 研發全新多模態感知AI框架 AI能同時模擬人眼和手預測物體運動
研發全新多模態感知AI框架 AI能同時模擬人眼和手預測物體運動

據外媒VentureBeat報道,來自三星、麥吉爾大學和約克大學的研究人員,近日研發出一個全新的生成式多模態感知AI框架,能夠根據物體初始狀態的視覺和觸覺數據,來預測出物體的運動趨勢。
據悉,這是第一個利用視覺和觸覺感知來學習多模態動力學模型的研究。
運動預測是自動化領域的一大關鍵技術,通過預判物體和環境的交互方式,自動化系統得以作出更加智能的決策。該團隊的這項研究,似乎又將這一技術的應用向前推進了一步。
這篇論文名為《基于多模態的生成模型指導的直觀物理研究(Learning Intuitive Physics with Multimodal Generative Models)》,已發表于arXiv平臺。
論文鏈接:
https://arxiv.org/pdf/2101.04454.pdf
一、運動預測有挑戰:摩擦力、壓力難確定
假如你要接住一個掉落的物體,你會迅速判斷它的運動走向,然后準確接住它。
但對于一個機器人來說,要準確預測出物體還未發生的運動趨勢,可不是一件容易的事。
近期,不少運動預測方面的AI研究,都指出了觸覺和視覺之間的協同作用。
其中,觸覺數據可以反映物體和環境間的作用力、由此產生的物體運動和環境接觸等關鍵信息,提供一種展現物體與環境交互過程的整體視角;視覺數據則可以直觀反映了立體形狀、位置等物體屬性。
在本文研究人員看來,視覺、觸覺信號的組合,或有助于推測出物體運動后的最終穩定狀態。
研究人員在論文寫道:“先前的研究表明,由于摩擦力、幾何特性、壓力分布存在不確定性,預測運動對象的軌跡具有挑戰性。”
比如推一個瓶子,如何準確預測這個動作的結果,接下來這個瓶子是會向前移動,還是會翻倒?
▲《基于多模態的生成模型指導的直觀物理研究(Learning Intuitive Physics with Multimodal Generative Models)》論文插圖
為了減少這種不確定性,研究團隊設計并實現了一個由軟硬件組成的高質量AI感知系統,經訓練后,該系統能捕獲到運動軌跡中最關鍵、最穩定的元素,從而準確測量和預測物體落在表面上的最終靜止狀態。
二、開發新型視覺觸覺傳感器,打造多模態感知系統
動態預測常被表述為一個高分辨率的時間問題,但在此項研究中,研究人員關注的是物體運動后的最終結果,而不是預測細粒度的物體運動軌跡。
