 關于C++的49個常用知識
關于C++的49個常用知識
1、在main執行之前和之后執行的代碼可能是什么?
main函數執行之前,主要就是初始化系統相關資源:
設置棧指針
初始化靜態static變量和global全局變量,即.data段的內容
將未初始化部分的全局變量賦初值:數值型short,int,long等為0,bool為FALSE,指針為NULL等等,即.bss段的內容
全局對象初始化,在main之前調用構造函數,這是可能會執行前的一些代碼
將main函數的參數argc,argv等傳遞給main函數,然后才真正運行main函數
main函數執行之后:
全局對象的析構函數會在main函數之后執行;
可以用 atexit 注冊一個函數,它會在main 之后執行;
2、結構體內存對齊問題?
結構體內成員按照聲明順序存儲,第一個成員地址和整個結構體地址相同。
未特殊說明時,按結構體中size最大的成員對齊(若有double成員,按8字節對齊。)
3、指針和引用的區別
指針是一個變量,存儲的是一個地址,引用跟原來的變量實質上是同一個東西,是原變量的別名
指針可以有多級,引用只有一級
指針可以為空,引用不能為NULL且在定義時必須初始化
指針在初始化后可以改變指向,而引用在初始化之后不可再改變
sizeof指針得到的是本指針的大小,sizeof引用得到的是引用所指向變量的大小
當把指針作為參數進行傳遞時,也是將實參的一個拷貝傳遞給形參,兩者指向的地址相同,但不是同一個變量,在函數中改變這個變量的指向不影響實參,而引用卻可以。
引用只是別名,不占用具體存儲空間,只有聲明沒有定義;指針是具體變量,需要占用存儲空間。
引用在聲明時必須初始化為另一變量,一旦出現必須為typename refname &varname形式;指針聲明和定義可以分開,可以先只聲明指針變量而不初始化,等用到時再指向具體變量。
引用一旦初始化之后就不可以再改變(變量可以被引用為多次,但引用只能作為一個變量引用);指針變量可以重新指向別的變量。
不存在指向空值的引用,必須有具體實體;但是存在指向空值的指針。
參考代碼:
void test(int *p) { int a=1; p=&a; cout《《p《《“ ”《《*p《《endl; } int main(void) { int *p=NULL; test(p); if(p==NULL) cout《《“指針p為NULL”《《endl; return 0; } //運行結果為: //0x22ff44 1 //指針p為NULL void testPTR(int* p) { int a = 12; p = &a; } void testREFF(int& p) { int a = 12; p = a; } void main() { int a = 10; int* b = &a; testPTR(b);//改變指針指向,但是沒改變指針的所指的內容 cout 《《 a 《《 endl;// 10 cout 《《 *b 《《 endl;// 10 a = 10; testREFF(a); cout 《《 a 《《 endl;//12 }
4、堆和棧的區別
申請方式不同:棧由系統自動分配;堆是自己申請和釋放的。
申請大小限制不同:棧頂和棧底是之前預設好的,棧是向棧底擴展,大小固定,可以通過ulimit -a查看,由ulimit -s修改;堆向高地址擴展,是不連續的內存區域,大小可以靈活調整。
申請效率不同:棧由系統分配,速度快,不會有碎片;堆由程序員分配,速度慢,且會有碎片。
形象的比喻
棧就像我們去飯館里吃飯,只管點菜(發出申請)、付錢、和吃(使用),吃飽了就走,不必理會切菜、洗菜等準備工作和洗碗、刷鍋等掃尾工作,他的好處是快捷,但是自由度小。
堆就象是自己動手做喜歡吃的菜肴,比較麻煩,但是比較符合自己的口味,而且自由度大。
https://blog.csdn.net/qq_34175893/article/details/83502412
5、區別以下指針類型?
int *p[10] int (*p)[10] int *p(int) int (*p)(int)
int *p[10]表示指針數組,強調數組概念,是一個數組變量,數組大小為10,數組內每個元素都是指向int類型的指針變量。
int (*p)[10]表示數組指針,強調是指針,只有一個變量,是指針類型,不過指向的是一個int類型的數組,這個數組大小是10。
int *p(int)是函數聲明,函數名是p,參數是int類型的,返回值是int *類型的。
int (*p)(int)是函數指針,強調是指針,該指針指向的函數具有int類型參數,并且返回值是int類型的。
6、基類的虛函數表存放在內存的什么區,虛表指針vptr的初始化時間
首先整理一下虛函數表的特征:
虛函數表是全局共享的元素,即全局僅有一個,在編譯時就構造完成
虛函數表類似一個數組,類對象中存儲vptr指針,指向虛函數表,即虛函數表不是函數,不是程序代碼,不可能存儲在代碼段
虛函數表存儲虛函數的地址,即虛函數表的元素是指向類成員函數的指針,而類中虛函數的個數在編譯時期可以確定,即虛函數表的大小可以確定,即大小是在編譯時期確定的,不必動態分配內存空間存儲虛函數表,所以不在堆中
根據以上特征,虛函數表類似于類中靜態成員變量。靜態成員變量也是全局共享,大小確定,因此最有可能存在全局數據區,測試結果顯示:
虛函數表vtable在Linux/Unix中存放在可執行文件的只讀數據段中(rodata),這與微軟的編譯器將虛函數表存放在常量段存在一些差別
由于虛表指針vptr跟虛函數密不可分,對于有虛函數或者繼承于擁有虛函數的基類,對該類進行實例化時,在構造函數執行時會對虛表指針進行初始化,并且存在對象內存布局的最前面。
一般分為五個區域:棧區、堆區、函數區(存放函數體等二進制代碼)、全局靜態區、常量區
C++中虛函數表位于只讀數據段(.rodata),也就是C++內存模型中的常量區;而虛函數則位于代碼段(.text),也就是C++內存模型中的代碼區。
7、new / delete 與 malloc / free的異同
相同點
都可用于內存的動態申請和釋放
不同點
前者是C++運算符,后者是C/C++語言標準庫函數
new自動計算要分配的空間大小,malloc需要手工計算
new是類型安全的,malloc不是。例如:
int *p = new float[2]; //編譯錯誤 int *p = (int*)malloc(2 * sizeof(double));//編譯無錯誤
new調用名為operator new的標準庫函數分配足夠空間并調用相關對象的構造函數,delete對指針所指對象運行適當的析構函數;然后通過調用名為operator delete的標準庫函數釋放該對象所用內存。后者均沒有相關調用
后者需要庫文件支持,前者不用
new是封裝了malloc,直接free不會報錯,但是這只是釋放內存,而不會析構對象
8、new和delete是如何實現的?
new的實現過程是:首先調用名為operator new的標準庫函數,分配足夠大的原始為類型化的內存,以保存指定類型的一個對象;接下來運行該類型的一個構造函數,用指定初始化構造對象;最后返回指向新分配并構造后的的對象的指針
delete的實現過程:對指針指向的對象運行適當的析構函數;然后通過調用名為operator delete的標準庫函數釋放該對象所用內存
9、malloc和new的區別?
malloc和free是標準庫函數,支持覆蓋;new和delete是運算符,并且支持重載。
malloc僅僅分配內存空間,free僅僅回收空間,不具備調用構造函數和析構函數功能,用malloc分配空間存儲類的對象存在風險;new和delete除了分配回收功能外,還會調用構造函數和析構函數。
malloc和free返回的是void類型指針(必須進行類型轉換),new和delete返回的是具體類型指針。
delete和delete[]區別?
delete只會調用一次析構函數。
delete[]會調用數組中每個元素的析構函數。
10、宏定義和函數有何區別?
宏在編譯時完成替換,之后被替換的文本參與編譯,相當于直接插入了代碼,運行時不存在函數調用,執行起來更快;函數調用在運行時需要跳轉到具體調用函數。
宏定義屬于在結構中插入代碼,沒有返回值;函數調用具有返回值。
宏定義參數沒有類型,不進行類型檢查;函數參數具有類型,需要檢查類型。
宏定義不要在最后加分號。
11、宏定義和typedef區別?
宏主要用于定義常量及書寫復雜的內容;typedef主要用于定義類型別名。
宏替換發生在編譯階段之前,屬于文本插入替換;typedef是編譯的一部分。
宏不檢查類型;typedef會檢查數據類型。
宏不是語句,不在在最后加分號;typedef是語句,要加分號標識結束。
注意對指針的操作,typedef char * p_char和#define p_char char *區別巨大。
12、變量聲明和定義區別?
聲明僅僅是把變量的聲明的位置及類型提供給編譯器,并不分配內存空間;定義要在定義的地方為其分配存儲空間。
相同變量可以在多處聲明(外部變量extern),但只能在一處定義。
13、哪幾種情況必須用到初始化成員列表?
