") 蘋果M1芯片速度為什么那么快?
蘋果M1芯片速度為什么那么快?

除了輕度辦公以外,Arm 架構(gòu)的蘋果電腦還可以打游戲、看視頻、跑深度學(xué)習(xí),效率都還不錯(cuò)。
最近,很多人的 M1 芯片版蘋果 MacBook 和 Mac Mini 到貨了。在不少測試中,我們看到了令人期待的結(jié)果:M1 芯片跑分比肩高端 X86 處理器,對標(biāo)的 CPU 是 Ryzen 4900HS 和英特爾 Core i9,還能跟英偉達(dá)的 GPU GTX 1050Ti 打得有來有回。5 納米的芯片,真就如此神奇?
自蘋果發(fā)布搭載自研 M1 芯片的 Mac 產(chǎn)品后,人們對 M1 芯片充滿了好奇,各種測評(píng)層出不窮。最近,開發(fā)者 Erik Engheim 撰寫長文,分析 M1 芯片速度快背后的技術(shù)原因,以及英特爾和 AMD 等芯片廠商的劣勢。 關(guān)于蘋果的 M1 芯片,這篇文章將圍繞以下問題展開討論:
M1 芯片速度快背后的技術(shù)原因。
蘋果是不是采用了什么特殊的技術(shù)來實(shí)現(xiàn)這一點(diǎn)?
如果 Intel 和 AMD 也想這么做,難度有多大?
鑒于蘋果的官方宣傳中存在大量專業(yè)術(shù)語,我們先從最基礎(chǔ)的講起。 什么是 CPU? 在提到英特爾和 AMD 的芯片時(shí),我們通常談?wù)摰氖侵醒胩幚砥鳎–PU),或者叫微處理器。它們從內(nèi)存中提取指令,然后按順序執(zhí)行每條指令。
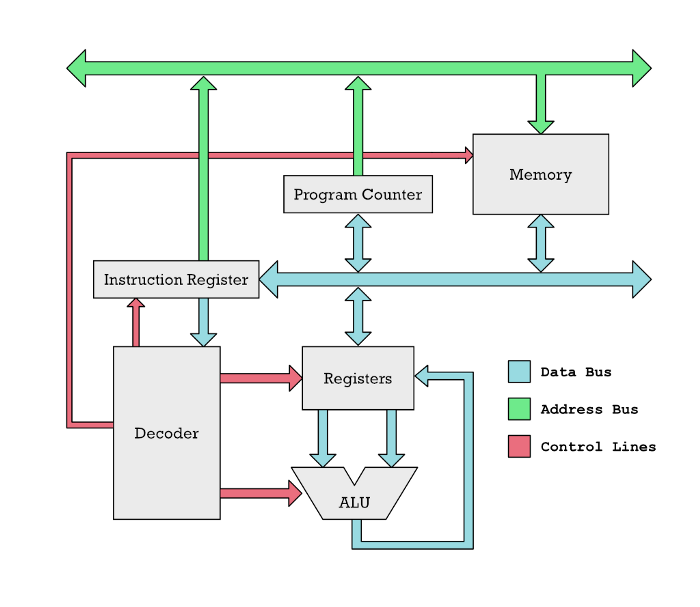
一個(gè)基本的 RISC CPU(不是 M1)。指令沿著藍(lán)色箭頭從內(nèi)存移動(dòng)到指令寄存器。解碼器用來解讀指令的內(nèi)容,同時(shí)通過紅色的控制線來連通 CPU 的各個(gè)部分。ALU 對寄存器中的數(shù)字進(jìn)行加減運(yùn)算。 CPU 本質(zhì)上是一個(gè)設(shè)備,包含許多被稱為寄存器的內(nèi)存單元和被稱為算術(shù)邏輯單元(ALU)的計(jì)算單元。ALU 執(zhí)行加法、減法和其他基礎(chǔ)數(shù)學(xué)運(yùn)算。然而,這些只與 CPU 寄存器相連。如果想把兩個(gè)數(shù)字加起來,你必須把這兩個(gè)數(shù)字從內(nèi)存中取出,放到 CPU 的兩個(gè)寄存器中。 下面是 RISC CPU(M1 中的 CPU 類型)執(zhí)行的幾個(gè)典型指令示例:
此處的 r1 和 r2 是寄存器。當(dāng)前的 RISC CPU 無法對不在寄存器中的數(shù)字執(zhí)行示例中的運(yùn)算,比如不能將在兩個(gè)不同位置的內(nèi)存中的數(shù)字相加,而是要將兩個(gè)數(shù)字各放到一個(gè)單獨(dú)的寄存器里。 在上面的示例中,我們必須先將內(nèi)存位置為 150 的數(shù)字放到寄存器 r1 中,然后將位置為 200 的數(shù)字放到 r2 中,只有這樣,這兩個(gè)數(shù)字才能依據(jù) add r1, r2 指令進(jìn)行加法運(yùn)算。
