 最新終端機器學習研究的最新進展
最新終端機器學習研究的最新進展

演講內容主要包括介紹回顧最新終端機器學習研究的最新進展,介紹Google發布終端設備視覺開發工具,包括TFLite視覺任務API、開源MediaPipe系統、ML Kit開發包等,以及實戰開發經驗。同時還包括高效終端機器設備視覺技術未來發展方向,例如硬件加速下的深度學習以及端上多任務學習等等。
大家好,我是來自Google Research的高級軟件工程師汪啟扉,首先感謝LiveVideoStack邀請我在此處演講。今天,我的主題是高效終端設備機器學習的最新進展 。
本次演講將包括五個主要部分。首先,我將簡要介紹端上機器學習。其次我將討論如何建立適合移動端的機器學習模型,在第三和第四部分 ,我將分別介紹適用于移動應用的端上機器學習優化,以及基于隱私保護的端上機器學習的最新研究。最后,我將討論端上機器智能的未來工作的展望。
1 端上機器學習
1.1 什么是端上機器學習
得益于深度學習的巨大成功,我們周圍的設備、機器、事物都變得越來越智能。智能手機、家庭助理、可穿戴設備等設備、自動駕駛汽車、無人機之類的機器,以及諸如電燈開關、家用傳感器之類的機器,正在利用機器智能來支持自動翻譯、自動駕駛、智能家居等應用。比如智能手機、家庭助理、可穿戴設備等;機器方面有自動駕駛汽車、無人機,生活中的器件包括電燈開關、家用傳感器之類的機器 。這些機器都正在利用自動翻譯、自動駕駛、智能家居等功能。用戶可以隨心所以地使用機器智能并享受其中。
早年,由于移動端上的計算資源非常有限,大多數機器智能都利用云計算實現。在基于云的機器智能中,源數據會發送到云端進行智能推理,然后將結果下載到本地設備。此類基于云和客戶端的系統可能會遭受延遲、隱私和可靠性方面的困擾。不過最近,我們注意到將智能推理從云端遷移到邊緣端以改善這些問題的趨勢。
1.2為什么我們需要端上機器學習
在基于云的機器智能應用中,用戶和設備間的長交互延遲通常是由不穩定的網絡帶寬引起的。通過將機器智能轉移到客戶端可以提供穩定的低交互延遲。
機器智能需要訪問私有用戶數據,例如用戶圖片、文檔、電子郵件、語音等。機器將所有數據上傳到云中可能會引起隱私和安全問題。由于端上機器只能在本地設備上處理所有數據,因此可以保護用戶私有數據免受惡意軟件攻擊。
最后,即使在網絡不可用或云服務關閉的情況下,將智能計算移到端上可以保持智能服務始終可用。
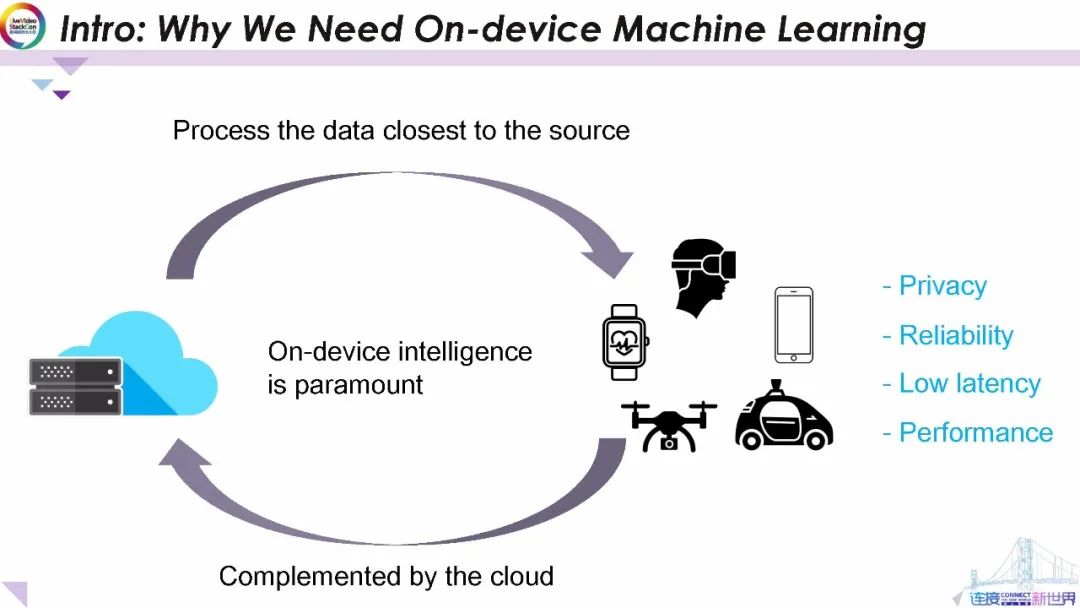
因此,端上機器智能已成為智能和移動領域重點研究方向。通過隱私保護的云端計算可以很好地平衡延遲、可靠性、隱私和性能等問題。
