 圖解BERT預訓練模型!
圖解BERT預訓練模型!
一、前言
2018 年是機器學習模型處理文本(或者更準確地說,自然語言處理或 NLP)的轉折點。我們對這些方面的理解正在迅速發展:如何最好地表示單詞和句子,從而最好地捕捉基本語義和關系?此外,NLP 社區已經發布了非常強大的組件,你可以免費下載,并在自己的模型和 pipeline 中使用(今年可以說是 NLP 的 ImageNet 時刻,這句話指的是多年前類似的發展也加速了 機器學習在計算機視覺任務中的應用)。
ULM-FiT 與 Cookie Monster(餅干怪獸)無關。但我想不出別的了...
BERT的發布是這個領域發展的最新的里程碑之一,這個事件標志著NLP 新時代的開始。BERT模型打破了基于語言處理的任務的幾個記錄。在 BERT 的論文發布后不久,這個團隊還公開了模型的代碼,并提供了模型的下載版本,這些模型已經在大規模數據集上進行了預訓練。這是一個重大的發展,因為它使得任何一個構建構建機器學習模型來處理語言的人,都可以將這個強大的功能作為一個現成的組件來使用,從而節省了從零開始訓練語言處理模型所需要的時間、精力、知識和資源。
BERT 開發的兩個步驟:第 1 步,你可以下載預訓練好的模型(這個模型是在無標注的數據上訓練的)。然后在第 2 步只需要關心模型微調即可。
你需要注意一些事情,才能理解 BERT 是什么。因此,在介紹模型本身涉及的概念之前,讓我們先看看如何使用 BERT。
二、示例:句子分類
使用 BERT 最直接的方法就是對一個句子進行分類。這個模型如下所示:
為了訓練這樣一個模型,你主要需要訓練分類器(上圖中的 Classifier),在訓練過程中 幾乎不用改動BERT模型。這個訓練過程稱為微調,它起源于Semi-supervised Sequence Learning 和 ULMFiT。
由于我們在討論分類器,這屬于機器學習的監督學習領域。這意味著我們需要一個帶有標簽的數據集來訓練這樣一個模型。例如,在下面這個垃圾郵件分類器的例子中,帶有標簽的數據集包括一個郵件內容列表和對應的標簽(每個郵件是“垃圾郵件”或者“非垃圾郵件”)。
其他一些例子包括:
1)語義分析
輸入:電影或者產品的評價。輸出:判斷這個評價是正面的還是負面的。
數據集示例:SST (https://nlp.stanford.edu/sentiment)
2)Fact-checking
輸入:一個句子。輸出:這個句子是不是一個斷言
參考視頻:https://www.youtube.com/watch?v=ddf0lgPCoSo
三、模型架構
現在你已經通過上面的例子,了解了如何使用 BERT,接下來讓我們更深入地了解一下它的工作原理。
論文里介紹了兩種不同模型大小的 BERT:
BERT BASE - 與 OpenAI 的 Transformer 大小相當,以便比較性能
BERT LARGE - 一個非常巨大的模型,它取得了最先進的結果
BERT 基本上是一個訓練好的 Transformer 的 decoder 的棧。關于 Transformer 的介紹,可以閱讀之前的文章《 圖解Transformer(完整版)!》,這里主要介紹 Transformer 模型,這是 BERT 中的一個基本概念。此外,我們還會介紹其他一些概念。