這種老式機(jī)械計(jì)算器有兩個(gè)寄存器:累加器和輸入寄存器。現(xiàn)代 CPU 通常有十幾個(gè)寄存器,而且它們是電子的,不是機(jī)械的。 寄存器的概念由來已久。例如,在上圖的機(jī)械計(jì)算器上,寄存器用來存放加起來的數(shù)字。 M1 不是 CPU 這么簡單 M1 芯片不是 CPU,而是把多個(gè)芯片集成到了一起,CPU 只是其中的一部分。 可以說,M1 是把整個(gè)計(jì)算機(jī)放在了一塊芯片上。M1 包含 CPU、GPU、內(nèi)存、輸入 / 輸出控制器,以及完整計(jì)算機(jī)所需的其他很多東西,這就是我們經(jīng)常會(huì)在手機(jī)上看到的 SoC(片上系統(tǒng))概念。
M1 是一個(gè)片上系統(tǒng)。也就是說,將構(gòu)成一臺(tái)計(jì)算機(jī)的所有部件都放在一塊硅芯片上。 如今,如果你從英特爾或 AMD 購買一塊芯片,你拿到的實(shí)際上是一個(gè)微處理器包,而過去的計(jì)算機(jī)主板上是多個(gè)單獨(dú)的芯片。
計(jì)算機(jī)主板示例,上面包含內(nèi)存、CPU、顯卡、IO 控制器、網(wǎng)卡等部件。 然而,現(xiàn)在我們可以在一塊硅片上集成大量晶體管,因此 AMD、英特爾等公司開始將多個(gè)微處理器放在一塊芯片上。我們將這些芯片稱為 CPU 核心。一個(gè)核心基本上是一個(gè)完全獨(dú)立的芯片,它可以從內(nèi)存中讀取指令并執(zhí)行計(jì)算。
具備多個(gè) CPU 核心的微芯片。 很長一段時(shí)間以來,添加更多通用 CPU 核心成為提高芯片性能的主要方法,但有家廠商沒這么做。 蘋果的異構(gòu)計(jì)算策略沒那么神秘 在提升性能的道路上,蘋果并沒有選擇增加更多通用 CPU 核心,而是采取了另一種策略:添加更多專用芯片來完成一些專門的任務(wù)。這樣做的好處是:與通用 CPU 核心相比,專用芯片可以使用更少的電流執(zhí)行任務(wù),而且速度還更快。 這并不是什么全新的技術(shù)。多年來,圖形處理單元(GPU)等專用芯片已經(jīng)存在于英偉達(dá)和 AMD 的顯卡中,執(zhí)行與圖形相關(guān)的操作,速度比通用 CPU 快得多。 蘋果只是在這個(gè)方向上走得更加徹底。除了通用核心和內(nèi)存之外,M1 包含了一系列專用芯片:
CPU(中央處理器):SoC 的「大腦」,運(yùn)行操作系統(tǒng)和 app 的大部分代碼。
GPU(圖形處理器):處理圖形相關(guān)的任務(wù),如可視化 app 的用戶界面和 2D/3D 游戲。
IPU(圖像處理單元):用于加快圖像處理應(yīng)用所承擔(dān)的常見任務(wù)。
DSP(數(shù)字信號(hào)處理器):具備比 CPU 更強(qiáng)的數(shù)學(xué)密集型功能,包括解壓音樂文件。
NPU(神經(jīng)網(wǎng)絡(luò)處理器):用于高端智能手機(jī),加速語音識(shí)別等機(jī)器學(xué)習(xí)任務(wù)。
視頻編碼器 / 解碼器:以高能效的方式處理視頻文件和格式的轉(zhuǎn)換。
Secure Enclave:負(fù)責(zé)加密、身份驗(yàn)證,維護(hù)安全性。
統(tǒng)一內(nèi)存(unified memory):允許 CPU、GPU 和其他核心快速交換信息。