1.3端上推理
基本上,因此,端上智能是通過使用來自設備傳感器(例如攝像頭、麥克風、和所有其他傳感器)的輸入信號在設備上運行深度學習推理來實現。該模型完全在設備上運行而無需與服務器通信。
1.4 挑戰
有限的計算資源
雖然應用終端設備機器學習顯示出巨大優勢,但仍然面臨許多挑戰。首要的挑戰是有限的計算資源,在過去的幾十年中,我們注意到了移動芯片組的計算能力遵循摩爾定律而不斷提高。但是,與具有分布式計算系統的云集群相比,單臺設備的計算資源仍然非常有限,無法滿足新興應用程序不斷增長的計算需求。
有限的功率
如今,用戶對設備的使用比以往任何時候都多,每款新手機都在不斷提升電池容量并且支持快速充電功能。但是,設備的有限功率仍然是長續航時間的主要挑戰。
設備過熱
此外,高功耗通常導致設備過熱,尤其是對于可穿戴設備,這會影響用戶體驗并引起安全隱患。
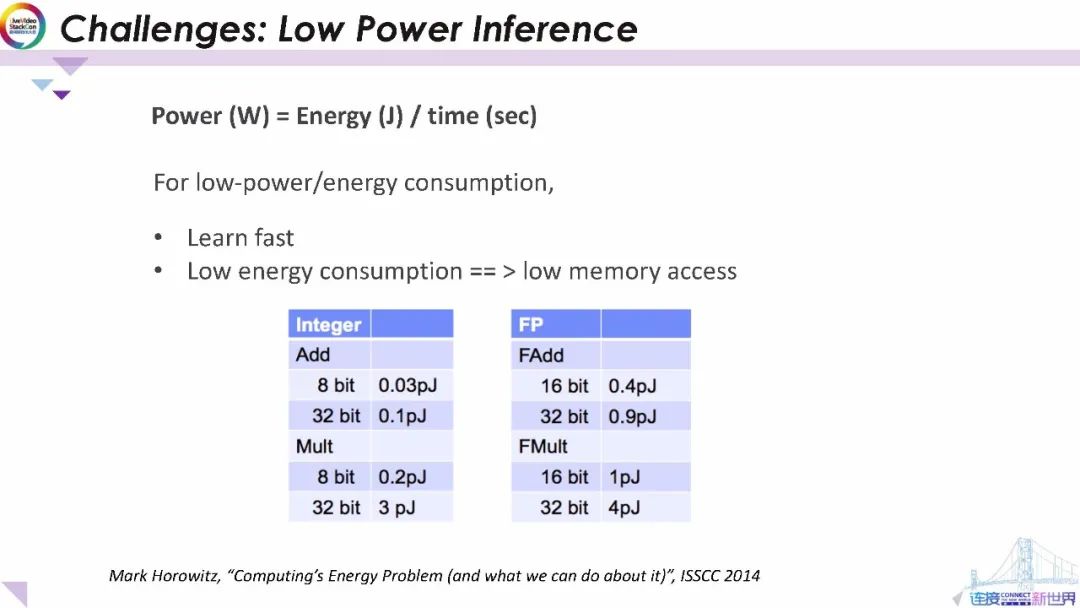
從實驗數據中可以看出,機器學習使用的浮點計算會比整數計算需要更高的功耗。為了快速學習并降低功耗和內存的使用,我們必須優化機器智能模型以滿足終端設備應用在功耗、內存和延遲上的限制。
2 建立適合移動端的機器學習模型

現在,讓我們討論如何建立適合移動端的智能模型。
2.1模型效率
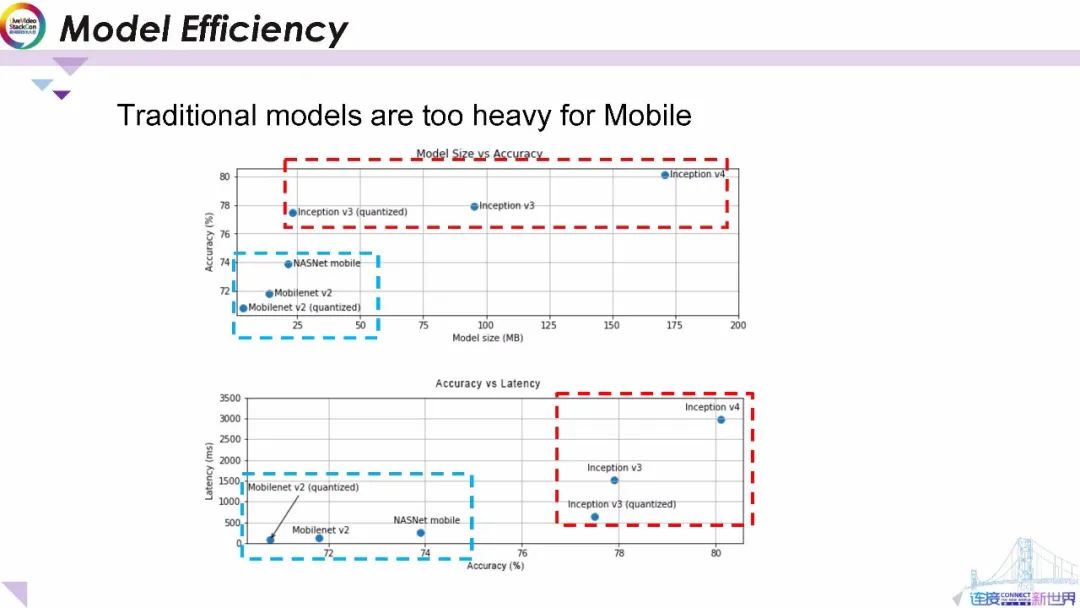
在深入探討開發移動端智能模型的細節之前,我們先了解一下傳統服務器端智能模型和移動端智能模型的性能數據。上圖顯示了模型大小和準確性之間的數據;而下圖顯示了模型準確性和延遲之間的數據。其中紅色虛線框顯示了傳統智能模型的性能數據,藍色虛線框顯示的移動端智能模型。從圖中可以看出就模型大小和推理延遲而言 Google Inceptiom等傳統服務器端智能模型比MobileNet模型要繁重得多。因此,傳統模型過于繁重,無法應用于移動應用。
2.2 MobileNetV1
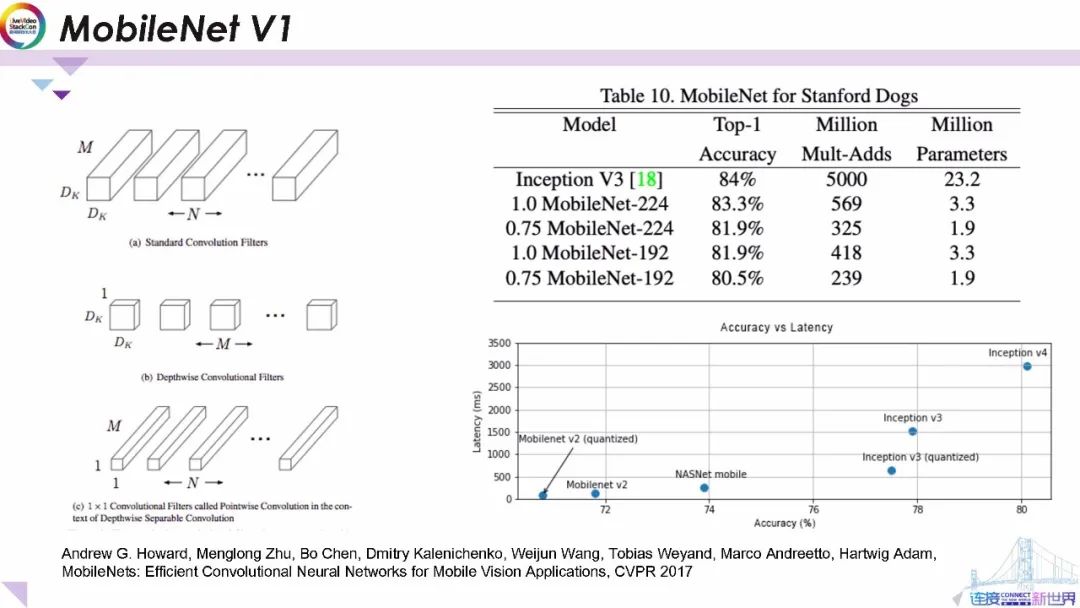
2017年 谷歌發布了著名的MobileNnet端上深度學習架構,它的主要貢獻之一是將標準卷積運算轉換為逐通道卷積運算。如左圖所示,逐通道卷積運算將標準卷積運算分解為兩個單獨的卷積運算:
第一步,它通過M個卷積內核對M個輸入通道進行卷積;
第二步,它對第一步的輸出進行1x1卷積,而不是通過其他N-1個不同的卷積運算組作為標準卷積運算對輸入進行卷積 。
通過這樣做可以使模型計算復雜度和參數數量減少約10倍,并使性能與Inception等最新服務器端智能模型保持一致。