初始化一個const成員。
初始化一個reference成員。
調用一個基類的構造函數,而該函數有一組參數。
調用一個數據成員對象的構造函數,而該函數有一組參數。
14、strlen和sizeof區別?
sizeof是運算符,并不是函數,結果在編譯時得到而非運行中獲得;strlen是字符處理的庫函數。
sizeof參數可以是任何數據的類型或者數據(sizeof參數不退化);strlen的參數只能是字符指針且結尾是‘’的字符串。
因為sizeof值在編譯時確定,所以不能用來得到動態分配(運行時分配)存儲空間的大小。
int main(int argc, char const *argv[]){ const char* str = “name”; sizeof(str); // 取的是指針str的長度,是8 strlen(str); // 取的是這個字符串的長度,不包含結尾的 。大小是4 return 0; }
15、常量指針和指針常量區別?
常量指針是一個指針,讀成常量的指針,指向一個只讀變量。如int const *p或const int *p。
指針常量是一個不能給改變指向的指針。指針是個常亮,不能中途改變指向,如int *const p。
16、a和&a有什么區別?
假設數組int a[10]; int (*p)[10] = &a;
a是數組名,是數組首元素地址,+1表示地址值加上一個int類型的大小,如果a的值是0x00000001,加1操作后變為0x00000005。*(a + 1) = a[1]。
&a是數組的指針,其類型為int (*)[10](就是前面提到的數組指針),其加1時,系統會認為是數組首地址加上整個數組的偏移(10個int型變量),值為數組a尾元素后一個元素的地址。
若(int *)p ,此時輸出 *p時,其值為a[0]的值,因為被轉為int *類型,解引用時按照int類型大小來讀取。
17、數組名和指針(這里為指向數組首元素的指針)區別?
二者均可通過增減偏移量來訪問數組中的元素。
數組名不是真正意義上的指針,可以理解為常指針,所以數組名沒有自增、自減等操作。
當數組名當做形參傳遞給調用函數后,就失去了原有特性,退化成一般指針,多了自增、自減操作,但sizeof運算符不能再得到原數組的大小了。
18、野指針和懸空指針
都是是指向無效內存區域(這里的無效指的是“不安全不可控”)的指針,訪問行為將會導致未定義行為。
野指針,指的是沒有被初始化過的指針
int main(void) { int * p; std::cout《《*p《《std::endl; return 0; }
因此,為了防止出錯,對于指針初始化時都是賦值為 nullptr,這樣在使用時編譯器就會直接報錯,產生非法內存訪問。
懸空指針,指針最初指向的內存已經被釋放了的一種指針。
int main(void) { int * p = nullptr; int* p2 = new int; p = p2; delete p2; }
此時 p和p2就是懸空指針,指向的內存已經被釋放。繼續使用這兩個指針,行為不可預料。需要設置為p=p2=nullptr。此時再使用,編譯器會直接保錯。
避免野指針比較簡單,但懸空指針比較麻煩。c++引入了智能指針,C++智能指針的本質就是避免懸空指針的產生。
產生原因及解決辦法:
野指針:指針變量未及時初始化 =》 定義指針變量及時初始化,要么置空。
懸空指針:指針free或delete之后沒有及時置空 =》 釋放操作后立即置空。
19、迭代器失效的情況
以vector為例:
插入元素:
1、尾后插入:size 《 capacity時,首迭代器不失效尾迭代失效(未重新分配空間),size == capacity時,所有迭代器均失效(需要重新分配空間)。
2、中間插入:中間插入:size 《 capacity時,首迭代器不失效但插入元素之后所有迭代器失效,size == capacity時,所有迭代器均失效。
刪除元素:
尾后刪除:只有尾迭代失效。
中間刪除:刪除位置之后所有迭代失效。
20、C和C++的區別
C++中new和delete是對內存分配的運算符,取代了C中的malloc和free。
標準C++中的字符串類取代了標準C函數庫頭文件中的字符數組處理函數(C中沒有字符串類型)。
C++中用來做控制態輸入輸出的iostream類庫替代了標準C中的stdio函數庫。
C++中的try/catch/throw異常處理機制取代了標準C中的setjmp()和longjmp()函數。
在C++中,允許有相同的函數名,不過它們的參數類型不能完全相同,這樣這些函數就可以相互區別開來。而這在C語言中是不允許的。也就是C++可以重載,C語言不允許。
C++語言中,允許變量定義語句在程序中的任何地方,只要在是使用它之前就可以;而C語言中,必須要在函數開頭部分。而且C++允許重復定義變量,C語言也是做不到這一點的
在C++中,除了值和指針之外,新增了引用。引用型變量是其他變量的一個別名,我們可以認為他們只是名字不相同,其他都是相同的。
C++相對與C增加了一些關鍵字,如:bool、using、dynamic_cast、namespace等等
《C語言與C++有什么區別?》
https://www.cnblogs.com/ITziyuan/p/9487760.html
21、C++與Java的區別
語言特性
Java語言給開發人員提供了更為簡潔的語法;完全面向對象,由于JVM可以安裝到任何的操作系統上,所以說它的可移植性強
Java語言中沒有指針的概念,引入了真正的數組。不同于C++中利用指針實現的“偽數組”,Java引入了真正的數組,同時將容易造成麻煩的指針從語言中去掉,這將有利于防止在C++程序中常見的因為數組操作越界等指針操作而對系統數據進行非法讀寫帶來的不安全問題
C++也可以在其他系統運行,但是需要不同的編碼(這一點不如Java,只編寫一次代碼,到處運行),例如對一個數字,在windows下是大端存儲,在unix中則為小端存儲。Java程序一般都是生成字節碼,在JVM里面運行得到結果
Java用接口(Interface)技術取代C++程序中的多繼承性。接口與多繼承有同樣的功能,但是省卻了多繼承在實現和維護上的復雜性
垃圾回收
C++用析構函數回收垃圾,寫C和C++程序時一定要注意內存的申請和釋放
Java語言不使用指針,內存的分配和回收都是自動進行的,程序員無須考慮內存碎片的問題
應用場景
Java在桌面程序上不如C++實用,C++可以直接編譯成exe文件,指針是c++的優勢,可以直接對內存的操作,但同時具有危險性 。(操作內存的確是一項非常危險的事情,一旦指針指向的位置發生錯誤,或者誤刪除了內存中某個地址單元存放的重要數據,后果是可想而知的)
Java在Web 應用上具有C++ 無可比擬的優勢,具有豐富多樣的框架
對于底層程序的編程以及控制方面的編程,C++很靈活,因為有句柄的存在
《C++和java的區別和聯系》:
https://www.cnblogs.com/tanrong/p/8503202.html
22、C++中struct和class的區別
相同點
兩者都擁有成員函數、公有和私有部分
任何可以使用class完成的工作,同樣可以使用struct完成
不同點
兩者中如果不對成員不指定公私有,struct默認是公有的,class則默認是私有的
class默認是private繼承,而struct模式是public繼承
class可以作為模板類型,struct不行
引申:C++和C的struct區別
C語言中:struct是用戶自定義數據類型(UDT);C++中struct是抽象數據類型(ADT),支持成員函數的定義,(C++中的struct能繼承,能實現多態)
C中struct是沒有權限的設置的,且struct中只能是一些變量的集合體,可以封裝數據卻不可以隱藏數據,而且成員不可以是函數
C++中,struct增加了訪問權限,且可以和類一樣有成員函數,成員默認訪問說明符為public(為了與C兼容)
struct作為類的一種特例是用來自定義數據結構的。一個結構標記聲明后,在C中必須在結構標記前加上struct,才能做結構類型名(除:typedef struct class{};);C++中結構體標記(結構體名)可以直接作為結構體類型名使用,此外結構體struct在C++中被當作類的一種特例
《struct結構在C和C++中的區別》:
https://blog.csdn.net/mm_hh/article/details/70456240
23、define宏定義和const的區別
編譯階段
define是在編譯的預處理階段起作用,而const是在編譯、運行的時候起作用
安全性
define只做替換,不做類型檢查和計算,也不求解,容易產生錯誤,一般最好加上一個大括號包含住全部的內容,要不然很容易出錯
const常量有數據類型,編譯器可以對其進行類型安全檢查
內存占用
define只是將宏名稱進行替換,在內存中會產生多分相同的備份。const在程序運行中只有一份備份,且可以執行常量折疊,能將復雜的的表達式計算出結果放入常量表
宏替換發生在編譯階段之前,屬于文本插入替換;const作用發生于編譯過程中。
宏不檢查類型;const會檢查數據類型。
宏定義的數據沒有分配內存空間,只是插入替換掉;const定義的變量只是值不能改變,但要分配內存空間。
24、C++中const和static的作用
static
不考慮類的情況
隱藏。所有不加static的全局變量和函數具有全局可見性,可以在其他文件中使用,加了之后只能在該文件所在的編譯模塊中使用
默認初始化為0,包括未初始化的全局靜態變量與局部靜態變量,都存在全局未初始化區
靜態變量在函數內定義,始終存在,且只進行一次初始化,具有記憶性,其作用范圍與局部變量相同,函數退出后仍然存在,但不能使用
考慮類的情況
static成員變量:只與類關聯,不與類的對象關聯。定義時要分配空間,不能在類聲明中初始化,必須在類定義體外部初始化,初始化時不需要標示為static;可以被非static成員函數任意訪問。
static成員函數:不具有this指針,無法訪問類對象的非static成員變量和非static成員函數;不能被聲明為const、虛函數和volatile;可以被非static成員函數任意訪問
const
不考慮類的情況
const常量在定義時必須初始化,之后無法更改
const形參可以接收const和非const類型的實參,例如
// i 可以是 int 型或者 const int 型 void fun(const int& i){ //。.. }
考慮類的情況
const成員變量:不能在類定義外部初始化,只能通過構造函數初始化列表進行初始化,并且必須有構造函數;不同類對其const數據成員的值可以不同,所以不能在類中聲明時初始化
const成員函數:const對象不可以調用非const成員函數;非const對象都可以調用;不可以改變非mutable(用該關鍵字聲明的變量可以在const成員函數中被修改)數據的值
25、C++的頂層const和底層const
概念區分
頂層const:指的是const修飾的變量本身是一個常量,無法修改,指的是指針,就是 * 號的右邊
底層const:指的是const修飾的變量所指向的對象是一個常量,指的是所指變量,就是 * 號的左邊
舉個例子