這就是使用 M1 Mac 進(jìn)行圖像和視頻編輯時(shí)速度有所提升的一部分原因。許多此類任務(wù)可以直接在專用硬件上運(yùn)行,這樣一來,相對廉價(jià)的 M1 Mac Mini 就能夠輕松對大型視頻文件進(jìn)行編碼。
你或許疑惑,統(tǒng)一內(nèi)存與共享內(nèi)存有什么區(qū)別。將視頻內(nèi)存與主存共享的做法導(dǎo)致了低性能,因?yàn)?CPU 和 GPU 必須輪流訪問內(nèi)存,共享意味著爭用數(shù)據(jù)總線。 統(tǒng)一內(nèi)存的情況就不同了。在統(tǒng)一內(nèi)存中,CPU 和 GPU 可以同時(shí)訪問內(nèi)存,并且 CPU 和 GPU 還可以相互告知一些內(nèi)存的位置。以前 CPU 必須將數(shù)據(jù)從其主存區(qū)域復(fù)制到 GPU 使用的區(qū)域,而使用統(tǒng)一內(nèi)存模式,無需復(fù)制,通過告知內(nèi)存位置即可令 GPU 使用該內(nèi)存。 也就是說,M1 上各種專有協(xié)處理器都可以使用同一內(nèi)存池彼此快速地交換信息,從而顯著提升性能。 英特爾和 AMD 為什么不效仿這一策略? 其他 ARM 芯片制造商也越來越多地投入專用硬件。AMD 開始在某些芯片上安裝功能更強(qiáng)大的 GPU,并通過加速處理器(APU)逐步向某種形式的 SoC 邁進(jìn)。(APU 將 CPU 核心和 GPU 核心放置在同一芯片上。)
AMD Ryzen 加速處理器在同一塊芯片上結(jié)合 CPU 和 GPU,但不包含其他協(xié)處理器、IO 控制器或統(tǒng)一內(nèi)存。 英特爾和 AMD 不這么做是有重要原因的。SoC 本質(zhì)上是芯片上的整個(gè)計(jì)算機(jī),這使得它非常適合實(shí)際的計(jì)算機(jī)制造商,例如惠普、戴爾。計(jì)算機(jī)制造商可以簡單地獲取 ARM 知識(shí)產(chǎn)權(quán)許可,并購買其他芯片的 IP,來添加他們認(rèn)為自己的 SoC 應(yīng)該具備的任意專用硬件。然后,他們將已完成的設(shè)計(jì)交給半導(dǎo)體代工廠,比如 GlobalFoundries 和臺(tái)積電(TSMC),臺(tái)積電現(xiàn)在是 AMD 和蘋果的芯片代工廠。
那么問題來了。英特爾和 AMD 的商業(yè)模型都是基于銷售通用 CPU(只需將其插入大型 PC 主板)。計(jì)算機(jī)制造商只需從不同的供應(yīng)商那里購買主板、內(nèi)存、CPU 和顯卡,然后將它們集成即可。但這種方式已經(jīng)漸漸淡出。 在 SoC 時(shí)代,計(jì)算機(jī)制造商無需組裝來自不同供應(yīng)商的物理組件,而是組裝來自不同供應(yīng)商的 IP(知識(shí)產(chǎn)權(quán))。他們從不同供應(yīng)商那里購買顯卡、CPU、調(diào)制解調(diào)器、IO 控制器等的設(shè)計(jì),并將其用于設(shè)計(jì) SoC,然后尋找代工廠完成制造過程。 但是英特爾、AMD、英偉達(dá)都不會(huì)將其知識(shí)產(chǎn)權(quán)給戴爾或惠普,讓他們?yōu)樽约旱挠?jì)算機(jī)制造 SoC。
