") 情感分析常用的知識(shí)有哪些呢?
情感分析常用的知識(shí)有哪些呢?
1.引文
情感分析 知識(shí)
當(dāng)training數(shù)據(jù)不足以覆蓋inference階段遇到的特征時(shí),是標(biāo)注更多的數(shù)據(jù)還是利用現(xiàn)有外部知識(shí)充當(dāng)監(jiān)督信號?
基于機(jī)器學(xué)習(xí)、深度學(xué)習(xí)的情感分析方法,經(jīng)常會(huì)遇到有標(biāo)注數(shù)據(jù)不足,在實(shí)際應(yīng)用過程中泛化能力差的局面。為了彌補(bǔ)這一缺點(diǎn),學(xué)者們嘗試引入外部情感知識(shí)為模型提供監(jiān)督信號,提高模型分析性能。本文從常見的外部情感知識(shí)類型出發(fā),簡要介紹在情感分析中使用知識(shí)的一些代表性工作。
2.正文
我們?yōu)槭裁匆粩鄧L試在情感分析中融入知識(shí)呢?筆者以為有如下幾點(diǎn)原因:
1)一般的文本分類任務(wù)只提供句子或文檔級別的情感標(biāo)簽,引入情感詞典等先驗(yàn)情感知識(shí)可以給情感文本引入更細(xì)粒度監(jiān)督信號,使得模型能學(xué)到更適合情感分析任務(wù)的特征表示。
2)底層的詞性、句法等分析任務(wù)能給下游的情感分類、抽取任務(wù)提供參考信息,如評價(jià)表達(dá)通常是形容詞或形容詞短語,而評價(jià)對象通常是名詞;不同情感分析任務(wù)本身存在相互促進(jìn)作用,如評價(jià)對象和評價(jià)詞在句子中出現(xiàn)的距離通常比較近,聯(lián)合抽取能同時(shí)提高兩者的性能表現(xiàn)。
3)短文本評論通常略去了大量的背景常識(shí)知識(shí),從文本本身通常難以推斷真實(shí)情感傾向性。例如一條有關(guān)大選的推文內(nèi)容是“I am so grateful for Joe Biden. Vote for #JoeBiden!!”,文本中并未涉及任何有關(guān)Trump的描述,要判斷它關(guān)于Trump的立場傾向性時(shí),需要了解的背景知識(shí)是,二者是這次大選的競爭對手,支持一個(gè)人就意味著反對另一個(gè)人。
那情感分析常用的知識(shí)又有哪些呢?
2.1 知識(shí)的類型及情感分析常用知識(shí)庫
依據(jù)對知識(shí)獲取途徑的劃分方式[1],我們簡單總結(jié)了情感分析中常用的知識(shí)類型:
顯性知識(shí)
一般情感詞典(如MPQA,Bing Liu詞典等),情感表情符;否定詞(Negation)、強(qiáng)化詞(Intensification)、連接詞(Conjunction)等規(guī)則
SentiWordNet
ConceptNet,SenticNet
數(shù)據(jù)