int a = 10; int* const b1 = &a; //頂層const,b1本身是一個常量 const int* b2 = &a; //底層const,b2本身可變,所指的對象是常量 const int b3 = 20; //頂層const,b3是常量不可變 const int* const b4 = &a; //前一個const為底層,后一個為頂層,b4不可變 const int& b5 = a; //用于聲明引用變量,都是底層const
區分作用
執行對象拷貝時有限制,常量的底層const不能賦值給非常量的底層const
使用命名的強制類型轉換函數const_cast時,只能改變運算對象的底層const
《C++ 頂層const與底層const總結》:
https://www.jianshu.com/p/fbbcf11100f6
《C++的頂層const和底層const淺析》:
https://blog.csdn.net/qq_37059483/article/details/78811231
const int a; int const a; const int *a; int *const a;
int const a和const int a均表示定義常量類型a。
const int *a,其中a為指向int型變量的指針,const在 * 左側,表示a指向不可變常量。(看成const (*a),對引用加const)
int *const a,依舊是指針類型,表示a為指向整型數據的常指針。(看成const(a),對指針const)
26、類的對象存儲空間?
非靜態成員的數據類型大小之和。
編譯器加入的額外成員變量(如指向虛函數表的指針)。
為了邊緣對齊優化加入的padding。
27、final和override關鍵字
override
當在父類中使用了虛函數時候,你可能需要在某個子類中對這個虛函數進行重寫,以下方法都可以:
class A { virtual void foo(); } class B : public A { void foo(); //OK virtual void foo(); // OK void foo() override; //OK }
如果不使用override,當你手一抖,將foo()寫成了foo()會怎么樣呢?結果是編譯器并不會報錯,因為它并不知道你的目的是重寫虛函數,而是把它當成了新的函數。如果這個虛函數很重要的話,那就會對整個程序不利。所以,override的作用就出來了,它指定了子類的這個虛函數是重寫的父類的,如果你名字不小心打錯了的話,編譯器是不會編譯通過的:
class A { virtual void foo(); }; class B : public A { virtual void f00(); //OK,這個函數是B新增的,不是繼承的 virtual void f0o() override; //Error, 加了override之后,這個函數一定是繼承自A的,A找不到就報錯 };
final
當不希望某個類被繼承,或不希望某個虛函數被重寫,可以在類名和虛函數后添加final關鍵字,添加final關鍵字后被繼承或重寫,編譯器會報錯。例子如下:
class Base { virtual void foo(); }; class A : public Base { void foo() final; // foo 被override并且是最后一個override,在其子類中不可以重寫 }; class B final : A // 指明B是不可以被繼承的 { void foo() override; // Error: 在A中已經被final了 }; class C : B // Error: B is final { };
《C++:override和final》:
https://www.cnblogs.com/whlook/p/6501918.html
28、拷貝初始化和直接初始化
當用于類類型對象時,初始化的拷貝形式和直接形式有所不同:直接初始化直接調用與實參匹配的構造函數,拷貝初始化總是調用拷貝構造函數。拷貝初始化首先使用指定構造函數創建一個臨時對象,然后用拷貝構造函數將那個臨時對象拷貝到正在創建的對象。舉例如下
string str1(“I am a string”);//語句1 直接初始化 string str2(str1);//語句2 直接初始化,str1是已經存在的對象,直接調用構造函數對str2進行初始化 string str3 = “I am a string”;//語句3 拷貝初始化,先為字符串”I am a string“創建臨時對象,再把臨時對象作為參數,使用拷貝構造函數構造str3 string str4 = str1;//語句4 拷貝初始化,這里相當于隱式調用拷貝構造函數,而不是調用賦值運算符函數
為了提高效率,允許編譯器跳過創建臨時對象這一步,直接調用構造函數構造要創建的對象,這樣就完全等價于直接初始化了(語句1和語句3等價)。但是需要辨別兩種情況。
當拷貝構造函數為private時:語句3和語句4在編譯時會報錯
使用explicit修飾構造函數時:如果構造函數存在隱式轉換,編譯時會報錯
C++的直接初始化與復制初始化的區別:
https://blog.csdn.net/qq936836/article/details/83450218
29、初始化和賦值的區別
對于簡單類型來說,初始化和賦值沒什么區別
對于類和復雜數據類型來說,這兩者的區別就大了,舉例如下:
class A{ public: int num1; int num2; public: A(int a=0, int b=0):num1(a),num2(b){}; A(const A& a){}; //重載 = 號操作符函數 A& operator=(const A& a){ num1 = a.num1 + 1; num2 = a.num2 + 1; return *this; }; }; int main(){ A a(1,1); A a1 = a; //拷貝初始化操作,調用拷貝構造函數 A b; b = a;//賦值操作,對象a中,num1 = 1,num2 = 1;對象b中,num1 = 2,num2 = 2 return 0; }
30、extern“C”的用法
為了能夠正確的在C++代碼中調用C語言的代碼:在程序中加上extern “C”后,相當于告訴編譯器這部分代碼是C語言寫的,因此要按照C語言進行編譯,而不是C++;
哪些情況下使用extern “C”:
(1)C++代碼中調用C語言代碼;
(2)在C++中的頭文件中使用;
(3)在多個人協同開發時,可能有人擅長C語言,而有人擅長C++;
舉個例子,C++中調用C代碼:
#ifndef __MY_HANDLE_H__ #define __MY_HANDLE_H__ extern “C”{ typedef unsigned int result_t; typedef void* my_handle_t; my_handle_t create_handle(const char* name); result_t operate_on_handle(my_handle_t handle); void close_handle(my_handle_t handle); }
參考的blog中有一篇google code上的文章,專門寫extern “C”的,有興趣的讀者不妨去看看
《extern “C”的功能和用法研究》:
https://blog.csdn.net/sss_369/article/details/84060561
綜上,總結出使用方法,在C語言的頭文件中,對其外部函數只能指定為extern類型,C語言中不支持extern “C”聲明,在.c文件中包含了extern “C”時會出現編譯語法錯誤。所以使用extern “C”全部都放在于cpp程序相關文件或其頭文件中。
總結出如下形式:
(1)C++調用C函數:
//xx.h extern int add(。..) //xx.c int add(){ } //xx.cpp extern “C” { #include “xx.h” }
(2)C調用C++函數
//xx.h extern “C”{ int add(); } //xx.cpp int add(){ } //xx.c extern int add();
31、模板函數和模板類的特例化
引入原因
編寫單一的模板,它能適應多種類型的需求,使每種類型都具有相同的功能,但對于某種特定類型,如果要實現其特有的功能,單一模板就無法做到,這時就需要模板特例化
定義
對單一模板提供的一個特殊實例,它將一個或多個模板參數綁定到特定的類型或值上
(1)模板函數特例化
必須為原函數模板的每個模板參數都提供實參,且使用關鍵字template后跟一個空尖括號對《》,表明將原模板的所有模板參數提供實參,舉例如下:
template《typename T》 //模板函數 int compare(const T &v1,const T &v2) { if(v1 》 v2) return -1; if(v2 》 v1) return 1; return 0; } //模板特例化,滿足針對字符串特定的比較,要提供所有實參,這里只有一個T template《》 int compare(const char* const &v1,const char* const &v2) { return strcmp(p1,p2); }
本質
特例化的本質是實例化一個模板,而非重載它。特例化不影響參數匹配。參數匹配都以最佳匹配為原則。例如,此處如果是compare(3,5),則調用普通的模板,若為compare(“hi”,”haha”)則調用特例化版本(因為這個cosnt char*相對于T,更匹配實參類型),注意二者函數體的語句不一樣了,實現不同功能。
注意
模板及其特例化版本應該聲明在同一個頭文件中,且所有同名模板的聲明應該放在前面,后面放特例化版本。
(2)類模板特例化
原理類似函數模板,不過在類中,我們可以對模板進行特例化,也可以對類進行部分特例化。對類進行特例化時,仍然用template《》表示是一個特例化版本,例如:
template《》 class hash《sales_data》 { size_t operator()(sales_data& s); //里面所有T都換成特例化類型版本sales_data //按照最佳匹配原則,若T != sales_data,就用普通類模板,否則,就使用含有特定功能的特例化版本。 };
類模板的部分特例化
不必為所有模板參數提供實參,可以指定一部分而非所有模板參數,一個類模板的部分特例化本身仍是一個模板,使用它時還必須為其特例化版本中未指定的模板參數提供實參(特例化時類名一定要和原來的模板相同,只是參數類型不同,按最佳匹配原則,哪個最匹配,就用相應的模板)
特例化類中的部分成員
可以特例化類中的部分成員函數而不是整個類,舉個例子:
template《typename T》 class Foo { void Bar(); void Barst(T a)(); }; template《》 void Foo《int》::Bar() { //進行int類型的特例化處理 cout 《《 “我是int型特例化” 《《 endl; } Foo《string》 fs; Foo《int》 fi;//使用特例化 fs.Bar();//使用的是普通模板,即Foo《string》::Bar() fi.Bar();//特例化版本,執行Foo《int》::Bar() //Foo《string》::Bar()和Foo《int》::Bar()功能不同
32、C和C++的類型安全
什么是類型安全?