當(dāng)然,英特爾和 AMD 可能只是開始銷售完整的 SoC,但是其中包含什么呢?PC 制造商可能對此有不同的想法。英特爾、AMD、微軟和 PC 制造商之間可能就 SoC 要包含哪些專用芯片產(chǎn)生沖突,因?yàn)檫@些芯片需要軟件支持。 而對于蘋果來說,這很簡單。蘋果控制整個(gè)產(chǎn)品,比如為機(jī)器學(xué)習(xí)開發(fā)者提供如 Core ML 庫等。至于 Core ML 是在蘋果的 CPU 上運(yùn)行還是 Neural Engine,這是開發(fā)者無需關(guān)心的實(shí)現(xiàn)細(xì)節(jié)了。 CPU 快速運(yùn)行的根本挑戰(zhàn) 異構(gòu)計(jì)算只是一部分原因。M1 的快速通用 CPU 核心 Firestorm 確實(shí)速度非常快,與之前的 ARM CPU 核心相比,二者的速度差距非常大。與 AMD 和英特爾核心相比,ARM 也非常弱。相比之下,F(xiàn)irestorm 擊敗了大多數(shù)英特爾核心,也幾乎擊敗了最快的 AMD Ryzen 核心。 在探討 Firestorm 的速度成因之前,我們先來了解讓 CPU 快速運(yùn)行的核心意義。 原則上可以通過以下兩種策略來完成 CPU 加速的任務(wù):
以更快的速度順序執(zhí)行更多指令;
并行執(zhí)行大量指令。
在上世紀(jì) 80 年代,這很容易做到。只要增加時(shí)鐘頻率,就能更快執(zhí)行指令。每個(gè)時(shí)鐘周期表示計(jì)算機(jī)執(zhí)行某項(xiàng)任務(wù)的時(shí)間,但是這項(xiàng)任務(wù)可能非常微小。一條指令由多個(gè)較小的任務(wù)構(gòu)成,因此可能需要多個(gè)時(shí)鐘周期。 但是現(xiàn)在已經(jīng)幾乎不可能增加時(shí)鐘頻率了,所以第二個(gè)策略「并行執(zhí)行大量指令」是目前研發(fā)的重心。 多核還是亂序處理器? 這個(gè)問題有兩種解決方法。一種是引入更多 CPU 核心。從軟件開發(fā)者的角度講,這類似于添加線程,每個(gè) CPU 核心就像一個(gè)硬件線程。雙核 CPU 可以同時(shí)執(zhí)行兩個(gè)單獨(dú)的任務(wù),即兩個(gè)線程。這些任務(wù)可以被描述為兩個(gè)存儲(chǔ)在內(nèi)存中的單獨(dú)程序,或者同一個(gè)程序被執(zhí)行了兩次。每個(gè)線程需要記錄,例如該線程當(dāng)前在程序指令序列中的位置。每個(gè)線程都可以存儲(chǔ)臨時(shí)結(jié)果(應(yīng)分開存儲(chǔ))。
原則上,處理器可以在只有一個(gè)核心的情況下運(yùn)行多個(gè)線程。這時(shí),處理器只能是暫停一個(gè)線程并存儲(chǔ)當(dāng)前進(jìn)程,然后再切換到另一個(gè)線程,之后再切換回來。這并不能帶來太多的性能提升,僅在線程經(jīng)常懸停來等待用戶輸入或者慢速網(wǎng)絡(luò)中的數(shù)據(jù)等時(shí)才使用。這些可以稱為軟件線程。硬件線程意味著可以使用實(shí)際的附加物理硬件(如附加核心)來加快處理速度。
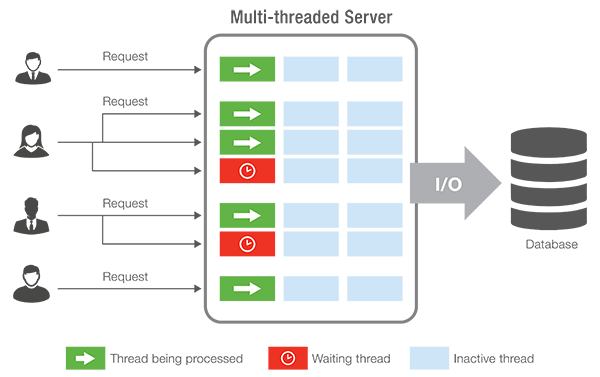
問題在于開發(fā)者必須編寫代碼才能利用這一點(diǎn),一些任務(wù)(例如服務(wù)器軟件)很容易編寫,你可以想象分別處理每個(gè)連接的用戶。這些任務(wù)彼此獨(dú)立,因此擁有大量核心是服務(wù)器(尤其是基于云的服務(wù))的絕佳選擇。
