") 清華聯(lián)合阿里達(dá)摩院開發(fā)行業(yè)首個人工標(biāo)注的少樣本NER數(shù)據(jù)集
清華聯(lián)合阿里達(dá)摩院開發(fā)行業(yè)首個人工標(biāo)注的少樣本NER數(shù)據(jù)集

NER(命名實(shí)體識別)作為NLP的一項(xiàng)基本任務(wù),其日常是訓(xùn)練人工智能(zhang)對一段文本中的專有名詞(人名、地名、機(jī)構(gòu)名等)進(jìn)行識別和分類。
翻譯成計算機(jī)語言,就是從一段非結(jié)構(gòu)化的自然語言中找到各種實(shí)體,并將其分為合適的類別。且避免出現(xiàn)“江大橋同志到底就任了多少年南京市長”這樣的問題
但在數(shù)據(jù)缺乏,樣本不足的前提下,如何基于先驗(yàn)知識進(jìn)行分類和學(xué)習(xí),這就是目前NLPer面臨的一道難題——少樣本(Few-Shot)。
雖然已有越來越多針對少樣本NER的研究出現(xiàn)(比如預(yù)訓(xùn)練語言模型BERT),但仍沒有一個專屬數(shù)據(jù)集以供使用。
而現(xiàn)在,共包含來自維基百科的18萬條句子,49萬個實(shí)體和460萬標(biāo)注,并具有8個粗粒度(coarse-grained types)實(shí)體類型和66個細(xì)粒度(fine-grained types)實(shí)體類型的數(shù)據(jù)集來了。
這就是清華大學(xué)聯(lián)合阿里達(dá)摩院共同開發(fā)的,行業(yè)內(nèi)第一個人工標(biāo)注(human-annotated)的少樣本NER數(shù)據(jù)集,F(xiàn)EW-NERD。
什么樣的數(shù)據(jù)集?
對比句子數(shù)量、標(biāo)記數(shù)、實(shí)體類型等統(tǒng)計數(shù)據(jù),F(xiàn)EW-NERD比相關(guān)領(lǐng)域內(nèi)已有的NER數(shù)據(jù)集都要更大。
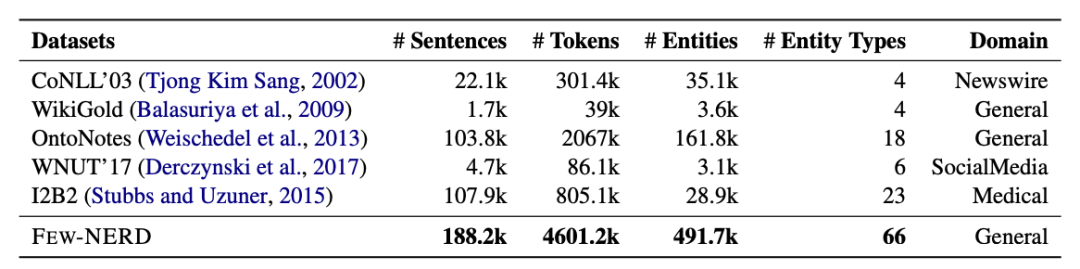
此外,它也是規(guī)模最大的人工標(biāo)注的數(shù)據(jù)集。
為實(shí)體命名常常需要聯(lián)系上下文,尤其是在實(shí)體類型很多時,注解難度將大大增加。
而FEW-NERD的注釋來自70位擁有語言學(xué)知識的注釋者,以及10位經(jīng)驗(yàn)豐富的專家。
具體而言,每個段落會交由兩人獨(dú)立完成注釋,然后由專家審查,再對分批抽取數(shù)據(jù)進(jìn)行雙重檢查。這很好地保證了注釋的準(zhǔn)確性。
比如上述“London is the fifth album by the British rock band…”這句話中的實(shí)體“London”,就被準(zhǔn)確標(biāo)注成了“Art-Music”。
而在以段落為單位進(jìn)行標(biāo)注時,因?yàn)闃颖玖坎⒉欢啵訤EW-NERD數(shù)據(jù)的類別分布預(yù)計是相對平衡的,這也是它與以往NER數(shù)據(jù)集的一個關(guān)鍵區(qū)別。
并且在實(shí)踐中,大多數(shù)未見的實(shí)體類型都是細(xì)粒度的。而傳統(tǒng)的NER數(shù)據(jù)集(如CoNLL’03、WNUT’17、OntoNotes)只包含4-18個粗粒度的類型。
這就難以構(gòu)建足夠多的N元任務(wù)(N-way metatasks),并訓(xùn)練學(xué)習(xí)相關(guān)特征。
相比之下,F(xiàn)EW-NERD共包含了112個實(shí)體標(biāo)簽, 并具有8個粗粒度實(shí)體類型,和66個細(xì)粒度實(shí)體類型。
基準(zhǔn)的選擇