類型安全很大程度上可以等價于內存安全,類型安全的代碼不會試圖訪問自己沒被授權的內存區域。“類型安全”常被用來形容編程語言,其根據在于該門編程語言是否提供保障類型安全的機制;有的時候也用“類型安全”形容某個程序,判別的標準在于該程序是否隱含類型錯誤。類型安全的編程語言與類型安全的程序之間,沒有必然聯系。好的程序員可以使用類型不那么安全的語言寫出類型相當安全的程序,相反的,差一點兒的程序員可能使用類型相當安全的語言寫出類型不太安全的程序。絕對類型安全的編程語言暫時還沒有。
(1)C的類型安全
C只在局部上下文中表現出類型安全,比如試圖從一種結構體的指針轉換成另一種結構體的指針時,編譯器將會報告錯誤,除非使用顯式類型轉換。然而,C中相當多的操作是不安全的。以下是兩個十分常見的例子:
printf格式輸出
上述代碼中,使用%d控制整型數字的輸出,沒有問題,但是改成%f時,明顯輸出錯誤,再改成%s時,運行直接報segmentation fault錯誤
malloc函數的返回值
malloc是C中進行內存分配的函數,它的返回類型是void*即空類型指針,常常有這樣的用法char* pStr=(char*)malloc(100*sizeof(char)),這里明顯做了顯式的類型轉換。類型匹配尚且沒有問題,但是一旦出現int* pInt=(int*)malloc(100*sizeof(char))就很可能帶來一些問題,而這樣的轉換C并不會提示錯誤。
(2)C++的類型安全
如果C++使用得當,它將遠比C更有類型安全性。相比于C語言,C++提供了一些新的機制保障類型安全:
操作符new返回的指針類型嚴格與對象匹配,而不是void*
C中很多以void*為參數的函數可以改寫為C++模板函數,而模板是支持類型檢查的;
引入const關鍵字代替#define constants,它是有類型、有作用域的,而#define constants只是簡單的文本替換
一些#define宏可被改寫為inline函數,結合函數的重載,可在類型安全的前提下支持多種類型,當然改寫為模板也能保證類型安全
C++提供了dynamic_cast關鍵字,使得轉換過程更加安全,因為dynamic_cast比static_cast涉及更多具體的類型檢查。
例1:使用void*進行類型轉換
例2:不同類型指針之間轉換
#include《iostream》 using namespace std; class Parent{}; class Child1 : public Parent { public: int i; Child1(int e):i(e){} }; class Child2 : public Parent { public: double d; Child2(double e):d(e){} }; int main() { Child1 c1(5); Child2 c2(4.1); Parent* pp; Child1* pc1; pp=&c1; pc1=(Child1*)pp; // 類型向下轉換 強制轉換,由于類型仍然為Child1*,不造成錯誤 cout《《pc1-》i《《endl; //輸出:5 pp=&c2; pc1=(Child1*)pp; //強制轉換,且類型發生變化,將造成錯誤 cout《《pc1-》i《《endl;// 輸出:1717986918 return 0; }
上面兩個例子之所以引起類型不安全的問題,是因為程序員使用不得當。第一個例子用到了空類型指針void*,第二個例子則是在兩個類型指針之間進行強制轉換。因此,想保證程序的類型安全性,應盡量避免使用空類型指針void*,盡量不對兩種類型指針做強制轉換。
33、為什么析構函數一般寫成虛函數
由于類的多態性,基類指針可以指向派生類的對象,如果刪除該基類的指針,就會調用該指針指向的派生類析構函數,而派生類的析構函數又自動調用基類的析構函數,這樣整個派生類的對象完全被釋放。如果析構函數不被聲明成虛函數,則編譯器實施靜態綁定,在刪除基類指針時,只會調用基類的析構函數而不調用派生類析構函數,這樣就會造成派生類對象析構不完全,造成內存泄漏。所以將析構函數聲明為虛函數是十分必要的。在實現多態時,當用基類操作派生類,在析構時防止只析構基類而不析構派生類的狀況發生,要將基類的析構函數聲明為虛函數。舉個例子:
#include 《iostream》 using namespace std; class Parent{ public: Parent(){ cout 《《 “Parent construct function” 《《 endl; }; ~Parent(){ cout 《《 “Parent destructor function” 《《endl; } }; class Son : public Parent{ public: Son(){ cout 《《 “Son construct function” 《《 endl; }; ~Son(){ cout 《《 “Son destructor function” 《《endl; } }; int main() { Parent* p = new Son(); delete p; p = NULL; return 0; } //運行結果: //Parent construct function //Son construct function //Parent destructor function
將基類的析構函數聲明為虛函數:
#include 《iostream》 using namespace std; class Parent{ public: Parent(){ cout 《《 “Parent construct function” 《《 endl; }; virtual ~Parent(){ cout 《《 “Parent destructor function” 《《endl; } }; class Son : public Parent{ public: Son(){ cout 《《 “Son construct function” 《《 endl; }; ~Son(){ cout 《《 “Son destructor function” 《《endl; } }; int main() { Parent* p = new Son(); delete p; p = NULL; return 0; } //運行結果: //Parent construct function //Son construct function //Son destructor function //Parent destructor function
34、構造函數能否聲明為虛函數或者純虛函數,析構函數呢?