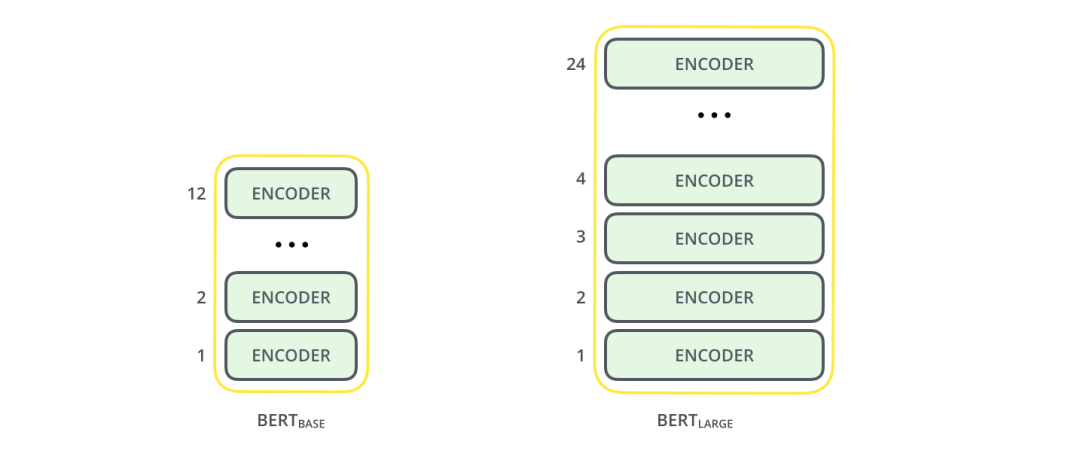
2 種不同大小規模的 BERT 模型都有大量的 Encoder 層(論文里把這些層稱為 Transformer Blocks)- BASE 版本由 12 層 Encoder,Large 版本有 20 層 Encoder。同時,這些 BERT 模型也有更大的前饋神經網絡(分別有 768 個和 1024 個隱藏層單元)和更多的 attention heads(分別有 12 個和 16 個),超過了原始 Transformer 論文中的默認配置參數(原論文中有 6 個 Encoder 層, 512 個隱藏層單元和 8 個 attention heads)。
四、模型輸入
第一個輸入的 token 是特殊的 [CLS],它 的含義是分類(class的縮寫)。
就像 Transformer 中普通的 Encoder 一樣,BERT 將一串單詞作為輸入,這些單詞在 Encoder 的棧中不斷向上流動。每一層都會經過 Self Attention 層,并通過一個前饋神經網絡,然后將結果傳給下一個 Encoder。
在模型架構方面,到目前為止,和 Transformer 是相同的(除了模型大小,因為這是我們可以改變的參數)。我們會在下面看到,BERT 和 Transformer 在模型的輸出上有一些不同。
五、模型輸出
每個位置輸出一個大小為 hidden_size(在 BERT Base 中是 768)的向量。對于上面提到的句子分類的例子,我們只關注第一個位置的輸出(輸入是 [CLS] 的那個位置)。
這個輸出的向量現在可以作為后面分類器的輸入。論文里用單層神經網絡作為分類器,取得了很好的效果。
如果你有更多標簽(例如你是一個電子郵件服務,需要將郵件標記為 “垃圾郵件”、“非垃圾郵件”、“社交”、“推廣”),你只需要調整分類器的神經網絡,增加輸出的神經元個數,然后經過 softmax 即可。
六、與卷積神經網絡進行對比
對于那些有計算機視覺背景的人來說,這個向量傳遞過程,會讓人聯想到 VGGNet 等網絡的卷積部分,和網絡最后的全連接分類部分之間的過程。
七、詞嵌入(Embedding)的新時代
上面提到的這些新發展帶來了文本編碼方式的新轉變。到目前為止,詞嵌入一直是 NLP 模型處理語言的主要表示方法。像 Word2Vec 和 Glove 這樣的方法已經被廣泛應用于此類任務。在我們討論新的方法之前,讓我們回顧一下它們是如何應用的。
7.1 回顧詞嵌入
單詞不能直接輸入機器學習模型,而需要某種數值表示形式,以便模型能夠在計算中使用。通過 Word2Vec,我們可以使用一個向量(一組數字)來恰當地表示單詞,并捕捉單詞的語義以及單詞和單詞之間的關系(例如,判斷單詞是否相似或者相反,或者像 "Stockholm" 和 "Sweden" 這樣的一對詞,與 "Cairo" 和 "Egypt"這一對詞,是否有同樣的關系)以及句法、語法關系(例如,"had" 和 "has" 之間的關系與 "was" 和 "is" 之間的關系相同)。
人們很快意識到,相比于在小規模數據集上和模型一起訓練詞嵌入,更好的一種做法是,在大規模文本數據上預訓練好詞嵌入,然后拿來使用。因此,我們可以下載由 Word2Vec 和 GloVe 預訓練好的單詞列表,及其詞嵌入。下面是單詞 "stick" 的 Glove 詞嵌入向量的例子(詞嵌入向量長度是 200)。