此外,MobileNetmobilenetV1還通過可以控制全局比例系數來對模型大小進行等比例縮放。
2.3 MobileNet V3
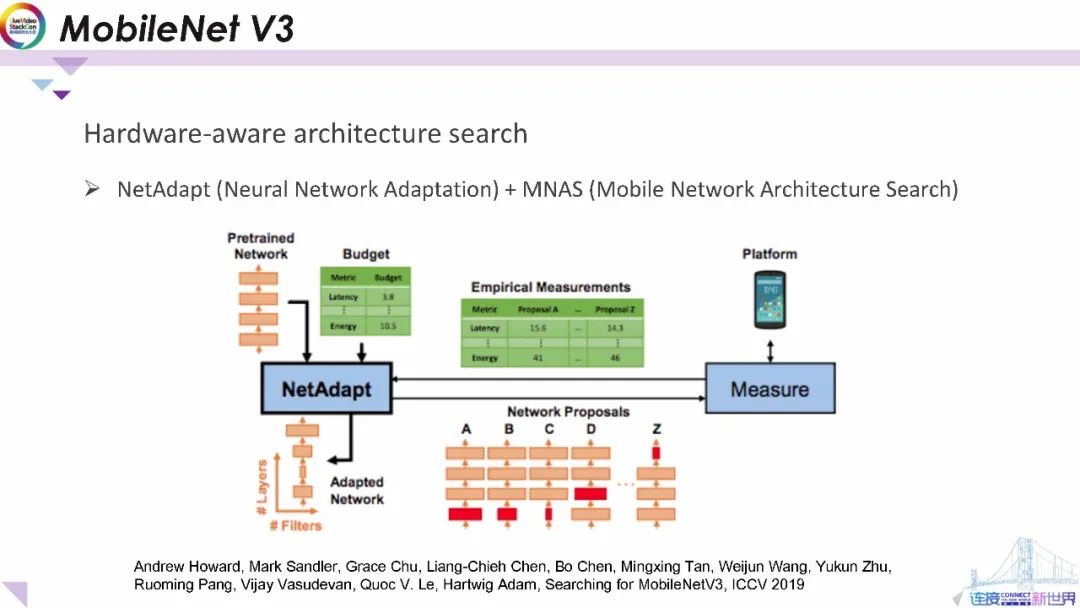
2019年研究人員設計了一個全新的MobileNet V3平臺。它通過硬件性能關聯的模型結構搜索來構建新的MobileNetMobilenet模型。新平臺通過將網絡適應性和移動網絡結構搜索融合在一起,并設置了具有目標延遲、 內存和功耗的目標函數來構建智能模型。
2.4MobileNet 性能基準測試
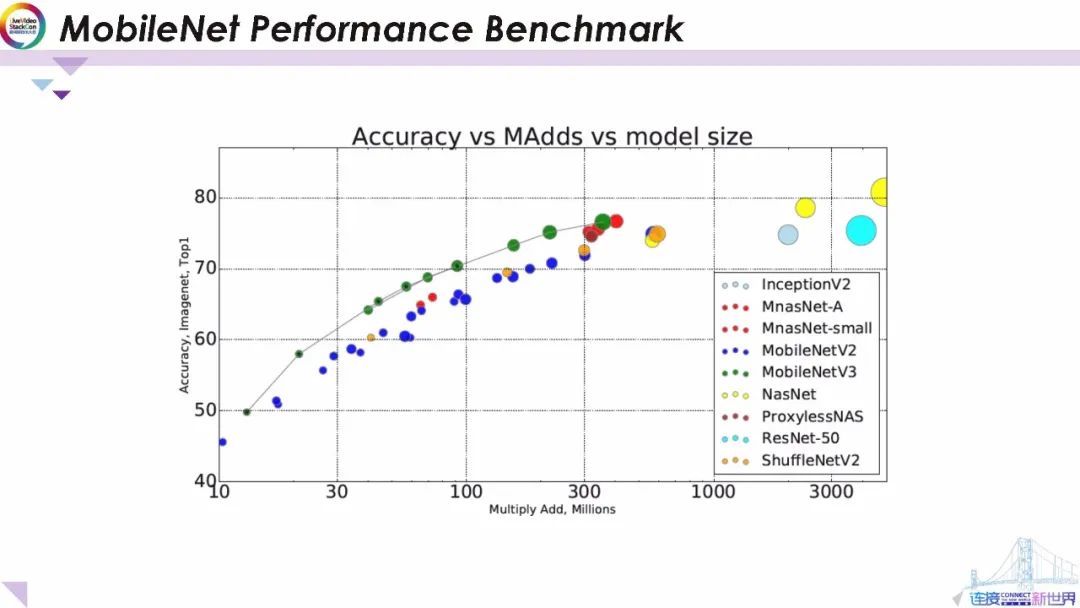
如圖所示,研究人員正在通過MobileNetmobilenetvV3和有效的神經體系結構搜索提升端上機器學習模型的性能。這些端上智能模型都達到了與最新服務器端智能模型相似的性能。但保持了較低的計算復雜度。更具體地說MobileNet V3以最低的計算復雜度限制實現了最高的準確性。這有些類似MobileNetmobilenet的體系結構已成為應用端上智能模型的參考和基準。
MLPerf

此外,我想向大家介紹機器學習性能基準測試平臺MLPerf。這是一個開放的平臺供研究人員發布智能模型在不同硬件平臺上的最新性能基準,包括準確性、延遲、內存占用和功耗。
每項測試結果涵蓋最常見的任務,包括在最流行的數據集上進行的圖像分類、對象檢測、圖像分割和自然語言處理。基于這些基準,用戶可以輕松查看,模型性能并為他們的應用選擇合適的模型。
2.5TFLite
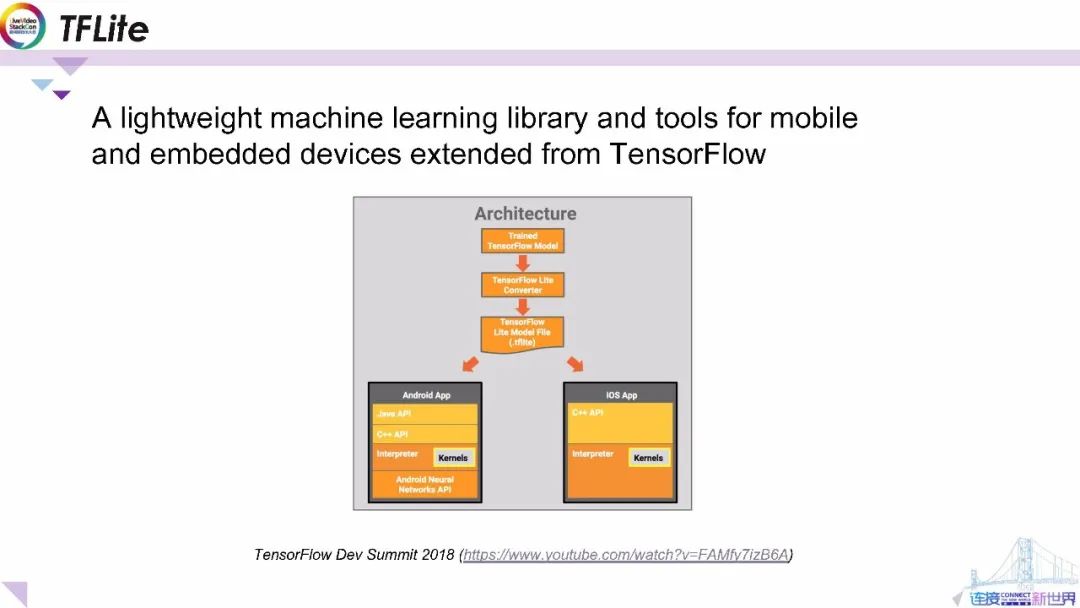
另一方面,Google發布了端上智能的基礎架構TFLite,并將其作為輕量級的機器學習庫以及用于移動和嵌入式設備的工具。它已嵌入到TensorFlow生態系統內,開發人員可以通過內置轉換器將訓練后的TensorFlow模型轉換為TFLite模型格式。轉換后的TFLite模型可用于構建跨平臺應用程序。
在Android系統中 ,Android神經網絡API提供了本機接口用于運行TFLitetflite模型,并將解釋器提供給開發人員,應用開發人員可以構建自定義的C ++和 Java API以在設備上調用模型進行智能推斷。在iosiOS系統中,用戶可以通過C ++ 直接調用解釋器。
TFLite的推理速度更快