數(shù)據(jù) (Twitter、微博表情符弱標(biāo)注數(shù)據(jù))
領(lǐng)域數(shù)據(jù)集 (例如某一類別商品評論數(shù)據(jù))
學(xué)習(xí)算法
詞法、句法、語義依存等模型
多任務(wù)學(xué)習(xí)算法
預(yù)訓(xùn)練語言模型、詞向量學(xué)習(xí)算法
其中,以情感詞典最為常用。情感分析數(shù)據(jù)通常結(jié)合語言模型算法,產(chǎn)生情感向量表示作為下游任務(wù)輸入;詞法、句法分析模型一般直接為下游情感分析任務(wù)提供特征輸入或者以多任務(wù)學(xué)習(xí)的方式參與到下游情感分析任務(wù)的訓(xùn)練過程中;結(jié)構(gòu)化的外部知識(shí)庫通常需要借助圖算法進(jìn)行特征挖掘,為文本提供更豐富的常識(shí)、情感上下文信息。
2.2 知識(shí)的引入方式及在情感分析部分任務(wù)上的應(yīng)用
下表展示了幾種常見的知識(shí)類型及其特點(diǎn),我們將根據(jù)知識(shí)的獲取途徑及引入方式,結(jié)合具體論文闡述其使用方式。
| 人工情感詞典 | 質(zhì)量高 | 規(guī)模小,靜態(tài),覆蓋低 |
| 自動(dòng)情感詞典 | 規(guī)模大 | 靜態(tài)、質(zhì)量低 |
| 語言學(xué)規(guī)則 | 適用范圍廣 | 不夠準(zhǔn)確 |
| 預(yù)訓(xùn)練語言模型 | 上下文建模能力強(qiáng) | 參數(shù)量大,訓(xùn)練時(shí)間長,運(yùn)行速度慢 |
| 常識(shí)知識(shí)庫 | 規(guī)模大、質(zhì)量高、覆蓋全 | 利用困難 |
| 知識(shí)類型 | 優(yōu)點(diǎn) | 缺點(diǎn) |
|---|
目前,相關(guān)的情感分析工作可以大致分為以下幾類:
引入情感詞典知識(shí)
要說情感知識(shí),大部分人首先會(huì)想到的就是人工編纂的情感詞典,它簡明直觀、質(zhì)量高、極性明確,使用方便,廣泛應(yīng)用在情感分類、情感元素抽取、情感原因發(fā)現(xiàn)、情感文本風(fēng)格遷移等多種情感分析任務(wù)上。情感詞區(qū)別于非情感詞的地方在于,它們一般表征一定的情感/情緒狀態(tài),通常情感詞典中還會(huì)給出其強(qiáng)度打分。類似的,現(xiàn)在網(wǎng)絡(luò)上流行的部分表情符 (emoj,如:) 、:( 、、)也能表征某些情感/情緒狀態(tài)。
圖1 人工編纂的情感詞典
我們在這里介紹一個(gè)同時(shí)使用情感詞典中詞的極性和打分的工作,看看前人們是如何在神經(jīng)網(wǎng)絡(luò)中把情感詞的情感信息融入文本的情感表示中的。