單詞 "stick" 的 Glove 詞嵌入 - 一個由200個浮點數組成的向量(四舍五入到小數點后兩位)。
由于這些向量都很長,且全部是數字,所以在文章中我使用以下基本形狀來表示向量:
7.2 ELMo:語境問題
如果我們使用 Glove 的詞嵌入表示方法,那么不管上下文是什么,單詞 "stick" 都只表示為同一個向量。一些研究人員指出,像 "stick" 這樣的詞有多種含義。為什么不能根據它使用的上下文來學習對應的詞嵌入呢?這樣既能捕捉單詞的語義信息,又能捕捉上下文的語義信息。于是,語境化的詞嵌入模型應運而生。
語境化的詞嵌入,可以根據單詞在句子語境中的含義,賦予不同的詞嵌入。你可以查看這個視頻 RIP Robin Williams(https://zhuanlan.zhihu.com/RIP Robin Williams)
ELMo 沒有對每個單詞使用固定的詞嵌入,而是在為每個詞分配詞嵌入之前,查看整個句子,融合上下文信息。它使用在特定任務上經過訓練的雙向 LSTM 來創建這些詞嵌入。
ELMo 在語境化的預訓練這條道路上邁出了重要的一步。ELMo LSTM 會在一個大規模的數據集上進行訓練,然后我們可以將它作為其他語言處理模型的一個部分,來處理自然語言任務。
那么 ELMo 的秘密是什么呢?
ELMo 通過訓練,預測單詞序列中的下一個詞,從而獲得了語言理解能力,這項任務被稱為語言建模。要實現 ELMo 很方便,因為我們有大量文本數據,模型可以從這些數據中學習,而不需要額外的標簽。
ELMo 預訓練過程的其中一個步驟:以 "Let’s stick to" 作為輸入,預測下一個最有可能的單詞。這是一個語言建模任務。當我們在大規模數據集上訓練時,模型開始學習語言的模式。例如,在 "hang" 這樣的詞之后,模型將會賦予 "out" 更高的概率(因為 "hang out" 是一個詞組),而不是 "camera"。
在上圖中,我們可以看到 ELMo 頭部上方展示了 LSTM 的每一步的隱藏層狀態向量。在這個預訓練過程完成后,這些隱藏層狀態在詞嵌入過程中派上用場。
ELMo 通過將隱藏層狀態(以及初始化的詞嵌入)以某種方式(向量拼接之后加權求和)結合在一起,實現了帶有語境化的詞嵌入。
7.3 ULM-FiT:NLP 領域的遷移學習
ULM-FiT 提出了一些方法來有效地利用模型在預訓練期間學習到的東西 - 這些東西不僅僅是詞嵌入,還有語境化的詞嵌入。ULM-FiT 提出了一個語言模型和一套流程,可以有效地為各種任務微調這個語言模型。
現在,NLP 可能終于找到了好的方法,可以像計算機視覺那樣進行遷移學習了。
7.4 Transformer:超越 LSTM
Transformer 論文和代碼的發布,以及它在機器翻譯等任務上取得的成果,開始讓人們認為它是 LSTM 的替代品。這是因為 Transformer 可以比 LSTM 更好地處理長期依賴。
Transformer 的 Encoder-Decoder 結構使得它非常適合機器翻譯。但你怎么才能用它來做文本分類呢?你怎么才能使用它來預訓練一個語言模型,并能夠在其他任務上進行微調(下游任務是指那些能夠利用預訓練模型的監督學習任務)?