TFLite通過以下功能在終端設備機器學習中脫穎而出。首先,其統一的基于FlatBuffer的模型格式與不同平臺兼容;其次,它為移動端優化了預融合激活和偏差計算;此外,它還提供了針對ARM上的NEON優化的內核從而顯著提高了執行速度;最后,它還支持訓練后量化。作為最流行的模型優化方法之一,模型量化將浮點系數轉換為整數。通常,量化可以使模型大小減少4倍,并使執行時間加快10-50%。
從圖中可以發現由TFLite自帶量化工具量化的模型顯著減少了類MobileNet模型和Inception V3模型的推理時間。此外,采用后期量化開發人員可以利用最新模型而無需從頭開始重新訓練模型。
模型壓縮
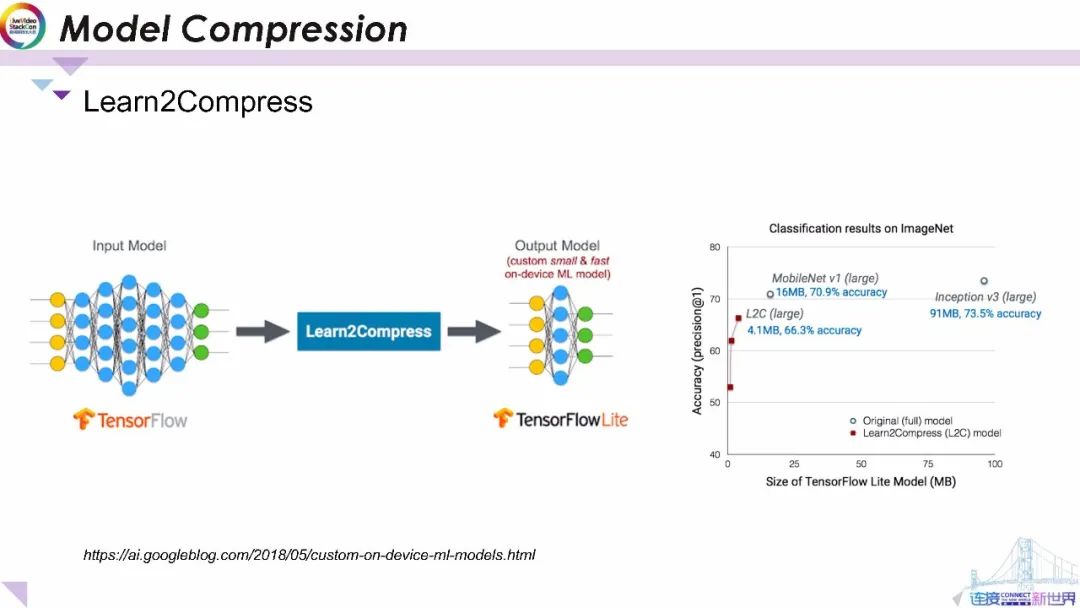
最近TFLite還發布了一個綜合庫用于將傳統的大型模型壓縮為較小的模型供給終端設備情形,這被稱為Learn2Compress。這項技術采用用戶提供的預先訓練的大型TensorFlow模型作為輸入進行訓練和優化 并自動生成尺寸更小、內存效率更高、能源效率更高、推理速度更快、準確性損失最小即用型端上智能模型。具體來說,模型壓縮是通過刪除對預測最無用的權重或操作(如低分數權重)實現。
它還引入了8位量化以及聯合模型訓練和模型蒸餾,以從大型模型中獲得緊湊的小型模型。對于圖像分類Learn2Compress可以生成小型且快速的模型并具有適合移動應用的良好預測精度。例如在ImageNet任務上Learn2Compress所獲得的模型比Inception V3基準模型小22倍,比MobileNet V1基準模型小4倍,準確度僅下降4.6-7%。
TFLite 任務API
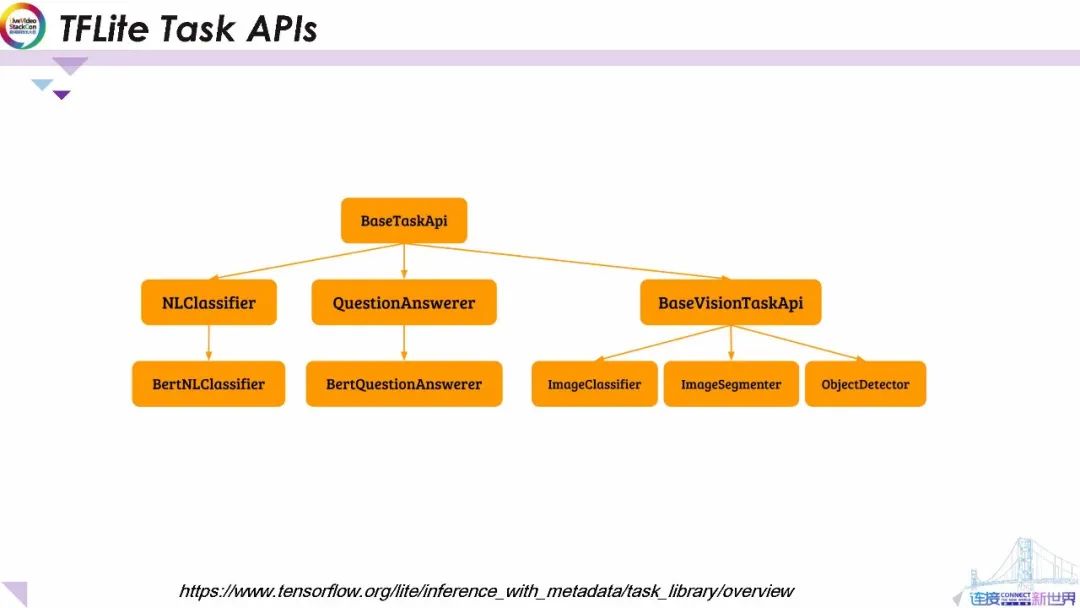
除了穩定的框架和先進的學習技術,TFLite還公開了一組功能強大且易于使用的工具庫供應用程序開發人員使用TFLite創建ML體驗。它為流行的機器學習任務(包括基于Bert NLP引擎的自然語言分類器、問題回答器)以及視覺任務API(包括分類器、檢測器和分段器)提供了優化的即用型模型接口。
TFLite任務庫可以實現跨平臺工作,并且在支持JAVA、 C++和Swift等上開發接受支持。這套TFLite ML機器學習任務API提供了四個主要優點。首先,它提供了簡潔且明確的API供非ML機器學習專家使用。其次,它為開發人員提供了高度可擴展性和自定義功能,開發者可在不了解模型的情況下構建自己的Android和iosOS應用程序。第三,它還發布了功能強大但通用的數據處理工具庫支持通用視覺和自然語言處理邏輯,以在用戶數據和模型所需的數據格式之間進行轉換,工具庫還提供了可以同時用于訓練和推理的處理邏輯。最后,它通過優化處理獲得了較高的性能,數據處理流程將不超過幾毫秒 從而確保使用TensorFlowTFLite的快速推理體驗,所有任務庫所用到的模型均由Google研究部門提供支持。接下來,我將討論如何使用TFLite任務API 在設備上構建機器智能應用程序。