給定一段評論文本,Teng等人[2]首先找出其中的情感相關(guān)詞匯(如情感詞、轉(zhuǎn)折詞、否定詞),并計(jì)算其對文本整體情感極性的貢獻(xiàn)程度,然后將每個(gè)詞的貢獻(xiàn)值乘上其情感得分作為局部的情感極性值,最終加上全局的情感極性預(yù)測值作為整個(gè)文本的情感得分。
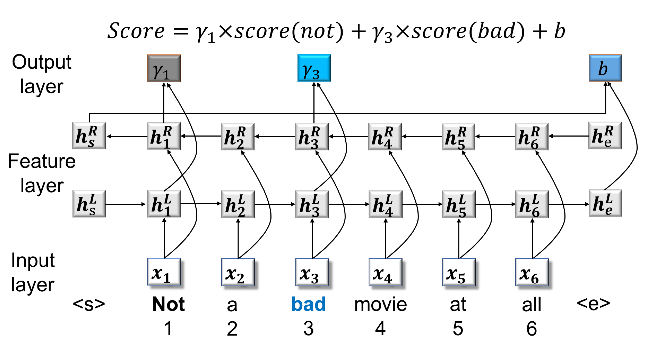
圖2 同時(shí)使用情感詞典中詞的極性和打分
雖然上述工作在計(jì)算情感得分時(shí),考慮了not、very等否定詞、強(qiáng)化詞的得分信息,但是沒有顯式把這些詞對周圍詞的情感語義表示的影響刻畫出來,Qian等人[3]考慮到情感詞、否定詞、強(qiáng)化詞在情感語義組合過程中起到的不同作用,對文本建模過程中對不同位置詞的情感分布加以約束。例如,若一個(gè)詞的上文是not等否定詞,會(huì)帶來not處文本情感語義的翻轉(zhuǎn)。
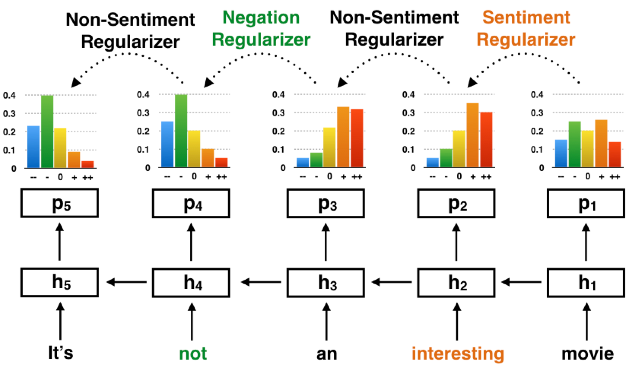
圖3 對不同位置詞的情感分布加以約束
總體來看,情感詞典作為一種易于獲取、極性準(zhǔn)確的情感知識(shí),能夠在標(biāo)注語料之外,為情感分析提供額外的監(jiān)督信號,既可以提升有監(jiān)督模型的泛化能力,也能夠?yàn)榘氡O(jiān)督、無監(jiān)督模型提供一定的指導(dǎo)。
引入大規(guī)模無標(biāo)注語料
語言建模作為一個(gè)典型的自監(jiān)督學(xué)習(xí)任務(wù),其語言模型產(chǎn)生的詞表示作為下游任務(wù)網(wǎng)絡(luò)模型的輸入,表現(xiàn)出優(yōu)越的性能,因而得到廣泛的應(yīng)用。如果能將情感知識(shí)融入到語言模型中,其產(chǎn)生的詞表示必然對情感分析各子任務(wù)帶來性能提升。
我們接著介紹一個(gè)在詞向量中融入顯式情感詞典知識(shí)(實(shí)際使用的是表情符)的方法。
Tang等人[4]觀察到,一般的詞向量對于“good”和“bad”這種上下文相近但極性相反的詞,給出的向量表示沒有很強(qiáng)的區(qū)分性,不利于下游的各情感分析任務(wù)。Twitter和微博中有海量包含表情符的文本,利用這些情感極性明確的表情符可以過濾得到大量弱標(biāo)注的情感文本。Tang等人使用這些語料,他們在普通的C&W模型基礎(chǔ)上,引入情感得分相關(guān)的損失,將這些弱標(biāo)注的情感信息融入詞向量表示中,使“good”和“bad”這種上下文相近但情感不同的詞的向量表示有明顯的差異。在情感分類任務(wù)上,他們驗(yàn)證了融入情感表情符知識(shí)的有效性。在此基礎(chǔ)上,他們還進(jìn)一步自動(dòng)構(gòu)建大規(guī)模情感詞典,該詞典被[2]應(yīng)用到Twitter情感分類任務(wù)上。
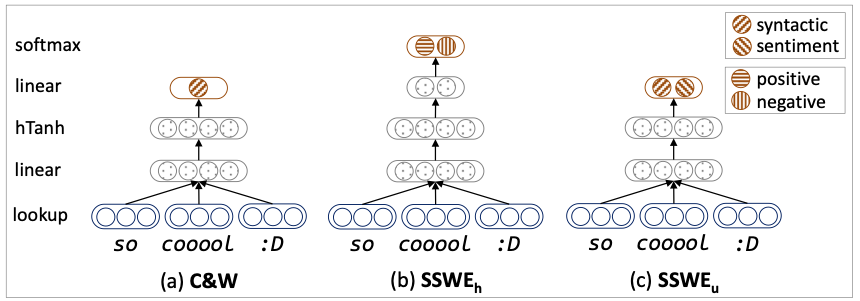