析構函數:
析構函數可以為虛函數,并且一般情況下基類析構函數要定義為虛函數。
只有在基類析構函數定義為虛函數時,調用操作符delete銷毀指向對象的基類指針時,才能準確調用派生類的析構函數(從該級向上按序調用虛函數),才能準確銷毀數據。
析構函數可以是純虛函數,含有純虛函數的類是抽象類,此時不能被實例化。但派生類中可以根據自身需求重新改寫基類中的純虛函數。
構造函數:
構造函數不能定義為虛函數。在構造函數中可以調用虛函數,不過此時調用的是正在構造的類中的虛函數,而不是子類的虛函數,因為此時子類尚未構造好。
35、C++中的重載、重寫(覆蓋)和隱藏的區別
(1)重載(overload)
重載是指在同一范圍定義中的同名成員函數才存在重載關系。主要特點是函數名相同,參數類型和數目有所不同,不能出現參數個數和類型均相同,僅僅依靠返回值不同來區分的函數。重載和函數成員是否是虛函數無關。舉個例子:
class A{ 。.. virtual int fun(); void fun(int); void fun(double, double); static int fun(char); 。.. }
(2)重寫(覆蓋)(override)
重寫指的是在派生類中覆蓋基類中的同名函數,重寫就是重寫函數體,要求基類函數必須是虛函數且:
與基類的虛函數有相同的參數個數
與基類的虛函數有相同的參數類型
與基類的虛函數有相同的返回值類型
舉個例子:
//父類 class A{ public: virtual int fun(int a){} } //子類 class B : public A{ public: //重寫,一般加override可以確保是重寫父類的函數 virtual int fun(int a) override{} }
重載與重寫的區別:
重寫是父類和子類之間的垂直關系,重載是不同函數之間的水平關系
重寫要求參數列表相同,重載則要求參數列表不同,返回值不要求
重寫關系中,調用方法根據對象類型決定,重載根據調用時實參表與形參表的對應關系來選擇函數體
(3)隱藏(hide)
隱藏指的是某些情況下,派生類中的函數屏蔽了基類中的同名函數,包括以下情況:
兩個函數參數相同,但是基類函數不是虛函數。和重寫的區別在于基類函數是否是虛函數。舉個例子:
//父類 class A{ public: void fun(int a){ cout 《《 “A中的fun函數” 《《 endl; } }; //子類 class B : public A{ public: //隱藏父類的fun函數 void fun(int a){ cout 《《 “B中的fun函數” 《《 endl; } }; int main(){ B b; b.fun(2); //調用的是B中的fun函數 b.A::fun(2); //調用A中fun函數 return 0; }
兩個函數參數不同,無論基類函數是不是虛函數,都會被隱藏。和重載的區別在于兩個函數不在同一個類中。舉個例子:
//父類 class A{ public: virtual void fun(int a){ cout 《《 “A中的fun函數” 《《 endl; } }; //子類 class B : public A{ public: //隱藏父類的fun函數 virtual void fun(char* a){ cout 《《 “A中的fun函數” 《《 endl; } }; int main(){ B b; b.fun(2); //報錯,調用的是B中的fun函數,參數類型不對 b.A::fun(2); //調用A中fun函數 return 0; }
36、C++的多態如何實現
C++的多態性,一言以蔽之就是:
在基類的函數前加上virtual關鍵字,在派生類中重寫該函數,運行時將會根據所指對象的實際類型來調用相應的函數,如果對象類型是派生類,就調用派生類的函數,如果對象類型是基類,就調用基類的函數。
舉個例子:
#include 《iostream》 using namespace std; class Base{ public: virtual void fun(){ cout 《《 “ Base::func()” 《《endl; } }; class Son1 : public Base{ public: virtual void fun() override{ cout 《《 “ Son1::func()” 《《endl; } }; class Son2 : public Base{ }; int main() { Base* base = new Son1; base-》fun(); base = new Son2; base-》fun(); delete base; base = NULL; return 0; } // 運行結果 // Son1::func() // Base::func()
例子中,Base為基類,其中的函數為虛函數。子類1繼承并重寫了基類的函數,子類2繼承基類但沒有重寫基類的函數,從結果分析子類體現了多態性,那么為什么會出現多態性,其底層的原理是什么?這里需要引出虛表和虛基表指針的概念。
虛表:虛函數表的縮寫,類中含有virtual關鍵字修飾的方法時,編譯器會自動生成虛表
虛表指針:在含有虛函數的類實例化對象時,對象地址的前四個字節存儲的指向虛表的指針
上圖中展示了虛表和虛表指針在基類對象和派生類對象中的模型,下面闡述實現多態的過程:
(1)編譯器在發現基類中有虛函數時,會自動為每個含有虛函數的類生成一份虛表,該表是一個一維數組,虛表里保存了虛函數的入口地址
(2)編譯器會在每個對象的前四個字節中保存一個虛表指針,即vptr,指向對象所屬類的虛表。在構造時,根據對象的類型去初始化虛指針vptr,從而讓vptr指向正確的虛表,從而在調用虛函數時,能找到正確的函數
(3)所謂的合適時機,在派生類定義對象時,程序運行會自動調用構造函數,在構造函數中創建虛表并對虛表初始化。在構造子類對象時,會先調用父類的構造函數,此時,編譯器只“看到了”父類,并為父類對象初始化虛表指針,令它指向父類的虛表;當調用子類的構造函數時,為子類對象初始化虛表指針,令它指向子類的虛表
(4)當派生類對基類的虛函數沒有重寫時,派生類的虛表指針指向的是基類的虛表;當派生類對基類的虛函數重寫時,派生類的虛表指針指向的是自身的虛表;當派生類中有自己的虛函數時,在自己的虛表中將此虛函數地址添加在后面
這樣指向派生類的基類指針在運行時,就可以根據派生類對虛函數重寫情況動態的進行調用,從而實現多態性。
37、C++有哪幾種的構造函數
C++中的構造函數可以分為4類:
默認構造函數
初始化構造函數(有參數)
拷貝構造函數
移動構造函數(move和右值引用)
委托構造函數
轉換構造函數
舉個例子:
#include 《iostream》 using namespace std; class Student{ public: Student(){//默認構造函數,沒有參數 this-》age = 20; this-》num = 1000; }; Student(int a, int n):age(a), num(n){}; //初始化構造函數,有參數和參數列表 Student(const Student& s){//拷貝構造函數,這里與編譯器生成的一致 this-》age = s.age; this-》num = s.num; }; Student(int r){ //轉換構造函數,形參是其他類型變量,且只有一個形參 this-》age = r; this-》num = 1002; }; ~Student(){} public: int age; int num; }; int main(){ Student s1; Student s2(18,1001); int a = 10; Student s3(a); Student s4(s3); printf(“s1 age:%d, num:%d ”, s1.age, s1.num); printf(“s2 age:%d, num:%d ”, s2.age, s2.num); printf(“s3 age:%d, num:%d ”, s3.age, s3.num); printf(“s2 age:%d, num:%d ”, s4.age, s4.num); return 0; } //運行結果 //s1 age:20, num:1000 //s2 age:18, num:1001 //s3 age:10, num:1002 //s2 age:10, num:1002
默認構造函數和初始化構造函數在定義類的對象,完成對象的初始化工作
復制構造函數用于復制本類的對象
轉換構造函數用于將其他類型的變量,隱式轉換為本類對象
《淺談C++中的幾種構造函數》:
https://blog.csdn.net/zxc024000/article/details/51153743
38、淺拷貝和深拷貝的區別
淺拷貝
淺拷貝只是拷貝一個指針,并沒有新開辟一個地址,拷貝的指針和原來的指針指向同一塊地址,如果原來的指針所指向的資源釋放了,那么再釋放淺拷貝的指針的資源就會出現錯誤。
深拷貝
深拷貝不僅拷貝值,還開辟出一塊新的空間用來存放新的值,即使原先的對象被析構掉,釋放內存了也不會影響到深拷貝得到的值。在自己實現拷貝賦值的時候,如果有指針變量的話是需要自己實現深拷貝的。