從Java運行TFLite Task APIs
此處,我將展示一個Android客戶端使用TFLite任務API 的示例 。Android客戶端將調用JAVA接口以傳遞輸入信號,輸入信號將通過自身API進一步轉發給模型調用,模型推斷完成后,將輸出結果發送給java接口,并進一步回傳到Android客戶端。
在示例中,用戶需要將模型文件復制到設備上的本地目錄 :
第一步:導入gradle依賴關系和模型文件的其他設置;
第二步:可以使用對象檢測器選項創建對象檢測器,并通過調用檢測方法進行同步推斷。在端到端系統設計中,可以利用MediaPipe框架以同步或異步方式進行設計,請進一步參考開放源代碼的MediaPipe系統以獲取構建端到端視覺系統的詳細信息。
3 建立適合移動端的機器學習模型

看上去我們已經為智能社區建立端上機器智能應用程序做出了卓越的貢獻,那我們是否可以做得更好?答案是肯定的。
3.1硬件加速
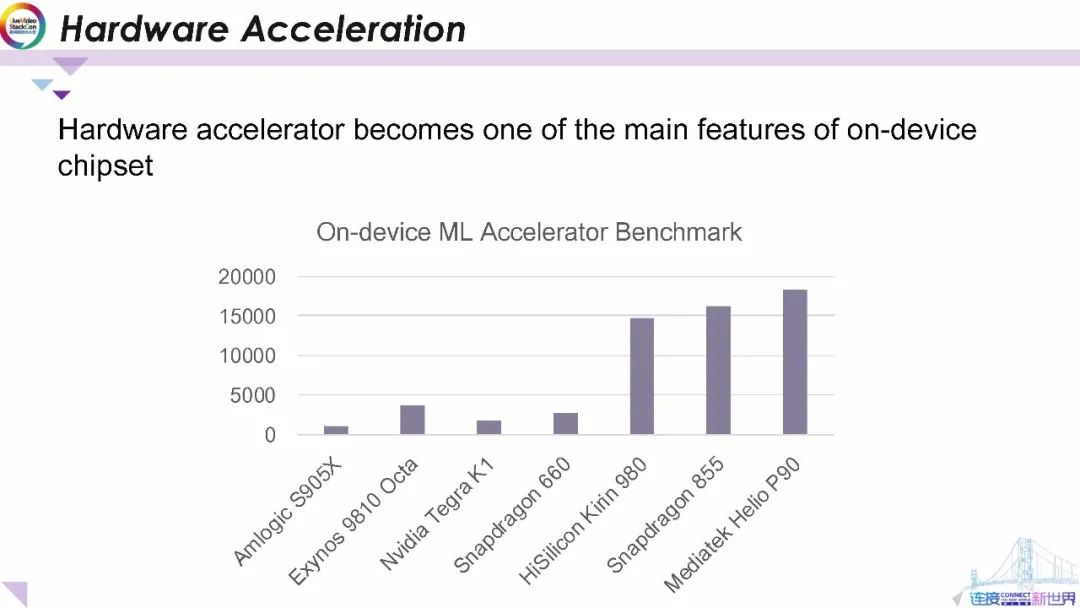
端上機器學習社區當前正在研究的一項主要工作,通過諸如GPU EdgeTPU 和DSP之類的等硬件加速器來加速ML機器學習推理。上圖顯示了一些最近為移動設備開發的硬件加速器。從圖中可以發現最新的芯片組(如海思、麒麟980、驍龍855和MediaTtek P9)的性能顯著提高。這個令人振奮的消息將鼓勵開發人員在終端設備上開發更多的應用程序。
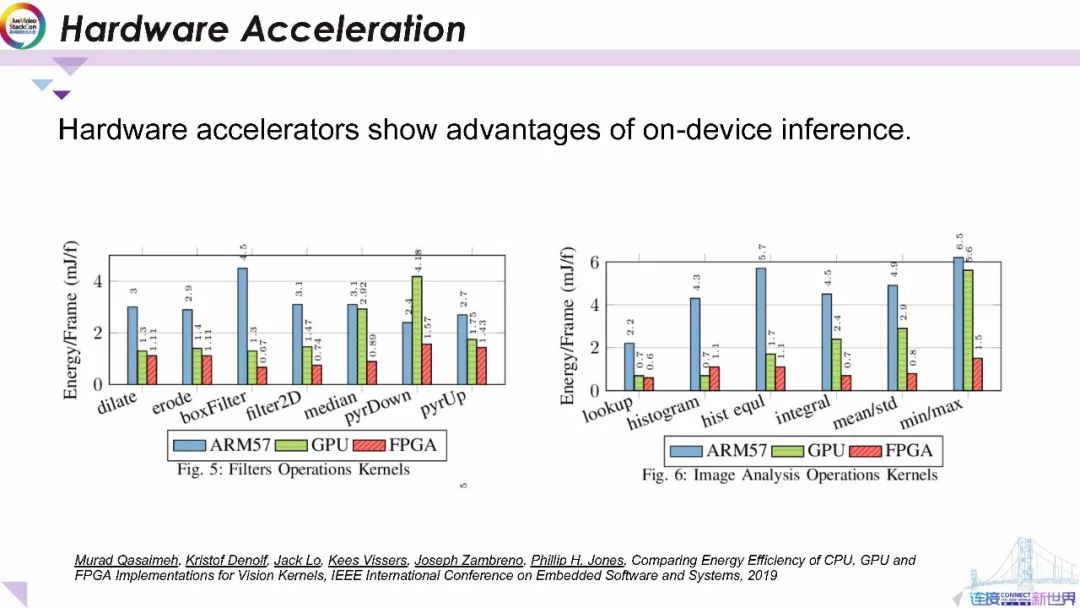
這張幻燈片中的圖顯示了在ARM GPU和FPGA上運行基本濾波操作和圖像分析操作的功耗基準與在CPU上運行相比通過在GPU和FPGA上進行優化來降低能源成本具有顯著優勢。
對于Filter2D(這是深度學習中最常用的操作之一)在GPU上運行可以將GPU的功耗降低一半。在FPGA上運行可以將功耗進一步降低到CPU的四分之一。
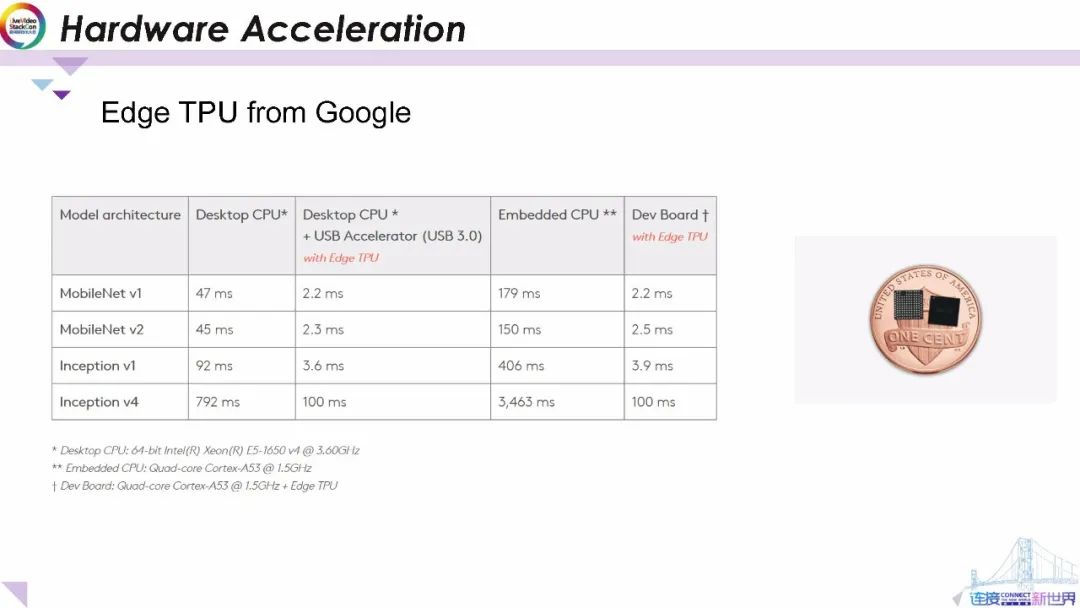
我們通過運行移動模型(如mobilenetMobileNet) 和服務器端流行模型(如Iinception)列出了不同硬件平臺的基準。在臺式機CPU上運行MobileNet V1和V2大約需要45毫秒 ;在CPU和FPGA上協同運行時將顯著減少20倍 。