7.5 OpenAI Transformer:預訓練一個 Transformer Decoder 來進行語言建模
事實證明,我們不需要一個完整的 Transformer 來進行遷移學習和微調。我們只需要 Transformer 的 Decoder 就可以了。Decoder 是一個很好的選擇,用它來做語言建模(預測下一個詞)是很自然的,因為它可以屏蔽后來的詞 。當你使用它進行逐詞翻譯時,這是個很有用的特性。
OpenAI Transformer 是由 Transformer 的 Decoder 堆疊而成的
這個模型包括 12 個 Decoder 層。因為在這種設計中沒有 Encoder,這些 Decoder 層不會像普通的 Transformer 中的 Decoder 層那樣有 Encoder-Decoder Attention 子層。不過,它仍然會有 Self Attention 層(這些層使用了 mask,因此不會看到句子后來的 token)。
有了這個結構,我們可以繼續在同樣的語言建模任務上訓練這個模型:使用大規模未標記的數據來預測下一個詞。只需要把 7000 本書的文字扔給模型 ,然后讓它學習。書籍非常適合這種任務,因為書籍的數據可以使得模型學習到相關聯的信息。如果你使用 tweets 或者文章來訓練,模型是得不到這些信息的。
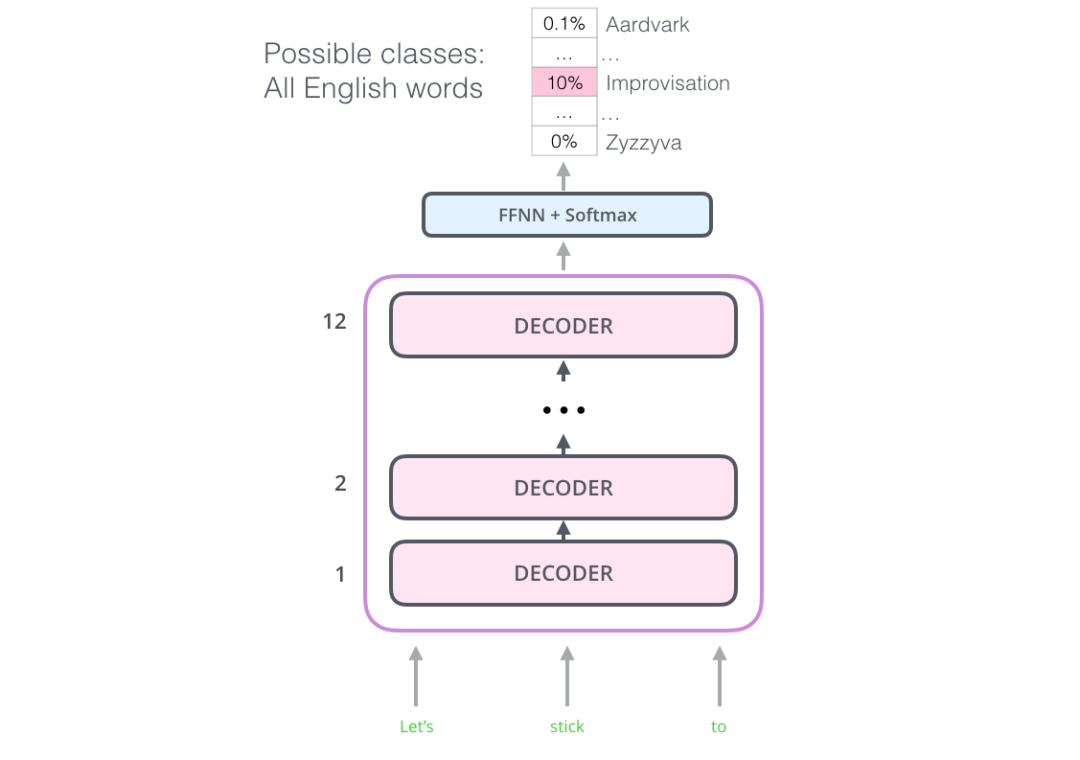
上圖表示:OpenAI Transformer 在 7000 本書的組成的數據集中預測下一個單詞。
7.6 下游任務的遷移學習
現在,OpenAI Transformer 已經經過了預訓練,它的網絡層經過調整,可以很好地處理文本語言,我們可以開始使用它來處理下游任務。讓我們先看下句子分類任務(把電子郵件分類為 ”垃圾郵件“ 或者 ”非垃圾郵件“):
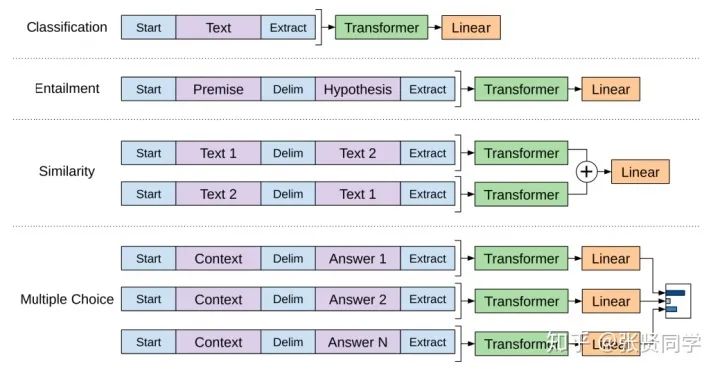
OpenAI 的論文列出了一些列輸入變換方法,來處理不同任務類型的輸入。下面這張圖片來源于論文,展示了執行不同任務的模型結構和對應輸入變換。這些都是非常很巧妙的做法。
八、BERT:從 Decoder 到 Encoder
OpenAI Transformer 為我們提供了一個基于 Transformer 的可以微調的預訓練網絡。但是在把 LSTM 換成 Transformer 的過程中,有些東西丟失了。ELMo 的語言模型是雙向的,但 OpenAI Transformer 只訓練了一個前向的語言模型。我們是否可以構建一個基于 Transformer 的語言模型,它既向前看,又向后看(用技術術語來說 - 融合上文和下文的信息)。
