") 詳解對GNN的預測過程的實現(xiàn)與應(yīng)用方法
詳解對GNN的預測過程的實現(xiàn)與應(yīng)用方法

本文發(fā)表在ICLR2021,將文本轉(zhuǎn)化成圖,從圖的角度對NLP結(jié)果進行解釋。

圖數(shù)據(jù)的天然優(yōu)勢是為學習算法提供了豐富的結(jié)構(gòu)化信息,節(jié)點之間鄰接關(guān)系的設(shè)計成為了重要的先驗信息和交互約束。然而,有一部分邊上的消息是可以忽略的,論文首先提出方法在不影響模型預測效果的情況下,將圖結(jié)構(gòu)中冗余的邊drop掉。通過分析剩余邊上具有怎樣的先驗知識,實現(xiàn)對GNN的預測過程加以解釋。
0. Abstract
GNN 能夠?qū)⒔Y(jié)構(gòu)歸納偏置(structural inductive biases) 整合到 NLP 模型中。然而,卻鮮有工作對于這種結(jié)構(gòu)偏置的原理加以解釋,特別是在理解圖結(jié)構(gòu)的哪些部分有助于模型的預測方面。因此,本文介紹了一種事后(post-hoc)方法,來對 GNN 的預測加以解釋,它能夠識別出不必要的邊。給定一個訓練過的GNN模型,本文通過學習一個簡單的分類器,對于每一層中的每條邊,預測那條邊是否可以被丟棄。作者證明了這樣的分類器的訓練可以用完全可微分的方式,使用隨機門,并通過范數(shù)促進稀疏性。此外,作者還進行了非常有意義的實驗,將提出的技術(shù)作為歸因方法,同時分析了兩個 NLP 任務(wù)中的GNN模型——問題回答和語義角色標注,并提供了對這些模型中信息流的理解。實驗結(jié)果表明,可以丟棄大量的邊卻不會影響到模型的性能,同時通過分析剩余的重要邊來解釋模型的預測過程。
1. Introduction基于GNN的NLP任務(wù)
1.應(yīng)用現(xiàn)狀
近年來,圖神經(jīng)網(wǎng)絡(luò)(GNNs)成為了一種可擴展和高性能的方法,能夠?qū)⒄Z言信息和其他結(jié)構(gòu)偏置整合到NLP模型中。GNN 能夠用于文本數(shù)據(jù)的表示,例如:語法和語義圖、共指結(jié)構(gòu)、知識庫與文本鏈接等。也能夠用在多種NLP任務(wù)中,例如:關(guān)系抽取,問題回答,語義語法解析,文本摘要,機器翻譯,社交網(wǎng)絡(luò)中的濫用語言檢測等。
2.應(yīng)用瓶頸——在NLP任務(wù)中的可解釋性
雖然 GNN 性能較好,但模型還是相對復雜的,很難理解模型預測背后的“原因”。對于NLP從業(yè)者來說,知道給定的模型編碼了哪些語言信息以及編碼是如何發(fā)生的是非常重要的,GNN 可解釋性差是實現(xiàn)這種分析的障礙。此外,這種不透明性降低了用戶的信任,阻礙了有害偏置的發(fā)現(xiàn),并使錯誤分析復雜化;在這篇論文中,著重于對 GNN 的事后分析,并對解釋GNN的方法制定了以下要求:
能夠識別層之間的相關(guān)路徑,因為路徑是向用戶展示 GNN 推理模式的最自然的方式之一;
易于處理,適用于現(xiàn)代基于 GNN 的 NLP 模型;
盡可能的提升可信度,為模型如何真正的達到預測效果提供解釋。
前置知識:擦除搜索(erasure search)
1.定義
執(zhí)行解釋的一個簡單方法是使用擦除搜索[1],這是一種歸因的方法,在不影響模型預測的情況下,查找到可以被完全刪除的最大特征子集。刪除意味著模型丟棄的所有特征信息都能夠被忽略。
2.擦除搜索應(yīng)用于GNN