此外 在嵌入式CPU(如四核Cortex A53 )上運行MobileNet V1和V2將超過150毫秒,而在EdgeTPU上使用不到2.5毫秒。
通過對比CPU和 EdgeTPU上運行inception模型,我們同樣可以觀察到運行在EdgeTPU的延遲比運行在CPU上的延遲顯著減少。
令人難以置信的是上述顯著的延遲降低是通過右圖所示的微型芯片組實現的。
EfficientNet-EdgeTPU
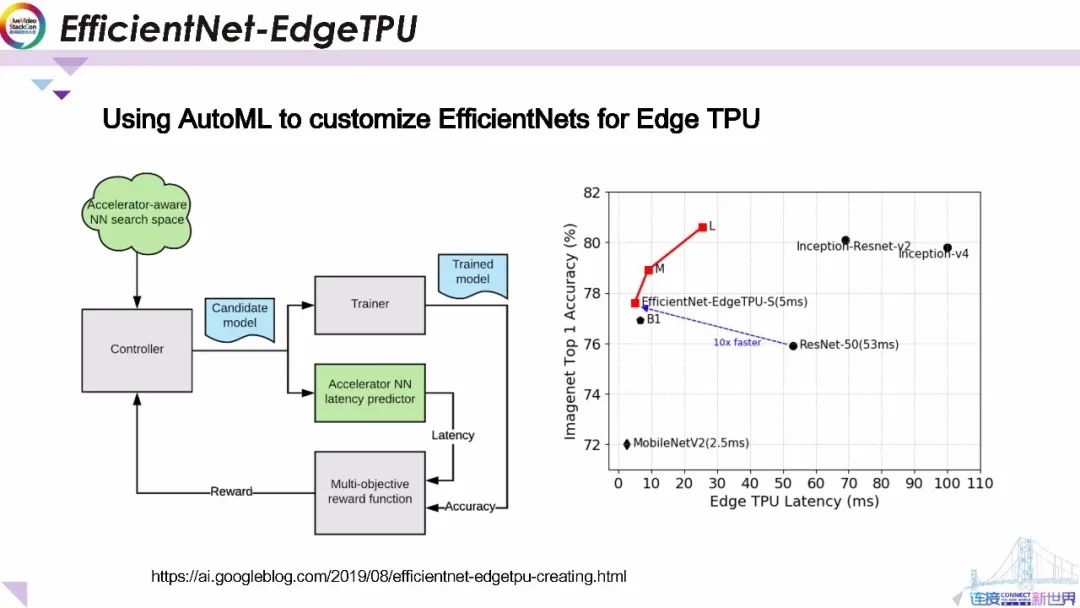
在這里,我們要展示一個利用自動機器學習構建硬件加速的端上機器學習模型的示例。我們將EfficientNet(也是最先進的移動神經網絡體系結構之一)作為這項工作的基礎。為了構建旨在利用Edge TPU的加速器體系結構的 EfficientNets,我們調用了自動網絡結構搜索框架 ,并使用可以在Edge上高效執行的構建塊來擴展原始的EfficientNet的神經網絡體系結構搜索空間。我們還構建并集成了一個“延遲預測器”模塊,該模塊通過在周期精確的模型結構結構模擬器上運行模型來提供在Edge TPU上執行時模型延遲的估計。自動網絡結構搜索控制器通過強化學習算法以在嘗試通過搜索實現最大化預測延遲和模型準確性的聯合獎勵函數。
根據過去的經驗 我們知道當該模型適合其片上存儲器時Edge TPU的功耗和性能就將得到最大化。因此,我們還修改了獎勵函數以便為滿足此約束的模型生成更高的獎勵。
與現有EfficientNet, ResNet, 以及Inception 模型相比,EfficientNet-EdgeTPU-小/中/大模型通過專用于Edge硬件的網絡架構可實現更好的延遲和準確性,特別值得注意的是比起ResNet-50,我們獲得的,EfficientNet-EdgeTPU-小模型具有更高的精度但運行速度快10倍。

作為廣泛采用的終端設備推理平臺,TFLite還支持原生硬件加速。在這里,我們顯示在CPU, GPU 和邊緣TPU上運行MobileNet V1TFLite模型的示例。
從總體上看CPU在MobileNet Vv1上運行浮點,推理一幀數據大約需要124毫秒。在CPU上運行量化的MobileNet Vv1比浮點模型快1.9倍,在GPU上運行浮點模型的速度比CPU快7.7倍,每幀僅使用16毫秒左右。
最后,在Edge TPU上運行量化模型僅需2毫秒。這比CPU上的浮點模型快62倍。因為我們可以得出通過硬件加速,可以在延遲、功耗和內存方面顯著優化模型推理的結論。
4 端上機器學習的隱私意識