研究人員認為,關注未來關鍵時間的結果,有助于大大提高模型預測的準確度和可靠性。
該研究團隊開發了一款名為“透視肌膚(STS,See-Through-Your-Skin)”的新型視覺-觸覺多模態傳感器,可以同時捕捉物體的視覺和觸覺特征數據,并重建在1640×1232的高分辨率圖像中。
由于光學觸覺傳感器通常使用不透明和反光的涂料涂層,研究人員開發了一種具有可控透明度的薄膜,使得傳感器能同時采集關于物理交互的觸覺信息和傳感器外部世界的視覺信息。
具體而言,研究人員通過改變STS傳感器的內部照明條件,來控制傳感器的觸覺和視覺測量的占空比,從而設置了反光涂料層的透明度。
如上圖左上角所示,利用內部照明可將傳感器表面變成透明,從而使得傳感器內置攝像頭能直接采集傳感器外部世界的圖像;上圖的左下角顯示,傳感器也可以保持內外一致的亮度,通過感知膜形變來采集物理交互觸覺信息。
借助STS傳感器和PyBullet模擬器,研究人員在動態場景中快速生成大量物體交互的視覺觸覺數據集,用于驗證其感知系統的性能。
受多模態變分自編碼器(MVAE)啟發,研究團隊設計了一個生成式多模態感知系統,在一個統一的MVAE框架內集成了視覺、觸覺和3D Pose反饋。
MVAE可以解讀STS傳感器采集的視覺、觸覺數據,將所有模態的物體關鍵信息映射到一個共享的嵌入空間,用于推斷物體在運動后最終的穩定狀態。
實驗結果表明,MVAE架構可以被訓練用于預測多模態運動軌跡中最穩定和信息最豐富的元素。
三、不懼單一模態信息缺失,準確預測物體未來狀態
該研究團隊生成的視覺觸覺數據庫主要包含三種動態模擬場景,分別是物體在平面上自由落體、物體在斜面上下滑、物體在靜止狀態下收到外力擾動。
下圖顯示了模擬三種動態場景的示例集,頂部一行顯示3D Pose視圖,中間一行、底部一行分別顯示STS傳感器采集的視覺和觸覺結果。
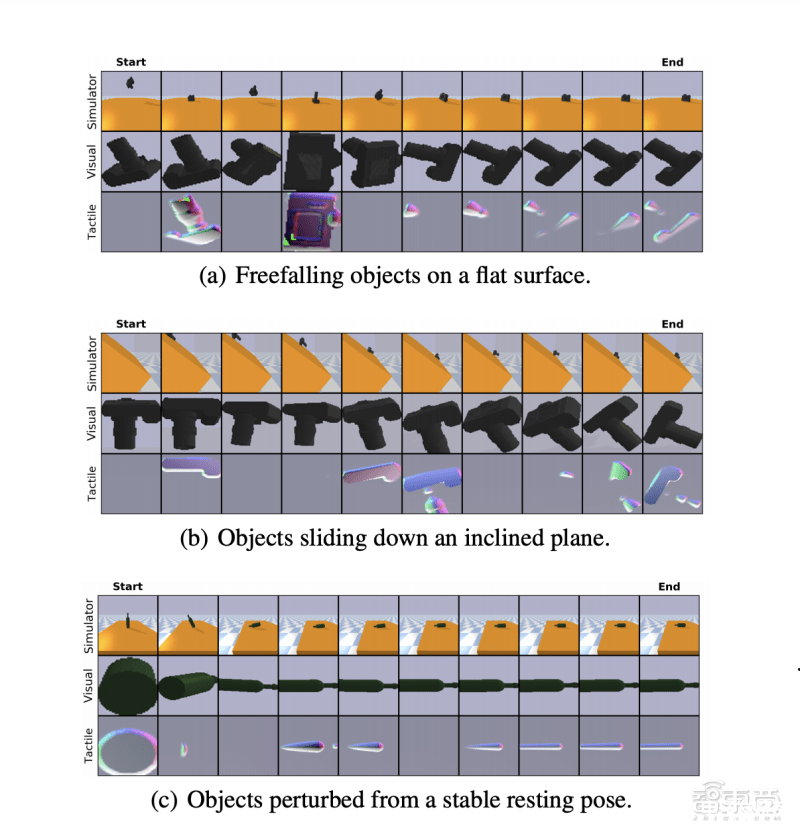
研究人員在三種模擬動態場景和使用STS傳感器的真實實驗場景中,分別驗證了其動力學模型的預測能力。
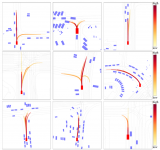