具有 128 個(gè)核心的 Ampere Altra Max ARM CPU 專為云計(jì)算而設(shè)計(jì),大量硬件線程是一項(xiàng)優(yōu)勢。 這就是你會(huì)看到 128 核心 Ampere Altra Max ARM CPU 的原因了。該芯片專為云計(jì)算制造,不需要瘋狂的單核性能,因?yàn)樵谠粕闲枰客呔哂斜M可能多的線程來處理盡可能多的并發(fā)用戶。 而蘋果則不同,蘋果生產(chǎn)單用戶設(shè)備,大量線程并不是優(yōu)勢。蘋果的設(shè)備多用于游戲、視頻編輯、開發(fā)等。蘋果希望臺(tái)式機(jī)具有精美的響應(yīng)圖形和動(dòng)畫。 桌面軟件通常不需要利用很多核心,例如,電腦游戲通常需要 8 個(gè)核心,在這種情況下 128 個(gè)核心就完全是浪費(fèi)了。因此,用戶需要的是更少但更強(qiáng)大的核心。
亂序執(zhí)行是一種并行執(zhí)行更多指令但不以多線程執(zhí)行的方式。開發(fā)者無需專門編碼其軟件即可利用它。從開發(fā)者的角度來講,每個(gè)核心的運(yùn)行速度都更快了。 要了解其工作原理,首先我們需要了解一些內(nèi)存知識(shí)。在一個(gè)特定的內(nèi)存位置上請求數(shù)據(jù)的速度很慢。但是與獲得 128 個(gè)字節(jié)相比,延遲獲得 1 個(gè)字節(jié)的影響不大。數(shù)據(jù)通過數(shù)據(jù)總線發(fā)送,你可以將其視為內(nèi)存與數(shù)據(jù)經(jīng)過的 CPU 不同部分之間的一條通道或管道。實(shí)際上它只是一些可以導(dǎo)電的銅線。如果數(shù)據(jù)總線足夠?qū)挘憔涂梢酝瑫r(shí)獲取多個(gè)字節(jié)。 因此 CPU 一次執(zhí)行一整個(gè)指令塊,但是這些指令被編寫為一條接著一條執(zhí)行。現(xiàn)代微處理器會(huì)進(jìn)行「亂序執(zhí)行」。這意味著它們能夠快速分析指令緩沖區(qū),查看指令之間的依賴關(guān)系。示例如下:
01: mul r1, r2, r3 // r1 ← r2 × r302: add r4, r1, 5 // r4 ← r1 + 503: add r6, r2, 1 // r6 ← r2 + 1 乘法是一個(gè)緩慢的運(yùn)算過程,需要多個(gè)時(shí)鐘周期來執(zhí)行。第二條指令僅需等待,因?yàn)槠溆?jì)算取決于先知道放入 r1 寄存器的結(jié)果。但是,第三條指令并不取決于先前指令的計(jì)算結(jié)果,因此亂序處理器可以并行計(jì)算此指令。 但現(xiàn)實(shí)情況往往有數(shù)百條指令,CPU 能夠找出這些指令之間的所有依賴關(guān)系。
它通過查看每個(gè)指令的輸入來分析指令的輸入是否取決于一或多個(gè)其他指令的輸出,輸入和輸出指包含之前計(jì)算結(jié)果的寄存器。 例如上例中,add r4, r1, 5 指令依賴于來自 r1 的輸入,而 r1 通過 mul r1, r2, r3 指令得到。 我們可以將這些關(guān)系鏈接在一起,形成 CPU 可以處理的詳細(xì)圖。圖的節(jié)點(diǎn)表示指令,邊表示連接它們的寄存器。CPU 可以分析這類節(jié)點(diǎn)圖,并確定可以并行執(zhí)行的指令,以及在繼續(xù)執(zhí)行之前需要在哪一步等待多個(gè)相關(guān)計(jì)算結(jié)果。