對于GNN 而言,擦除搜索需要找到可以完全丟棄的最大子圖。對于上面提到的三點需求,擦除搜索只能滿足(1)和(3),在易處理性上失敗了。在實際場景中是不可行的,一次只刪除一個特征的花銷非常大,并且由于飽和性會低估特征的貢獻;此外,在擦除搜索中,優(yōu)化是針對每個例子單獨進行的。由于使用另一個可選擇的較小子圖也可以做出類似的預測,即使是非冗余的邊也會被積極地修剪,這可能會導致過擬合,作者將這個問題稱為事后偏差(hindsight bias)。
GRAPHMASK 方法
論文提出的 GRAPHMASK 旨在通過可擴展的方式實現(xiàn)與擦除搜索相同的優(yōu)點,從而滿足上述的需求。也就是說,作者的方法對保留或丟棄邊做出了可解釋的硬性選擇,從而使被丟棄的邊與模型預測沒有相關(guān)性,同時保持了易處理性。GRAPHMASK 可以理解為子集擦除的一種可微的形式。其中,作者不是為每個給定的例子找到一個需要擦除的最佳子集,而是學習一個參數(shù)化的擦除函數(shù),該函數(shù)可以預測是否應(yīng)該保留第層的每條邊 。給定一個示例圖 ,作者的方法為第 層返回一個子圖 ,這樣就可以認為 之外的任何邊都不會影響模型的預測。由于作者的模型依賴于參數(shù)化的擦除函數(shù),而不是對每條邊單獨進行選擇,作者可以通過在訓練數(shù)據(jù)集上攤開參數(shù)學習,這種策略避免了事后偏差。
論文的貢獻
作者提出了一種新的針對GNN可解釋性的方法,適用于任何以GNN為組件的端到端神經(jīng)模型(作者將發(fā)布代碼)。
作者用人工數(shù)據(jù)證明了現(xiàn)有最新方法的缺點,并展示了論文的方法如何解決這些缺點并提高可信度。
作者使用GRAPHMASK來分析兩個NLP任務(wù)中的GNN模型:語義角色標注和多跳問題回答。
2. MethodsGNN
給定輸入圖 ,GNN 第層的工作機制能夠通過一個消息函數(shù) 和一個聚合函數(shù) 定義:
其中, 表示節(jié)點 和 之間的關(guān)系類型, 是節(jié)點 的鄰居集合, 是第 層節(jié)點的表示。
GRAPHMASK
目標:獲得原始圖數(shù)據(jù)中的冗余信息,檢測在不影響模型預測的情況下,第 層的哪些邊上的消息 可以被忽略,作者將這些邊和邊上的消息視為冗余的。
整體思路(如下圖):節(jié)點的隱藏狀態(tài)和消息被喂入一個分類器 ,預測得到一個掩碼 ,作者用 來代替第 層的消息,并使用修改后的節(jié)點狀態(tài)重新計算前向傳播。分類器 在不改變模型預測的情況下,盡可能多的遮蔽隱藏狀態(tài)。
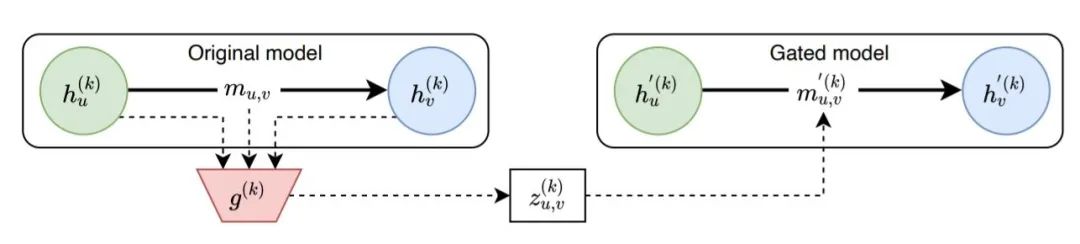
模型框架
Original Model 當節(jié)點 和 之間有邊連接時,那么消息 能夠自由的傳遞給節(jié)點 ;
Gated Model 訓練一個分類器 控制原始消息 是否要被遮蔽,若原始消息被遮蔽,則計算一個新的消息 ,再傳遞給節(jié)點 。
Gated Model 中消息的計算
作者通過一個二元選擇模型 查找需要丟棄的邊, 并通過一個可學習的基線 替換被丟棄的消息:
即,當 時,原始消息被遮蔽掉,使用學習到的參數(shù) 作為新的消息。
二元選擇模型的局限
不滿足作者在 Introduction 中提出的要求:1)該過程涉及到對所有可能被丟棄的候選邊進行搜索,所以不是易處理的。2)搜索過程是對每一個例子單獨進行的,存在事后偏見的危險。
為了克服這些問題,作者通過一個簡單的函數(shù)來計算 ,對每個任務(wù)跨數(shù)據(jù)點學習一次:
其中 是分類器 的參數(shù),以單層神經(jīng)網(wǎng)絡(luò)的形式實現(xiàn)。
分類器 的優(yōu)勢
不是根據(jù)給定的預測值來選擇門值 ,而是在多個數(shù)據(jù)點上訓練參數(shù) ,并用于解釋在訓練階段未見的例子上的預測。
的計算僅依靠模型在當前階段的可用信息(即 , , ),而不是讓模型提供一個lookahead.
