 如何通過蒸餾來使小模型具有更好的性能
如何通過蒸餾來使小模型具有更好的性能
之前我們討論了『模型壓縮與蒸餾!BERT的忒修斯船』,算是一個開篇。本文繼續討論關于模型蒸餾(Distilling Knowledge)及關于BERT模型的知識蒸餾,分享針對具體任務時可行的簡潔方案,同時在新的視角下探討了知識蒸餾有效的一些原因,并通過實驗進行驗證。
模型蒸餾的最重要的一個特點就是降低資源使用以及加速模型推理速度,而小模型往往性能較低,本文總結如何通過蒸餾來使小模型具有更好的性能。
Distilling the Knowledge in a Neural Network
這篇是2015年Hinton發表的,也是我看到的最早提出Knowledge Distillation的論文[1]。
在這篇論文中,Hinton指出one-hot 的label只指示了true label 的信息,但是沒有給出negative label 之間、negative 與 true label之間的相對關系,比如:
現在的任務是給定一個詞(比如:蘋果),然后判斷詞對應的類別(電視/手機/水果/汽車),假如現在我們有兩個樣本:(蘋果,[0,0,1,0])和(小米,[0,1,0,0])而one-hot 形式的label并不能告訴我們,蘋果中 label是水果的概率高出label是拖拉機的概率,稍低于是手機的概率,而小米中label是電視的概率稍低于是手機的概率,但是同時要高于是汽車和水果的概率,這些相對關系在one-hot 形式的label中是無法得到的。
而這些信息非常重要,有了這些信息,我們可以更容易的學習任務。于是提出了Teacher-Student模式,即用一個大的復雜的模型(也可以是ensemble后的)來先學習,然后得到label的相對關系(logits),然后將學習到的知識遷移到一個小模型(Student)。
Distilling
具體遷移過程是Student 在進行training 時,除了學習ground truth 外,還需要學習label 的probability(softmax output),但是不是直接學習softmax output,而是學習soften labels,所謂soften labels 即經過Temperature 平滑后的 probability,具體形式:
其中T 越大,對應的probability 越平滑,如下圖所示。而平滑probability 可以看作是對soften label的一種正則化手段。
更直觀的實驗請查閱Knowledge Distillation From Scratch[2]
Distill BERT
看到的第一篇針對 BERT 模型做蒸餾的是Distilling Task-Specific Knowledge from BERT into Simple Neural Networks[3]。
在這篇論文中,作者延續Hinton 的思路在BERT 上做實驗,首先用BERT-12 做Teacher,然后用一個單層Bi-LSTM 做Student,loss 上除了ground truth 外,也選擇了使用teacher 的logits,包括Temperature 平滑后的soften labels 的CrossEntropy和 logits 之間的MSE,最后實驗驗證MSE效果優于CE。
此外,由于是從頭開始訓練Student,所以只用任務相關數據會嚴重樣本不足,所以作者提出了三種NLP的任務無關的data augment策略:
mask:隨機mask一部分token作為新樣本,讓teacher去生成對應logits ;
根據POS標簽去替換,得到 ”What do pigs eat?" -> " How do pigs ear?"
n-gram采樣:隨機選取n-gram,n取[1-5],丟棄其余部分。
在Distilling the Knowledge in a Neural Network[4]中曾指出 logits 之間的CrossEntropy是可以看作是MSE 的近似版本,不過這里作者的結論是MSE 更好。
此外,由于Hinton 實驗時是巨大數據量,所以不存在樣本不足的情況,而普通實驗時都會遇到遷移時訓練樣本不足,需要做數據增強的問題。
TinyBERT
TinyBERT 出自TinyBERT: Distilling BERT for Natural Language Understanding[5]。
由于Transformer 結構在NLP 任務中的強大能力,作者選擇用與BERT 同結構的方式做Student。此外,為了提高KD后模型性能,做了更細致的工作:
Student選擇一個更窄更淺的transformer;
將KD也分為兩個階段:pre-train 和 fine-tuning,并且在兩個階段上都進行KD;