許多指令可以很早完成,但是其結(jié)果無法正式化。我們無法提交這些結(jié)果,否則順序?qū)⒊霈F(xiàn)錯(cuò)誤。指令往往是需要按照順序執(zhí)行的。像堆棧一樣,CPU 將從頂部一直彈出已完成的指令,直到命中未完成的指令。 亂序執(zhí)行功能讓 M1 上的 Firestorm 核心發(fā)揮了重要作用,實(shí)際上它比英特爾或 AMD 的產(chǎn)品更加強(qiáng)大。 為什么英特爾和 AMD 的亂序執(zhí)行不如 M1? 「重排序緩沖區(qū)」(Re-Order Buffer,ROB)不包含常規(guī)的機(jī)器碼指令,即 CPU 從內(nèi)存中獲取的待執(zhí)行指令。這些是 CPU 指令集架構(gòu)(ISA)中的指令,也就是我們稱為 x86、ARM、PowerPC 等的指令。 但是,CPU 內(nèi)部會(huì)使用程序員無法看到的完全不同的指令集,即微操作(micro-op 或 μop),ROB 內(nèi)全是微操作。 微操作非常寬(包含很多位),能夠包含各種元信息。而 ARM 或 x86 指令則無法添加此類信息,因?yàn)闀?huì)發(fā)生:
程序的二進(jìn)制文件完全膨脹。
暴露 CPU 的工作原理細(xì)節(jié),比如是否具備亂序執(zhí)行單元、寄存器重命名等詳細(xì)信息。
很多元信息僅在當(dāng)前執(zhí)行情況下才有意義。
你可以將其視為,在編寫程序時(shí)有一個(gè)公共 API,需要保持穩(wěn)定并供所有人使用,那就是 ARM、x86、PowerPC、MIPS 等指令集。而微操作基本上是用于實(shí)現(xiàn)公共 API 的私人 API。 通常,微操作對于 CPU 而言更易于使用,因?yàn)槊織l微指令都能完成一項(xiàng)簡單的有限任務(wù)。常規(guī)的 ISA 指令可能更復(fù)雜,會(huì)導(dǎo)致大量事情發(fā)生,進(jìn)而實(shí)際上轉(zhuǎn)化為多個(gè)微操作。 CISC CPU 通常只使用微操作,否則大型復(fù)雜的 CISC 指令會(huì)讓 pipeline 和亂序執(zhí)行幾乎無法實(shí)現(xiàn)。 RISC CPU 有一個(gè)選擇,所以較小的 ARM CPU 不使用微操作,但這也意味著它們無法執(zhí)行亂序執(zhí)行等。 對于理解英特爾和 AMD 的亂序執(zhí)行不如 M1,這很關(guān)鍵。
快速運(yùn)行的能力取決于你可以用微操作填充 ROB 的速度及數(shù)量。填充的速度越快,這種能力就越大,你就有更多機(jī)會(huì)選擇可并行執(zhí)行的指令,性能就會(huì)進(jìn)一步提升。 機(jī)器碼指令被指令解碼器分割成多個(gè)微操作。如果有更多的解碼器,我們就可以并行分割更多的指令,從而更快地填充 ROB。 這就是存在巨大差異的地方。最糟糕的英特爾和 AMD 微處理器核心具有 4 個(gè)解碼器,這意味著它可以并行解碼 4 條指令,并輸出微操作。