這兩個方面的設(shè)計,防止了事后偏差。作者把這種策略稱為 amortization。另一種選擇是為每個門獨立的選擇參數(shù),不在門間共享任何參數(shù),直接在測試樣本上執(zhí)行優(yōu)化,作者將這種策略稱為 GraphMask 的 non-amortized 版本。將在后面看到,與 amortization 版本不同的是,它容易受到事后偏見的影響。
計算過程
當獲得訓練好的分類器 后,使用論文提出的 GRAPHMASK 方法分析一個數(shù)據(jù)點過程如下:
1)在該數(shù)據(jù)點上執(zhí)行原始模型,得到 , , 。
2)對每一層的每一條邊進行門計算,并執(zhí)行如圖1所示模型的稀疏化版本。根據(jù)公式3對原始模型的消息進行門控。
3)對于后續(xù)各層,使用公式2對被遮蔽后的消息進行聚合,以獲得頂點嵌入 ,然后用它來獲得下一組被掩蔽的消息。
GRAPHMASK 唯一學習的參數(shù)是擦除函數(shù)的參數(shù) 和學習到的基線向量 ,原 GNN 模型的參數(shù)保持不變。只要依靠稀疏化圖的預測與使用原始圖的預測相同,我們就可以將被掩蓋的信息解釋為冗余的信息。
模型參數(shù)估計
問題定義
給定:具有 層的 GNN 函數(shù) , 圖 , 輸入嵌入
任務(wù):找到一個信息量大的子圖集合 , ,也就是每一層GNN網(wǎng)絡(luò)對應(yīng)一個子圖,找到邊數(shù)目最少的子圖,并使得:。
約束優(yōu)化過程
用約束優(yōu)化的語言來形式化上述問題,并采用一種能夠?qū)崿F(xiàn)梯度下降的方法,如拉格朗日松弛。一般來說,不可能保證)和 相等,因為是一個平穩(wěn)函數(shù),輸入數(shù)據(jù)的最小變化也無法產(chǎn)生完全相同的輸出。
為了衡量兩個輸出的不一致程度,作者引入了一個散度:,和一個容忍度:, 在該范圍內(nèi)的差異是可接受的。 的選擇取決于原始模型的輸出結(jié)構(gòu)。最小化分類器 預測的非零值數(shù)目(即未被遮蔽的邊的總數(shù)),比較常見的方法是最小化 范數(shù)。因此,從形式上講,在數(shù)據(jù)集 上定義本文的目標函數(shù)為:
其中1是指示函數(shù), 是拉格朗日乘子。
以上目標函數(shù)不可微,由于:1) 不連續(xù),導數(shù)幾乎處處為0;2)輸出的二值需要一個不連續(xù)的激活,如階躍函數(shù)。因此沒辦法使用基于梯度的優(yōu)化方法,作者采用稀疏松弛解決以上問題,并采用 Hard Concrete 分布(封閉區(qū)間[0,1]上的混合離散連續(xù)分布)。
4. Experiments作者進行了三個系列的實驗,本文將呈現(xiàn)重要的表格和結(jié)果,具體實驗細節(jié)和分析參閱論文。
綜合實驗
