") 淺談GPU: 衡量計算效能的正確姿勢(2)
淺談GPU: 衡量計算效能的正確姿勢(2)
這次我們準(zhǔn)備聊下決定系統(tǒng)計算性能的兩大關(guān)鍵指標(biāo),1. 浮點運算能力(FLOPS), 2. 內(nèi)存帶寬(Memory Bandwidth)。
一· 為什么這兩個指標(biāo)很重要
目前無論是嵌入式系統(tǒng),PC還是大型服務(wù)器都遵循了馮。諾依曼結(jié)構(gòu)。
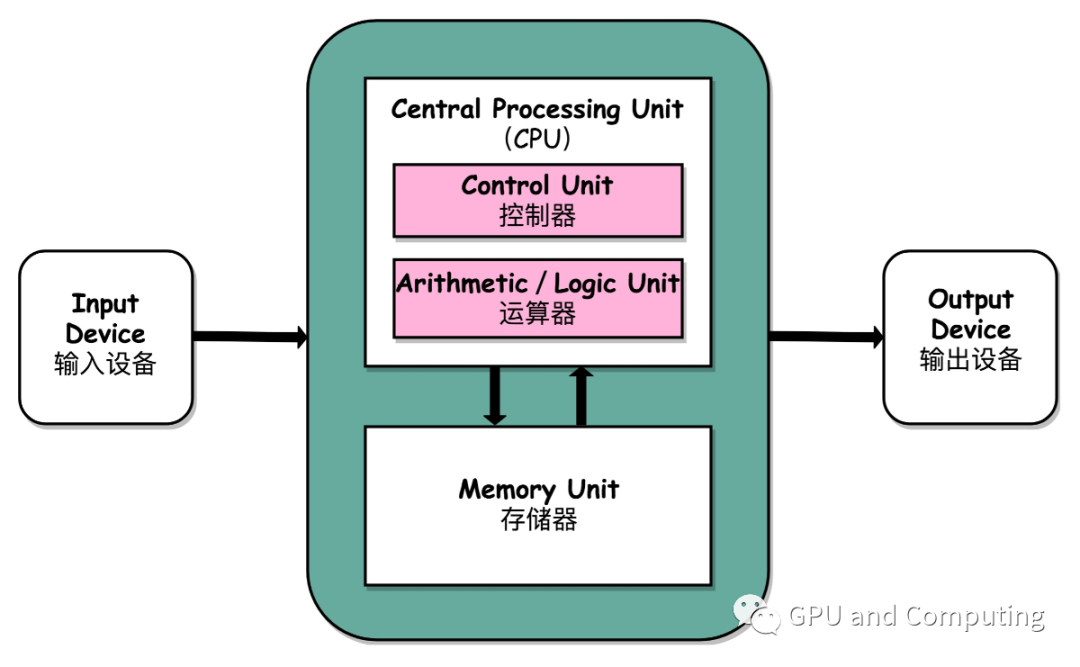
對CPU密集型程序來說,執(zhí)行時候系統(tǒng)的內(nèi)部交互主要在處理器(包括控制器和運算器)和存儲器之間展開,大概是如下圖過程。
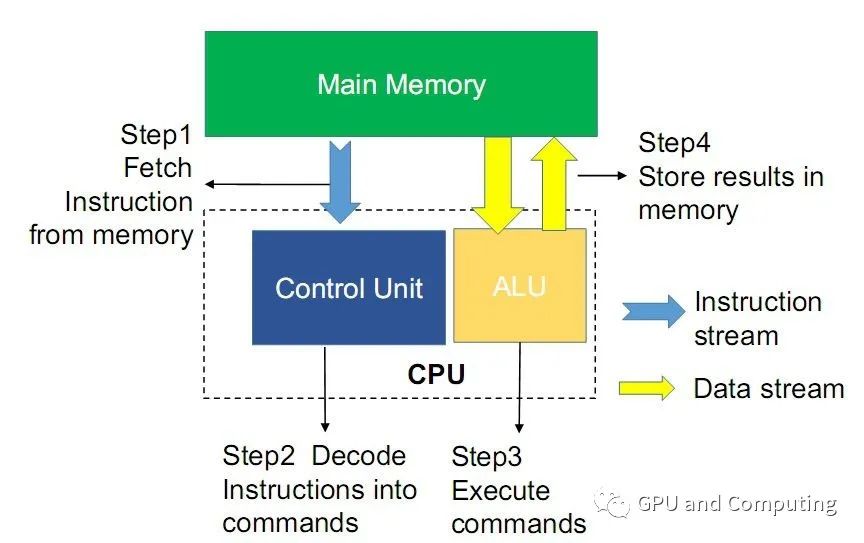
所以CPU的處理能力以及訪存的效率對程序的性能起到了關(guān)鍵作用。大家知道計算一個程序執(zhí)行時間的公式如下(假設(shè)該程序是CPU Bound),
程序執(zhí)行時間(time) = 程序指令數(shù)目(Intructions) * 指令的平均時鐘數(shù)(CPI, Clock cycles/Instruction) * 時鐘周期(Seconds/Clock cycle)
為支持計算所需的精度和廣度,CPU/GPU ALU支持浮點運算,單精度甚至雙精度都是必須的要求。這里我們引入FLOPS(floating point operations per second)的概念來表征CPU/GPU浮點運算能力,所以針對浮點計算密集型程序,把FLOPS套到上面公式,我們可以用浮點運算數(shù)目/FLOPS來估摸程序大概執(zhí)行時間。