但是蘋果有 8 個(gè)解碼器。不僅如此,ROB 還大了約 2 倍,基本上可以容納 3 倍的指令。沒有其他主流芯片制造商的 CPU 擁有如此多的解碼器。 為什么英特爾和 AMD 不能添加更多的指令解碼器? 這就牽扯到 RISC 了。M1 Firestorm 核心使用的是 ARM RISC 架構(gòu)。 對于 x86,一條指令的長度可能是 1–15 字節(jié)不等。而在 RISC 芯片上,指令大小是固定的。如果每個(gè)指令具有相同的長度,將字節(jié)流分割成指令并饋入 8 個(gè)不同的并行解碼器將易如反掌。但是在 x86 CPU 上,解碼器不知道下一條指令從哪里開始,它必須實(shí)際分析每條指令,判斷它的長度。
英特爾和 AMD 采用暴力方式處理這一問題,它們嘗試在每個(gè)可能的起點(diǎn)上解碼指令。這意味著必須處理大量錯(cuò)誤的猜測和錯(cuò)誤。這讓解碼器階段變得非常復(fù)雜,也很難再添加更多的解碼器。相比而言,蘋果輕輕松松就可以添加更多解碼器。 實(shí)際上,添加更多東西會(huì)導(dǎo)致許多其他問題,以至于 AMD 本身的 4 個(gè)解碼器基本上已經(jīng)是其上限了。 而正是這一點(diǎn)讓 M1 Firestorm 核心在相同的時(shí)鐘頻率下處理的指令數(shù)量是 AMD 和英特爾 CPU 的兩倍。 有人可能會(huì)反駁說,CISC 指令會(huì)變成更多的微操作,它們的密度更大,因此解碼一條 x86 指令類似于解碼兩條 ARM 指令。 然而實(shí)際上,高度優(yōu)化的 x86 代碼很少使用復(fù)雜的 CISC 指令。在某些方面,它具有 RISC 風(fēng)格。 但這對 Intel 或 AMD 沒有幫助,因?yàn)榧词?15 個(gè)字節(jié)長的指令很少見,也必須制造解碼器來處理它們。而這會(huì)導(dǎo)致復(fù)雜性,從而阻止 AMD 和 Intel 添加更多解碼器。 AMD 的 Zen3 核心不還是更快嗎? 據(jù)了解,最新 AMD CPU 核心(即 Zen3)要比 Firestorm 核心快一點(diǎn)。但這只是因?yàn)?Zen3 核心的時(shí)鐘頻率為 5 GHz,F(xiàn)irestorm 核心的時(shí)鐘頻率為 3.2 GHz。盡管時(shí)鐘頻率高了近 60%,但 Zen3 也只是勉強(qiáng)超越 Firestorm。 那蘋果為什么不增加時(shí)鐘頻率呢?因?yàn)楦叩臅r(shí)鐘頻率會(huì)使芯片變熱。這也是蘋果的主要賣點(diǎn)之一。與 Intel 和 AMD 的產(chǎn)品不同,他們的計(jì)算機(jī)幾乎不需要冷卻。 從本質(zhì)上講,我們可以說 Firestorm 核心確實(shí)優(yōu)于 Zen3 核心。Zen3 只能通過更大的電流和變得更熱來維持領(lǐng)先。而蘋果選擇不這樣做。
如果蘋果想要更高的性能,他們只會(huì)增加更多的核心。這樣就可以在降低功耗的同時(shí),還能提供更高的性能。 未來將會(huì)如何 看來 AMD 和英特爾在兩個(gè)方面都陷入了困境:
它們沒有允許其輕松追求異構(gòu)計(jì)算和 SoC 設(shè)計(jì)的商業(yè)模型。
傳統(tǒng)的 x86 CISC 指令集讓它們難以提高亂序執(zhí)行性能。