作者首先將GRAPHMASK應(yīng)用在一個已知真實屬性的 Toy 數(shù)據(jù)集中,對方法的忠誠度進行評估。
任務(wù)描述 給定一個星形圖 ,有一個單獨的中心頂點,葉節(jié)點,以及邊,圖中每條邊都事先分配好了一種顏色 。然后,給定一個查詢 ,
需要預測的是 分配給顏色 的邊數(shù)是否大于分配給顏色 的邊數(shù)。我們事先明確已知與 兩種顏色相匹配的邊是重要的,除此之外的其它邊都不影響預測。作者定義了一個忠實度的黃金標準:對于,所有 和 類型的邊都應(yīng)該被保留, 而所有其他的邊都應(yīng)該被丟棄。
GRAPHMASK與三個基線方法比較
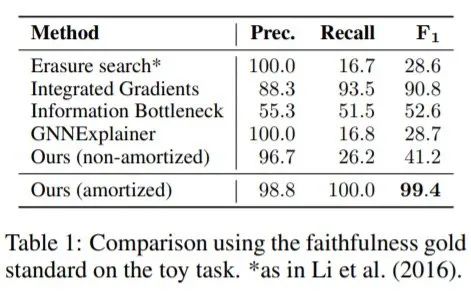
只有本文提出的方法的 amortized 版本近似復制了黃金標準,事實上,擦除搜索、GNNExplainer 和 non-amortized 的GRAPHMASK只召回了一小部分非冗余邊。
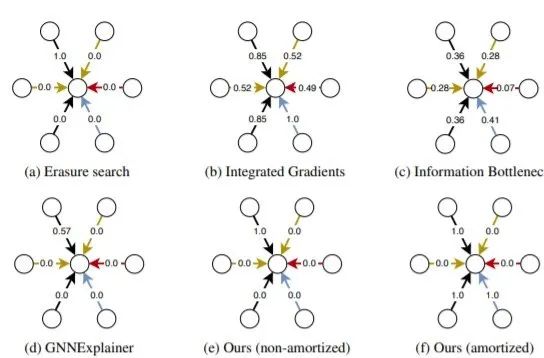
圖2 可視化每種方法的分數(shù)分配情況
擦除搜索、GNNExplainer 和 non-amortized 版本 GRAPHMASK 只保留一條黑色邊,造成過擬合。集成梯度和信息瓶頸方法給出了不滿意的結(jié)果,因為所有邊邊都有屬性。只有amortized -GRAPHMASK能夠正確地將屬性分配給且僅分配給黑色和藍色邊,amortized 可以防止目標過擬合。
問題回答任務(wù)
任務(wù)描述 給定一個查詢句和一組上下文文檔,在上下文中找到最能回答查詢的實體。GNN圖中的節(jié)點對應(yīng)于查詢和上下文中實體的提及,并在這些實體之間引入了四種類型的邊:字符串匹配(MATCH)、文檔級共現(xiàn)(DOC-BASED)、核心參考解析(COREF),沒有任何其他邊(COMPLEMENT)。
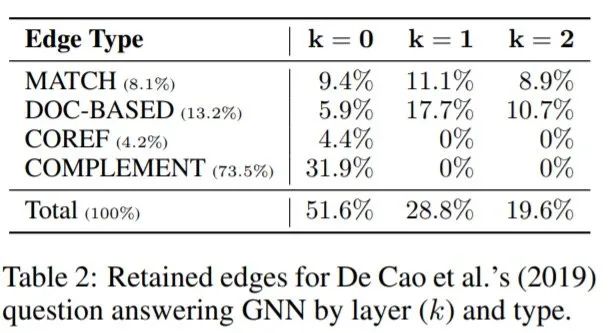
GRAPHMASK復制了原始模型的性能,雖然準確度下降0.4%,但是僅有27%的邊被保留,保留的邊大部分存在于底層(底層的邊比較重要)。作者測量了每一層保留邊的百分比,這些邊發(fā)生在源于查詢實體的路徑上。觀察發(fā)現(xiàn),發(fā)生在源于查詢的提及的路徑上的邊的比例按層急劇增加,從0層的11.8%,到1層的42.7%,在頂層達到73.8%。與預測答案相對應(yīng)的一些提及在99.7%的情況下是一些保留邊的目標。然而,預測實體與查詢連接的幾率(72.1%)與平均候選實體的幾率(69.2%)幾乎相同。因此,GNN不僅負責通過圖傳播證據(jù)到預測答案,還負責傳播證據(jù)到備選候選實體。大多數(shù)路徑采取兩種形式之一,即一條COMPLEMENT邊之后是一條MATCH或一條DOC-BASED邊(22%),或者一條COMPLEMENT邊之后是兩條MATCH或DOC-BASED邊(52%)。
