 什么是自動駕駛數據標注?如何好做數據標注?
什么是自動駕駛數據標注?如何好做數據標注?

[首發于智駕最前沿微信公眾號]在自動駕駛系統的開發過程中,數據標注是一項至關重要的工作。它不僅決定了模型訓練的質量,也直接影響了車輛感知、決策與控制的性能表現。隨著傳感器種類和數據量的劇增,有效、精準且高效的數據標注流程顯得尤為關鍵。那什么是數據標注?如何做數據標注?
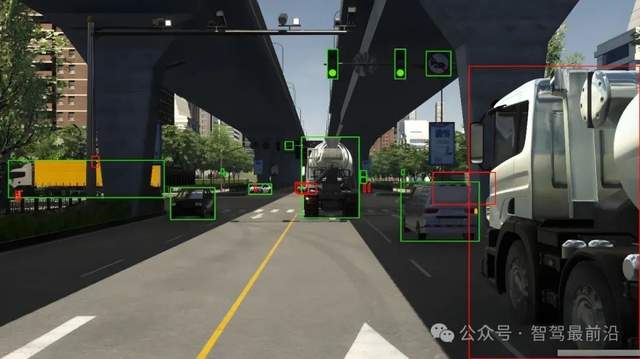
自動駕駛數據標注是指在自動駕駛系統所采集的感知數據(如攝像頭圖像、激光雷達點云、毫米波雷達等)中,為各種交通要素(車輛、行人、交通標志、車道線等)手動或半自動地添加類別標簽和空間標記(如邊界框、多邊形輪廓、實例ID、時序關聯等)的過程。通過準確、規范的標注,機器學習模型才能夠從海量原始數據中學習到目標的特征與行為模式,實現對真實道路環境的感知、理解與預測。高質量的標注不僅是訓練和評估算法性能的基礎,也直接關系到自動駕駛系統的安全性和可靠性。
自動駕駛數據標注就像給汽車“貼標簽”和“畫地圖”。當自動駕駛汽車的攝像頭或雷達拍下路面上的畫面時,我們需要在這些照片或點云里,用框框或線條把行人、車輛、紅綠燈、車道線等重要東西圈出來,并告訴電腦這是什么。這樣,電腦才能學會分辨路上的各種物體,并知道它們在哪里、在動還是靜。好的標注就像給自動駕駛汽車準備了清晰的“路況說明書”,幫助它更安全、更準確地開車。
想做好數據標注需要明確標注目標與業務場景。在開始標注之前,團隊必須對自動駕駛系統所需識別的對象類型、標注粒度以及實際應用場景有充分的了解。如在高速公路場景下重點關注相鄰車輛、護欄、交通標志等目標;而在城區復雜環境里,還要對行人、自行車、停車線、路口等做更細致的定義。只有在明確了標注目標之后,才能制定相應的標注規范和注釋手冊,避免后期因定義不清而產生的大量返工。

