 知識圖譜與訓練模型相結合和命名實體識別的研究工作
知識圖譜與訓練模型相結合和命名實體識別的研究工作

本次將分享ICLR2021中的三篇投遞文章,涉及知識圖譜與訓練模型相結合和命名實體識別(NER)的研究工作。
文章概覽
知識圖譜和語言理解的聯合預訓練(JAKET: Joint Pre-training of Knowledge Graph and Language Understanding)。該論文提出了知識圖譜和文本的聯合訓練框架,通過將RoBERTa作為語言模型將上下文編碼信息傳遞給知識圖譜,同時借助圖注意力模型將知識圖譜的結構化信息反饋給語言模型,從而實現知識圖譜模型和語言模型的循環交替訓練,使得在知識圖譜指導下的預訓練模型能夠快速適應新領域知識。
語言模型是開放知識圖譜(Language Models are Open Knowledge Graphs)。該論文提出了能夠自動化構建知識圖譜的Match and Map(MAMA)模型,借助預先訓練好的語言模型中的注意力權重來提取語料中的實體間關系,并基于已有的schema框架自動化構建開放性知識圖譜。
命名實體識別中未標記實體問題的研究(Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition)。論文探究了未標注實體問題對NER實驗指標的影響,并提出了一種負采樣策略,通過改進損失函數,將為標注實體當作負樣本訓練,從而極大改善了未標注實體問題對NER實驗指標的影響。
論文細節
1
論文動機
現有的將知識圖譜與預訓練模型相結合的研究工作還存在挑戰:當預先訓練好的模型與新領域中的知識圖譜結合微調時,語言模型難以高效學習到結構化的實體關系語義信息。同時知識圖譜的理解推理能力也需要上下文的輔助。基于此,論文提出了一個聯合預訓練框架:JAKET,通過同時對知識圖譜和語言建模,實現兩個模型之間的信息互補和交替訓練。方法1. 知識模塊(Knowledge Module,KM)知識模塊主要是對知識圖譜進行建模,生成含有結構化信息的實體表示。采用圖注意力模型和組合算子思想來聚合實體嵌入和關系嵌入信息。在第L層的實體V的嵌入信息傳播公式為:
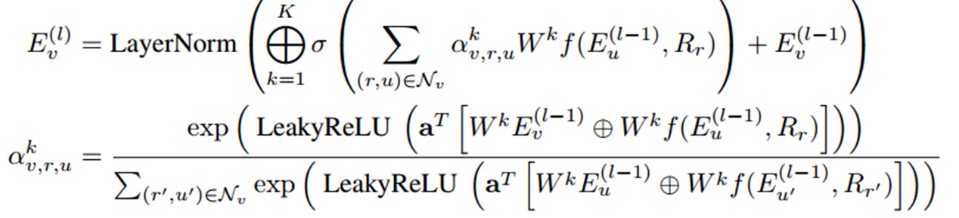
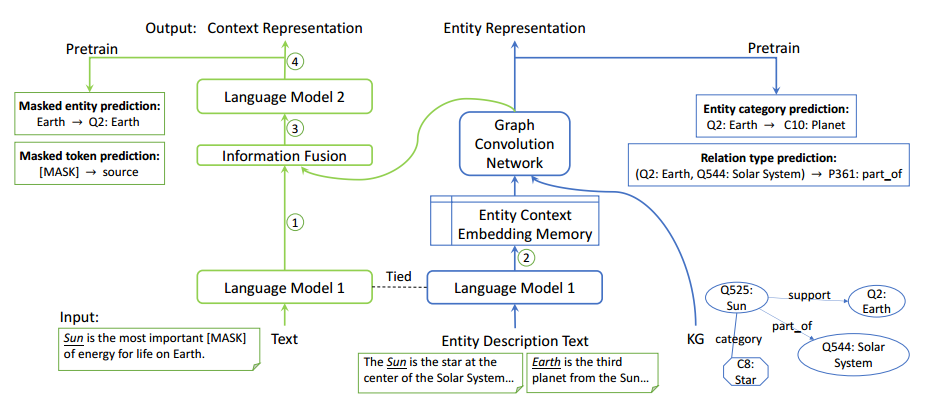
考慮到計算過程中可能會出現的實體數爆炸問題,實驗采用了設置minibatch領域采樣的方法獲取多跳鄰居集合。2. 語言模塊(Language Module,LM)語言模塊主要是對文本建模,學習文本的嵌入表示。采用RoBERT-base作為預訓練模型。3.解決循環依賴問題(Solve the syclic dependency)由于LM和KM是互相傳遞信息的,訓練過程存在循環依賴問題,不便于后續計算優化。論文提出了分解語言模型解決此問題,即將LM分解為LM1和LM2子模塊,將RoBERT的前6層和后6層分別作為LM1和LM2,實現LM1,KM和LM2的聯合訓練。整體框架如下圖所示。
實驗結果論文在實體類別預測、關系類別預測、詞塊掩碼預測、實體掩碼預測4個任務上進行預訓練,并在小樣本關系分類、KGQA和實體分類這3個下游任務上進行實驗。實驗結果分別如下圖所示:
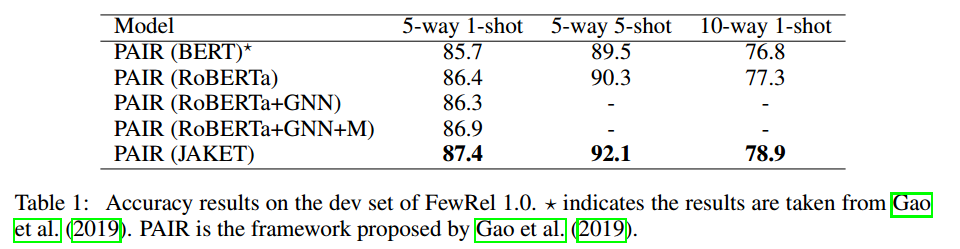
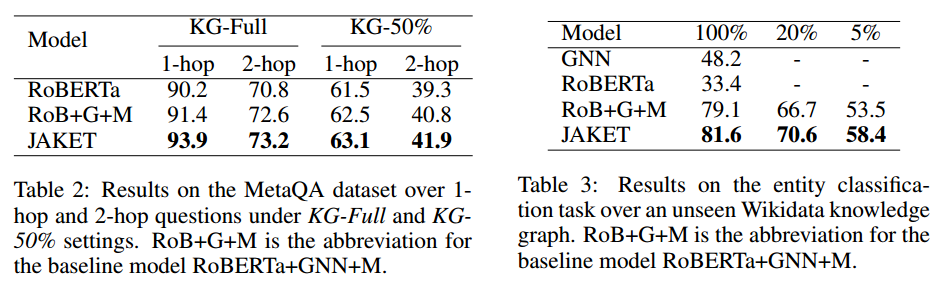
由實驗結果可知,在3個任務中論文提出的JAKET都可以進一步提高性能,并且聯合預訓練可以有效減少模型對下游訓練數據的依賴。
2

論文動機
知識圖譜的構建方法通常需要人工輔助參與,但是人力成本太高;
同時BERT等預訓練模型通常在非常大規模的語料上訓練,訓練好的模型本身包含常識知識,這些知識可以促進上層的其他應用。
所以本論文提出了一種無監督的Match and Map(MAMA)模型,來將預訓練語言模型中包含的知識轉換為知識圖譜。
方法