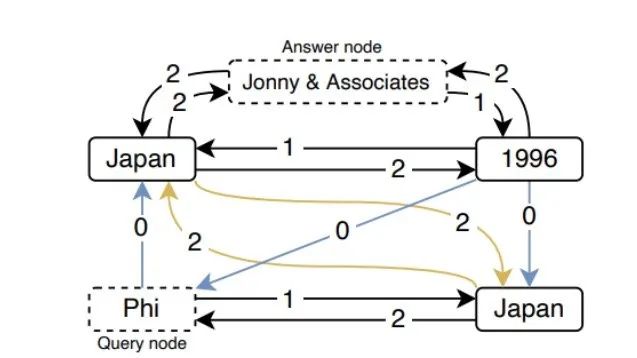
圖3 QA任務(wù)中邊的保留情況
查詢 “record label Phi” 的保留子圖(占原始邊的21%)。黑色邊類型是DOC-BASED,藍色是COMPLEMENT,黃色是MATCH,其中邊上的數(shù)字表示在哪一層保留了這種邊。可以看到 Japan 和 Johnny & Associates 之間第2層中的 DOC-BASED 類型邊的情況。事實上,在第0層、第1層和第2層中,分別有49%、98%和79%的保留邊也保留了它們的逆向邊。換句話說,提及之間 “不定向 ”的信息交換,使得它的表征更加豐富。
語義角色標注任務(wù)

圖4 GNN+LSTM模型的語義角色標注的實例分析(丟棄冗余弧)
任務(wù)描述 基于GNN的語義角色標注系統(tǒng),識別給定謂詞的論元,并將它們分配到語義角色上,見圖4中句子下面的標簽。該 GNN 模型依賴于自動預測的句法依賴樹,允許信息雙向流動。作者針對[2]中性能最好的模型,包括BiLSTM+GNN,以及GNN-only 模型。對于LSTM+GNN,遮蔽模型的性能變化非常小,F(xiàn)1 僅下降0.62%,卻只保留了其中4%的消息。GNN-only 模型的性能變化同樣很小,F(xiàn)1 下降了 0.79%,保留了16%的消息。
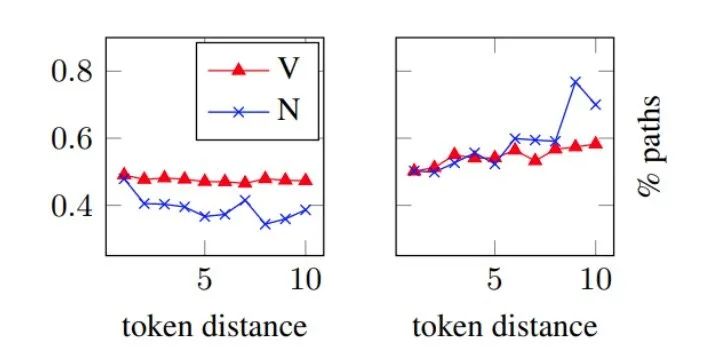
LSTM+GNN 模型(左)和 GNN-only 模型(右)的預測中使用的路徑百分比(縱坐標),橫坐標是謂詞和預測角色之間距離。
[2] 的原始研究結(jié)果表明,GNN對于預測遠離謂詞的角色特別有用,LSTM對于傳播信息的可靠性較低。GNN可以實現(xiàn)這一目標的方式是使用圖中的路徑;要么依賴整個路徑,要么部分依賴路徑中的最后幾條邊。其中連接謂詞和論元的路徑代表語義角色標注任務(wù)的重要特征。為了研究這個問題,作者在圖5中繪制了從謂詞到預測論元的路徑的百分比,從而保留了以預測論元為終點的子路徑(即至少一條邊),通過觀察圖5發(fā)現(xiàn):
LSTM+GNN 模型:隨著與謂詞距離的增加,對路徑的依賴性會降低。
GNN-only 模型:隨著與謂詞距離的增加,對路徑的依賴性會增加。
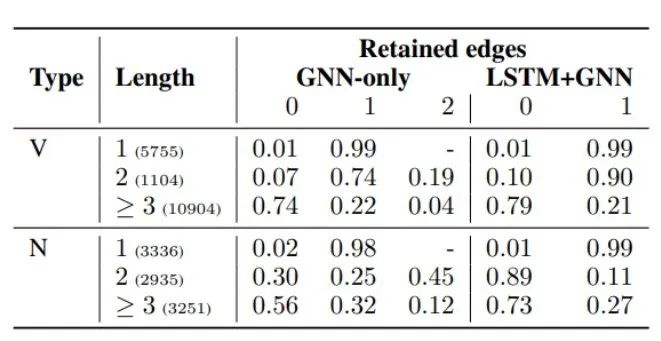
表3 兩種模型保留0、1或2條邊的路徑百分比,按路徑長度和謂詞類型劃分
通過觀察表3發(fā)現(xiàn):
幾乎所有的謂詞和角色之間的直接連接都被保留了下來,因為這些邊構(gòu)成了它們句法關(guān)系的最直接的指示。
較長的路徑在兩種模型中都是非常有用的--然而,在LSTM+GNN模型中,名詞謂詞對長路徑的使用率要低得多。
在這種特殊情況下,LSTM捕捉到了路徑上存在的信息,在其他情況下,GNN通過對連接謂詞和論元的路徑進行建模來補充LSTM。