我們是否已經實現端上機器智能的最終目標?我們才剛開始。
4.1 終端上的數據很有意義
正如我們在開始時提到的,數據隱私是促使我們,轉向終端設備機器智能的另一個主要原因。但是,最新的端上機器智能模型的訓練仍然需要在服務器端進行。舉一個典型的應用案例:為了使機器能夠為人類識別狗之類的動物,我們可以使用左側的公共訓練圖像來訓練模型,但是 我們通常需要在如右側圖片所示的極具挑戰性的場景下使用該模型。那么在具有挑戰性的日常個性化使用案例中如何使模型達到高精度?一種簡單的解決方案是,收集私有圖像并通過集中數據中心來重新訓練模型。雖然像Google這樣的大公司已經建立了最安全、最強大的云基礎架構來處理這些數據,以提供更好的服務。但這顯然仍然不是最佳的解決方案。因為它引起了使用用戶私人數據的問題,其中可能包含敏感信息,例如用戶人臉、用戶居住空間等。我們如何改善模型的個性化性能并保護用戶的隱私。
4.2聯邦學習
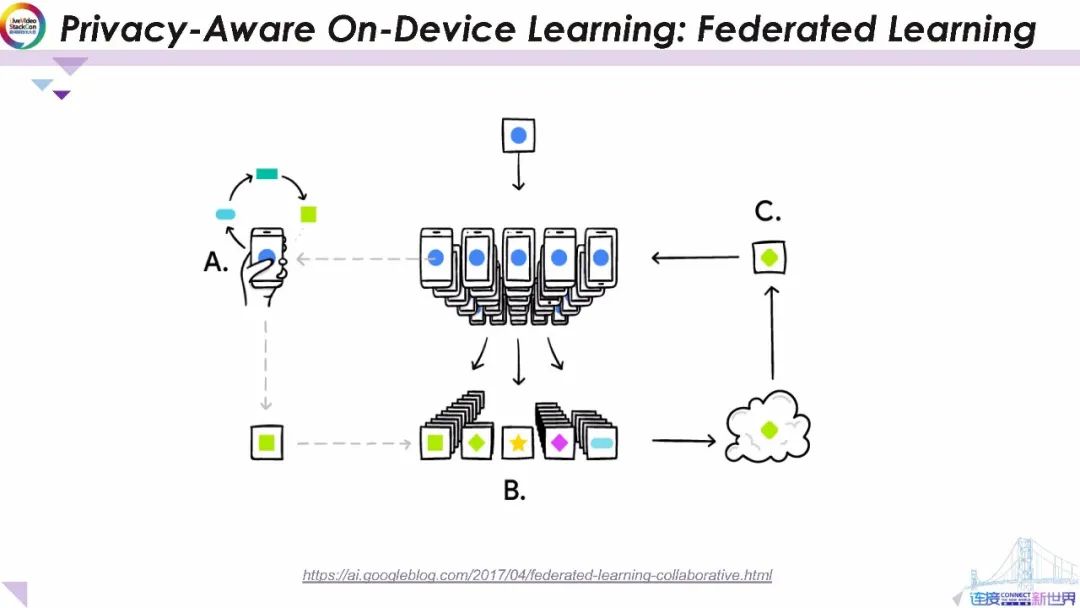
現在,對于通過用戶與移動設備交互進行訓練而得到的模型。我們將引入另一種方法——聯邦學習。
聯邦學習使手機能夠協作學習共享的預測模型。同時將所有訓練數據保留在設備上,從而將進行機器學習的能力與將數據存儲在云中的需求脫鉤,這超出了通過將模型訓練帶入設備對移動設備進行預測使用本地模型的范圍。它的工作方式如下:用戶的設備下載當前模型,通過從手機上的數據學習來改進當前模型,然后將更改匯總為一個小的局部更新,僅使用加密通信將模型的更新發送到云,并在此立即將其與其他用戶更新平均以改善共享模型。所有訓練數據都保留在用戶的設備上,并沒有將用戶個人的數據更新存儲在云端,聯邦學習可在確保隱私的同時 提供更智能的模型、更低的延遲和更低的功耗。
這種方法的另一個直接優勢是除了提供對共享模型的更新之外,還可以立即使用手機上改進的模型,從而為您使用手機的方式提供個性化的體驗。
用Gboard測試聯邦學習
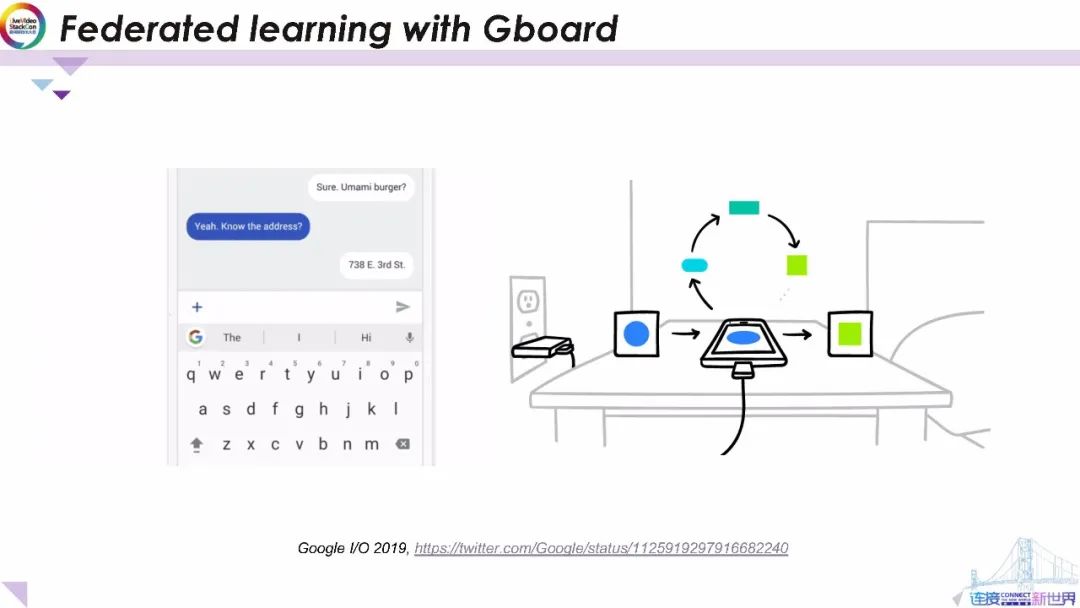
我們目前正在Android的Google鍵盤應用Gboard上測試聯邦學習。當Gboard顯示建議的查詢時,您的手機將在本地存儲有關當前上下文,以及是否接受建議的信息。聯邦學習會處理終端設備上的歷史記錄以提出對Gboard查詢建議模型下一次迭代的改進建議。
對于擁有數百萬用戶的Gboard而言,將該技術部署到的不同的設備中是一個非常有挑戰的任務。在實際部署中,我們使用微型版本的TensorFlow來實現在設備上的模型訓練,精心安排的時間表可確保僅在設備閑置插入電源和免費無線連接時進行訓練,因此不會影響終端的使用性能。