#include 《iostream》 #include 《string.h》 using namespace std; class Student { private: int num; char *name; public: Student(){ name = new char(20); cout 《《 “Student” 《《 endl; }; ~Student(){ cout 《《 “~Student ” 《《 &name 《《 endl; delete name; name = NULL; }; Student(const Student &s){//拷貝構造函數 //淺拷貝,當對象的name和傳入對象的name指向相同的地址 name = s.name; //深拷貝 //name = new char(20); //memcpy(name, s.name, strlen(s.name)); cout 《《 “copy Student” 《《 endl; }; }; int main() { {// 花括號讓s1和s2變成局部對象,方便測試 Student s1; Student s2(s1);// 復制對象 } system(“pause”); return 0; } //淺拷貝執行結果: //Student //copy Student //~Student 0x7fffed0c3ec0 //~Student 0x7fffed0c3ed0 //*** Error in `/tmp/815453382/a.out‘: double free or corruption (fasttop): 0x0000000001c82c20 *** //深拷貝執行結果: //Student //copy Student //~Student 0x7fffebca9fb0 //~Student 0x7fffebca9fc0
從執行結果可以看出,淺拷貝在對象的拷貝創建時存在風險,即被拷貝的對象析構釋放資源之后,拷貝對象析構時會再次釋放一個已經釋放的資源,深拷貝的結果是兩個對象之間沒有任何關系,各自成員地址不同。
《C++面試題之淺拷貝和深拷貝的區別》:
https://blog.csdn.net/caoshangpa/article/details/79226270
39、內聯函數和宏定義的區別
內聯(inline)函數和普通函數相比可以加快程序運行的速度,因為不需要中斷調用,在編譯的時候內聯函數可以直接嵌入到目標代碼中。
內聯函數適用場景
使用宏定義的地方都可以使用inline函數
作為類成員接口函數來讀寫類的私有成員或者保護成員,會提高效率
為什么不能把所有的函數寫成內聯函數
內聯函數以代碼復雜為代價,它以省去函數調用的開銷來提高執行效率。所以一方面如果內聯函數體內代碼執行時間相比函數調用開銷較大,則沒有太大的意義;另一方面每一處內聯函數的調用都要復制代碼,消耗更多的內存空間,因此以下情況不宜使用內聯函數:
函數體內的代碼比較長,將導致內存消耗代價
函數體內有循環,函數執行時間要比函數調用開銷大
主要區別
內聯函數在編譯時展開,宏在預編譯時展開
內聯函數直接嵌入到目標代碼中,宏是簡單的做文本替換
內聯函數有類型檢測、語法判斷等功能,而宏沒有
內聯函數是函數,宏不是
宏定義時要注意書寫(參數要括起來)否則容易出現歧義,內聯函數不會產生歧義
內聯函數代碼是被放到符號表中,使用時像宏一樣展開,沒有調用的開銷,效率很高;
在使用時,宏只做簡單字符串替換(編譯前)。而內聯函數可以進行參數類型檢查(編譯時),且具有返回值。
內聯函數本身是函數,強調函數特性,具有重載等功能。
內聯函數可以作為某個類的成員函數,這樣可以使用類的保護成員和私有成員,進而提升效率。而當一個表達式涉及到類保護成員或私有成員時,宏就不能實現了。
40、構造函數、析構函數、虛函數可否聲明為內聯函數
首先,將這些函數聲明為內聯函數,在語法上沒有錯誤。因為inline同register一樣,只是個建議,編譯器并不一定真正的內聯。
register關鍵字:這個關鍵字請求編譯器盡可能的將變量存在CPU內部寄存器中,而不是通過內存尋址訪問,以提高效率
舉個例子:
#include 《iostream》 using namespace std; class A { public: inline A() { cout 《《 “inline construct()” 《《endl; } inline ~A() { cout 《《 “inline destruct()” 《《endl; } inline virtual void virtualFun() { cout 《《 “inline virtual function” 《《endl; } }; int main() { A a; a.virtualFun(); return 0; } //輸出結果 //inline construct() //inline virtual function //inline destruct()
構造函數和析構函數聲明為內聯函數是沒有意義的
《Effective C++》中所闡述的是:將構造函數和析構函數聲明為inline是沒有什么意義的,即編譯器并不真正對聲明為inline的構造和析構函數進行內聯操作,因為編譯器會在構造和析構函數中添加額外的操作(申請/釋放內存,構造/析構對象等),致使構造函數/析構函數并不像看上去的那么精簡。其次,class中的函數默認是inline型的,編譯器也只是有選擇性的inline,將構造函數和析構函數聲明為內聯函數是沒有什么意義的。
將虛函數聲明為inline,要分情況討論
有的人認為虛函數被聲明為inline,但是編譯器并沒有對其內聯,他們給出的理由是inline是編譯期決定的,而虛函數是運行期決定的,即在不知道將要調用哪個函數的情況下,如何將函數內聯呢?
上述觀點看似正確,其實不然,如果虛函數在編譯器就能夠決定將要調用哪個函數時,就能夠內聯,那么什么情況下編譯器可以確定要調用哪個函數呢,答案是當用對象調用虛函數(此時不具有多態性)時,就內聯展開
綜上,當是指向派生類的指針(多態性)調用聲明為inline的虛函數時,不會內聯展開;當是對象本身調用虛函數時,會內聯展開,當然前提依然是函數并不復雜的情況下
《構造函數、析構函數、虛函數可否內聯,有何意義》:
https://www.cnblogs.com/helloweworld/archive/2013/06/14/3136705.html
41、auto、decltype和decltype(auto)的用法
(1)auto
C++11新標準引入了auto類型說明符,用它就能讓編譯器替我們去分析表達式所屬的類型。和原來那些只對應某種特定的類型說明符(例如 int)不同,
auto 讓編譯器通過初始值來進行類型推演。從而獲得定義變量的類型,所以說 auto 定義的變量必須有初始值。舉個例子:
//普通;類型 int a = 1, b = 3; auto c = a + b;// c為int型 //const類型 const int i = 5; auto j = i; // 變量i是頂層const, 會被忽略, 所以j的類型是int auto k = &i; // 變量i是一個常量, 對常量取地址是一種底層const, 所以b的類型是const int* const auto l = i; //如果希望推斷出的類型是頂層const的, 那么就需要在auto前面加上cosnt //引用和指針類型 int x = 2; int& y = x; auto z = y; //z是int型不是int& 型 auto& p1 = y; //p1是int&型 auto p2 = &x; //p2是指針類型int*
(2)decltype
有的時候我們還會遇到這種情況,我們希望從表達式中推斷出要定義變量的類型,但卻不想用表達式的值去初始化變量。還有可能是函數的返回類型為某表達式的值類型。在這些時候auto顯得就無力了,所以C++11又引入了第二種類型說明符decltype,它的作用是選擇并返回操作數的數據類型。在此過程中,編譯器只是分析表達式并得到它的類型,卻不進行實際的計算表達式的值。
int func() {return 0}; //普通類型 decltype(func()) sum = 5; // sum的類型是函數func()的返回值的類型int, 但是這時不會實際調用函數func() int a = 0; decltype(a) b = 4; // a的類型是int, 所以b的類型也是int //不論是頂層const還是底層const, decltype都會保留 const int c = 3; decltype(c) d = c; // d的類型和c是一樣的, 都是頂層const int e = 4; const int* f = &e; // f是底層const decltype(f) g = f; // g也是底層const //引用與指針類型 //1. 如果表達式是引用類型, 那么decltype的類型也是引用 const int i = 3, &j = i; decltype(j) k = 5; // k的類型是 const int& //2. 如果表達式是引用類型, 但是想要得到這個引用所指向的類型, 需要修改表達式: int i = 3, &r = i; decltype(r + 0) t = 5; // 此時是int類型 //3. 對指針的解引用操作返回的是引用類型 int i = 3, j = 6, *p = &i; decltype(*p) c = j; // c是int&類型, c和j綁定在一起 //4. 如果一個表達式的類型不是引用, 但是我們需要推斷出引用, 那么可以加上一對括號, 就變成了引用類型了 int i = 3; decltype((i)) j = i; // 此時j的類型是int&類型, j和i綁定在了一起
(3)decltype(auto)
decltype(auto)是C++14新增的類型指示符,可以用來聲明變量以及指示函數返回類型。在使用時,會將“=”號左邊的表達式替換掉auto,再根據decltype的語法規則來確定類型。舉個例子:
int e = 4; const int* f = &e; // f是底層const decltype(auto) j = f;//j的類型是const int* 并且指向的是e
《auto和decltype的用法總結》:
https://www.cnblogs.com/XiangfeiAi/p/4451904.html
《C++11新特性中auto 和 decltype 區別和聯系》:
https://www.jb51.net/article/103666.htm
42、public,protected和private訪問和繼承權限/public/protected/private的區別?