圖4 將基于表情符過濾的弱標(biāo)注情感信息融入詞向量表示中
引入外部特征提取算法
除了準(zhǔn)確的情感詞知識(shí),詞法、句法、語義依存信息、評價(jià)詞和評價(jià)表達(dá)等情感信息在文本的情感語義建模過程中也發(fā)揮了重要作用,這些知識(shí)不是顯性存在于大規(guī)模的知識(shí)圖譜中,而是存在于對應(yīng)的人工標(biāo)注數(shù)據(jù)中。一般利用學(xué)習(xí)算法從這些數(shù)據(jù)中訓(xùn)練用于提取特征的模型。
Tian等人[5]在近期的預(yù)訓(xùn)練BERT語言模型基礎(chǔ)上,將文本中的評價(jià)對象(屬性)、情感詞等情感元素引入Mask Language Model預(yù)訓(xùn)練任務(wù),進(jìn)一步提高了BERT類模型在多個(gè)情感分類數(shù)據(jù)集上的性能。
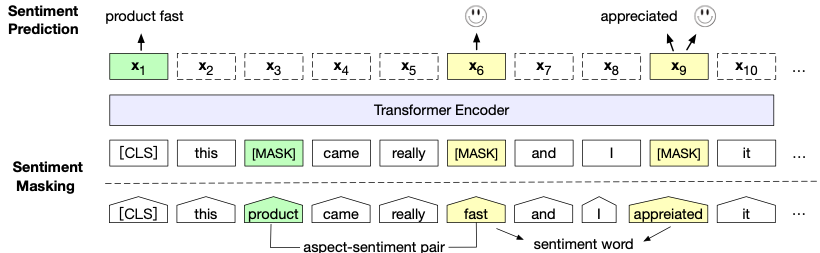
圖5 將多種情感元素引入Mask Language Model預(yù)訓(xùn)練任務(wù) 同[3]類似,Ke等人[6]在預(yù)訓(xùn)練語言模型中引入詞級別的情感、詞性知識(shí)。他們先給每個(gè)詞預(yù)測詞性信息,然后依據(jù)詞性信息從SentiWordNet中推斷其情感極性。基于獲得的詞性和情感信息,他們在一般的Masked Language Model基礎(chǔ)上同時(shí)預(yù)測這些語言學(xué)標(biāo)簽,實(shí)現(xiàn)在預(yù)訓(xùn)練語言模型中注入情感知識(shí)。該模型在主流的情感分類、細(xì)粒度情感分析數(shù)據(jù)集上取得了目前最好的結(jié)果,證明引入詞性和情感極性知識(shí)在預(yù)訓(xùn)練任務(wù)中的有效性。
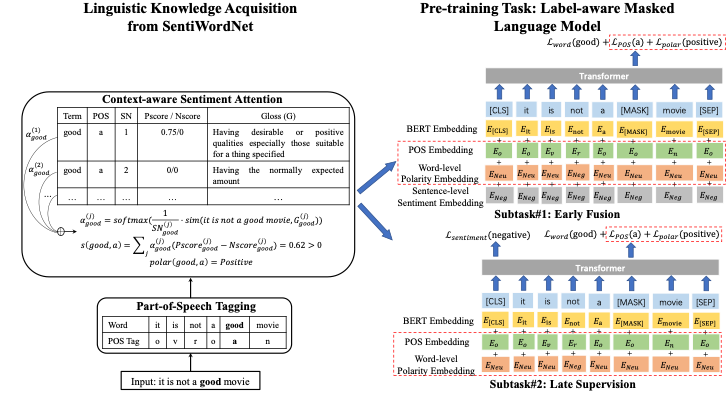
圖6在預(yù)訓(xùn)練語言模型中引入詞級別的情感、詞性知識(shí)
Sun等人[7]提出在面向?qū)傩缘那楦蟹诸悾ˋBSA)任務(wù)上,引入Stanford parser解析得到的依存樹信息輔助識(shí)別評價(jià)對象相關(guān)的評價(jià)詞。他們將GCN在依存樹上學(xué)習(xí)得到的表示與BLSTM學(xué)習(xí)到的特征結(jié)合,判斷句子針對評價(jià)對象的情感極性。
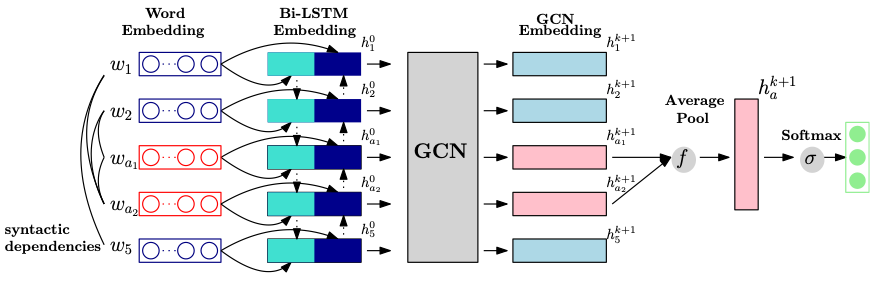
圖7將GCN在依存樹上學(xué)習(xí)得到的表示與BLSTM學(xué)習(xí)到的特征結(jié)合
在外部特征引入方式上,目前方法以兩種方法為主:(1)直接作為特征輸入模型(2)以多任務(wù)學(xué)習(xí)的方式,作為輔助任務(wù)與主任務(wù)一同訓(xùn)練。這些方法的區(qū)別主要在引入特征類別或者輔助任務(wù)的任務(wù)設(shè)計(jì)。