訪存效率的重要性我們這里也可以再提一下,以GPU為例,無論是游戲還是深度學(xué)習(xí),都有大量的內(nèi)存讀寫數(shù)據(jù)量。比如graphics里,有三角面片模型裝載,紋理采樣,深度測試(depth test),Alpha混合,以及圖像輸出等等。深度學(xué)習(xí)訓(xùn)練的時候,巨大的訓(xùn)練集/測試集輸入,迭代過程幾十萬,百萬級別參數(shù)讀寫。如果訪存成為瓶頸(Memory Bound),強大的計算能力也無從發(fā)揮。
二,如何知道FLOPS 和內(nèi)存帶寬
我們先看下如何得到兩個指標(biāo)的理論數(shù)值。
關(guān)于內(nèi)存帶寬,假設(shè)某款GPU,其顯示內(nèi)存的時鐘頻率為1546 MHZ,顯存的位寬(Interface Width)為384 bit, 則其帶寬的理論峰值計算如下,具體也可以參考https://en.wikipedia.org/wiki/Memory_bandwidth。
BW = 1546(clocks per second) * 384(memory interface width) * 2(DDR) / 8(In bytes) = 148GB/s
而GPU的理論FLOPS計算就要微妙很多,各個廠家對演算過程諱莫如深,一般不會公開,我們這里也不多著墨,大家參考廠家給出的數(shù)據(jù)罷了。ARM的網(wǎng)站寫過一篇文章探討FLOPS營銷噱頭一地雞毛的狀態(tài),F(xiàn)lipping the FLOPS - how ARM measures GPU compute performance,搜來看看,可以起到心理預(yù)防的作用。
相比理論數(shù)值,對碼農(nóng)來說,我們更關(guān)心是我們程序運行的實際性能數(shù)值,這才是關(guān)系我們飯碗的要緊之處。假設(shè)一個程序的核心運算是如下SAXPY,恰當(dāng)?shù)夭渴鸬紾PU或者多核CPU后,比如平均運行時間為1us,我們該如何計算實際訪存帶寬和FOPS?