8.1 Masked Language Model(MLM 語言模型)
那么如何才能像 LSTM 那樣,融合上文和下文的雙向信息呢?
一種直觀的想法是使用 Transformer 的 Encoder。但是 Encoder 的 Self Attention 層,每個 token 會把大部分注意力集中到自己身上,那么這樣將容易預測到每個 token,模型學不到有用的信息。BERT 提出使用 mask,把需要預測的詞屏蔽掉。
下面這段風趣的對話是博客原文的。
“
BERT 說,“我們要用 Transformer 的 Encoder”。
Ernie 說,”這沒什么用,因為每個 token 都會在多層的雙向上下文中看到自己“。
BERT 自信地說,”我們會使用 mask“。
”
BERT 在語言建模任務中,巧妙地屏蔽了輸入中 15% 的單詞,并讓模型預測這些屏蔽位置的單詞。
找到合適的任務來訓練一個 Transformer 的 Encoder 是一個復雜的問題,BERT 通過使用早期文獻中的 "masked language model" 概念(在這里被稱為完形填空)來解決這個問題。
除了屏蔽輸入中 15% 的單詞外, BERT 還混合使用了其他的一些技巧,來改進模型的微調方式。例如,有時它會隨機地用一個詞替換另一個詞,然后讓模型預測這個位置原來的實際單詞。
8.2 兩個句子的任務
如果你回顧 OpenAI Transformer 在處理不同任務時所做的輸入變換,你會注意到有些任務需要模型對兩個句子的信息做一些處理(例如,判斷它們是不是同一句話的不同解釋。將一個維基百科條目作為輸入,再將一個相關的問題作為另一個輸入,模型判斷是否可以回答這個問題)。
為了讓 BERT 更好地處理多個句子之間的關系,預訓練過程還包括一個額外的任務:給出兩個句子(A 和 B),判斷 B 是否是 A 后面的相鄰句子。
BERT 預訓練的第 2 個任務是兩個句子的分類任務。在上圖中,tokenization 這一步被簡化了,因為 BERT 實際上使用了 WordPieces 作為 token,而不是使用單詞本身。在 WordPiece 中,有些詞會被拆分成更小的部分。
8.3 BERT 在不同任務上的應用
BERT 的論文展示了 BERT 在多種任務上的應用。
8.4 將 BERT 用于特征提取
