 一種端到端的單階段多視圖融合3D檢測方法MVAF-Net
一種端到端的單階段多視圖融合3D檢測方法MVAF-Net
該方法將激光雷達投影的BEV和前向視角、與攝像頭視角圖像作為檢測輸入,在特征融合中,提出attentive pointwise fusion (APF) 模塊。設計attentive pointwise weighting (APW) 模塊學習,附加另外兩個任務foreground分類和中心回歸。

如圖是架構圖:整個MVAF-Net包括三個部分
1)單視圖特征提取(SVFE),
2)多視圖特征融合(MVFF)
3)融合特征檢測(FFD)。
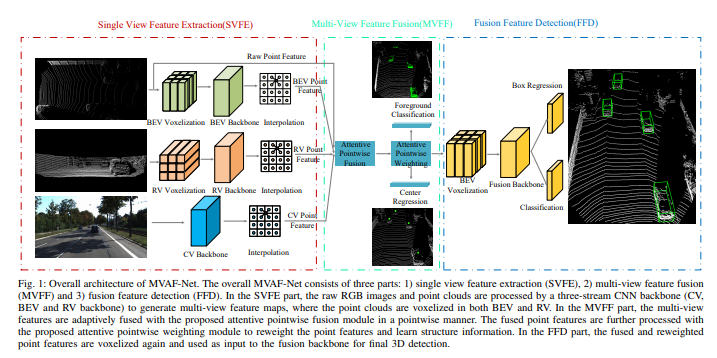
在SVFE部分,原始的RGB圖像和點云由3-stream CNN主干(CV,BEV和RV)處理,生成多視圖特征圖,在BEV和RV做點云體素化。在MVFF部分,多視圖特征與attentive pointwise fusion模塊逐點自適應融合。融合的點特征通過attentive pointwise weighting模塊進一步處理,對點特征進行加權并學習結構信息。在FFD部分,對融合和重加權的點特征再次體素化,并作融合主干輸入給最終的3D檢測。
RV投影表示為柱面坐標系統:
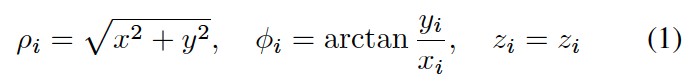
attentive pointwise fusion模塊架構如下:
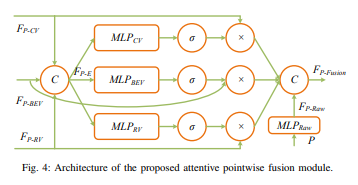
而attentive pointwise weighting模塊架構如下:
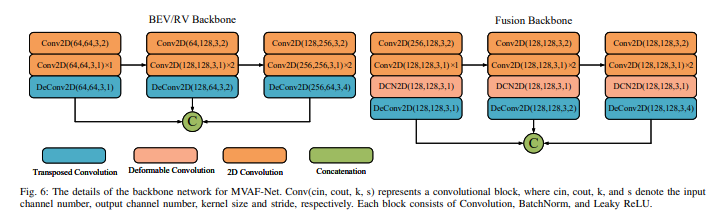
MVAF-Net的主干網絡細節如下圖:
檢測頭包括:分類(focal loss)、框回歸(SmoothL1 loss)和方向分類(softMax loss)。其總loss函數為
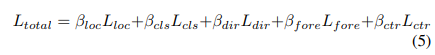
最后兩個是前景分類項(focal loss)和中心回歸項(SmoothL1 loss)。
結果如下:
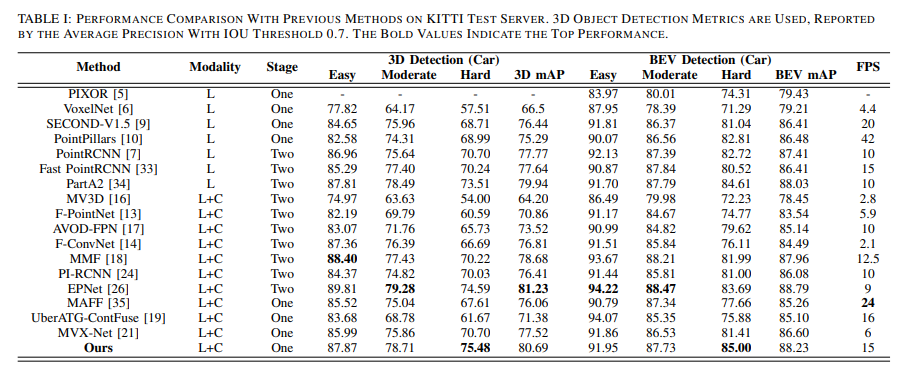
結論
我們提出了一種端到端的單階段多視圖融合3D檢測方法MVAF-Net,它由三部分組成:單視圖特征提取(SVFE),多視圖特征融合(MVFF)和融合特征檢測(FFD)。在SVFE部分,三流CNN主干(CV,BEV和RV主干)使用LiDAR點云和RGB圖像來生成多視圖特征圖。在MVFF部分,使用我們提出的注意點向融合(APF)模塊實現了多視圖特征的自適應融合,該模塊可以使用注意力機制自適應地確定從多視圖輸入中引入了多少信息。此外,我們通過提出的注意點加權(APW)模塊進一步改善了網絡的性能,該模塊可以對點特征進行加權并通過兩個額外的任務來學習結構信息:前景分類和中心回歸。大量實驗驗證了所提出的APF和APW模塊的有效性。此外,所提出的MVAF-Net產生了競爭性結果,并且在所有單階段融合方法中均達到了最佳性能。此外,我們的MVAF-Net勝過大多數兩階段融合方法,在KITTI基準上實現了速度和精度之間的最佳平衡。
責任編輯:lq
-
模塊
+關注
關注
7文章
2736瀏覽量
47767 -
攝像頭
+關注
關注
60文章
4868瀏覽量
96359 -
激光雷達
+關注
關注
968文章
4031瀏覽量
190451
原文標題:相機與激光雷達融合的3D目標檢測方法MVAF-Net
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SciChart 3D for WPF圖表庫
sc單模單纖耦合器、有接收端和發射端區分嗎?
單端功放和雙端的區別是什么
差分轉單端電路作用是什么
差分放大電路單端輸入和雙端輸入的區別
蘇州吳中區多色PCB板元器件3D視覺檢測技術


采用端到端的逆設計方法實現多維度多通道超構表面全息設計
移動協作機器人的RGB-D感知的端到端處理方案





 工商網監
工商網監
評論