征由于其局部獨立性,可以通過稀疏編碼實現(xiàn)全局交互。
2. 基于語義和非語義特征的不同行為,我們提出使用稀疏自注意機制自適應(yīng)地從圖像中提取非語義特征。
3. 為了解決傳統(tǒng)多尺度融合方法的不可學習性,我們引入了一種可學習的多尺度監(jiān)督機制。
4. 我們提出的 SparseViT 在不依賴手工特征提取器的情況下保持了參數(shù)效率,并在四個公共數(shù)據(jù)集上實現(xiàn)了最先進的(SoTA)性能和出色的模型泛化能力。
SparseViT 通過利用語義特征和非語義特征之間的差異性,使模型能夠自適應(yīng)地提取在圖像篡改定位中更為關(guān)鍵的非語義特征,為篡改區(qū)域的精準定位提供了全新的研究思路。
相關(guān)代碼和操作文檔、使用教程已完全開源在 GitHub 上(https://github.com/scu-zjz/SparseViT)。該代碼有著完善的更新計劃,倉庫將被長期維護,歡迎全球研究者使用和提出改進意見。
SparseViT 的主要科研成員來自四川大學呂建成團隊,合作方為澳門大學潘治文教授團隊。
-
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41132 -
IML
+關(guān)注
關(guān)注
0文章
14瀏覽量
11572 -
Transformer
+關(guān)注
關(guān)注
0文章
151瀏覽量
6465
原文標題:AAAI 2025 | SparseViT:以非語義為中心、參數(shù)高效的稀疏化視覺Transformer
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
小型數(shù)據(jù)中心晶振選型關(guān)鍵參數(shù)全解
奇瑞汽車整合相關(guān)業(yè)務(wù)成立智能化中心
【「# ROS 2智能機器人開發(fā)實踐」閱讀體驗】視覺實現(xiàn)的基礎(chǔ)算法的應(yīng)用
融媒體IP化新標桿:千視助力武威市融媒體中心打造全新非遺直播體驗

華為發(fā)布以AI為中心的網(wǎng)絡(luò)解決方案
如何使用MATLAB構(gòu)建Transformer模型

王欣然教授團隊提出基于二維材料的高效稀疏神經(jīng)網(wǎng)絡(luò)硬件方案

地平線ViG基于視覺Mamba的通用視覺主干網(wǎng)絡(luò)
港大提出SparX:強化Vision Mamba和Transformer的稀疏跳躍連接機制

利用VLM和MLLMs實現(xiàn)SLAM語義增強

使用ReMEmbR實現(xiàn)機器人推理與行動能力
使用語義線索增強局部特征匹配






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論