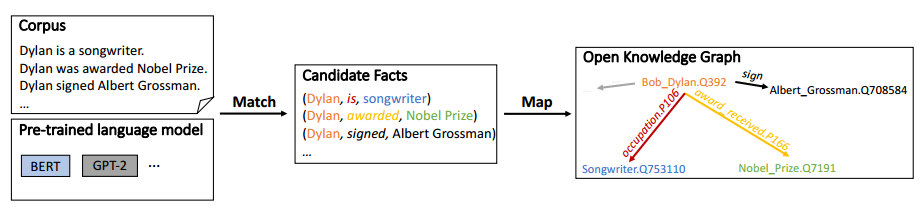
1. 匹配(Match)

Match階段主要是自動抽取三元組。對于輸入的文本,使用開源工具抽取出實體,并將實體兩兩配對為頭實體和尾實體,利用預訓練模型的注意力權重來提取實體對的關系。通過beam search的方法搜索多條從頭實體到尾實體的路徑,從而獲取多個候選的三元組。再通過設置一些限制規則過濾掉不符常理的三元組,即得到用于構建知識圖譜的三元組。
2. 映射(Map)
Map階段主要是將Match階段抽取到的三元組映射到知識圖譜中去。利用成熟的實體鏈接和關系映射技術,將三元組映射到已有的固定schema圖譜中。對于部分映射或完全不匹配的三元組,就構建開放schema的知識圖譜,并最后將這兩類知識圖譜融合,得到一個靈活的開放性知識圖譜。
整體框架如下:
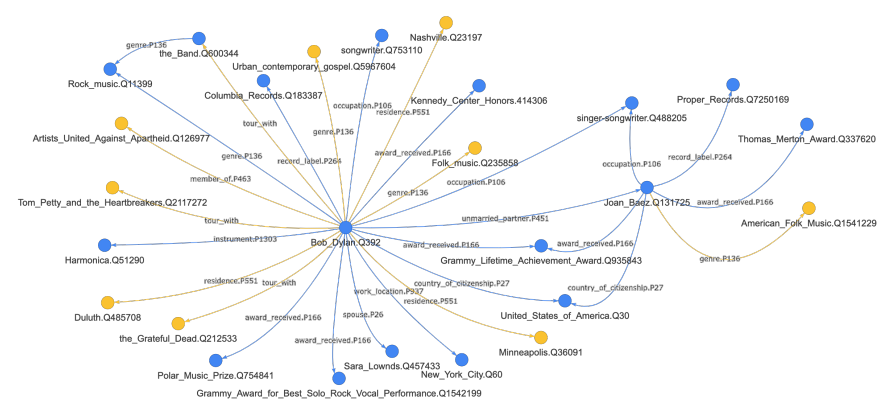
論文中使用BERT-large對Wikipedia語料進行自動化構建知識圖譜,圖譜效果如下:
實驗結果
論文在TAC KBP和Wikidata數據集上進行槽填充任務實驗。
在TAC KBP數據集上的結果如下表:
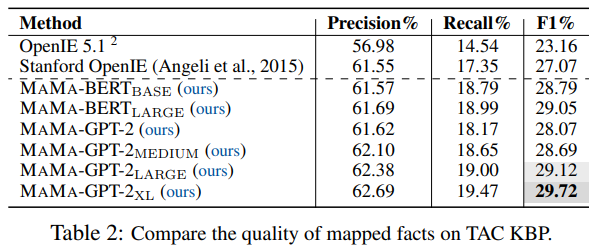
基于TAC KBP數據集的實驗結果主要有兩點:一是MAMA模型能夠提升知識圖譜的槽填充效果;二是更大/更深的語言模型能夠抽取出更高質量的知識圖譜。
在Wikidata數據集上的結果如下表:
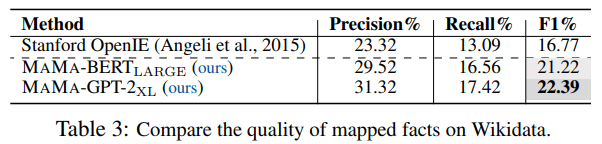
基于Wikidata數據集的實驗結論一方面說明MAMA可擴展到更大的語料庫,另一方面說明MAMA能從更大規模的語料庫中抽取出更完整的知識圖譜。
3

論文動機
實體未標注問題是命名實體識別(NER)任務中的常見問題,且該問題在實際情況中無法完全避免。既然無法徹底解決實體未標注問題,那么該問題是否會對NER模型產生影響呢?若產生較大影響,如何將這種消極影響盡量降低?