使用 BERT 并不是只有微調這一種方法。就像 ELMo 一樣,你可以使用預訓練的 BERT 來創建語境化的詞嵌入。然后你可以把這些詞嵌入用到你現有的模型中。論文里也提到,這種方法在命名實體識別任務中的效果,接近于微調 BERT 模型的效果。
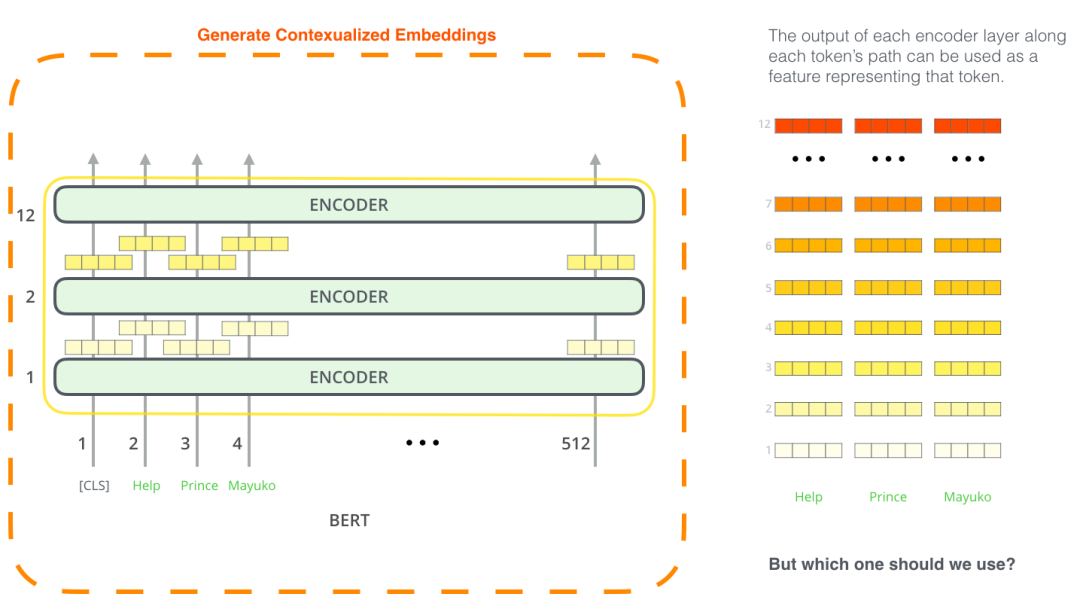
那么哪種向量最適合作為上下文詞嵌入?我認為這取決于任務。論文里驗證了 6 種選擇(與微調后的 96.4 分的模型相比):
8.5 如何使用 BERT
嘗試 BERT 的最佳方式是通過托管在 Google Colab 上的BERT FineTuning with Cloud TPUs。如果你之前從來沒有使用過 Cloud TPU,那這也是一個很好的嘗試開端,因為 BERT 代碼可以運行在 TPU、CPU 和 GPU。
下一步是查看BERT 倉庫中的代碼:
模型是在modeling.py(class BertModel)中定義的,和普通的 Transformer encoder 完全相同。
run_classifier.py是微調網絡的一個示例。它還構建了監督模型分類層。如果你想構建自己的分類器,請查看這個文件中的 create_model() 方法。
可以下載一些預訓練好的模型。這些模型包括 BERT Base、BERT Large,以及英語、中文和包括 102 種語言的多語言模型,這些模型都是在維基百科的數據上進行訓練的。
BERT 不會將單詞作為 token。相反,它關注的是 WordPiece。tokenization.py就是 tokenizer,它會將你的單詞轉換為適合 BERT 的 wordPiece。
責任編輯:lq
-
機器學習
+關注
關注
66文章
8481瀏覽量
133913 -
自然語言處理
+關注
關注
1文章
625瀏覽量
13948 -
nlp
+關注
關注
1文章
490瀏覽量
22436
原文標題:【NLP專欄】圖解 BERT 預訓練模型!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

從Open Model Zoo下載的FastSeg大型公共預訓練模型,無法導入名稱是怎么回事?
用PaddleNLP在4060單卡上實踐大模型預訓練技術

KerasHub統一、全面的預訓練模型庫
【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型

直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論