5. Conclusion論文介紹了GRAPHMASK,這是一種適用于任何GNN模型的事后解釋方法。通過學習每條消息的端到端可微分的hard gates,并在訓練數(shù)據(jù)上進行攤銷,GRAPHMASK 可擴展到其它的GNN模型,并且能夠識別邊和路徑如何影響預測。作者應(yīng)用提出的方法分析了兩個NLP模型的預測——語義角色標簽?zāi)P秃蛦栴}回答模型。GRAPHMASK發(fā)現(xiàn)了這些模型依賴于哪些類型的邊,以及它們在進行預測時如何運用路徑。
參考文獻[1] Jiwei Li, Will Monroe, and Dan Jurafsky. Understanding neural networks through representation erasure. arXiv preprint arXiv:1612.08220, 2016.
[2] Michael Roth and Mirella Lapata. Neural semantic role labeling with dependency path embeddings. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1192–1202, Berlin, Germany, August 2016. Association for Computational Linguistics. doi: 10.18653/v1/P16-1113. URL https://www.aclweb. org/anthology/P16-1113.
編輯:lyn
-
人工智能
+關(guān)注
關(guān)注
1806文章
48987瀏覽量
249122 -
模型參數(shù)
+關(guān)注
關(guān)注
0文章
4瀏覽量
6467 -
深度學習
+關(guān)注
關(guān)注
73文章
5560瀏覽量
122765 -
GNN
+關(guān)注
關(guān)注
1文章
31瀏覽量
6552
原文標題:【GNN】別用Attention了,用GNN來解釋NLP模型吧
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄

中小企業(yè)預測性維護三大策略

SVPWM的原理及法則推導和控制算法詳解
設(shè)備管理系統(tǒng):如何實現(xiàn)預測性維護與故障預防?
詳解溫度傳感器校準方法
運動控制中如何實現(xiàn)路徑軌跡預測

放電消納負載如何實現(xiàn)的
一種創(chuàng)新的動態(tài)軌跡預測方法
電流探頭在輻射預測試的原理分析

簡述拉曼散射效應(yīng)的實現(xiàn)過程
PLC對模擬量信號的處理過程及方法 詳解版





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論