為了探索FEW-NERD所有實(shí)體類型之間的知識相關(guān)性(knowledge correlations),研究者進(jìn)行了實(shí)體類型相似性的實(shí)證研究。
從實(shí)驗(yàn)結(jié)果得知,相同粗粒度類型的實(shí)體類型具有較大的相似性,從而使知識遷移更加容易。
這啟發(fā)了研究者從知識遷移的角度進(jìn)行基準(zhǔn)設(shè)定。最終設(shè)置了三個基準(zhǔn):
FEW-NERD (SUP)
采用標(biāo)準(zhǔn)的監(jiān)督式NER設(shè)置,將70%的數(shù)據(jù)隨機(jī)分割為訓(xùn)練數(shù)據(jù),10%為驗(yàn)證數(shù)據(jù),20%為測試數(shù)據(jù)。
FEW-NERD(INTRA)
少樣本學(xué)習(xí)任務(wù),只包含粗粒度實(shí)體類型。
FEW-NRTD (INTER)
少樣本學(xué)習(xí)任務(wù),包含60%的細(xì)粒度類型,20%的細(xì)粒度類型。
實(shí)際的應(yīng)用
針對少樣本命名實(shí)體識別,F(xiàn)EW-NERD提供了一個同時包含粗粒度和細(xì)粒度,且統(tǒng)一基準(zhǔn)的大型數(shù)據(jù)集。
而作者也指出,由于精確的上下文標(biāo)注,F(xiàn)EW-NERD數(shù)據(jù)集不僅可以用于少樣本場景,在監(jiān)督學(xué)習(xí)、終身學(xué)習(xí)、開放信息抽取、實(shí)體分類等任務(wù)上也可以發(fā)揮作用。
此外,建立在FEW-NERD基礎(chǔ)上的模型和系統(tǒng),還能幫助構(gòu)建各個領(lǐng)域的知識圖譜(KGs),包括生物醫(yī)學(xué)、金融和法律領(lǐng)域,并進(jìn)一步促進(jìn)NLP在特定領(lǐng)域的應(yīng)用發(fā)展。
開發(fā)者還表示,將在未來增加跨域注釋、遠(yuǎn)距離注釋和更精細(xì)的實(shí)體類型來擴(kuò)展FEW-NERD。
原文標(biāo)題:ACL-IJCNLP 2021|行業(yè)首個少樣本NER數(shù)據(jù)集,清華聯(lián)合阿里達(dá)摩院開發(fā)
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7257瀏覽量
91943 -
人工智能
+關(guān)注
關(guān)注
1807文章
49035瀏覽量
249792
原文標(biāo)題:ACL-IJCNLP 2021|行業(yè)首個少樣本NER數(shù)據(jù)集,清華聯(lián)合阿里達(dá)摩院開發(fā)
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
阿里巴巴達(dá)摩院劉志偉:QEMU RISC-V 的進(jìn)展、特性與未來規(guī)劃
什么是自動駕駛數(shù)據(jù)標(biāo)注?如何好做數(shù)據(jù)標(biāo)注?
全球首個胃癌影像篩查AI模型發(fā)布
東軟集團(tuán)入選國家數(shù)據(jù)局數(shù)據(jù)標(biāo)注優(yōu)秀案例
標(biāo)貝科技“4D-BEV上億點(diǎn)云標(biāo)注系統(tǒng)”入選國家數(shù)據(jù)局首批數(shù)據(jù)標(biāo)注優(yōu)秀案例

普華基礎(chǔ)軟件蒞臨阿里巴巴達(dá)摩院調(diào)研交流
中興通訊GoldenDB數(shù)據(jù)庫助力首個住房公積金國產(chǎn)數(shù)據(jù)庫聯(lián)合實(shí)驗(yàn)室落地?fù)P州
AI自動圖像標(biāo)注工具SpeedDP將是數(shù)據(jù)標(biāo)注行業(yè)發(fā)展的重要引擎






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論