引入常識(shí)知識(shí)
除了情感詞典、情感詞向量、情感預(yù)訓(xùn)練語言模型、文本特征抽取器外,結(jié)構(gòu)化的外部知識(shí)也是很常見的一種情感知識(shí)來源。它的特點(diǎn)是規(guī)模大,覆蓋面廣,蘊(yùn)含豐富的實(shí)體、事件或者常識(shí)概念間相關(guān)關(guān)系知識(shí)。結(jié)構(gòu)化知識(shí)中具備高質(zhì)量的關(guān)系類型,因而適用于需要推理、泛化的情感分析任務(wù)。
一個(gè)典型的需要泛化的任務(wù)是跨領(lǐng)域文本情感分類任務(wù)。源端和目標(biāo)端的評價(jià)對象、評價(jià)詞等情感相關(guān)特征差異較大,訓(xùn)練時(shí)模型依賴的源端分類特征未必會(huì)在目標(biāo)端文本中出現(xiàn),如何將這些情感特征進(jìn)行對齊是一個(gè)重要且富有挑戰(zhàn)性的問題。一類方法是使用通用情感詞典作為pivot信息,建立源端、目標(biāo)端共享特征的對齊,但這類方法只考慮共享的情感詞信息,且通過文本本身學(xué)習(xí)到的情感表達(dá)對齊也不充分、準(zhǔn)確,同時(shí)無法捕獲到不同領(lǐng)域之間評價(jià)對象之間鏈接關(guān)系。
而結(jié)構(gòu)化外部知識(shí)正好彌補(bǔ)了這些缺點(diǎn),它蘊(yùn)含情感詞到非情感詞、不同領(lǐng)域評價(jià)對象之間的關(guān)聯(lián)關(guān)系。近年由于圖表示算法的進(jìn)步,學(xué)者們能夠更高效的對這些結(jié)構(gòu)化外部知識(shí)加以利用。
在跨領(lǐng)域情感文檔情感分類任務(wù)上,Ghosal等人[8]在ACL2020上提出KinGDOM算法, 利用ConceptNet為所有領(lǐng)域構(gòu)建一個(gè)小規(guī)模知識(shí)圖譜,然后找出每個(gè)文檔中獨(dú)有的名詞、形容詞、副詞集合,再依據(jù)從中抽取出一個(gè)文檔相關(guān)的子圖,進(jìn)而提供一個(gè)由知識(shí)庫知識(shí)提取而來的特征表示,與文檔本身的情感表示一起做最后的情感分類。
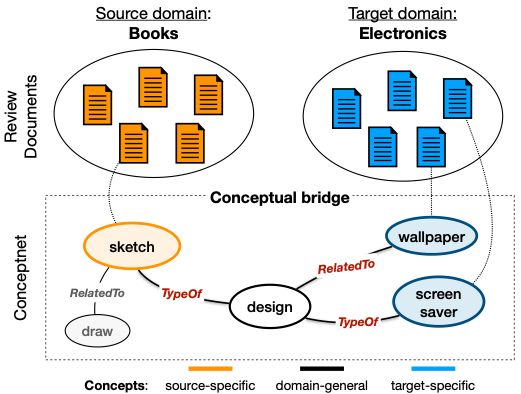
圖8KinGDOM算法
類似地,在跨目標(biāo)立場分類任務(wù)上,Zhang等人[9]利用SenticNet和EmoLex構(gòu)建學(xué)習(xí)帶情緒關(guān)系連接的語義-情緒圖譜(SE-graph),并使用圖卷積神經(jīng)網(wǎng)絡(luò)(GCN)學(xué)習(xí)節(jié)點(diǎn)表示。給定一段文本,他們使用SE-graph為每個(gè)詞學(xué)習(xí)構(gòu)建一個(gè)子圖并學(xué)習(xí)其表示,得到的外部特征表示送入修改后的BLSTM隱層,與當(dāng)前上下文特征進(jìn)行融合。