int N = 1 《《 22;
void saxpy(float a, float *x, float *y){
for (int i = 0; i 《 n; ++i)
y[i] = a*x[i] + y[i];
}
我們可以看到每次迭代,有三次內(nèi)存訪問(x讀一次,y讀寫各一次),而有兩次浮點運算(乘加各一次)。所以實際BW和FOPS的計算如下,
BW = (3 * N * 4) / (1 / 1e9) = 120GB/s
FOPS = (2 * N) / (1 / 1e9) = 20GFLOPS
我們可以把實際數(shù)值和理論峰值比較下,確認(rèn)運算瓶頸在何處,是memory bound還是cpu bound,然后進一步優(yōu)化,關(guān)于這部分內(nèi)容,我們以后介紹roofline模型的時候還會涉及。
三,ALU和訪存的功耗水平
下圖來自David A. Patterson的另一本著作《計算機體系結(jié)構(gòu):量化研究方法》,羅列45nm制程各種類型ALU和訪存的功耗大小以及他們相對水平,可以看到32b的內(nèi)存訪問的功耗遠超同樣位寬大小的運算。
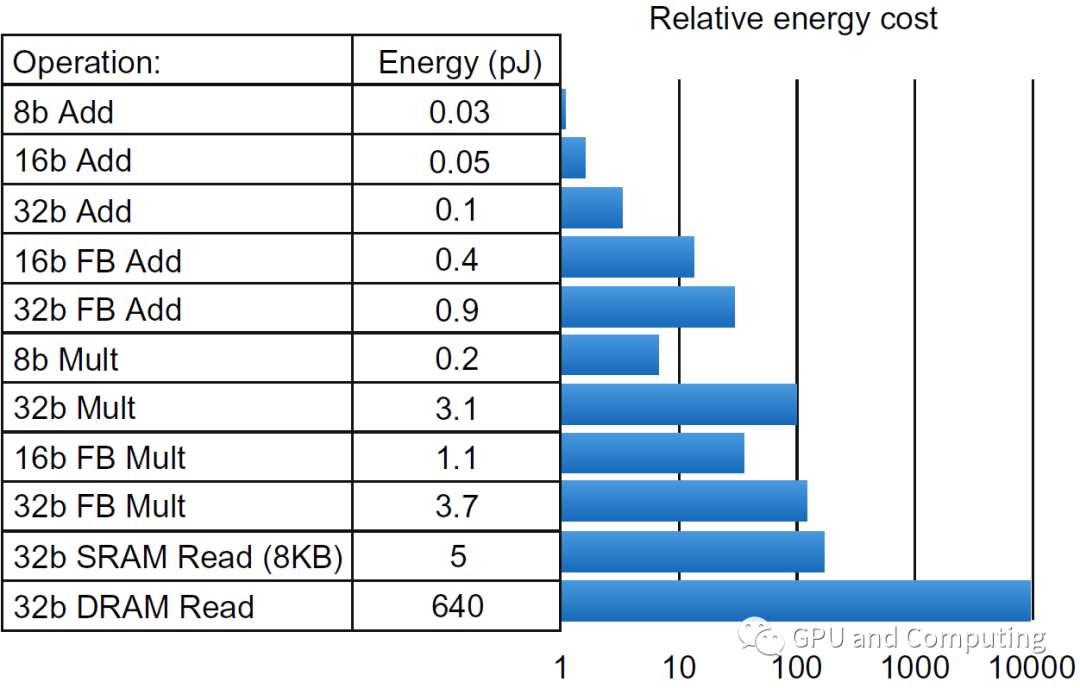
為什么我們要在這里留意功耗水平?移動設(shè)備由于電池供電,尺寸大小散熱限制,對功耗異常敏感,功耗大小直接決定設(shè)備的使用價值。以后我們談到移動GPU的設(shè)計的時候,可以了解如何在消除減少內(nèi)存訪問方面極盡所能。另外比特幣礦場礦機,數(shù)據(jù)中心的服務(wù)器,其數(shù)目都是以萬記,它們更是電老虎,每天的電力消耗才是運營的最大費用,會極大地影響了投資回報率,所以功耗水平有很重要的經(jīng)濟效果。最后目前全民倡導(dǎo)碳中和,綠色計算,身處產(chǎn)業(yè)鏈的我們,從硬件和軟件角度,努力提升功耗水平,也有很大社會意義。
編輯:lyn
-
cpu
+關(guān)注
關(guān)注
68文章
11055瀏覽量
216307 -
gpu
+關(guān)注
關(guān)注
28文章
4923瀏覽量
130829 -
ALU
+關(guān)注
關(guān)注
0文章
34瀏覽量
13292
原文標(biāo)題:GPU: 衡量計算效能的正確姿勢(2)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
常見傳動機構(gòu)負(fù)載慣量計算方法及實例

淺談電磁流量計的常見故障及排除方法
GPU加速計算平臺的優(yōu)勢
GPU云計算服務(wù)怎么樣
調(diào)理電路的噪聲余量計算如何計算
算智算中心的算力如何衡量?

電磁流量計的正確調(diào)試步驟
云端超級計算機使用教程
《CST Studio Suite 2024 GPU加速計算指南》
靶式流量計的工作原理 靶式流量計和渦街流量計比較
平衡流量計計算公式

GPU加速計算平臺是什么
GPU計算主板學(xué)習(xí)資料第735篇:基于3U VPX的AGX Xavier GPU計算主板 信號計算主板 視頻處理 相機信號





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論