5 未來的工作

看起來我們已經達成了不錯的目標,那么未來會是什么樣?
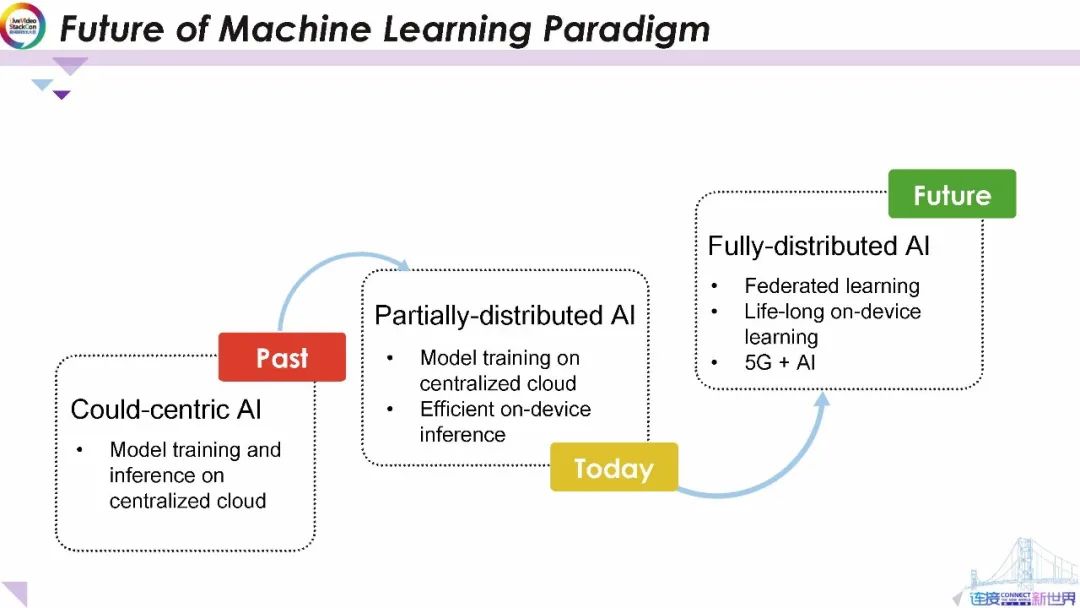
過去,所有的訓練和推理都是在集中式云系統上進行的。這引起人們對隱私、延遲和可靠性的日益關注。今天,我們通過節省功效的智能設備,推理來制作部分分布式機器智能模型仍在集中式數據中心上訓練并在本地設備上運行。
在不久的將來,借助聯邦學習技術我們將擁有完全分布式的AI以解決隱私問題和終身終端設備學習的支持。最近,5G正在全球范圍內部署,5G的低延遲和高容量還將使AI處理能夠在設備、邊緣云和中央云之間分布從而為各種新的和增強的體驗提供靈活的混合系統解決方案。
這種無線邊緣架構具有適應性,并且可以根據每個用例進行適當的權衡。例如,性能和經濟權衡可能有助于確定如何分配工作負載以滿足特定應用程序所需的延遲或計算要求。到那時,我們可以看到loT(物聯網) 智慧城市和個性化領域中大量的新興應用。
總結

在本次報告中,我們簡要概述了端上機器學習的機遇和挑戰。其次 我們討論關于終端設備機器學習的資源效率計算。在這一部分中,我們介紹了移動模型體系結構TFLite框架用于壓縮模型的高級技術,以及用于用戶構建端上機器智能應用的開源機器學習任務API。最后,我們介紹了隱私保護的端上機器學習技術(聯邦學習)的最新進展。我們還指出了端上人工智能的未來發展方向。
責任編輯:lq
-
視覺系統
+關注
關注
3文章
351瀏覽量
31308 -
機器學習
+關注
關注
66文章
8505瀏覽量
134677 -
自動駕駛
+關注
關注
790文章
14326瀏覽量
170747
原文標題:高效終端設備視覺系統開發與優化
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
東風汽車轉型突破取得新進展
英特爾持續推進核心制程和先進封裝技術創新,分享最新進展
谷歌Gemini API最新進展
京東方華燦光電氮化鎵器件的最新進展
垂直氮化鎵器件的最新進展和可靠性挑戰
上海光機所在激光燒蝕波紋的調制機理研究中取得新進展
Qorvo在手機RF和Wi-Fi 7技術上的最新進展及市場策略
FF將發布FX品牌最新進展
揭秘超以太網聯盟(UEC)1.0 規范最新進展(2024Q4)
Qorvo在射頻和電源管理領域的最新進展
芯片和封裝級互連技術的最新進展
AI大模型的最新研究進展
5G新通話技術取得新進展
中國科學院西安光機所智能光學顯微成像研究取得新進展






 工商網監
工商網監
評論