基于上述問題,論文分析了未標注實體問題對NER實驗指標的影響及其原因,并提出了一種具有魯棒性的負采樣策略,使得模型能夠保持在未標注實體概率極低的狀態下訓練,從而提升實體標注效果。
方法
1.合成數據集(Synthetic Datasets)
通過在標注完善的CoNLL-2003和OntoNotes5.0數據集按照一定概率隨機掩蓋標注出的實體,獲取人工合成的欠完善標注數據集。
2.衡量指標(Metrics)
文章中設計了侵蝕率(erosion rate)和誤導率(misguidance rate)2種指標來測算NER中未標注實體問題的影響。
侵蝕率代表實體標注量減少對NER指標下降的影響程度。
誤導率代表未標注實體對當作負樣本時對NER指標下降的影響程度。
3.負采樣(Negative Sampling)
文章采用負采樣的方式進行降噪,對所有的非實體進行負采樣,采樣負樣本進行損失函數的計算。改進后的損失函數如下所示:
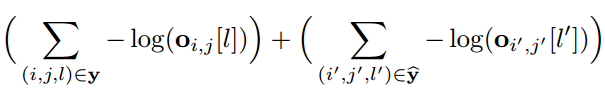
其中前半部分表示標注實體集合的損失,后半部分則是負采樣實體集合的損失。文章的整體模型框架如下圖所示,總體就是BERT/LSTM編碼+softmax的思路。
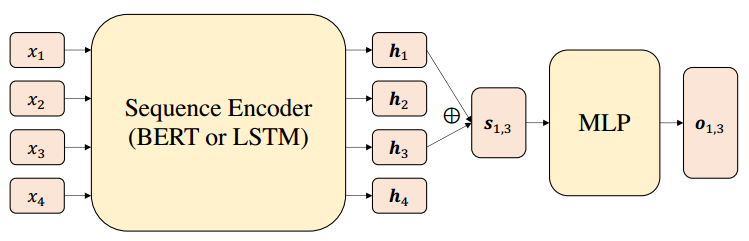
實驗結果
文章在合成數據集上進行NER任務實驗,分析未標注問題的影響和負采樣的訓練效果。
首先是分別基于CoNLL-2003和OntoNotes5.0合成數據集進行的實驗結果:
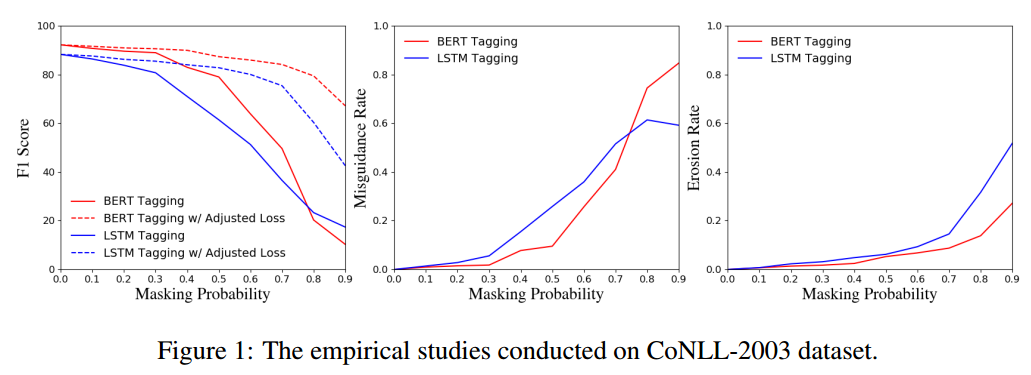
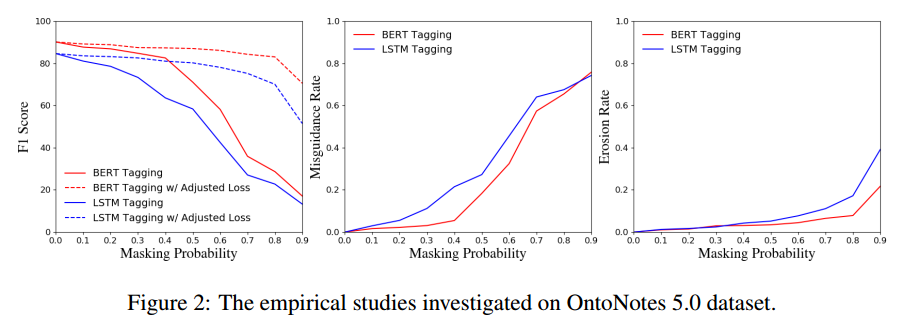
由圖可知:隨著實體掩蓋概率p增大,即未標注實體數量增多,NER指標下降明顯;在p很低的時候,誤導率就較高了,而侵蝕率受影響較小,說明把未標注實體當作負樣本訓練、對NER指標下降的影響程度很大,實體標注量減少對指標下降的影響較小