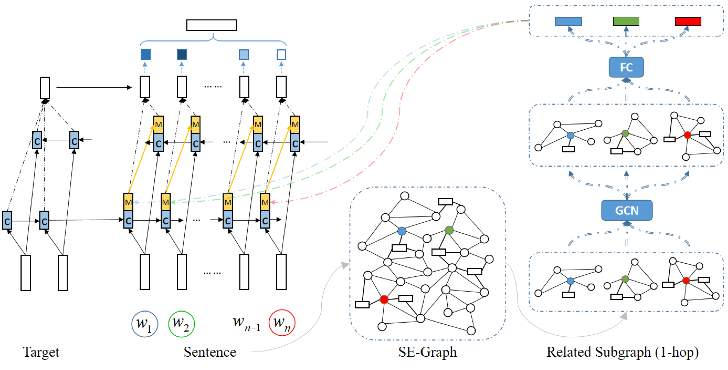
圖9基于SE-graph 使用GCN學(xué)習(xí)節(jié)點(diǎn)表示
這兩個(gè)工作都使用外部結(jié)構(gòu)知識(shí),擴(kuò)展了輸入特征空間,利用知識(shí)庫中的連接將源端和目標(biāo)端的評價(jià)詞、評價(jià)對象等特征進(jìn)行對齊,極大地豐富了情感上下文信息。
3.總結(jié)
本文介紹了情感分析中引入外部知識(shí)的部分工作,簡要介紹了現(xiàn)階段情感分析常用的外部知識(shí),從最常見的情感詞典入手,逐步介紹基于情感詞典的情感詞向量、預(yù)訓(xùn)練語言模型,展示了使用多任務(wù)學(xué)習(xí)融合詞性、依存句法等文本底層特征抽取器的工作,最后介紹了近期熱門的使用結(jié)構(gòu)化外部知識(shí)的文本情感遷移學(xué)習(xí)工作。我們可以看出,情感詞典雖然最為簡單,卻是情感知識(shí)引入多種引入方式的基石,在情感分析算法中地位無出其右。
對于未來工作,一方面,由于目前的情感分析中知識(shí)引入的應(yīng)用場景仍局限在情感分類任務(wù)中,有待擴(kuò)展到情感抽取、情感(多樣性)生成等各個(gè)情感分析任務(wù)上;另一方面,在情感分析專用預(yù)訓(xùn)練語言模型中融合結(jié)構(gòu)化外部知識(shí),增強(qiáng)預(yù)訓(xùn)練語言模型對情感分析相關(guān)世界知識(shí)的理解仍有待探索。
責(zé)任編輯:lq
-
文本分類
+關(guān)注
關(guān)注
0文章
18瀏覽量
7372 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1221瀏覽量
25195 -
情感分析
+關(guān)注
關(guān)注
0文章
14瀏覽量
5276
原文標(biāo)題:【情感分析】基于知識(shí)引入的情感分析
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于Raspberry Pi 5的情感機(jī)器人設(shè)計(jì)

Minitab常用功能介紹 如何在 Minitab 中進(jìn)行回歸分析

基于LSTM神經(jīng)網(wǎng)絡(luò)的情感分析方法
人員軌跡分析算法有哪些?
常用的仿真軟件有哪些
我常用的分析方法——輸入輸出阻抗,是怎么玩的?你會(huì)不?
smt貼片加工常用的檢測修理方法有哪些
常用的電源模塊有哪些
常用的電機(jī)控制算法有哪些
三星貼片電容規(guī)格有哪些呢?怎么選擇呢?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論