但這不意味著游戲結(jié)束。它們當(dāng)然可以增加時(shí)鐘頻率,使用更多的散熱,添加更多核心,增強(qiáng) CPU 緩存等。但它們目前都處于劣勢。英特爾的情況最糟糕,因?yàn)槠浜诵囊呀?jīng)被 Firestorm 擊敗,并且它的 GPU 薄弱,無法集成到 SoC 方案中。 引入更多核心的問題在于,對于典型的桌面工作負(fù)載,使用過多核心會(huì)導(dǎo)致收益遞減。當(dāng)然,很多核心非常適合服務(wù)器。但 Amazon 和 Ampere 等公司已經(jīng)使用 128 核的巨型 CPU 了。 幸運(yùn)的是,Apple 并未出售其芯片。因此,PC 用戶只能接受 AMD 和英特爾提供的產(chǎn)品。PC 用戶可能會(huì)跳船,但這是一個(gè)緩慢的過程。人們通常不會(huì)立即離開已經(jīng)有大量投入的平臺(tái)。 但是,年輕的專業(yè)人士沒有在任何平臺(tái)上投入太多資金,他們將來可能會(huì)越來越多地轉(zhuǎn)向蘋果,從而擴(kuò)大蘋果在高端市場的份額和在 PC 市場總利潤中的份額。 參考內(nèi)容: https://erik-engheim.medium.com/why-is-apples-m1-chip-so-fast-3262b158cba2
原文標(biāo)題:蘋果M1芯片為何如此快?
文章出處:【微信公眾號(hào):FPGA技術(shù)江湖】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
芯片
+關(guān)注
關(guān)注
459文章
52503瀏覽量
440736 -
ARM
+關(guān)注
關(guān)注
134文章
9352瀏覽量
377467 -
蘋果
+關(guān)注
關(guān)注
61文章
24545瀏覽量
203946
原文標(biāo)題:蘋果M1芯片為何如此快?
文章出處:【微信號(hào):HXSLH1010101010,微信公眾號(hào):FPGA技術(shù)江湖】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
用于 Cat M1/1/NTN 和 WCDMA HSDPA/HSUPA/HSPA(頻段 1、2、4、5、8)和 CDMA(頻段類別 0、1、6、15)的多模式、多頻段功率放大器模塊 skyworksinc

M3 Ultra 蘋果最強(qiáng)芯片 80 核 GPU,32 核 NPU

THS8135進(jìn)行YUV輸出,如何配置M1,M2,還有SYNC_T這些信號(hào)?
M1攜手6D Technologies云原生BSS平臺(tái)實(shí)現(xiàn)轉(zhuǎn)型
中軟高科身份證讀取及M1卡讀寫二合一機(jī)具開發(fā)文檔
THS8135不需要外部再引入SYNC/BLANK信號(hào),M1/M2/CLK & SYNC/SYNC_T/BLANK信號(hào)應(yīng)該怎樣處理?
蘋果M5系列芯片量產(chǎn)及新品搭載計(jì)劃曝光
蘋果發(fā)布M4系列芯片,AI PC領(lǐng)域競爭白熱化
蘋果發(fā)布新款MacBook Pro,M4 Max芯片性能提升3.5倍
蘋果發(fā)布搭載M4芯片的iMac
快充協(xié)議芯片的特點(diǎn)
快充工作原理,解讀什么是快充協(xié)議及協(xié)議芯片的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論