如下方圖表顯示,在三種模擬場景中的固定步和最終步預測中,相比僅依賴視覺(VAE-visual only)或僅依賴觸覺(VAE-tactile only)的單模態感知模型,多模態感知模型(MVAE)在驗證集中的二進制交叉熵誤差(BCE)均值更小,即預測結果的準確性更高。
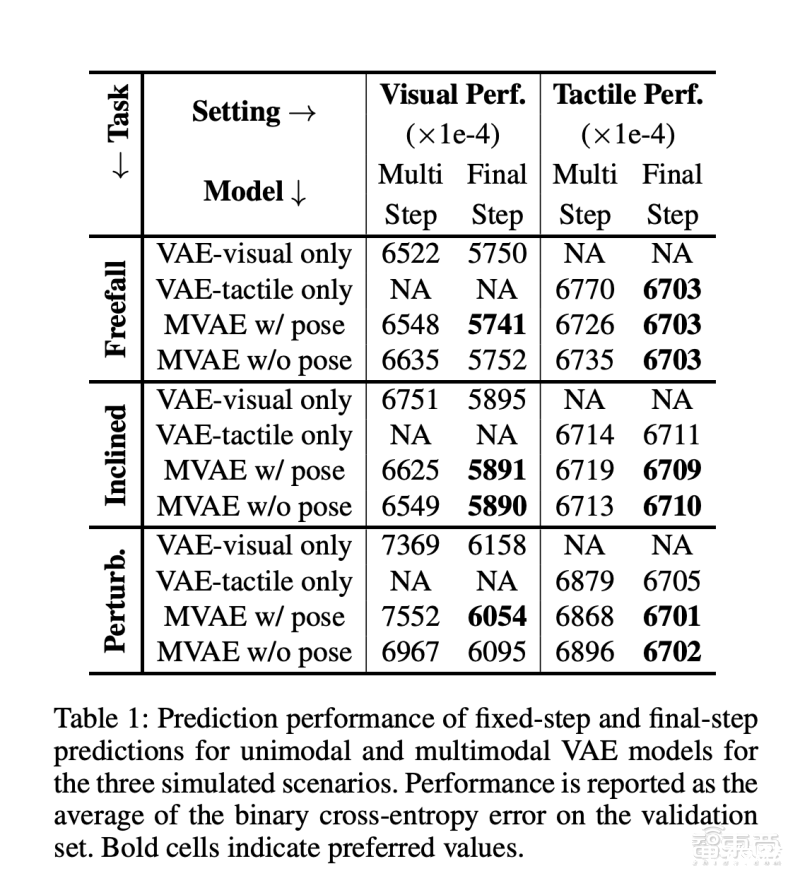
研究人員還用基于高時間分辨率的模型進行對比實驗,發現這一模型在預測物體最終靜止狀態時,準確性要高于動態模型。這是由于不確定性和錯誤會隨著時間前向傳播,導致模糊和不精確的預測。
結果表明,在對中間狀態不感興趣的動態場景中,該AI框架能以更高的準確度來預測最終結果,而無需明確推理中間步驟。
此外,由于該研究方法破譯了觸覺、視覺、物體姿態之間的映射關系,因此即便某一模態信息缺失,比如缺乏觸覺信息時,該框架仍然可以從視覺信息推測出視覺信息,從而預測物體運動后的最終落點。
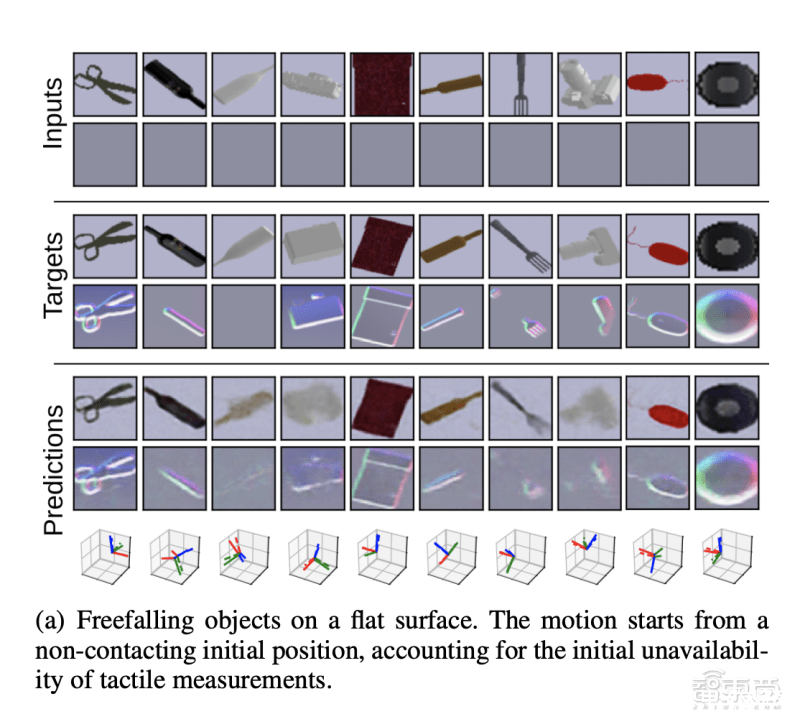
結語:制造業自動化將是運動預測的一大應用場景
該研究團隊的這項新成果能夠基于觸覺、視覺的雙模態數據對物體的運動軌跡進行預判,并推測出物體的最終靜止狀態。
相較于以往的運動預測技術,該研究團隊實現了觸覺和視覺數據的雙向推測,為制造業的自動化場景提供了更多的可能性。
比如,揀貨機器人能夠更準確地判斷貨物的運動狀態,從而提高拾取精度;貨架機器人能夠提前預判貨物的運動軌跡,從而防止貨物跌落破損,減少損失。
不過,這項成果能夠預測的運動狀態還相對有限,我們期待研究團隊對復雜的運動模式、多樣的物體形態進行更多的模擬和技術攻關。
責任編輯:PSY
-
AI
+關注
關注
88文章
35164瀏覽量
279940 -
自動化
+關注
關注
29文章
5784瀏覽量
84875 -
智能感知
+關注
關注
2文章
106瀏覽量
18073 -
運動物體
+關注
關注
0文章
4瀏覽量
6785
發布評論請先 登錄
信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代

設備預測性維護進入2.0時代:多模態AI如何突破誤報困局

海康威視發布多模態大模型AI融合巡檢超腦
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
安霸在ISC West上推出下一代前端多模態AI技術
采用可更新且具區分度錨點的多模態運動預測研究





 工商網監
工商網監
評論