使用了更多的loss:Embedding之間的MSE,Attention Matrix中的logits之間的MSE,Hidden state之間的MSE以及最后的分類層的CE;
為了提高下游任務fine-tuning后的性能,使用了近義詞替換的策略進行數據增強。
優點
6層transformer基本達到了bert-12的性能,并且hidden size更小,實際是比bert-6更小的;
因為有pre-train KD,所以可以拿來當bert 一樣直接在下游fine-tuning。
缺點
由于hidden size的不同,所以為了進行MSE,需要用一個參數矩陣W 來調節,這個參數只在訓練時使用,訓練完后丟棄,這個矩陣沒有任何約束,覺得不優雅;
其次,student model的每一層都需要去學習teacher model的對應的block的輸出,如何對不同的層如何設計更好的權重也是一個費力的事;
雖然student的結構也是transformer,但是由于hidden size 不同,沒法使用teacher的預訓練結果,但是我覺得這里其實可以用降維的方式用teacher的預訓練結果,可能不需要pretraining的階段了也說不定。
DistilBERT
DistilBERT 出自DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[6]。
論文中作者通過調查發現BERT 中的hidden size 對計算效率的改變比hidden layer nums 的影響小,說白了就是「讓模型變矮比讓模型變瘦效率更高」,所以作者使用了一個更矮的BERT來做Student 來遷移BERT 中的知識。
由于DistilBERT 是一個與BERT 同結構只是層數更小,所以DistilBERT 可以用BERT 的預訓練的權重進行初始化。此外,DistilBERT 是一個與任務無關的模型,即與BERT 一樣,可以對很多下游任務進行fine-tuning。
由于DistilBERT 與 BERT 的前幾層一致,所以loss 的選擇上就更多一些,作者選擇了triple loss:MLM loss + embedding cosin loss + soften labels cross entropy loss
優點
DistilBERT 做到了與BERT 一樣,完全與任務無關,不需要添加額外的Distillation 階段(添加后結果會更好)。
MobileBERT
MobileBERT 出自MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices[7]。
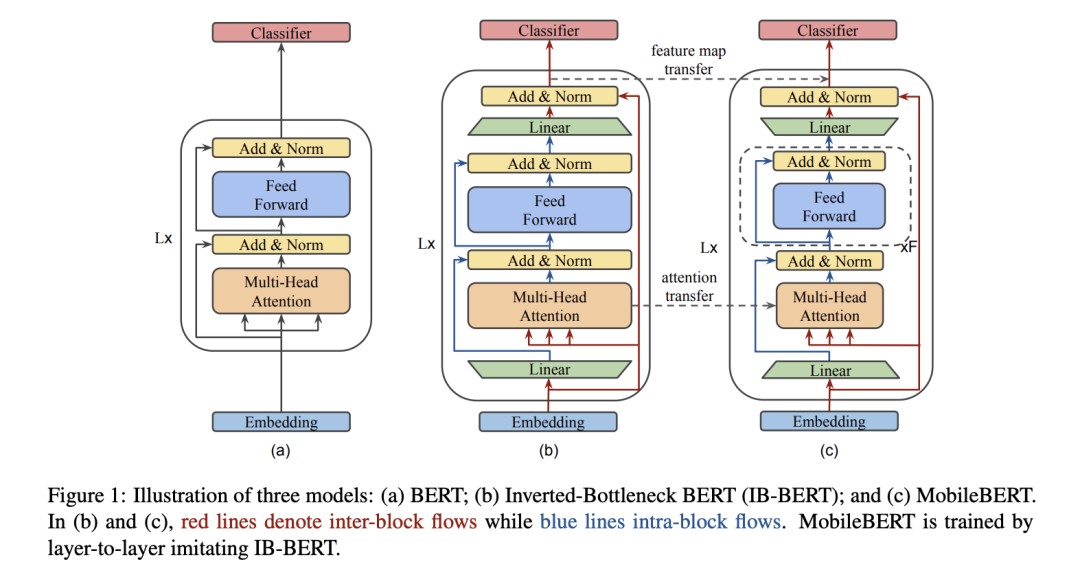
作者同樣采用一個transformer 作為基本結構,但作者認為深度很重要,寬度較小對模型損壞較小,所以整體架構是保持模型深度不變,通過一個矩陣來改變feature size,即bottleneck,再通過在block的前后插入兩個bottleneck,來scale feature size。
由于MobileBERT太窄太深,所以不好訓練,作者提出新的方式,通過一個同深但是更寬的同架構的模型來訓練 作為teacher,然后用MobileBERT遷移。
loss 設計上主要包括三部分:feature map之間的MSE,Attention logits之間的KL,以及pre-training MLM + pre-training-NSP + pre-training-KD
訓練策略上,有三種方式:
將KD作為附加預訓練的附加任務,即一起訓練;
分層訓練,每次訓練一層,同時凍結之前的層;
分開訓練,首先訓練遷移,然后單獨進行pre-training。
此外,為了提高推理速度,將gelu 替換為更快的 relu ,LayerNormalization 替換為 更簡單的NoNorm,也做了量化的實驗。
優點
首先mobileBERT容量更小,推理更快,與任務無關,可以當bert來直接在下游fine-tuning,而之前的KD大多數時候需要與任務綁定并使用數據增強,才能達到不錯的性能;
論文實驗非常詳實,包括如何選擇inter-block size, intra-block size, 不同訓練策略如何影響等;
訓練策略上,除了之前的一起訓練完,實驗了兩種新的訓練方式,而最終的一層一層的訓練與skip connection 有異曲同工的作用:每層都學一小部分內容,從而降低學習的難度;
替換了gelu 和 LayerNormalization,進一步提速。
缺點
要訓練一個IBBERT作為teacher,而這個模型容量與BERT-Large差不多,增加了訓練難度.