其次將文章提出的負采樣訓練模型與其他SOTA模型分別在完全標注數據集和真實數據集上做對比,實驗結果如下:
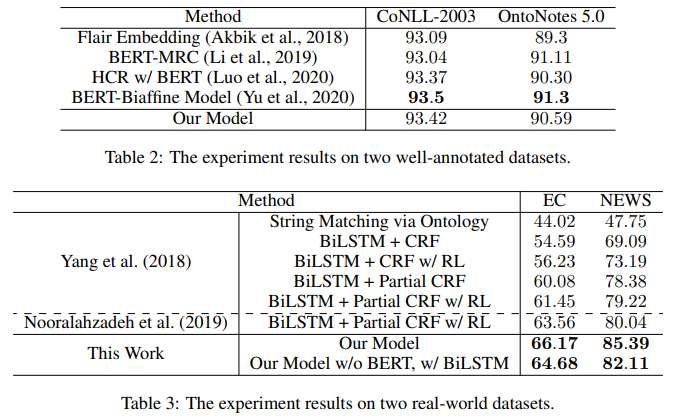
結果表明本模型在完全標注數據集上的效果和其他模型相差不大,并且真實世界數據集上的效果遠優于其他的模型,所以本文模型的綜合效果最好。
總結
此次解讀的三篇論文圍繞知識建模和信息抽取的研究點展開。感覺知識圖譜結合語言模型的相關研究的趨勢是嘗試使用同一套編碼系統,同時對語言模型中的上下文信息和知識圖譜中的結構化語義信息進行編碼和訓練,從而實現知識融合或知識挖掘。此外,第三篇文章主要想給廣大做知識圖譜方向的研究者分享一個命名實體識別的技巧思路,當面對標注質量不那么高的數據集時,或許可以嘗試一下負采樣的方法。
以上就是Fudan DISC本期的論文分享內容,歡迎大家的批評和交流。
原文標題:【論文解讀】ICLR2021 知識建模與信息抽取
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
模型
+關注
關注
1文章
3531瀏覽量
50564 -
深度學習
+關注
關注
73文章
5564瀏覽量
122923
原文標題:【論文解讀】ICLR2021 知識建模與信息抽取
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
訓練完模型后用cls_video.py在canmvIDE上運行,按著步驟操作但是攝像頭沒有識別到是什么情況?
請問如何能讓模型的效果更好?
小白學大模型:訓練大語言模型的深度指南

GPU是如何訓練AI大模型的
名單公布!【書籍評測活動NO.52】基于大模型的RAG應用開發與優化

ASR與傳統語音識別的區別
從零開始訓練一個大語言模型需要投資多少錢?






 工商網監
工商網監
評論