public的變量和函數在類的內部外部都可以訪問。
protected的變量和函數只能在類的內部和其派生類中訪問。
private修飾的元素只能在類內訪問。
(一)訪問權限
派生類可以繼承基類中除了構造/析構、賦值運算符重載函數之外的成員,但是這些成員的訪問屬性在派生過程中也是可以調整的,三種派生方式的訪問權限如下表所示:注意外部訪問并不是真正的外部訪問,而是在通過派生類的對象對基類成員的訪問。

派生類對基類成員的訪問形象有如下兩種:
內部訪問:由派生類中新增的成員函數對從基類繼承來的成員的訪問
外部訪問:在派生類外部,通過派生類的對象對從基類繼承來的成員的訪問
(二)繼承權限
public繼承
公有繼承的特點是基類的公有成員和保護成員作為派生類的成員時,都保持原有的狀態,而基類的私有成員任然是私有的,不能被這個派生類的子類所訪問
protected繼承
保護繼承的特點是基類的所有公有成員和保護成員都成為派生類的保護成員,并且只能被它的派生類成員函數或友元函數訪問,基類的私有成員仍然是私有的。
private繼承
私有繼承的特點是基類的所有公有成員和保護成員都成為派生類的私有成員,并不被它的派生類的子類所訪問,基類的成員只能由自己派生類訪問,無法再往下繼承,訪問規則如下表

43、如何用代碼判斷大小端存儲
大端存儲:字數據的高字節存儲在低地址中
小端存儲:字數據的低字節存儲在低地址中
例如:32bit的數字0x12345678
所以在Socket編程中,往往需要將操作系統所用的小端存儲的IP地址轉換為大端存儲,這樣才能進行網絡傳輸
小端模式中的存儲方式為:

大端模式中的存儲方式為:

了解了大小端存儲的方式,如何在代碼中進行判斷呢?下面介紹兩種判斷方式:
方式一:使用強制類型轉換-這種法子不錯
#include 《iostream》 using namespace std; int main() { int a = 0x1234; //由于int和char的長度不同,借助int型轉換成char型,只會留下低地址的部分 char c = (char)(a); if (c == 0x12) cout 《《 “big endian” 《《 endl; else if(c == 0x34) cout 《《 “little endian” 《《 endl; }
方式二:巧用union聯合體
#include 《iostream》 using namespace std; //union聯合體的重疊式存儲,endian聯合體占用內存的空間為每個成員字節長度的最大值 union endian { int a; char ch; }; int main() { endian value; value.a = 0x1234; //a和ch共用4字節的內存空間 if (value.ch == 0x12) cout 《《 “big endian”《《endl; else if (value.ch == 0x34) cout 《《 “little endian”《《endl; }
《寫程序判斷系統是大端序還是小端序》:
https://www.cnblogs.com/zhoudayang/p/5985563.html
44、volatile、mutable和explicit關鍵字的用法
(1)volatile
volatile 關鍵字是一種類型修飾符,用它聲明的類型變量表示可以被某些編譯器未知的因素更改,比如:操作系統、硬件或者其它線程等。遇到這個關鍵字聲明的變量,編譯器對訪問該變量的代碼就不再進行優化,從而可以提供對特殊地址的穩定訪問。
當要求使用 volatile 聲明的變量的值的時候,系統總是重新從它所在的內存讀取數據,即使它前面的指令剛剛從該處讀取過數據。
volatile定義變量的值是易變的,每次用到這個變量的值的時候都要去重新讀取這個變量的值,而不是讀寄存器內的備份。多線程中被幾個任務共享的變量需要定義為volatile類型。
volatile 指針
volatile 指針和 const 修飾詞類似,const 有常量指針和指針常量的說法,volatile 也有相應的概念
修飾由指針指向的對象、數據是 const 或 volatile 的:
const char* cpch; volatile char* vpch;
指針自身的值——一個代表地址的整數變量,是 const 或 volatile 的:
char* const pchc; char* volatile pchv;
注意:
可以把一個非volatile int賦給volatile int,但是不能把非volatile對象賦給一個volatile對象。
除了基本類型外,對用戶定義類型也可以用volatile類型進行修飾。
C++中一個有volatile標識符的類只能訪問它接口的子集,一個由類的實現者控制的子集。用戶只能用const_cast來獲得對類型接口的完全訪問。此外,volatile向const一樣會從類傳遞到它的成員。
多線程下的volatile
有些變量是用volatile關鍵字聲明的。當兩個線程都要用到某一個變量且該變量的值會被改變時,應該用volatile聲明,該關鍵字的作用是防止優化編譯器把變量從內存裝入CPU寄存器中。如果變量被裝入寄存器,那么兩個線程有可能一個使用內存中的變量,一個使用寄存器中的變量,這會造成程序的錯誤執行。volatile的意思是讓編譯器每次操作該變量時一定要從內存中真正取出,而不是使用已經存在寄存器中的值。
(2)mutable
mutable的中文意思是“可變的,易變的”,跟constant(既C++中的const)是反義詞。在C++中,mutable也是為了突破const的限制而設置的。被mutable修飾的變量,將永遠處于可變的狀態,即使在一個const函數中。我們知道,如果類的成員函數不會改變對象的狀態,那么這個成員函數一般會聲明成const的。但是,有些時候,我們需要在const函數里面修改一些跟類狀態無關的數據成員,那么這個函數就應該被mutable來修飾,并且放在函數后后面關鍵字位置。
(3)explicit
explicit關鍵字用來修飾類的構造函數,被修飾的構造函數的類,不能發生相應的隱式類型轉換,只能以顯示的方式進行類型轉換,注意以下幾點:
explicit 關鍵字只能用于類內部的構造函數聲明上
explicit 關鍵字作用于單個參數的構造函數
被explicit修飾的構造函數的類,不能發生相應的隱式類型轉換
45、什么情況下會調用拷貝構造函數
用類的一個實例化對象去初始化另一個對象的時候
函數的參數是類的對象時(非引用傳遞)
函數的返回值是函數體內局部對象的類的對象時 ,此時雖然發生(Named return Value優化)NRV優化,但是由于返回方式是值傳遞,所以會在返回值的地方調用拷貝構造函數
另:第三種情況在Linux g++ 下則不會發生拷貝構造函數,不僅如此即使返回局部對象的引用,依然不會發生拷貝構造函數
總結就是:即使發生NRV優化的情況下,Linux+ g++的環境是不管值返回方式還是引用方式返回的方式都不會發生拷貝構造函數,而Windows + VS2019在值返回的情況下發生拷貝構造函數,引用返回方式則不發生拷貝構造函數。
在c++編譯器發生NRV優化,如果是引用返回的形式則不會調用拷貝構造函數,如果是值傳遞的方式依然會發生拷貝構造函數。
在VS2019下進行下述實驗:
舉個例子:
class A { public: A() {}; A(const A& a) { cout 《《 “copy constructor is called” 《《 endl; }; ~A() {}; }; void useClassA(A a) {} A getClassA()//此時會發生拷貝構造函數的調用,雖然發生NRV優化,但是依然調用拷貝構造函數 { A a; return a; } //A& getClassA2()// VS2019下,此時編輯器會進行(Named return Value優化)NRV優化,不調用拷貝構造函數 ,如果是引用傳遞的方式返回當前函數體內生成的對象時,并不發生拷貝構造函數的調用 //{ // A a; // return a; //} int main() { A a1, a2,a3,a4; A a2 = a1; //調用拷貝構造函數,對應情況1 useClassA(a1);//調用拷貝構造函數,對應情況2 a3 = getClassA();//發生NRV優化,但是值返回,依然會有拷貝構造函數的調用 情況3 a4 = getClassA2(a1);//發生NRV優化,且引用返回自身,不會調用 return 0; }
情況1比較好理解
情況2的實現過程是,調用函數時先根據傳入的實參產生臨時對象,再用拷貝構造去初始化這個臨時對象,在函數中與形參對應,函數調用結束后析構臨時對象
情況3在執行return時,理論的執行過程是:產生臨時對象,調用拷貝構造函數把返回對象拷貝給臨時對象,函數執行完先析構局部變量,再析構臨時對象, 依然會調用拷貝構造函數
《C++拷貝構造函數詳解》:
https://www.cnblogs.com/alantu2018/p/8459250.html
46、C++中有幾種類型的new
在C++中,new有三種典型的使用方法:plain new,nothrow new和placement new
(1)plain new
言下之意就是普通的new,就是我們常用的new,在C++中定義如下:
void* operator new(std::size_t) throw(std::bad_alloc); void operator delete(void *) throw();
因此plain new在空間分配失敗的情況下,拋出異常std::bad_alloc而不是返回NULL,因此通過判斷返回值是否為NULL是徒勞的,舉個例子:
#include 《iostream》 #include 《string》 using namespace std; int main() { try { char *p = new char[10e11]; delete p; } catch (const std::bad_alloc &ex) { cout 《《 ex.what() 《《 endl; } return 0; } //執行結果:bad allocation
(2)nothrow new
nothrow new在空間分配失敗的情況下是不拋出異常,而是返回NULL,定義如下:
void * operator new(std::size_t,const std::nothrow_t&) throw(); void operator delete(void*) throw();
舉個例子:
#include 《iostream》 #include 《string》 using namespace std; int main() { char *p = new(nothrow) char[10e11]; if (p == NULL) { cout 《《 “alloc failed” 《《 endl; } delete p; return 0; } //運行結果:alloc failed
(3)placement new
這種new允許在一塊已經分配成功的內存上重新構造對象或對象數組。placement new不用擔心內存分配失敗,因為它根本不分配內存,它做的唯一一件事情就是調用對象的構造函數。定義如下:
void* operator new(size_t,void*); void operator delete(void*,void*);
使用placement new需要注意兩點:
palcement new的主要用途就是反復使用一塊較大的動態分配的內存來構造不同類型的對象或者他們的數組
placement new構造起來的對象數組,要顯式的調用他們的析構函數來銷毀(析構函數并不釋放對象的內存),千萬不要使用delete,這是因為placement new構造起來的對象或數組大小并不一定等于原來分配的內存大小,使用delete會造成內存泄漏或者之后釋放內存時出現運行時錯誤。
舉個例子:
#include 《iostream》 #include 《string》 using namespace std; class ADT{ int i; int j; public: ADT(){ i = 10; j = 100; cout 《《 “ADT construct i=” 《《 i 《《 “j=”《《j 《《endl; } ~ADT(){ cout 《《 “ADT destruct” 《《 endl; } }; int main() { char *p = new(nothrow) char[sizeof ADT + 1]; if (p == NULL) { cout 《《 “alloc failed” 《《 endl; } ADT *q = new(p) ADT; //placement new:不必擔心失敗,只要p所指對象的的空間足夠ADT創建即可 //delete q;//錯誤!不能在此處調用delete q; q-》ADT::~ADT();//顯示調用析構函數 delete[] p; return 0; } //輸出結果: //ADT construct i=10j=100 //ADT destruct
47、C++中NULL和nullptr區別
算是為了與C語言進行兼容而定義的一個問題吧
NULL來自C語言,一般由宏定義實現,而 nullptr 則是C++11的新增關鍵字。在C語言中,NULL被定義為(void*)0,而在C++語言中,NULL則被定義為整數0。編譯器一般對其實際定義如下:
#ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif
在C++中指針必須有明確的類型定義。但是將NULL定義為0帶來的另一個問題是無法與整數的0區分。因為C++中允許有函數重載,所以可以試想如下函數定義情況:
#include 《iostream》 using namespace std; void fun(char* p) { cout 《《 “char*” 《《 endl; } void fun(int p) { cout 《《 “int” 《《 endl; } int main() { fun(NULL); return 0; } //輸出結果:int
那么在傳入NULL參數時,會把NULL當做整數0來看,如果我們想調用參數是指針的函數,該怎么辦呢?。nullptr在C++11被引入用于解決這一問題,nullptr可以明確區分整型和指針類型,能夠根據環境自動轉換成相應的指針類型,但不會被轉換為任何整型,所以不會造成參數傳遞錯誤。
nullptr的一種實現方式如下:
const class nullptr_t{ public: template《class T》 inline operator T*() const{ return 0; } template《class C, class T》 inline operator T C::*() const { return 0; } private: void operator&() const; } nullptr = {};
以上通過模板類和運算符重載的方式來對不同類型的指針進行實例化從而解決了(void*)指針帶來參數類型不明的問題,另外由于nullptr是明確的指針類型,所以不會與整形變量相混淆。但nullptr仍然存在一定問題,例如:
#include 《iostream》 using namespace std; void fun(char* p) { cout《《 “char* p” 《《endl; } void fun(int* p) { cout《《 “int* p” 《《endl; } void fun(int p) { cout《《 “int p” 《《endl; } int main() { fun((char*)nullptr);//語句1 fun(nullptr);//語句2 fun(NULL);//語句3 return 0; } //運行結果: //語句1:char* p //語句2:報錯,有多個匹配 //3:int p
在這種情況下存在對不同指針類型的函數重載,此時如果傳入nullptr指針則仍然存在無法區分應實際調用哪個函數,這種情況下必須顯示的指明參數類型。
48、簡要說明C++的內存分區
C++中的內存分區,分別是堆、棧、自由存儲區、全局/靜態存儲區、常量存儲區和代碼區。如下圖所示
棧:在執行函數時,函數內局部變量的存儲單元都可以在棧上創建,函數執行結束時這些存儲單元自動被釋放。棧內存分配運算內置于處理器的指令集中,效率很高,但是分配的內存容量有限
堆:就是那些由 new分配的內存塊,他們的釋放編譯器不去管,由我們的應用程序去控制,一般一個new就要對應一個 delete。如果程序員沒有釋放掉,那么在程序結束后,操作系統會自動回收
自由存儲區:就是那些由malloc等分配的內存塊,它和堆是十分相似的,不過它是用free來結束自己的生命的
全局/靜態存儲區:全局變量和靜態變量被分配到同一塊內存中,在以前的C語言中,全局變量和靜態變量又分為初始化的和未初始化的,在C++里面沒有這個區分了,它們共同占用同一塊內存區,在該區定義的變量若沒有初始化,則會被自動初始化,例如int型變量自動初始為0
常量存儲區:這是一塊比較特殊的存儲區,這里面存放的是常量,不允許修改
代碼區:存放函數體的二進制代碼
49、C++的異常處理的方法
在程序執行過程中,由于程序員的疏忽或是系統資源緊張等因素都有可能導致異常,任何程序都無法保證絕對的穩定,常見的異常有:
數組下標越界
除法計算時除數為0
動態分配空間時空間不足
…
如果不及時對這些異常進行處理,程序多數情況下都會崩潰。
(1)try、throw和catch關鍵字
C++中的異常處理機制主要使用try、throw和catch三個關鍵字,其在程序中的用法如下:
#include 《iostream》 using namespace std; int main() { double m = 1, n = 0; try { cout 《《 “before dividing.” 《《 endl; if (n == 0) throw - 1; //拋出int型異常 else if (m == 0) throw - 1.0; //拋出 double 型異常 else cout 《《 m / n 《《 endl; cout 《《 “after dividing.” 《《 endl; } catch (double d) { cout 《《 “catch (double)” 《《 d 《《 endl; } catch (。..) { cout 《《 “catch (。..)” 《《 endl; } cout 《《 “finished” 《《 endl; return 0; } //運行結果 //before dividing. //catch (。..) //finished
代碼中,對兩個數進行除法計算,其中除數為0。可以看到以上三個關鍵字,程序的執行流程是先執行try包裹的語句塊,如果執行過程中沒有異常發生,則不會進入任何catch包裹的語句塊。如果發生異常,則使用throw進行異常拋出,再由catch進行捕獲,throw可以拋出各種數據類型的信息,代碼中使用的是數字,也可以自定義異常class。
catch根據throw拋出的數據類型進行精確捕獲(不會出現類型轉換),如果匹配不到就直接報錯,可以使用catch(…)的方式捕獲任何異常(不推薦)。
當然,如果catch了異常,當前函數如果不進行處理,或者已經處理了想通知上一層的調用者,可以在catch里面再throw異常。
(2)函數的異常聲明列表
有時候,程序員在定義函數的時候知道函數可能發生的異常,可以在函數聲明和定義時,指出所能拋出異常的列表,寫法如下:
int fun() throw(int,double,A,B,C){。..};
這種寫法表名函數可能會拋出int,double型或者A、B、C三種類型的異常,如果throw中為空,表明不會拋出任何異常,如果沒有throw則可能拋出任何異常
(3)C++標準異常類 exception
C++ 標準庫中有一些類代表異常,這些類都是從 exception 類派生而來的,如下圖所示
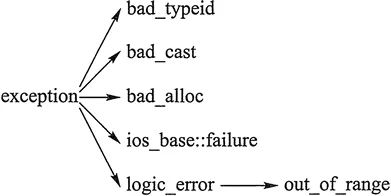
bad_typeid:使用typeid運算符,如果其操作數是一個多態類的指針,而該指針的值為 NULL,則會拋出此異常,例如:
#include 《iostream》 #include 《typeinfo》 using namespace std; class A{ public: virtual ~A(); }; using namespace std; int main() { A* a = NULL; try { cout 《《 typeid(*a).name() 《《 endl; // Error condition } catch (bad_typeid){ cout 《《 “Object is NULL” 《《 endl; } return 0; } //運行結果:bject is NULL
bad_cast:在用 dynamic_cast 進行從多態基類對象(或引用)到派生類的引用的強制類型轉換時,如果轉換是不安全的,則會拋出此異常
bad_alloc:在用 new 運算符進行動態內存分配時,如果沒有足夠的內存,則會引發此異常
out_of_range:用 vector 或 string的at 成員函數根據下標訪問元素時,如果下標越界,則會拋出此異常
原文標題:《逆襲進大廠》之 C++ 篇 49 問 49 答(絕對的干貨)
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
程序
+關注
關注
117文章
3824瀏覽量
82456 -
C++
+關注
關注
22文章
2117瀏覽量
74796
原文標題:《逆襲進大廠》之 C++ 篇 49 問 49 答(絕對的干貨)
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
主流的 MCU 開發語言為什么是 C 而不是 C++?

C++學到什么程度可以找工作?
基于OpenHarmony標準系統的C++公共基礎類庫案例:ThreadPoll

Spire.XLS for C++組件說明
同樣是函數,在C和C++中有什么區別
C++新手容易犯的十個編程錯誤

ostream在c++中的用法
OpenVINO2024 C++推理使用技巧
C++中實現類似instanceof的方法






 工商網監
工商網監
評論