明確好標注目標與業務場景后,就要精心設計標注規范與本體(ontology)。標注規范相當于規則手冊,需要對類別名稱、屬性定義、標注邊界和格式等做詳細描述。分類體系要兼顧覆蓋全面與實際可操作性,既要考慮到模型的職責分工,也要避免類別之間的模糊重疊。同時,針對屬性信息(如車輛顏色、速度區間、交通標志類型)也要統一編碼,使后續模型訓練和評估時的數據統計更便捷。一個嚴謹的本體設計能有效減少標注歧義,并為下游任務奠定堅實基礎。
標注工具的選擇與定制同樣不容忽視。市面上有諸多商業和開源標注平臺,各有優劣。這就需要評估工具對多傳感器數據(如攝像頭圖像、激光雷達點云、毫米波雷達數據等)的支持程度,以及對三維標注、軌跡標注、語義分割等功能的完備性。此外,可定制化程度也是關鍵指標之一,若能夠根據項目需求添加自動預標注、智能審核、批量導出多種格式等插件,將大幅提升整個標注效率。
自動駕駛數據標注中人員培訓與管理是保證標注質量的根基。標注人員需要理解自動駕駛感知的基本原理,才能準確區分不同交通要素。此外還要熟練掌握標注工具的各項功能。定期組織培訓與考核,形成知識庫與常見問題解答,并通過標注示例和對比案例幫助標注員理解規范細節。
在標注流程中,質量控制尤為關鍵。可在標注的不同階段設置多級審校機制,初級標注完成后進行自檢,中級審核員復查,再由高級專家進行抽樣驗證;對于發現的問題,要及時反饋給標注員并迅速修正。通過引入統計指標(如平均標注時間、發現的錯誤率、復議率等),以量化質量水平,并不斷優化流程和規范。
多傳感器數據的時空同步和對齊是數據標注時的一大挑戰。自動駕駛系統通常需要將攝像頭與激光雷達、毫米波雷達等多源數據進行融合,對標注人員來說,必須準確識別同一物體在不同傳感器視角下的對應關系。為此,標注工具應支持多視角聯動標注和跨模態預覽,并提供時序檢查功能,以保證在不同時間戳的數據上標注的一致性與連貫性。
邊界框標注(bounding box)雖然普及,但在復雜場景中存在遮擋嚴重、目標形態多變等問題。若引入多邊形標注(polyline/segmentation)和實例分割(instance segmentation)更能滿足需求。多邊形標注能夠準確勾勒物體輪廓,而實例分割則能提供像素級精度。但相應地,標注成本也會增加,因此在實際項目中要根據使用場景和模型需求做權衡。
對于動態目標,還需要進行軌跡標注與時序關聯。通過在視頻流中為同一目標分配一致的ID,應能夠繪制出目標在連續幀中的運動軌跡,這對后續的多目標跟蹤(MOT)和運動預測至關重要。做好軌跡標注需要同時兼顧連續幀的對齊、ID一致性以及對突然出現或消失目標的處理策略,避免產生虛假斷鏈或ID錯配。
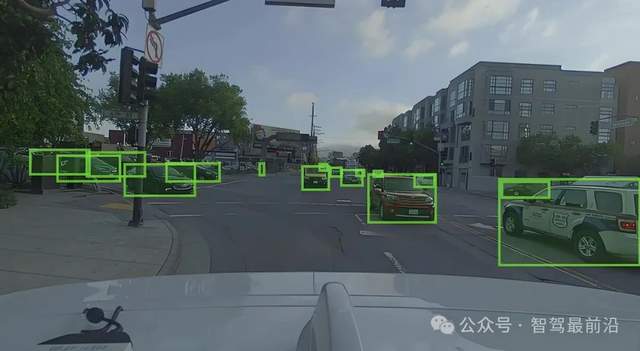
自動預標注正在成為提高效率的有力工具。借助自動預標注工具可以對新數據進行初步標注,再由人工進行修正,可在不降低標注質量的前提下大幅提升標注速度。為了發揮最大效益,需要不斷更新預標注模型,讓其在新場景下有更高的準確率;同時要對預標注結果設置可視化差異提示,使標注人員能夠快速定位需要修正的區域。
數據注釋后的格式與存儲同樣需要精心規劃。常見的標注格式有JSON、XML、ProtoBuf等,它們在定義方式、兼容性與可擴展性上各有特點。應根據模型訓練框架和數據管線來選擇最合適的格式,并對存儲路徑、文件命名、數據版本等做嚴格約束。與此同時,還應將標注數據與原始影像、點云等進行有效關聯,方便追溯與二次處理。
隱私保護和合規性是自動駕駛數據標注中不可忽視的一方面。自動駕駛數據中可能包含行人面部、車牌信息等敏感內容,需遵守相關法律法規,對必要信息進行脫敏處理或馬賽克遮擋。此外,對于不同國家和地區的標注,還要兼顧各地隱私保護條例,制定相應的數據存取與管理策略,以確保項目在法律邊界內運行。
數據多樣性與長尾場景是打造魯棒模型的重點,在自動駕駛數據標注時要尤為注意。標注時要特別關注低光照、惡劣天氣、夜間行駛、異常交通標志等長尾場景,不要僅局限于常見的白天晴好環境。通過對這些稀有場景下的數據進行優先標注與強化訓練,可以有效提升自動駕駛系統在復雜環境下的穩定性與安全性。
迭代和反饋機制有助于持續提升標注效率。隨著模型的迭代更新,新的需求、新的錯誤類型會不斷涌現,標注規范也需及時同步更新。應建立快速反饋通道,讓標注員、審核員、算法工程師能夠在統一平臺上對發現的問題進行歸類和討論,并將優化結果快速落地到工具和手冊中。
成本與時效是數據標注管理中一直需要平衡的因素。高精度標注意味著更多的人力和時間投入,但同時也能為模型帶來更穩定的收益。在做自動駕駛數據標注時,要根據節點需求和預算來制定合適的標注計劃,合理分配精力到核心場景與關鍵目標的標注中,并在保證質量的前提下追求最佳效率。
總而言之,自動駕駛數據標注是一項復雜而關鍵的系統工程,涵蓋了從目標定義、規范設計、工具選型到人員培訓、質量控制等多個環節。只有在每一個環節都做到精細化管理,才能為自動駕駛系統的訓練提供高質量的數據支撐,為最終實現安全可靠的自動駕駛奠定基礎。
審核編輯 黃宇
-
傳感器
+關注
關注
2565文章
52885瀏覽量
766517 -
自動駕駛
+關注
關注
788文章
14298瀏覽量
170443
發布評論請先 登錄
什么是數據標注?數據如何標注?

自動駕駛技術中的點云數據標注步驟和注意事項
點云標注在自動駕駛中的實踐應用與挑戰
點云標注在自動駕駛中的精度提升
自動駕駛點云標注:挑戰與解決方案
基于點云標注的自動駕駛技術:現狀與未來
自動駕駛點云標注的挑戰與解決方案


從自動駕駛行業,分析數據標注在人工智能的重要性
以自動駕駛角度解析數據標注對于人工智能的重要性





 工商網監
工商網監
評論