總結
以上論文的遷移過程其實可以總結為兩類:
soft label遷移,即主要遷移Teacher 模型最后分類層的logits 及相應的soft label;
feature遷移,即除了最后分類層外,還遷移Teacher 模型中的output/attention/embedding等特征。
Student 的選擇上,除了自定義外,還可以選擇跟Teacher 同結構,而為了降低參數量,可以選擇將模型變矮/變窄/減小hidden size 等方式。
而為了蒸餾后的模型能更加的general,適應更多的task,就需要遷移更多的信息,設計上也越復雜。
想法
實際工作上,大多數時候我們都是需要一個task 來做模型,而以上論文中告訴我們,遷移的信息越多,Student 的性能越好。
而針對具體task ,我覺得比較簡潔有效的一種方式是采用更矮的Teacher 來作為Student ,這樣可以直接將Teacher 中的前幾層的信息完全遷移過來,然后在object 上,加入遷移Teacher 在train data 上的logits ,這樣就可以比較有效的進行蒸餾了。
除此之外,讓我們換個角度看看為什么logits 能增強Student 模型的性能呢?除了遷移的角度外,其實logits 提供了label 更多的信息(不同類別的相對關系),而這個額外信息只要優于隨機分布,就能對模型提供更多的約束信息,從而增強模型性能,即當前的模型可以看作是分別擬合ground truth 和 logits的兩個模型的ensemble,只不過是兩個模型共享參數。
上面我們提到只要logits 優于隨機,對Student 模型來說就會有所提升,那logits 由誰產生的其實并不重要。所以,我們除了可以用Teacher 產生的logits來增強Student 模型外,我們還可以增強Teacher 模型,或者直接用Student 先學習一下,產生logits,再用Student 去遷移上次產生的logits。
想到這里,我不禁的有個大膽的想法:既然我可以一邊生成logits, 一邊學習logits,那我不是可以持續這個過程,直到模型完全擬合train data,生成的logits退化為one-hot,那此時的模型是不是能得到一個非常大的提升呢?
實驗
實驗的基本設置是用12層bert 作為Teacher model ,用3層bert 作為Student model 。soften labels 采用Temperature 平滑后的結果,此外,Student model 除了學習 soften labels 的外,也需要學習ground truth。
Teacher-to-Student
Teacher model 在train data 上訓練,然后在train data 上生成對應的soften labels,Student model 學習ground truth 和 soften labels。
student-to-student
既然soften labels 是一種對labels 的一種平滑估計,那我們可以用任何方式去估計他,所以這里我們就用student 去做一個估計:student model 在train data 上進行訓練,然后在train data 上生成對應的soften labels ,將 student model 利用bert 預訓練結果重新初始化,然后去學習ground truth 和 soften labels.
normal-noise-training
既然是對labels 的一個估計,那假如給一個隨機的估計,只要保證生成的logits 中true label 對應的值最大,就能對Student 模型進行一定程度的提升:直接在train label 上添加一個normal noise ,然后重新進行平滑后歸一,作為soften labels讓student model 去學習。
實驗結果
從結果中可以看到:
優于隨機的logits 對Student 模型有一定的提升,估計越準確,提升越高;
越大的模型性能越好;
迭代進行logits 的生成與訓練不能進一步提高模型性能,原因主要是新的logits 分布相比之前的對模型的提升非常小,此外這個分布也比較容易擬合,所以無法進一步提升。
責任編輯:lq
-
容量
+關注
關注
0文章
117瀏覽量
21280 -
模型
+關注
關注
1文章
3371瀏覽量
49289 -
nlp
+關注
關注
1文章
489瀏覽量
22123
原文標題:模型壓縮與蒸餾!BERT家族的瘦身之路
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
IBM在watsonx.ai平臺推出DeepSeek R1蒸餾模型
DeepSeek模型成功部署,物通博聯在 AI 賦能工業上持續探索、不斷前行
Gitee AI 聯合沐曦首發全套 DeepSeek R1 千問蒸餾模型,全免費體驗!





 工商網監
工商網監
評論